前两篇文章都在讲 Redis 的 5 大常用数据类型,以及典型的 10 大应用场景。
那么今天就来看看 Redis 实现分布式锁。
聊一聊Redis实现分布式锁的8大坑
Redis中5大常见数据类型用法
工作中Redis用的最多的10种场景
在分布式系统中,保证资源的互斥访问是一个关键的点,而 Redis 作为高性能的键值存储系统,在分布式锁这块也被广泛的应用。然而,在使用 Redis 实现分布式锁时需要考虑很多的因素,以确保系统正确的使用还有程序的性能。
下面我们将探讨一下使用Redis实现分布式锁时需要注意的关键点。

首先还是大家都知道,使用 Redis 实现分布式锁,是两步操作,设置一个key,增加一个过期时间,所以我们首先需要保证的就是这两个操作是一个原子操作。
1、原子性
在获取锁和释放锁的过程中,要保证这个操作的原子性,确保加锁操作与设置过期时间操作是原子的。Redis 提供了原子操作的命令,如SETNX(SET if Not eXists)或者 SET 命令的带有NX(Not eXists)选项,可以用来确保锁的获取和释放是原子的。
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {return true;
}
return false;
2、锁的过期时间
为了保证锁的释放,防止死锁的发生,获取到的锁需要设置一个过期时间,也就是说当锁的持有者因为出现异常情况未能正确的释放锁时,锁也会到达这个时间之后自动释放,避免对系统造成影响。
try{String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);if ("OK".equals(result)) {return true;}return false;
} finally {unlock(lockKey);
}
此时有些朋友可能就会说,如果释放锁的过程中,发生系统异常或者网络断线问题,不也会造成锁的释放失败吗?
是的,这个极小概率的问题确实是存在的。所以我们设置锁的过期时间就是必须的。当发生异常无法主动释放锁的时候,就需要靠过期时间自动释放锁了。
不管操作成功与否,都要释放锁,不能忘了释放锁,可以说锁的过期时间就是对忘了释放锁的一个兜底。
3、锁的唯一标识
在上面对锁都加锁正常的情况下,在锁释放时,能正确的释放自己的锁吗,所以每个客户端应该提供一个唯一的标识符,确保在释放锁时能正确的释放自己的锁,而不是释放成为其他的锁。一般可以使用客户端的ID作为标识符,在释放锁时进行比较,确保只有当持有锁的客户端才能释放自己的锁。
如果我们加的锁没有加入唯一标识,在多线程环境下,可能就会出现释放了其他线程的锁的情况发生。
有些朋友可能就会说了,在多线程环境中,线程A加锁成功之后,线程B在线程A没有释放锁的前提下怎么可以再次获取到锁呢?所以也就没有释放其他线程的锁这个说法。
下面我们看这么一个场景,如果线程A执行任务需要10s,锁的时间是5s,也就是当锁的过期时间设置的过短,在任务还没执行成功的时候就释放了锁,此时,线程B就会加锁成功,等线程A执行任务执行完成之后,执行释放锁的操作,此时,就把线程B的锁给释放了,这不就出问题了吗。
所以,为了解决这个问题就是在锁上加入线程的ID或者唯一标识请求ID。
对于锁的过期时间短这个只能根据业务处理时间大概的计算一个时间,还有就是看门狗,进行锁的续期。
伪代码如下
if (jedis.get(lockKey).equals(requestId)) {jedis.del(lockKey);return true;
}
return false;
4、锁非阻塞获取
非阻塞获取意味着获取锁的操作不会阻塞当前线程或进程的执行。通常,在尝试获取锁时,如果锁已经被其他客户端持有,常见的做法是让当前线程或进程等待直到锁被释放。这种方式称为阻塞获取锁。
相比之下,非阻塞获取锁不会让当前线程或进程等待锁的释放,而是立即返回获取锁的结果。如果锁已经被其他客户端持有,那么获取锁的操作会失败,返回一个失败的结果或者一个空值,而不会阻塞当前线程或进程的执行。
非阻塞获取锁通常适用于一些对实时性要求较高、不希望阻塞的场景,比如轮询等待锁的释放。当获取锁失败时,可以立即执行一些其他操作或者进行重试,而不需要等待锁的释放。
在 Redis 中,可以使用 SETNX 命令尝试获取锁,如果返回成功(即返回1),表示获取锁成功;如果返回失败(即返回0),表示获取锁失败。通过这种方式,可以实现非阻塞获取锁的操作。
