1 电力变压器数据集介绍
1.1 数据背景
在这个Github仓库中,作者提供了几个可以用于长序列时间序列问题的数据集。所有数据集都经过了预处理,并存储为.csv文件。数据集的范围从2016/07到2018/07。

-
ETT-small: 含有2个电力变压器(来自2个站点)的数据,包括负载、油温。
-
ETT-large: 含有39个电力变压器(来自39个站点)的数据,包括负载、油温。
-
ETT-full: 含有69个电力变压器(来自39个站点)的数据,包括负载、油温、位置、气候、需求。
如果您使用此数据集,请引用Informer@AAAI2021最佳论文奖[论文]
1.2 为什么引入 油温数据 到该数据集中?
“电力分配问是电网根据顺序变化的需求管理电力分配到不同用户区域。但要预测特定用户区域的未来需求是困难的,因为它随工作日、假日、季节、天气、温度等的不同因素变化而变化。现有预测方法不能适用于长期真实世界数据的高精度长期预测,并且任何错误的预测都可能产生严重的后果。因此当前没有一种有效的方法来预测未来的用电量,管理人员就不得不根据经验值做出决策,而经验值的阈值通常远高于实际需求。保守的策略导致不必要的电力和设备折旧浪费。值得注意的是,变压器的油温可以有效反映电力变压器的工况。我们提出最有效的策略之一,是预测变压器的油温同时设法避免不必要的浪费。为了解决这个问题,我们的团队与北京国网富达科技发展公司建立了一个平台并收集了2年的数据。我们用它来预测电力变压器的油温并研究电力变压器极限负载能力。”
1.3 ETT-small:
我们提供了两年的数据,每个数据点每15分钟记录一次(用 m 标记),它们分别来自中国同一个省的两个不同地区,分别名为ETT-small-m1和ETT-small-m2。每个数据集包含2年 * 365天 * 24小时 * 4 = 70,080数据点。 此外,我们还提供一个小时级别粒度的数据集变体使用(用 h 标记),即ETT-small-h1和ETT-small-h2。 每个数据点均包含8维特征,包括数据点的记录日期、预测值“油温”以及6个不同类型的外部负载特征。
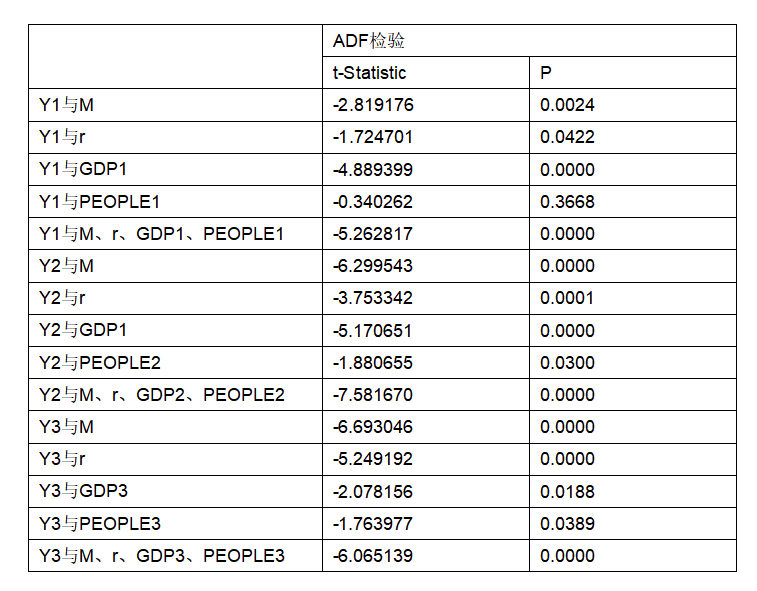
图 1."油温"特征在ETT-small数据集中的总览

