一Hive 库的基本操作
1.1 建库
1.默认路径是/user/hive/warehouse
 例如 我输入命令 create database text1
例如 我输入命令 create database text1
则text1出现在 warehouse目录下

2.指定位置创建数据库
create database text2 location '/bigdata29/bigdata29db'
后面的路径是hdfs的路径

3.最终写法
加上if not exists 可以判断该数据库存不存在
create database if not exists bigdata29_test1 location '/bigdata29/huangdadadb';

1.2 修改数据库
1.一般创建好的数据库都不会去修改数据库,如果要修改数据库也是修改创建的时间
alter database dept set dbproperties('createtime'='20220531');
1.3 数据库详细信息
1.3.1 显示数据库
1.show databases;
1.3.2 可以通过like进行过滤
show databases like 't*';
1.3.3 查看详情
desc database 数据库名;
1.3.4 切换数据库
use 数据库名;
1.3.5 删除数据库
drop database if exists 数据库名;
如果数据库不为空,使用cascade命令进行强制删除。报错信息如下FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)
drop database if exists 数据库名 cascade;
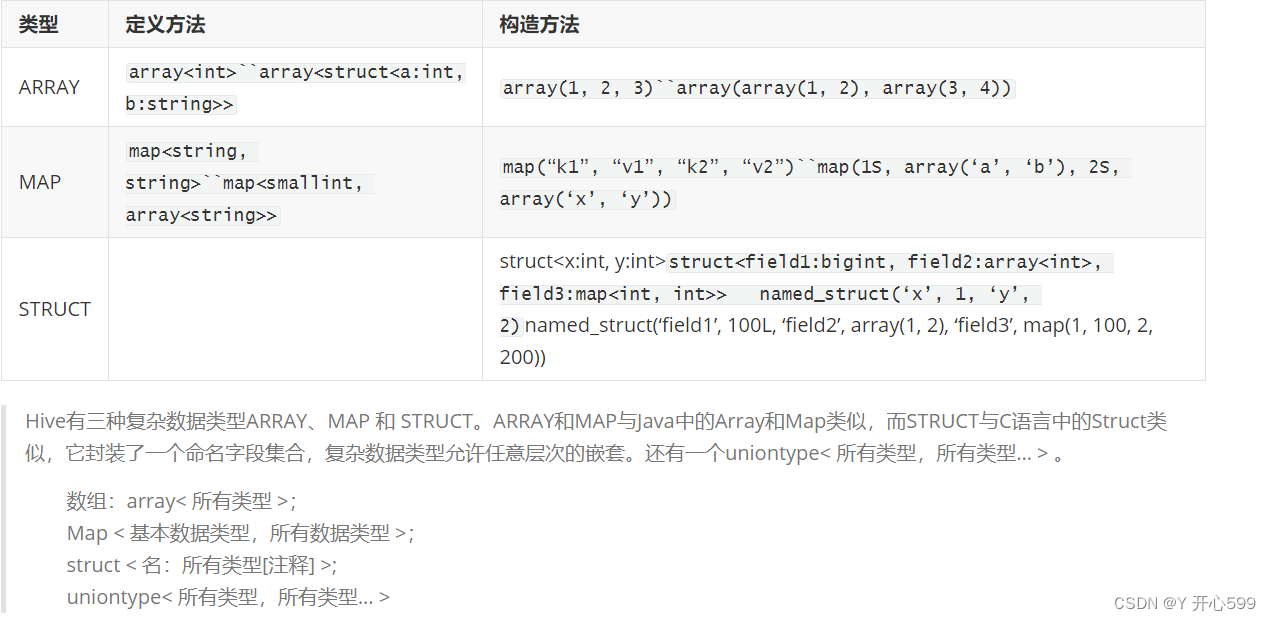
二 Hive的数据类型
2.1 基本数据类型

2.2 复杂数据类型
三 Hive 表的基本操作
3.1 默认建表
1.简单数据
create table IF NOT EXISTS 表名
(
数据名 数据类型
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; --> 以逗号做为分隔符
2.复杂数据
create table IF NOT EXISTS t_person(
name string,
friends array<string>,
children map<string,int>,
address struct<street:string ,city:string>
)
row format delimited fields terminated by ',' -- 列与列之间的分隔符
collection items terminated by '_' -- 元素与元素之间分隔符
map keys terminated by ':' -- Map数据类型键与值之间的分隔符
lines terminated by '\n'; -- 行与行之间的换行符
3.2 指定存储格式
3.2.1 相关文件格式

