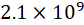作为计算机视觉研究人员,在处理大图像时,避免不了受到硬件的限制,毕竟大图像已经不再罕见,手机的相机和绕地球运行的卫星上的相机可以拍摄如此超大的照片,遇到超大图像的时候,我们当前最好的模型和硬件都会达到极限。

所以通常我们在处理大图像时会做出两个次优选择之一:下采样或裁剪。但这两种方法会导致图像中存在的信息量和上下文显着损失。所以研究人员提出了一个新框架,可在 GPU 上对大型图像进行端到端建模,同时有效地将全局背景与局部细节聚合起来。
之所以要费心费力的处理大图像,是因为如果你要看球赛,结果只能看到球附近的一小块区域,您一定不会满意。又或者您只能以低分辨率观看比赛。那还有什么意义呢?
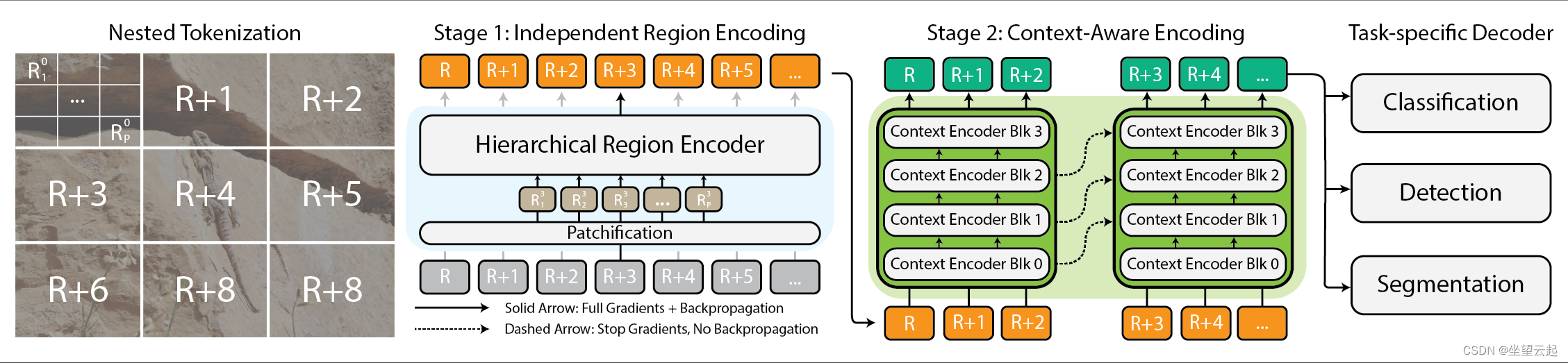
所以我们既想看到某颗具体的树木,也想看到整个森林,这就是这个框架被提出来的原因。该框架将这些巨大的图像按层次结构切成更小、更容易理解的部分,然后使用一些巧妙的技术,弄清楚这些部分之间的关系。
该框架的核心观点就是其核心是嵌套标记化。将图像分割成多个区域,每个区域可以根据视觉主干(我们称之为区域编码器)预期的输入大小进一步分割成子区域,然后再进行修补以供处理该区域编码