try {Long start = System.currentTimeMillis();while(true) {String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);if ("OK".equals(result)) {if(!exists(path)) {mkdir(path);}return true;}long time = System.currentTimeMillis() - start;if (time>=timeout) {return false;}try {Thread.sleep(50);} catch (InterruptedException e) {e.printStackTrace();}}
} finally{unlock(lockKey,requestId);
}
return false;
在规定的时间范围内,假如说500ms,自旋不断获取锁,不断尝试加锁。
如果成功,则返回。如果失败,则休息
50ms然后在开始重试获取锁。
如果到了超时时间,也就是500ms时,则直接返回失败。
说到了多次尝试加锁,在 Redis,分布式锁是互斥的,假如我们对某个 key 进行了加锁,如果 该key 对应的锁还没有释放的话,在使用相同的key去加锁,大概率是会失败的。
下面有这样一个场景,需要获取满足条件的菜单树,后台程序在代码中递归的去获取,知道获取到所有的满足条件的数据。我们要知道,菜单是可能随时都会变的,所以这个地方是可以加入分布式锁进行互斥的。
后台程序在递归获取菜单树的时候,第一层加锁成功,第二层、第n层 加锁不久加锁失败了吗?
递归中的加锁伪代码如下
private int expireTime = 1000;public void fun(int level,String lockKey,String requestId){try{String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);if ("OK".equals(result)) {if(level<=10){this.fun(++level,lockKey,requestId);} else {return;}}return;} finally {unlock(lockKey,requestId);}
}如果我们直接使用的话,看起来问题不大,但是真正执行程序之后,就会发现报错啦。
因为从根节点开始,第一层递归加锁成功之后,还没有释放这个锁,就直接进入到了第二层的递归之中。因为锁名为lockKey,并且值为requestId的锁已经存在,所以第二层递归大概率会加锁失败,最后就是返回结果,只有底层递归的结果返回了。
所以,我们还需要一个可重入的特性。
5、可重入
redisson 框架中已经实现了可重入锁的功能,所以我们可以直接使用
private int expireTime = 1000;public void run(String lockKey) {RLock lock = redisson.getLock(lockKey);this.fun(lock,1);
}public void fun(RLock lock,int level){try{lock.lock(5, TimeUnit.SECONDS);if(level<=10){this.fun(lock,++level);} else {return;}} finally {lock.unlock();}
}
上述的代码仅供参考,这也只是提供一个思路。
下面我们还是聊一下 redisson 可重入锁的原理。
加锁主要通过以下代码实现的。
if (redis.call('exists', KEYS[1]) == 0)
then redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil;
end;
return redis.call('pttl', KEYS[1]);
-
KEYS[1]:锁名
-
ARGV[1]:过期时间
-
ARGV[2]:uuid + “:” + threadId,可认为是requestId
1、先判断如果加锁的key不存在,则加锁。
2、接下来判断如果key和requestId值都存在,则使用hincrby命令给该key和requestId值计数,每次都加1。注意一下,这里就是重入锁的关键,锁重入一次值就加1。
3、如果当前 key 存在,但值不是 requestId ,则返回过期时间。
释放锁的脚本如下
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0)
then return nil
end
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0)
