堆的应用
- 1.堆排序
- 2. topK问题
堆结构主要有两个应用:1、堆排序 2、topK问题
1.堆排序
现实中,排序是非常常见的,比如排序班级同学的各科分数,购物时,商品会按销量,价格,好评数等进行排序。相信大家也不喜欢再购物筛选时,加载半天出不来吧!一个好的排序用的时间会大大减少,改善用户的体验。堆排序就是一个速度较快的排序。
既然是叫做堆排序,那么首先需要一个堆的数据结构吗?答案是不需要,只是借助堆这个结构来实现排序的,不需要去写一个堆的数据结构。
当我们需要对数组的内容进行排序(达到修改数组),我们并不是得到一个升序或者降序的结果,后续如果还需要别的操作,也是对数组进行的。因此,当排升序时,我们需要建大堆;排降序时,需要建小堆。
思路大致如下。
以升序为例。
建大堆,可以得到最大的值,把这个值换到数组的末尾,然后不把这个值看作数组的内容,进行堆的调整,成为新的堆后,再进行首尾交换,直至排好序。
数组需要我们排序,那么它一定是乱序的,我们需要先把这些数据建堆。建堆需要用到向下调整算法或向上调整算法。交换完数据进行调整时需要用到向下调整算法,为了代码的统一,选择向下调整算法。
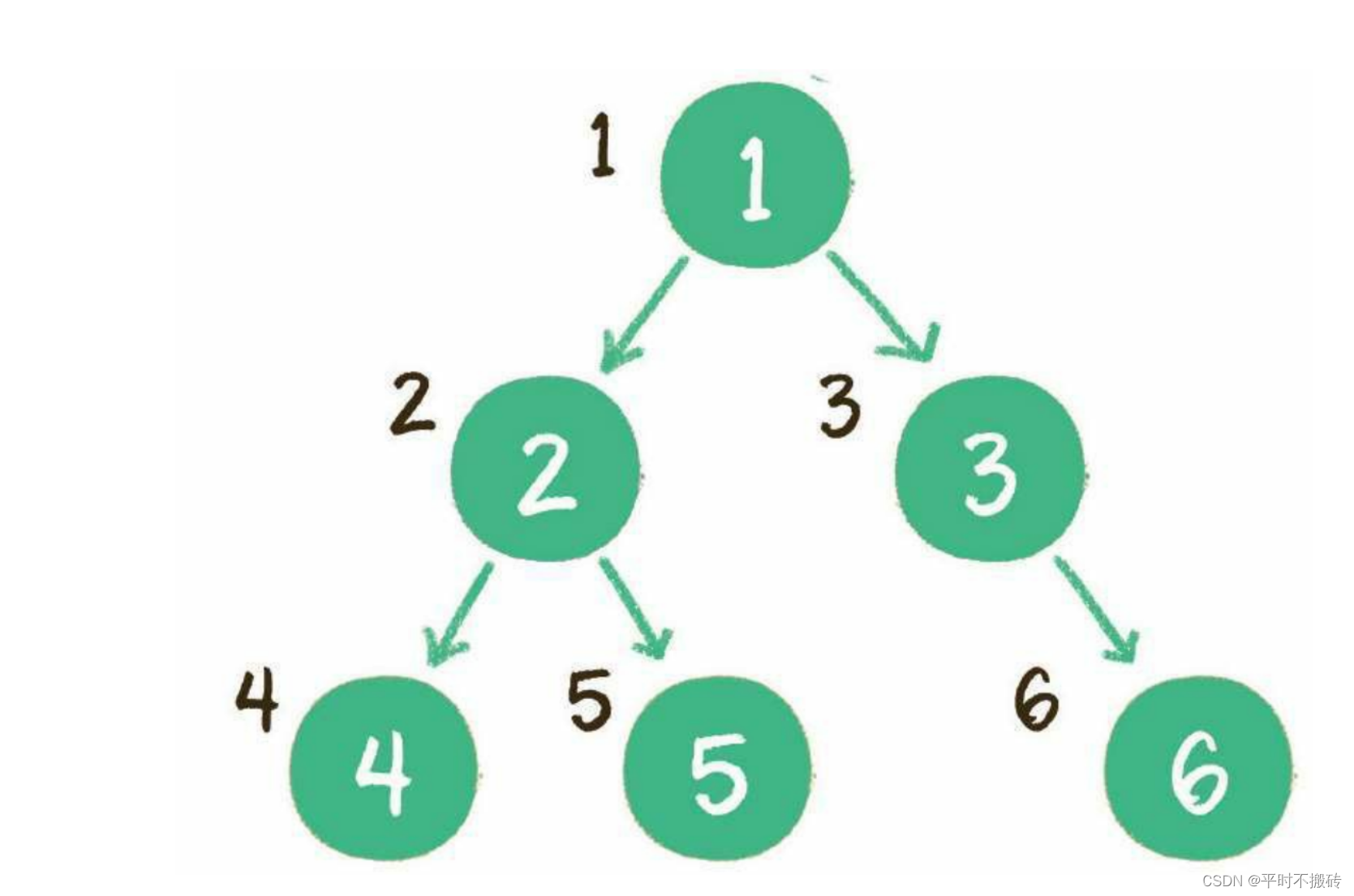
这里以 {5,1,3,2,4,6} 这组数据来画图帮助大家理解排序的过程。
代码如下
//堆排序
//复杂度O(N*logN)
void HeapSort(int* array, int numsArr)
{//向下调整建堆,复杂度O(N)for (int i = (numsArr - 2) / 2; i >= 0; i--){AdJustDown(array, numsArr, i);}//升序建大堆;降序建小堆//复杂度O(N*logN)int i = numsArr - 1;while (i > 0){swap(&array[0], &array[i]);//交换首尾元素AdJustDown(array, i, 0);i--;}
