一、背景
高并发接口中,为了提高接口的高性能,在需要保存审计及操作记录的时候,往往有以下常见方案:
- 保存到redis数据库
- 异步保存到mysql/mongodb/es等数据库
- logger打印业务日志,采集与展示则交由elk模块
对于第一种方案,接口的高性能依赖于redis的性能;第二种方案的关键在于异步,可以是基于事件驱动机制,常见的CQRS设计就是例子;
本文则是介绍第三种方案,不同的是,我们的数据展示是在业务管理后台,而非kibana。
另外,生产环境,我们的应用程序是部署在k8s容器。
二、设计方案
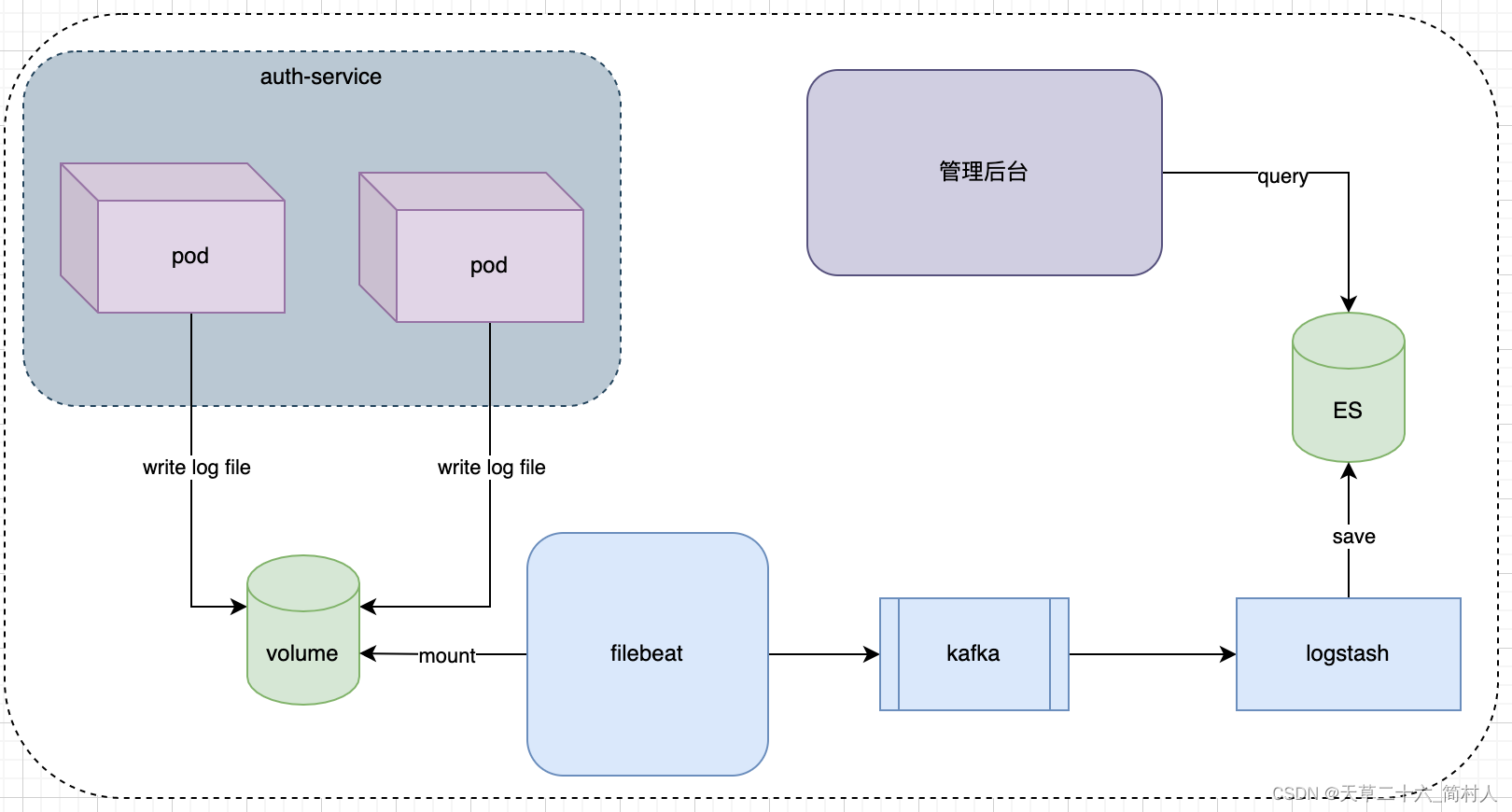
- 1、服务打印日志,持久化到nfs
- 2、filebeat先挂载nfs,再配置采集日志
- 3、kafka作为数据采集的削峰填谷的角色
- 4、Logstash读取kafka的数据,解析并存储到指定es数据库
- 5、管理后台连接并读取es数据库,展示数据
三、打印业务日志
使用logback使用不同的Logger对象,区分普通的jvm日志,把业务日志输出到指定的日志文件。
- logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--该日志将日志级别不同的log信息保存到不同的文件中 -->
<configuration><include resource="org/springframework/boot/logging/logback/defaults.xml"/><springProperty scope="context" name="springAppName"source="spring.application.name"/><springProperty scope="context" name="log_dir" source="logging.login.path" defaultValue="../logs"/><!-- 日志输出位置 --><property name="LOG_FILE" value="${log_dir}/${springAppName}-login"/><!-- 文件的日志输出样式 --><property name="FILE_LOG_PATTERN"value="%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}} ${LOG_LEVEL_PATTERN:-%5p} ${PID:- } --- [%t] %-40.40logger{39} : %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/><!