图 2.全部变量的自相关图展示
数据集是使用.csv形式进行存储的,在图3中我们给出了一个数据的样例。其中第一行(8列)是数据头,包括了 “HUFL”, “HULL”, “MUFL”, “MULL”, “LUFL”, “LULL” 和 “OT”,每一列的详细意义展示在表1中。
图 3. ETT 数据样例
2 基于Python的数据集预处理
2.1 数据可视化
第一步,查看数据形状
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')# 读取数据
original_data = pd.read_csv('ETTh2.csv')
print(original_data.shape)
original_data.head()
第二步,数据可视化
# 取油温数据
OTddata = original_data['OT'].tolist()
OTddata = np.array(OTddata) # 转换为numpy# 可视化
plt.figure(figsize=(15,5), dpi=100)
plt.grid(True)
plt.plot(OTddata, color='green')
plt.show()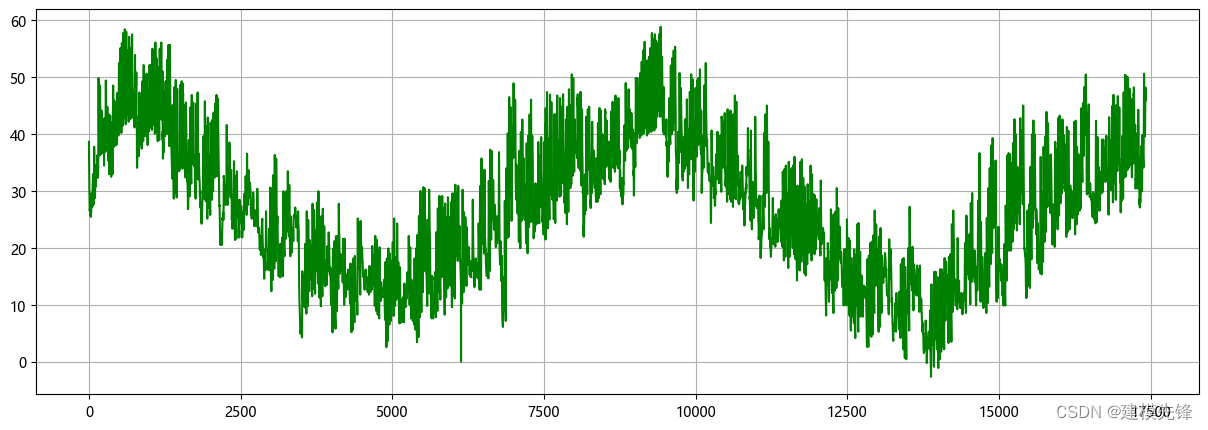
2.2 数据集预处理
第一步,先划分数据集,我们按照8:2划分训练集和测试集,划分比例不同,也会对后续的模型训练推理效果有影响,比如对电池寿命的预测中,明显训练集的数据量划分越多,模型拟合效果越好。
第二步,滑动窗口介绍
在时间序列预测问题中,滑动窗口是一种常用的数据处理方法,用于将时间序列数据转换为模型的输入特征和输出标签。滑动窗口的基本思想是以固定的时间窗口长度对时间序列进行切片,每次滑动一定的步长,从而生成一系列的子序列。这些子序列可以作为模型的输入特征,同时可以对应相同长度的下一个时间步的数据作为输出标签。这样就可以将时间序列数据转换为监督学习问题的数据集,用于训练和测试预测模型。
具体来说,对于一个时间序列 [x1, x2, x3, ..., xn],滑动窗口的过程如下:
1. 选择固定长度的时间窗口,比如长度为w。
2. 从序列的起始位置开始,取前w个数据作为输入特征,同时取第w+1个数据作为输出标签,形成第一个样本。
3. 然后向后滑动一个固定的步长,取第2到w+1个数据作为输入特征,同时取第w+2个数据作为输出标签,形成第二个样本,依此类推,直到序列末尾。
比如序列长为20,滑动窗口设置为4

训练集,滑动:

构造训练集数据和对应标签:
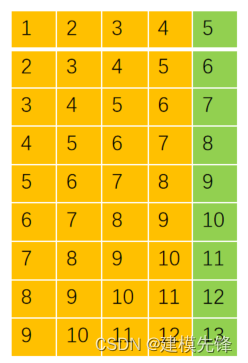
构造测试集数据和对应标签:

通过滑动窗口的处理,原始的时间序列数据被转换为一系列的样本,每个样本包括了固定长度的输入特征和对应的输出标签,用于模型的训练和测试。
滑动窗口技术可以帮助模型捕捉时间序列数据的局部模式和趋势,提高模型对时间序列的预测能力。
第三步,代码实现
import numpy as np
# 生成示例时间序列数据
time_series = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 定义滑动窗口大小
window_size = 3
# 使用滑动窗口处理时间序列数据
def data_window_maker(time_series, window_size):# 用来存放输入特征data_x = []# 用来存放输出标签data_y = []# 构建训练集和对应标签for i in range(len(time_series) - window_size):data_x.append(time_series[i:i+window_size]) # 取前window_size个数据作为输入特征data_y.append(time_series[i+window_size]) # 取第window_size+1个数据作为输出标签return data_x, data_yx, y = data_window_maker(time_series, window_size)
print("输出标签y:", y)
x
选择合适的 window_size 对于时间序列数据的滑动窗口处理非常关键。window_size 的大小直接影响着模型对时间序列数据的理解和预测能力。下面是一些关于选择 window_size 的决策因素:
-
上下文长度:window_size 应该足够长,能够捕获时间序列数据中的重要上下文信息,以便模型能够学习到时间序列数据的长期依赖关系。
-
数据周期性:如果时间序列数据具有明显的周期性,window_size 最好能够覆盖一个完整的周期,这样可以帮助模型更好地理解周期性特征。
-
数据频率:如果时间序列数据的采样频率很高,那么可能需要选择较小的 window_size,以便更好地捕捉时间序列数据的变化。
-
数据长度:如果时间序列数据比较长,可以适当增大 window_size,以提高模型对整体趋势的理解。
-
训练样本数量:选择合适的 window_size 可以确保生成足够数量的训练样本,以便模型能够充分学习时间序列数据的模式。
一般来说,选择合适的 window_size 需要结合具体的时间序列数据特点和预测任务需求来进行调整。通常情况下,可以通过尝试不同的 window_size 并进行交叉验证来确定最佳的参数值。也可阅读相关领域的论文,参考论文中的设定数值。