}
void AdJustDown(int* array, int num_array, int parent)//建大堆
{//假设左孩子符合条件int child = parent * 2 + 1;while (child < num_array){//存在右孩子且右孩子符合条件if (child + 1 < num_array && array[child + 1] > array[child]){++child;}if (array[child] > array[parent]){//交换数据swap(&array[child], &array[parent]);//更新下标parent = child;child = parent * 2 + 1;}else{break;}}
}
关于复杂度的概念,放在排序介绍。
我们的堆排序正不正确呢?验证一下就知道。
我们再换随机的20个数,来测试。

排序前后,我们都进行了打印,可以看出应该是没什么问题。
那堆排序的性能如何呢?我们排序1000万个数据看看需要用多少时间。
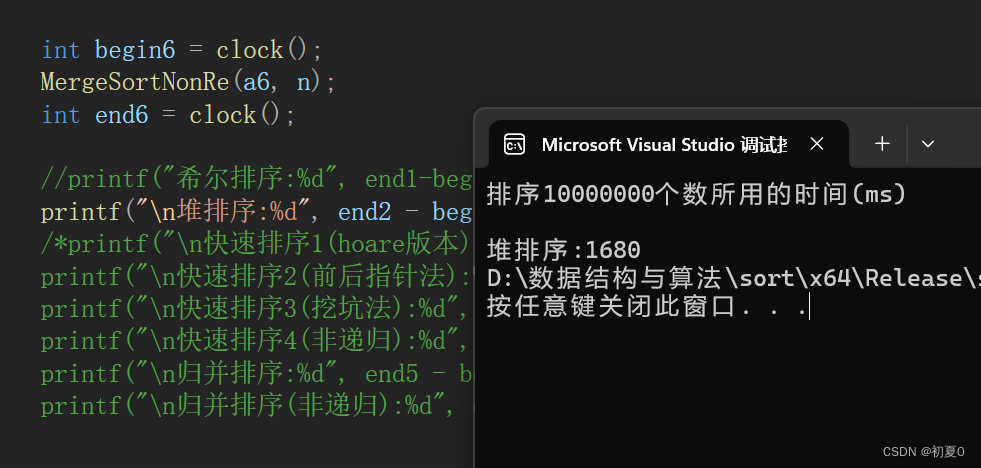
可以看出来,排序1000万个数据需要用到,17秒左右(release版本下),可能大家会觉得慢,是因为没有对比,后续介绍各种排序时,加上对比,大家就知道堆排序的速度了。
关于堆排序的介绍就到这里了,下面介绍堆的第二个应用
2. topK问题