-- 为logstash输出的JSON格式的Appender --><appender name="logstash"class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${LOG_FILE}.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!--日志文件输出的文件名 --><fileNamePattern>${LOG_FILE}.log.%d{yyyy-MM-dd}.%i.gz</fileNamePattern><timeBasedFileNamingAndTriggeringPolicyclass="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>20MB</maxFileSize></timeBasedFileNamingAndTriggeringPolicy><!--日志文件保留天数 --><MaxHistory>15</MaxHistory></rollingPolicy><!-- 日志输出编码 --><encoder><pattern>${FILE_LOG_PATTERN}</pattern><charset>utf8</charset></encoder></appender><logger name="com.xxx.event.handler.LoginLogEventHandler" level="INFO" additivity="false"><appender-ref ref="logstash"/></logger>
</configuration>
普通的jvm日志选择输出在console控制台,然后将流重定向到指定的日志文件里。
- console
<!-- 控制台的日志输出样式 --><property name="CONSOLE_LOG_PATTERN"value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/><!-- 控制台输出 --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>INFO</level></filter><!-- 日志输出编码 --><encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern><charset>utf8</charset></encoder></appender><!-- 日志输出级别 --><root level="INFO"><appender-ref ref="console"/></root>
对于业务应用程序来说,所做的事情只需要打印一条日志即可,其高性能可想而知。
四、flebeat采集日志
申请一台机器,专门采集日志,而非在每个Pod容器里使用sidecar边车模式部署filebeat容器。
当然,这台机器必须要先挂载nfs。(nfs是购买的阿里云“文件存储NAS”服务)

下面是filebeat.yml示例:
# cat /etc/filebeat/filebeat.yml
filebeat.prospectors:
- input_type: logpaths:- /login_output_service/auth-service.logmultiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'multiline.negate: truemultiline.match: afterdocument_type: login_out_logsoutput.kafka:enabled: truehosts: ["xxx.alikafka.aliyuncs.com:9092","yyy.alikafka.aliyuncs.com:9092","zzz.alikafka.aliyuncs.com:9092"]topic: 'login_out_logs'
五、kafka中间件
当然,它作为数据采集的中间件,所起的作用是削峰填谷,可以说,在整个链路中不是必须的。
建议你采用mq作为数据采集的过渡。
这里插一句,我们可以通过kafka的消息内容,反查出filebeat所在的机器。
原本的思路是想通过文件存储NAS查找ECS的挂载详情,可惜没找到入口。(也就是说,无法得到哪些ECS挂载了NFS,只能选择通过Kafka)
忘记了filebeat是部署在哪个机器,好在我们知道kafka,因为购买的是阿里云服务。
进入“消息队列Kafka版”
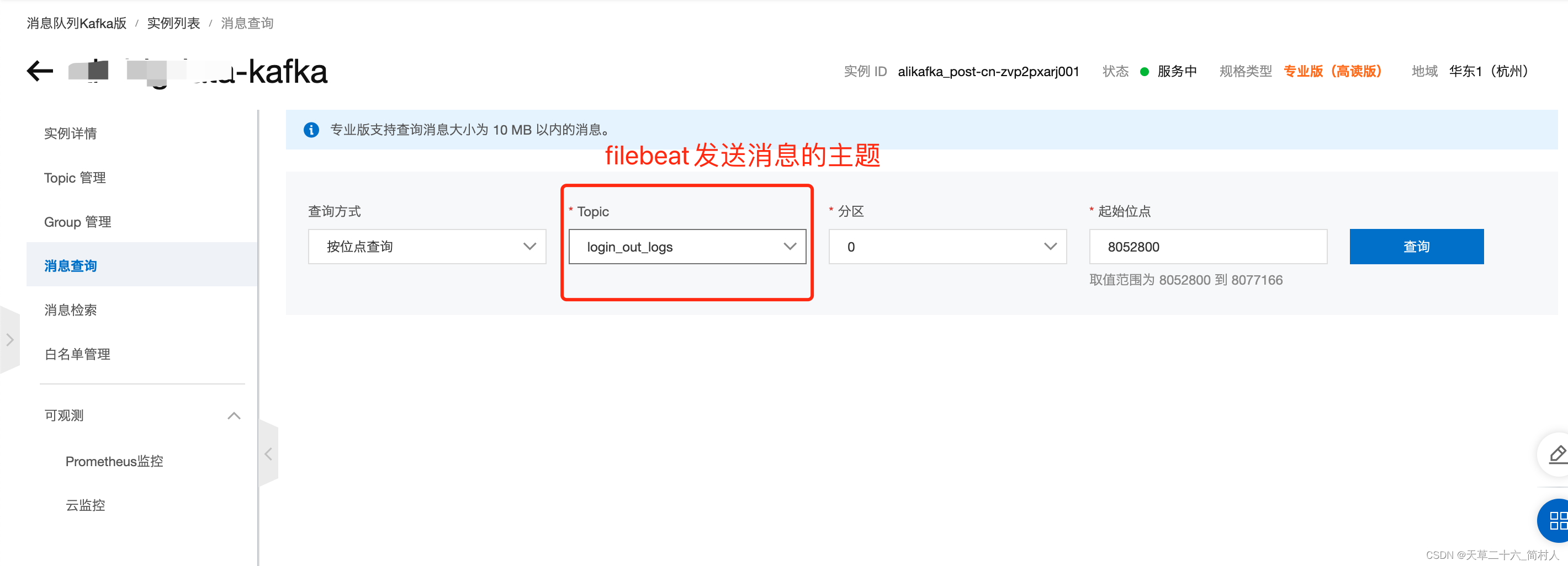
查看消息体内容:
