分类目录:《深入理解深度学习》总目录
相关文章:
·注意力机制(AttentionMechanism):基础知识
·注意力机制(AttentionMechanism):注意力汇聚与Nadaraya-Watson核回归
·注意力机制(AttentionMechanism):注意力评分函数(AttentionScoringFunction)
·注意力机制(AttentionMechanism):Bahdanau注意力
·注意力机制(AttentionMechanism):多头注意力(MultiheadAttention)
·注意力机制(AttentionMechanism):自注意力(Self-attention)
·注意力机制(AttentionMechanism):位置编码(PositionalEncoding)
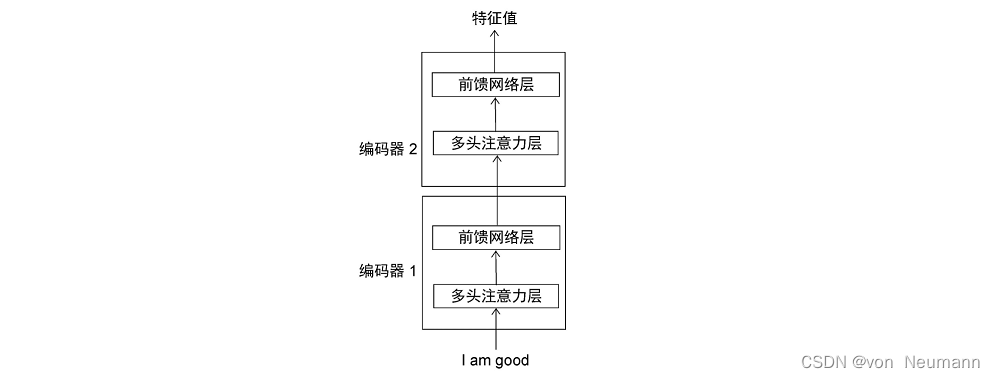
Transformer中的编码器不止一个,而是由一组 N N N个编码器串联而成。一个编码器的输出作为下一个编码器的输入。在下图中有 N N N个编码器,每一个编码器都从下方接收数据,再输出给上方。以此类推,原句中的特征会由最后一个编码器输出。编码器模块的主要功能就是提取原始序列(图中为“I am good.”句子)中的特征。

需要注意的是,在Transformer原论文《Attention Is All You Need》中,作者使用了 N = 6 N=6 N=6,也就是说,一共有6个编码器叠加在一起。当然,我们可以尝试使用不同的 N N N值。这里为了方便理解,我们使用 N = 2 N=2 N=2。要进一步理解编码器的工作原理,我们可以将编码器再次分解。下图展示了编码器的组成部分。由下图可知,每一个编码器的构造都是相同的,并且包含两个部分:
- 多头注意力层
- 前馈网络层
其中多头注意力层即是我们在《深入理解深度学习——注意力机制(Attention Mechanism):多头注意力(Multi-head Attention)》中介绍的多头注意力。前馈网络由两个有ReLU激活函数的全连接层组成。前馈网络的参数在句子的不同位置上是相同的,但在不同的编码器模块上是不同的。除此之外,在编码器中还有一个重要的组成部分,即叠加和归一组件。它同时连接一个子层的输入和输出,如下图所示(虚线部分),它同时连接多头注意力层的输入和输出,也同时连接前馈网络层的输入和输出。
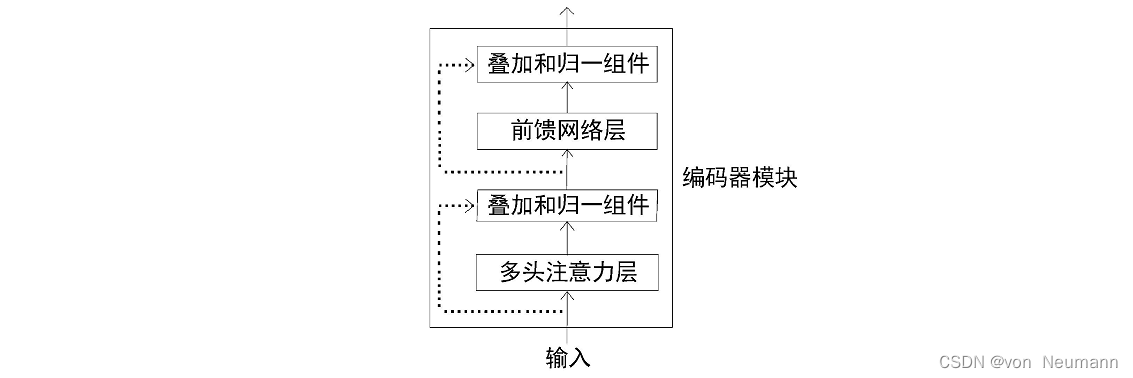
叠加和归一组件实际上包含一个残差连接与层的归一化。层的归一化可以防止每层的值剧烈变化,从而提高了模型的训练速度。
综上所述,我们将编码器1展开可以得到如下图所示结构:
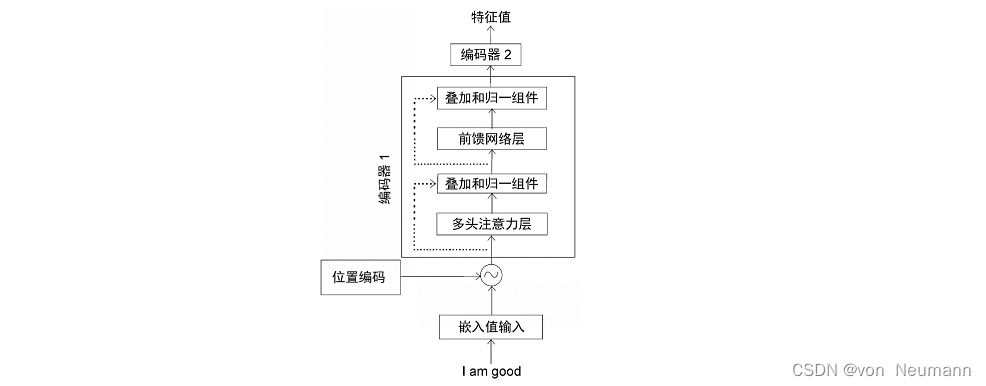
从上图中我们可以总结出以下几点:
- 将输入转换为嵌入矩阵(输入矩阵),并将位置编码加入其中,再将结果作为输入传入底层的编码器(编码器1)。
- 编码器1接受输入并将其送入多头注意力层,该子层运算后输出注意力矩阵。
- 将注意力矩阵输入到下一个子层,即前馈网络层。前馈网络层将注意力矩阵作为输入,并计算出特征值作为输出。
- 把从编码器1中得到的输出作为输入,传入下一个编码器(编码器2)。
- 编码器2进行同样的处理,再将给定输入句子的特征值作为输出。
这样可以将 N N N个编码器一个接一个地叠加起来。从最后一个编码器(顶层的编码器)得到的输出将是给定输入句子的特征值。让我们把从最后一个编码器(在本例中是编码器2)得到的特征值表示为 R R R。我们把 R R R作为输入传给解码器。解码器将基于这个输入生成目标句,这也是Transformer的编码器部分。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023