topK问题是指,选出某些事的前k个符合条件的值。比如,大家应该都玩过王者荣耀这款游戏,里面有一个叫做国服榜的东东,想上榜需要某个英雄的战力值达到全中国前十。这里只需要知道前十名是哪些玩家即可,后面的不需要进行排序或者统计。在比如,想找到全中国最富有的前三名是谁。等等问题。
如何使用堆来实现呢,可以想到的是,先排序在选择最大或者最小的几个。但是这是我们可能只是为了操作前k个数据,其他数据不做操作,那么这种做法就会浪费很多空间。因此,此法不可行。
数据保存着,不用,就会浪费,但是磁盘的空间很大。几十g,或者几百g。因此把数据存在文件里,再存到磁盘里,就可以解决这个问题。
接下来就是该筛选前k个数据了。
这里的做法是,建立一个只有k个数据的小堆,再用剩余的数据和堆顶的数据比较,符合条件的就进入堆,遍历完剩余的数据后,堆中的数据就是前k大的。
比如我们要从100000个数据里,找前10大的数据。建立十个值的小堆后,如果和堆顶比对的这个数据是第一大的,它进堆后会在堆的最下面,如果先比的是第十大的,它也不会挡在堆顶,它会往下换,除非已经找好了前十个。
我们需要在文件里先写100000个数据
代码如下
void createNdata()
{int N = 100000;FILE* fin = fopen("date.txt", "w");if (fin == NULL){printf("fopen failed");return;}while (N){int x = (rand() + N) % 1000000;fprintf(fin, "%d\n", x);N--;}fclose(fin);
}
有了数据后,需要建立一个k个数据的小堆,在从文件里读数据,比较。
void TopKFile(int k)
