索引覆盖、索引下推、索引合并、索引跳跃都是Mysql对索引的优化手段,它们的思想就是尽量让查询数据走索引,那它们有什么区别呢?
一、首先介绍一下MySQL体系结构
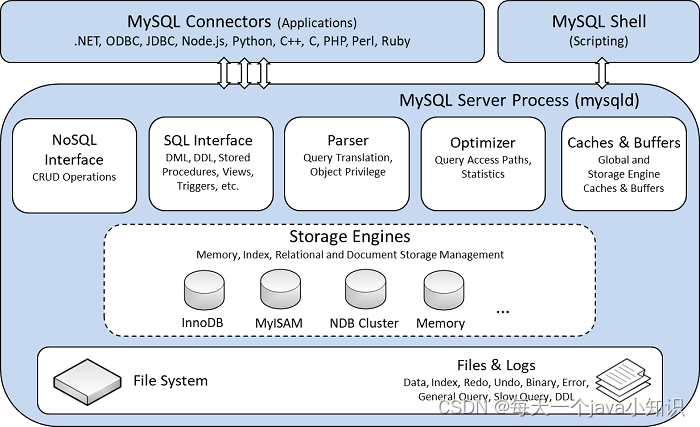
上图来自MySQL官方文档。
通常把MySQL从上至下分为以下几层:
- MySQL服务层:包括NoSQL和SQL接口、查询解析器、优化器、缓存和Buffer等组件。
- 存储引擎层:各种插件式的表格存储引擎,实现事务、索引等各种存储引擎相关的特性。
- 文件系统层: 读写物理文件。
MySQL服务层负责SQL语法解析、触发器、视图、内置函数、binlog、生成执行计划等,并调用存储引擎层去执行数据的存储和检索。我们后续说到的“索引下推”,它的“下”其实就是指将部分上层(服务层)负责的事情,交给了下层(存储引擎)去处理。
二、再介绍一下它们的概念
1、索引覆盖(Index Covering):索引覆盖是指查询的列包含在索引中,而不需要再次访问数据行。换句话说,查询可以直接从索引中获取所需的数据,而不必去查找实际的数据行。这样可以减少I/O操作,提高查询性能。
2、索引下推(Index Pushdown):索引下推是MySQL5.6中的新技术,是一种数据库查询优化技术,它利用了数据库引擎中的索引和过滤条件,将部分过滤工作下推到存储引擎层面进行处理,从而减少不必要的数据读取和传输。
在传统的查询执行过程中,数据库引擎首先根据索引定位到符合过滤条件的数据行,并将这些数据行读取到内存中,然后再进一步进行过滤操作。而索引下推则再这一步骤中尽可能将过滤操作下推到存储引擎层面,避免将不符合条件的数据行读取到内存中,减少了IO次数。
索引下推(简称ICP)的条件:
- 只能用于二级索引(secondary index);
- explain显示的执行计划中type值(join 类型)为 range 、ref 、 eq_ref 或者 ref_or_null ;
- 并非全部where条件都可以用ICP筛选,如果where条件的字段不在索引列中,还是要读取整表的记录到server端做where过滤;
- ICP只可以用于MyISAM和InnnoDB存储引擎;
通过一下命令开启/关闭索引下推(mysql 5.6之后默认开启)
set optimizer_switch="index_condition_pushdown=off";
set optimizer_switch="index_condition_pushdown=on";
3、索引合并(Index Merge):索引合并是指数据库系统在执行查询时,利用多个索引来加速查询的过程。它通过同时使用多个索引,并将它们的结果合并,来获取最终的查询结果。索引合并通常在数据库系统无法选择一个最优的单一索引来满足查询需求时使用。
索引合并又包含三个算法,在explain中显示:
using intersect:
index merge intersection access algorithm(索引合并交集访问算法)。
对于每一个使用到的索引进行查询,查询主键值集合,然后进行合并,求交集,也就是AND运算。
using union:
index merge union access algorithm(索引合并并集访问算法)
容易看出,与上述的算法类似,不过是使用了or连接条件,求并集。
执行流程与index merge intersect 类似,依旧是查询了有序的主键集合,然后进行求并集。
using sort_union:
index merge sort sort-union access algorithm (索引合并排序并集访问算法)
根据索引查询得到主键集合,对于每个主键集合进行排序,然后求并集。
4、索引跳跃(Index Skip Scan):索引跳跃是一种优化技术,用于在多列索引中查找数据,即使查询不是以索引的第一列开始。当索引的第一列选择性很差时,索引跳跃可以跳过该列,并在后续列上进行查找。这可以减少所需的索引扫描次数,从而提高查询性能。
我们可以通过SHOW VARIABLES like '%optimizer_switch%'查看它们的开启情况
index_merge=on(是否开启索引合并),
index_merge_union=on(索引合并中的并集操作),
index_merge_sort_union=on(索引合并中的排序并集操作),
index_merge_intersection=on(索引合并中的交集操作),
engine_condition_pushdown=on(是否开启引擎条件下推功能),
index_condition_pushdown=on(索引条件下推),
mrr=on,mrr_cost_based=on,block_nested_loop=on,
batched_key_access=off,materialization=on,
semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,
subquery_materialization_cost_based=on,use_index_extensions=on,
condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,
skip_scan=on(索引跳跃),
hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,
hypergraph_optimizer=off,derived_condition_pushdown=on
三、接下来创建一张员工表分别模拟一下这四个场景
1、首先我们创建了一个名为 employees 的表并创建相关索引,有 id、name、age 和 department 四个字段。
-- 创建员工表
CREATE TABLE employees (
ID int NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age int,
department VARCHAR(50)
);-- 创建name 和 age 列的联合索引
CREATE INDEX idx_name_age ON employees (name, age);-- 创建部门列的单列索引
CREATE INDEX idx_department ON employees (department);-- 创建覆盖了 name 和 department 列的联合索引
CREATE INDEX idx_name_department ON employees (name, department);-- 创建年龄列的单列索引
CREATE INDEX idx_age ON employees (age);
2、加入一些模拟数据,向数据库插入20条数据
INSERT INTO employees (name, age, department) VALUES
('张三', 30, '人力资源部'),
('李四', 25, '市场部'),
('王五', 35, '财务部'),
('赵六', 28, '信息技术部'),
('刘七', 32, '人力资源部'),
('陈八', 27, '市场部'),
('周九', 40, '财务部'),
('吴十', 26, '信息技术部'),
('郑十一', 33, '人力资源部'),
('孙十二', 29, '市场部'),
('朱十三', 38, '财务部'),
('冯十四', 24, '信息技术部'),
('田十五', 31, '人力资源部'),
('马十六', 26, '市场部'),
('韩十七', 37, '财务部'),
('顾十八', 23, '信息技术部'),
('张十九', 29, '人力资源部'),
('李二十', 28, '市场部'),
('王二十一', 39, '财务部'),
('赵二十二', 27, '信息技术部');
1)索引覆盖场景:因为现在我们数据库有 name 和 age 列的联合索引,当我们只查询 name 和 age时,就会走索引覆盖。
-- 查询员工姓名和年龄【索引覆盖】
SELECT name, age FROM employees;
我们用explain分析一下:

