接下来,我们开始在web框架上整合 LangChain、OpenAI、FAISS等。
一、PDF库
因为项目是基于PDF文档的,所以需要一些操作PDF的库,我们这边使用的是PyPDF2
from PyPDF2 import PdfReader# 获取pdf文件内容
def get_pdf_text(pdf):text = ""pdf_reader = PdfReader(pdf)for page in pdf_reader.pages:text += page.extract_text()return text传入 pdf 文件路径,返回 pdf 文档的文本内容。
二、LangChain库
1、文本拆分器
首先我们需要将第一步拿到的本文内容拆分,我们使用的是 RecursiveCharacterTextSplitter ,默认使用 ["\n\n","\n"," "] 来分割文本。
from langchain.text_splitter import RecursiveCharacterTextSplitter# 拆分文本
def get_text_chunks(text):text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,# chunk_size=768,chunk_overlap=200,length_function=len)chunks = text_splitter.split_text(text)return chunks其中这里 chunk_size 参数要注意,这里是指文本块的最大尺寸,如果用chatgpt3.5会在问答的时候容易出现token长度超过4096的异常,这个后面会说如何调整,只需要换一下模型就好了。
这个参数对于向量化来说,比较重要,因为到时候喂给OpenAI去分析的时候,携带的上下文内容就会比较多,这样准备性和语义分析上也有不少的帮助。
2、向量库
项目使用 FAISS,就是将 pdf 读取到的文本向量化以后,通过 FAISS 保存到本地,后续就不需要再执行向量化,就可以读取之前的备份。
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings# 保存
def save_vector_store(textChunks):db = FAISS.from_texts(textChunks, OpenAIEmbeddings())db.save_local('faiss')# 加载
def load_vector_store():return FAISS.load_local('faiss', OpenAIEmbeddings())其中 faiss 参数为保存的目录名称,默认在项目同级目录下生成。
这里使用 OpenAI 的方法 OpenAIEmbeddings 来进行向量化。
3、检索型问答链
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate# 获取检索型问答链
def get_qa_chain(vector_store):prompt_template = """基于以下已知内容,简洁和专业的来回答用户的问题。如果无法从中得到答案,清说"根据已知内容无法回答该问题"答案请使用中文。已知内容:{context}问题:{question}"""prompt = PromptTemplate(template=prompt_template,input_variables=["context", "question"])return RetrievalQA.from_llm(llm=ChatOpenAI(model_name='gpt-3.5-turbo-16k'), retriever=vector_store.as_retriever(), prompt=prompt)1)RetrievalQA 检索行问答链
这里使用 RetrievalQA,这种链的缺点是一问一答,是没有history的,是单轮问答。
2)自定义提示 PromptTemplate
这里还是使用到自定义提示 PromptTemplate,主要作用是使 OpenAI 能根据我们传入的向量文本为蓝本,限制它的回答范围,并要求使用中文回答。这样的好处在于,如果我们问一些非 pdf 涉及的内容,OpenAI 会返回无法作答,而不是根据自己的大模型数据来回答问题。
3)llm 模型
我们还是用 Chat 模型作为 llm 的输入模型,这里可以看到,我们使用的 model 为 gpt-3.5-turbo-16k,它可以支持 16384 个tokens,而 gpt-3.5-turbo 只支持 4096 个tokens
所以这里就回答了上面文本拆分器 chunk_size 参数,如果使用 gpt-3.5-turbo 模型,笔者尝试过,最大可能就是只能到 768,不过这个具体要看向量化以后,携带的文本的大小tokens而定。