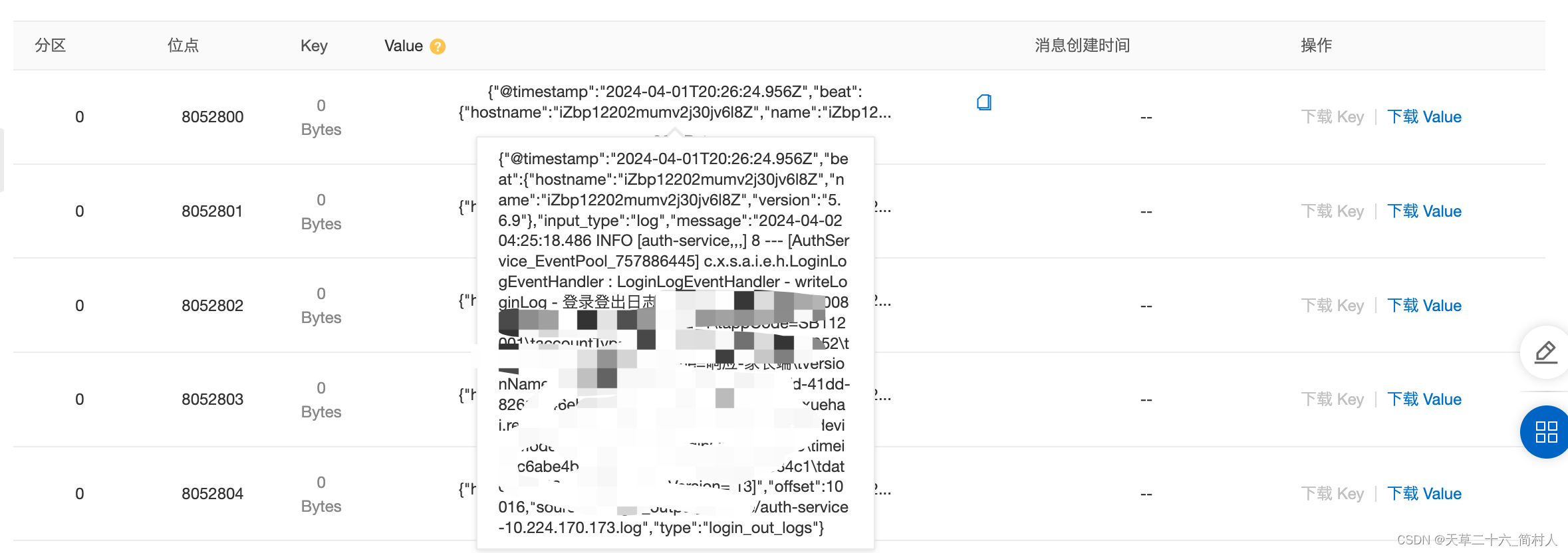
{“@timestamp”:“2024-04-01T20:26:24.956Z”,“beat”:{“hostname”:“iZbp12202mumv2j30jv6l8Z”,“name”:“iZbp12202mumv2j30jv6l8Z”,“version”:“5.6.9”},“input_type”:“log”,“message”:“2024-04-02 04:25:18.486 INFO [auth-service,] 8 — [AuthService_EventPool_757886445] c.x.s.a.i.e.h.LoginLogEventHandler : LoginLogEventHandler - writeLoginLog - 登录登出日志 [id=1774895838313730083\tdate=20240402042518\tosVersion= 13]”,“offset”:10016,“source”:“/opt/server/auth-service.log”,“type”:“login_out_logs”}
从这里可以看到,filebeat机器hostname是iZbp12202mumv2j30jv6l8Z,注意需要转换,实际上是“i-bp12202mumv2j30jv6l8”。
另外从source字段,可以知道日志的源文件在哪。
- 根据hostname查找ecs所在地
进入“云服务器ECS”
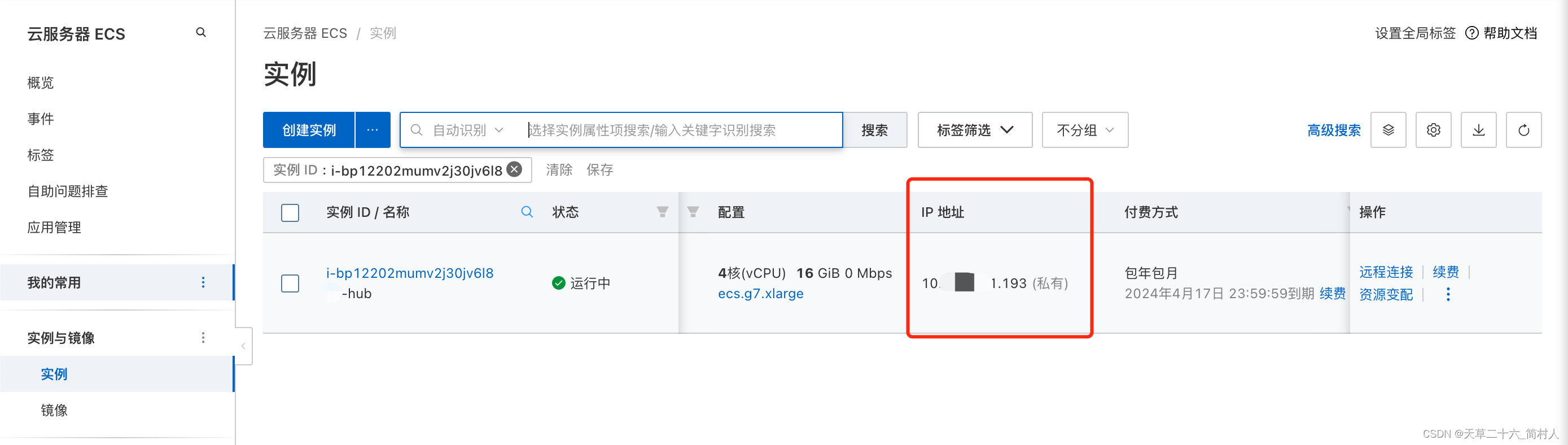
通过这两步,我们就通过kafka消息中间件,反查得到filebeat所在机器。关于filebeat在上一步已介绍,下面将介绍logstash的配置。
六、logstash存储业务日志
Logstash主要是用来解析业务日志,先读取kafka的数据,然后存储到es数据库。
另外logstash支持多个配置文件,建议你分开配置并加载。
# 默认配置
logstash -f /usr/share/logstash/pipeline/logstash.conf# 增加配置auth.conf
logstash -f /usr/share/logstash/pipeline/logstash.conf -f /usr/share/logstash/pipeline/auth.conf
- auth.conf 详情