{FILE* fout = fopen("date.txt", "r");int* heap = (int*)malloc(sizeof(int) * k);if (heap == NULL){return;}int i = 0;int num = k;int j = k;//读k个数据到数组while (j--){fscanf(fout, "%d", &heap[i++]);}int index = (k - 2) / 2;//将k个数据建堆while (index>=0){AdJustDown(heap, k, index);index--;}int nums = 0;//比较剩余的数据while (fscanf(fout, "%d", &nums) != EOF){if (nums > heap[0]){swap(&nums, &heap[0]);AdJustDown(heap, k, 0);}}for (int i = 0; i < k; i++){printf("%d ", heap[i]);}
}
最后打印的结果,就是前k大的数据。
运行验证一下
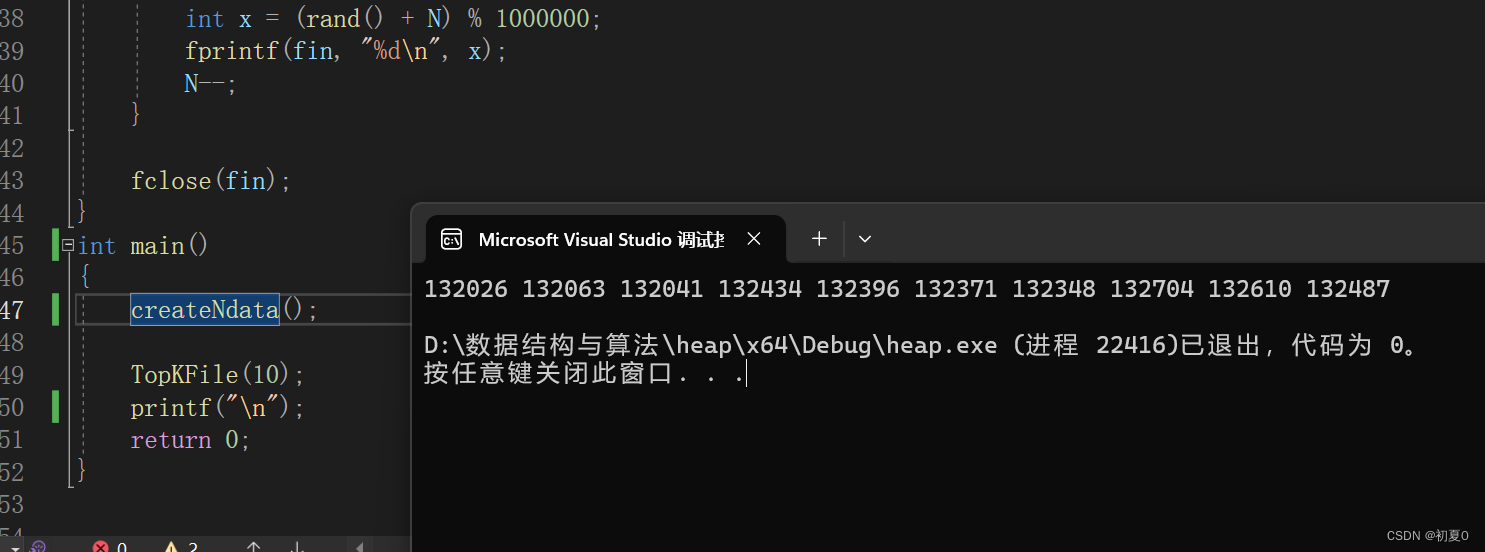
结果是十个比较大的数据,但是当我们打开文件后,会发现,数据大都很接近,不知道代码是否有问题,不知道这十个数是不是最大的。因此,这里再做一个操作,我们手动的修改十个值,如果代码能把这十个数据找出来,说明代码没有大问题。
修改的数据如下图
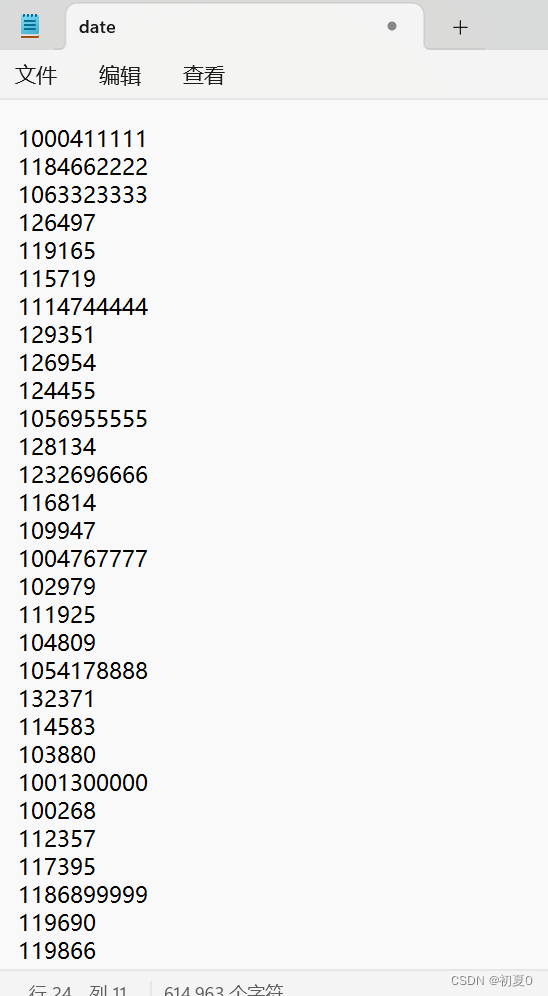
上面创建数据的代码里可以看出来,每一个数据都不可能超过1000000,而我们修改的数据每一个都超过了一百万,甚至一千万。
那么再来测试一下代码是否能找到这些数据。

可以看出,这十个值,确实是我们修改的那几个值。可见我们的代码应该没有什么问题了。
有关堆的应用就介绍到这里了。