可以看到type显示的是index,表示查询语句在索引字段中遍历,再通过索引指向存储实际数据的地方,而不需要回表去磁盘遍历;
并且Extra字段里面显示Using index,这个就表示使用了索引覆盖;
2)索引下推场景:因为我们建立了(name,age)的联合索引,在一起作为条件过滤时,两个过滤条件都会下推到存储引擎层进行过滤,而无需返回服务层进行where过滤。
-- 查询姓张并且年龄>20的员工信息【索引下推】
SELECT * FROM employees WHERE NAME LIKE '张%' AND age > 20 ;
我们先关闭索引下推,用explain分析一下:
set optimizer_switch="index_condition_pushdown=off";

可以看到使用了联合索引(name,age),Extra是Using where,也就是表示使用了where条件过滤。
过程:先在存储引擎层通过name索引查询以 '张' 开头的id,再回表查询这部分id的数据,再回到MySQL服务层使用where条件过滤age>20。(联合索引只能走name这一部分)
然后我们打开索引下推,再用explain分析一下:
set optimizer_switch="index_condition_pushdown=on";

可以看到使用了联合索引(name,age),并且Extra是Using index condition,也就是使用了索引下推。
过程:先在存储引擎层通过name索引查询以 '张' 开头的id,然后在这一批id中,继续在存储引擎层通过age索引查出年龄大于20的id,回表查询剩余id的数据,然后将符合条件的数据返回到MySQL服务层。(在储存引擎层过滤了name和age)
因为【使用了索引下推,是在符合name条件的id的基础上,再次筛选符合age条件的id】所以它符合条件的id数量一定小于等于【未使用索引下推,筛选出只符合name条件的id数量】,因为它们都要通过id回表,即索引下推最大限度减少了回表的次数。
3)索引合并场景:因为我们的name和department都是单列索引,在一起作为条件过滤时,会将两个结果集合并,得到最终的结果。
-- 查询姓张并且部门为市场部的员工信息【索引合并】
SELECT * FROM employees WHERE name = '张三' OR department = '市场部';
我们使用explain分析一下:
 可以看到此时type为index_merge,为索引合并;
可以看到此时type为index_merge,为索引合并;
同时Extra中显示Using sort_union(idx_name_age,idx_department),表示索引合并中的排序并集操作。
它与索引下推的区别是:
索引下推应用于联合索引,在存储引擎层面一层一层筛选出符合条件的id集合;而索引合并是应用于多个单列索引,并且将每个单列索引得到的id集合取交集,获得最后符合条件的id集合;
4)索引跳跃场景:因为现在我们数据库有 name 和 age 列的联合索引,当我们只查询 age时,它就会跳过name索引,直接走age索引,不必去匹配最左原则。
-- 查询年龄>20的员工信息【索引跳跃】
SELECT * FROM employees FORCE INDEX(idx_name_age) WHERE age > 20;
我们再次用explain分析一下:
 发现它的type是ALL,并没有走索引;
发现它的type是ALL,并没有走索引;
这可能是由于数据量太少,执行器在优化阶段直接选择了全表扫描。
如果走了索引跳跃,应该是下图的场景,Extra为Using index for skip scan;

走索引跳跃有三个条件:
- Mysql的版本在8.0以上;
- 在优化器选项中设置skip_scan = on;
- Msql的优化器认为走索引跳跃的成本更低,效率更快。
ps:以下是我整理的java面试资料,感兴趣的可以看看。最后,创作不易,觉得写得不错的可以点点关注!
链接:https://www.yuque.com/u39298356/uu4hxh?# 《Java知识宝典》