# cat /usr/local/logstash-6.8.23/config/auth.confinput {kafka {bootstrap_servers => "xxx.alikafka.aliyuncs.com:9092","yyy.alikafka.aliyuncs.com:9092","zzz.alikafka.aliyuncs.com:9092"codec => "json"type => "_doc"topics => "login_out_logs"}
}filter {grok {match => {"message"=>"%{JAVA_DATE:logdate}\s+%{XHJVM_VALUE:logType}\s.*登录登出日志\s+\[id=(%{FIELD_VALUE:id}?\s+)date=(%{FIELD_VALUE:date}?\s+)osVersion=(%{FIELD_VALUE:osVersion}?)\]"}}# 增加采集时间戳,去掉一些非必要的字段date {match => ["logdate", "yyyy-MM-dd HH:mm:ss.SSS"]target => "@timestamp"remove_field => [ "logdate", "logType", "host", "@version", "@timestamp", "path", "message", "beat", "source", "input_type", "offset"]}}output{elasticsearch{# es的地址hosts => ["10.xxx.xxx.126:9200"]index => "auth_login_out_logs_write"codec => line { format => "%{message}"}document_type => "_doc"# es的用户名user => "{username}"# es的密码password => "{password}"document_id => "%{id}"}
}
还好无意中找到了logstash所在机器,要不然,要找出logstash还真是麻烦。。。
因为这里把很多“无用”的字段remove掉了,所以在es数据库中也无法得到采集的链路详情。
七、总结
本文试着通过另外一个解决方案来保证高并发接口的高性能,顺便介绍了如何找回filebeat所在机器的过程。同时提醒我们,在采集数据的时候,或者程序开发的时候,特别是当你的链路很长的时候,把每个环节的主体信息记录下来是多么的重要。