then redis.call('pexpire', KEYS[1], ARGV[2]); return 0; else redis.call('del', KEYS[1]); redis.call('publish', KEYS[2], ARGV[1]); return 1;
end;
return nil
1、先判断如果 锁名key 和 requestId 值不存在,则直接返回。
2、如果 锁名key 和 requestId 值存在,则重入锁减1。
3、如果减1后,重入锁的 value 值还大于0,说明还有引用,则重试设置过期时间。
4、如果减1后,重入锁的 value 值还等于0,则可以删除锁,然后发消息通知等待线程抢锁。
6、锁竞争
对于大量写入的业务场景,使用普通的分布式锁就可以实现我们的需求。但是对于写入操作少的,有大量读取操作的业务场景,直接使用普通的redis锁就会浪费性能了。所以对于锁的优化来说,我们就可以从业务场景,读写锁来区分锁的颗粒度,尽可能将锁的粒度变细,提升我们系统的性能。
6.1、读写锁
对于降低锁的粒度,上面我们知道了读写锁也算事在业务层面进行降低锁粒度的一种方式,所以下面我们以 redisson 框架为例,看看实现读写锁是如何实现的。
读锁
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.readLock();
try {rLock.lock();//业务操作
} catch (Exception e) {log.error(e);
} finally {rLock.unlock();
}
写锁
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.writeLock();
try {rLock.lock();//业务操作
} catch (InterruptedException e) {log.error(e);
} finally {rLock.unlock();
}
通过讲锁分为读锁与写锁,最大的提升之后就在与大大的提高系统的读性能,因为读锁与读锁之间是没有冲突的,不存在互斥,然后又因为业务系统中的读操作是远远多与写操作的,所以我们在提升了读锁的性能的同时,系统整体锁的性能都得到了提升。
读写锁特点
- 读锁与读锁不互斥,可共享
- 读锁与写锁互斥
- 写锁与写锁互斥
6.2、分段锁
上面我们通过业务层面的读写锁进行了锁粒度的减小,下面我们在通过锁的分段减少锁粒度实现锁性能的提升。
如果你对 concurrentHashMap 的源码了解的话你就会知道分段锁的原理了。是的就是你想的那样,把一个大的锁划分为多个小的锁。
举个例子,假如我们在秒杀100个商品,那么常规做法就是一个锁,锁 100个商品,那么分段的意思就是,将100个商品分成10份,相当于有 10 个锁,每个锁锁定10个商品,这也就提升锁的性能提升了10倍。
具体的实现就是,在秒杀的过程中,对用户进行取模操作,算出来当前用户应该对哪一份商品进行秒杀。
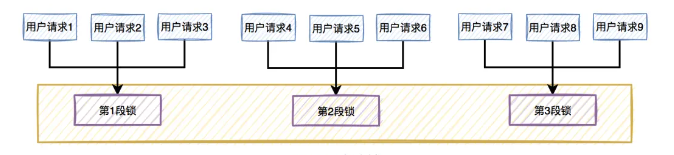
通过上述将大锁拆分为小锁的过程,以前多个线程只能争抢一个锁,现在可以争抢10个锁,大大降低了冲突,提升系统吞吐量。
不过需要注意的就是,使用分段锁确实可以提升系统性能,但是相对应的就是编码难度的提升,并且还需要引入取模等算法,所以我们在实际业务中,也要综合考虑。
7、锁超时
在上面我们也说过了,因为业务执行时间太长,导致锁自动释放了,也就是说业务的执行时间远远大于锁的过期时间,这个时候 Redis 会自动释放该锁。
针对这种情况,我们可以使用锁的续期,增加一个定时任务,如果到了超时时间,业务还没有执行完成,就需要对锁进行一个续期。
Timer timer = new Timer();
timer.schedule(new TimerTask() {@Overridepublic void run(Timeout timeout) throws Exception {//自动续期逻辑}
}, 10000, TimeUnit.MILLISECONDS);
获取到锁之后,自动的开启一个定时任务,每隔 10s 中自动刷新一次过期时间。这种机制就是上面我们提到过的看门狗。
对于自动续期操作,我们还是推荐使用 lua 脚本来实现
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('pexpire', KEYS[1], ARGV[1]);return 1;
end;
return 0;
需要注意的一点就是,锁的续期不是一直续期的,业务如果一直执行不完,到了一个总的超时时间,或者执行续期的次数超过几次,我们就不再进行续期操作了。
上面我们讲了这么几个点,下面我们来说一下 Redis 集群中的问题,如果发生网络分区,主从切换问题,那么该怎么解决呢?
