目录
一、简介
二、优缺点介绍
三、Python代码示例
四、总结
一、简介
GBDT(Gradient Boosting Decision Tree)是一种集成学习算法,被广泛应用于机器学习中的回归和分类问题。它由多个决策树组成,每个决策树都通过迭代逐渐提升预测性能。
GBDT的基本原理是迭代地训练决策树,每次训练都基于之前训练的结果来进行优化。训练过程基于梯度下降的思想,使用了加法模型(Additive Model)和函数优化方法。
二、优缺点介绍
优点:
-
高准确性:GBDT模型在训练集和测试集上都表现良好,可以处理高维度、稀疏特征以及非线性关系等复杂问题。
-
强大的泛化能力:GBDT能够通过组合多个弱分类器来形成一个强分类器,减少过拟合的风险。
-
可解释性:GBDT模型能够提供特征重要性排名,帮助我们了解哪些特征对于预测结果的贡献较大。
-
对于缺失值的鲁棒性:GBDT能够自动处理缺失值,无需额外的处理步骤。
缺点:
-
训练时间较长:由于GBDT是一个串行算法,需要按顺序构建每棵决策树,因此训练时间较长。
-
对异常值敏感:GBDT模型在训练过程中容易受到异常值的影响,可能导致模型的性能下降。
-
需要调节参数:GBDT模型有一些需要手动调节的参数,如树的数量、学习率等,需要通过交叉验证等方法进行调优。
三、Python代码示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, ConfusionMatrixDisplay# 加载Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
target_names = iris.target_names# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建GBDT分类器
gbdt = GradientBoostingClassifier()# 使用训练集训练模型
gbdt.fit(X_train, y_train)# 使用训练好的模型进行预测
y_pred = gbdt.predict(X_test)# 计算模型的准确率
accuracy = accuracy_score(y_test, y_pred)
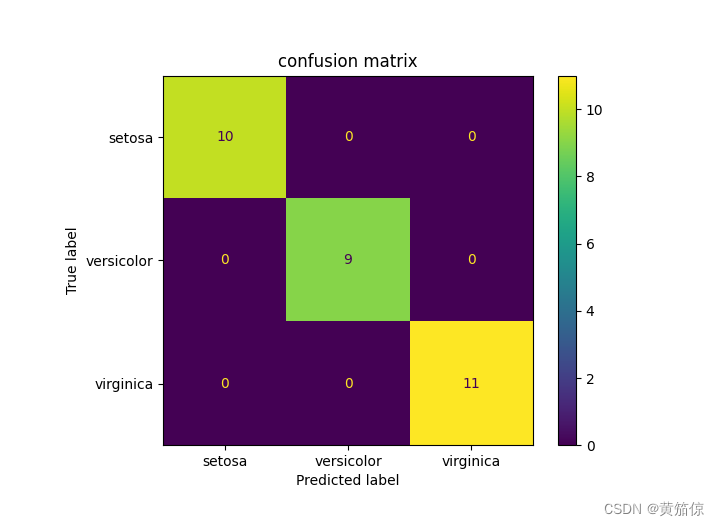
print("Accuracy:", accuracy)# 可视化分类结果的混淆矩阵
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=target_names)
disp.plot()
plt.title("confusion matrix")
plt.show()
plt.savefig(fname="result.png")
四、总结
GBDT模型是一种强大的集成学习算法,具有很好的泛化能力和可解释性。然而,训练时间较长和对异常值敏感是它的一些缺点。在实际应用中,我们需要根据具体情况评估模型的优缺点,并选择适合的算法。