不过使用 gpt-3.5-turbo-16k 也是有代价的,就是它比 gpt-3.5-turbo 要贵,大概是2倍的价格。
三、路由整合
我们将上面实现的三个工具方法整合到路由,主要实现 pdf 文件的本地向量初始化,还有基于向量化的 pdf 文档内容进行问答。
from fastapi import APIRouter, Body
from ..util import pdf, langchain, fassrouter = APIRouter(prefix="/chat"
)# 初始化pdf文件
@router.get("/init_pdf")
async def init_pdf():# pfd文件路径pdf_doc = "xxx.pdf"# get pdf textraw_text = pdf.get_pdf_text(pdf_doc)# get the text chunkstext_chunks = openai.get_text_chunks(raw_text)# savefass.save_vector_store(text_chunks)return {'success': True}# 问答
@router.post("/question")
async def question(text: str = Body(embed=True)
):vector_store = fass.load_vector_store()chain = langchain.get_qa_chain(vector_store)response = chain({"query": text})return {'success': True, "code": 0, "reply": response}1)初始化 pdf 文件
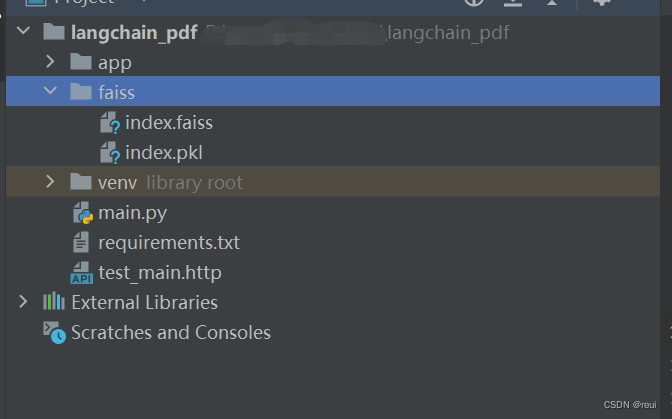
执行接口不报错的话,会看到项目同级目录下会多了一个 faiss 目录,里面包括两个索引文件。
2)配置 OpenAI
因为项目使用到 OpenAI 的接口,所以我们这边需要全局配置 api-key,还有我们云函数上的代理地址。
from fastapi import FastAPI
from app.routers import chat
import sys
import os
from dotenv import load_dotenv, find_dotenv
import openaiload_dotenv(find_dotenv())
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.api_base = os.getenv("OPENAI_API_BASE")# 防止相对路径导入出错
sys.path.append(os.path.join(os.path.dirname(__file__)))app = FastAPI()# 将其余单独模块进行整合
app.include_router(chat.router)调整后的 main.py 文件如上图,项目中需要加入 .env 文件
OPENAI_API_KEY=
OPENAI_API_BASE=https://xxxxxx/v1要注意api_base的地址后面,一般云函数地址的后面要加上 /v1
四、运行和测试
至此,一个简单的基于 LangChain 库的 PDF文档问答就完成了,我们随便拿一份网上能找到保险pdf做个实验,看看效果如何
我们就来问 pdf 中的这段内容,问题是 "风险的特征有哪些?"

我们来看看回复,几个大的要点也基本答上来了,效果也算可以了。
{"success": true,"code": 0,"reply": {"query": "风险的特征有哪些?","result": "风险的特征包括以下几个方面:\n1. 风险的客观性:风险是一种客观存在,与人的意志无关,独立于人的意识之外的客观存在。\n2. 风险的普遍性:在社会经济生活中,人们面临各种各样的风险,从个人、企业到国家和政府机关都无处不在。\n3. 风险的损害性:风险与人们的经济利益密切相关,会给人们的经济造成损失以及对人的生命造成伤害。\n4. 某一风险发生的不确定性:虽然风险是客观存在的,但对某一具体风险而言,其发生是偶然的,是一种随机现象。\n5. 总体风险发生的可测性:虽然个别风险事故的发生是偶然的,但大量风险事故往往呈现出明显的规律性,可以通过统计方法进行准确测量。"}
}我们再尝试问一些不在 pdf 里的问题,"如何评价中国足球"
{"success": true,"code": 0,"reply": {"query": "如何评价中国足球","result": "根据已知内容无法回答该问题。"}
}这跟我们上面 自定义提示 PromptTemplate 的内容是一致的。
最后附上 仓库地址