8、网络分区
假设 Redis 初始还是主从,一主三从模式。
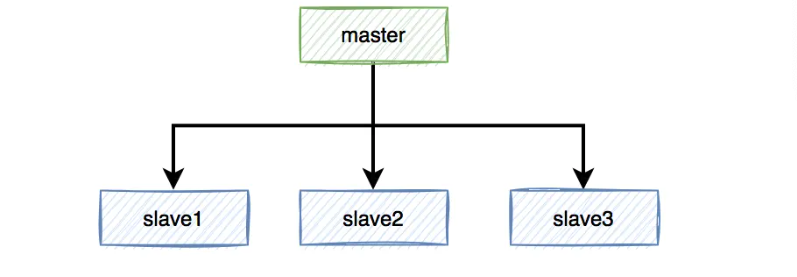
Redis 的加锁操作都是在 master 上操作,成功之后异步不同到 slave上。
当 master 宕机之后,我们就需要在三个slave中选举一个出来当作 master ,假如说我们选了slave1。
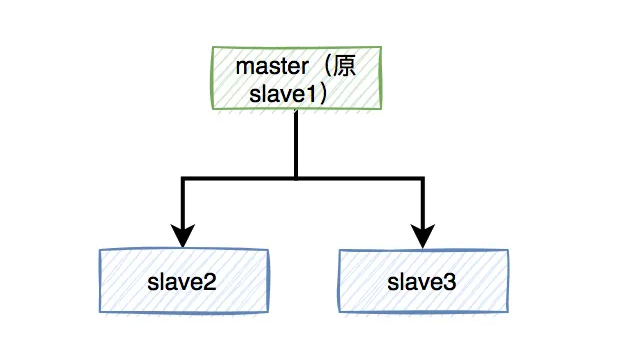
现在有一个锁A进行加锁,正好加锁到 master上,然后 master 还没有同步到 slave 上,master 就宕机了,此时,后面在来新的线程获取锁A,也是可以加锁成功的,所以分布式锁也就失效了。
Redisson 框架为了解决这个问题,提供了一个专门的类,就是 RedissonRedLock,使用 RedLock 算法。
RedissonRedLock 解决问题的思路就是多搭建几个独立的 Redisson 集群,采用分布式投票算法,少数服从多数这种。假如有5个 Redisson 集群,只要当加锁成功的集群有5/2+1个节点加锁成功,意味着这次加锁就是成功的。
1、搭建几套相互独立的 Redis 环境,我们这里搭建5套。
2、每套环境都有一个 redisson node 节点。
3、多个 redisson node 节点组成 RedissonRedLock。
4、环境包括单机、主从、哨兵、集群,可以一种或者多种混合都可以。
我们这个例子以主从为例来说
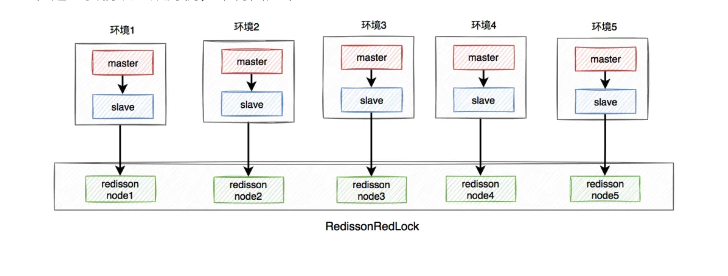
RedissonRedLock 加锁过程如下
1、向当前5个 Redisson node 节点加锁。
2、如果有3个节点加锁成功,那么整个 RedissonRedLock 就是加锁成功的。
3、如果小于3个节点加锁成功,那么整个加锁操作就是失败的。
4、如果中途各个节点加锁的总耗时,大于等于设置的最大等待时间,直接返回加锁失败。
通过上面这个示例可以发现,使用 RedissonRedLock 可以解决多个示例导致的锁失效的问题。但是带来的也是整个 Redis 集群的管理问题。
1、管理多套 Redis 环境
2、增加加锁的成本。有多少个 Redisson node就需要加锁多少次。
由此可见、在实际的高并发业务中,RedissonRedLock 的使用并不多。
在分布式系统中,CAP 理论应该都是知道的,所以我们在选择分布式锁的时候也可以参考这个。
C(Consistency) 一致性
A(Acailability) 可用性
P(Partition tolerance)分区容错性
所以如果我们的业务场景,更需要数据的一致性,我们可以使用 CP 的分布式锁,例子 zookeeper。
如果我们更需要的是保证数据的可用性,那么我们可以使用 AP 的分布式锁,例如 Redis。
其实在我们绝大多数的业务场景中,使用Redis已经可以满足,因为数据的不一致,我们还可以使用
BASE理论的最终一致性方案解决。因为如果系统不可用了,对用户来说体验肯定不是那么好的。
如果这篇文章对您有所帮助,或者有所启发的话,帮忙点个关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
wx 搜索《醉鱼Java》,回复面试、获取2024面试资料
参考链接:https://mp.weixin.qq.com/s/EhucmYblfrRxbAuJTdPlfg