平时学习用TextFile,工作使用orc
 3.2.2建表语法
3.2.2建表语法
create table IF NOT EXISTS 表名
(
id bigint,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS ORC -->存储文件的格式
3.3 查询结果作为表
1.表没有的情况下
create table 表名 as 查询语句;
2.有表的情况下 添加数据
insert into 表名 查询语句;
3.4 模仿其他表的结构
create table 表名 like 已经存在的表名;
3.5 显示表
show tables;
show tables like 'u*';
desc t_person;
desc formatted students; // 更加详细
3.6 加载数据
3.6.1 使用hdfs的put或者cp命令
1.将linux文件使用 put的命令放在 hive表对应的HDFS目录下
例如:
hadoop fs -put ./students.csv /bigdata29/bigdata29db/students/

2.如果hdfs中 有数据的文件,那么将这个文件复制一份到 hive表对应的hdfs目录下
例如:
hadoop fs -cp /bigdata29/students.csv /bigdata29/bigdata29db/students/
3.6.2 location 或者是load data
1.location 这个是创建表的时候后面加的数据。(先有数据后有表)
例如 create table IF NOT EXISTS students3
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/bigdata29/shuju/';
主要保证data目录下只能有一个数据
这个表存储在shuju目录下

2.location 这个是先创建表的时候后面添加数据。(先有表后有数据)
create table IF NOT EXISTS students4(id bigint,name string,age int,gender string,clazz string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/bigdata29/aaa/bbb/ccc';
先在/bigdata29/aaa/bbb/ccc这个目录下创建一个表 再将数据放到这个目录下

3.load data 这个是移动hdfs中文件
先创建一个新表 不加location的话默认在创建数据库的那个目录下
create table IF NOT EXISTS students5
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
再输入 load data inpath '/bigdata29/data/students.csv' into table students5;即可
但是bigdata29/data/students.csv文件没有了
4.load data local 是上传Linux的文件
create table IF NOT EXISTS students6
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
再输入 load data local inpath '/usr/local/soft/bigdata29/students.csv' into table students5;
这里的文件不会消失
into 改成 overwrite就是覆盖
3.6.2 查询语句加载数据
1.表没有的情况下
create table 表名 as 查询语句;
2.有表的情况下 添加数据
insert into 表名 查询语句;
3.6.3普通的插入
insert into 表名 values ('数据');
3.7 修改表
3.7.1 添加列
alter table 表名 add columns (数据名 数据类型);
3.7.2修改列名或者数据类型
alter table 表名 change 之前的数据名 更改过后的数据名 数据类型;
四 内外部表
4.1内部表
1.我们默认创建的就是内部表
2.当设置表路径的时候,如果直接指向一个已有的路径,可以直接去使用文件夹中的数据
当load数据的时候,就会将数据文件存放到表对应的文件夹中
而且数据一旦被load,就不能被修改
我们查询数据也是查询文件中的文件,这些数据最终都会存放到HDFS
当我们删除表的时候,表对应的文件夹会被删除,同时数据也会被删除
4.2外部表
1.创建表的时候加个关键字
create external table 表名
2.一般用的外部表比较多
3.外部表因为是指定其他的hdfs路径的数据加载到表中来,所以hive会认为自己不完全独占这份数据
4.删除hive表的时候,数据仍然保存在hdfs中,不会删除。
五 导出数据
5.1 放入Linux中
1.insert overwrite local directory 'Linux路径' 查询语句;
例如:
insert overwrite local directory '/usr/local/soft/bigdata29/person_data' select * from t_person;
2.按照指定的方式将数据输出到本地
insert overwrite local directory '/usr/local/soft/shujia/person'
ROW FORMAT DELIMITED fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
lines terminated by '\n'
select * from t_person;
5.2 放入hdfs中
1.insert overwrite directory 'hdfs路径' 查询语句;
2.export table t_person to 'hdfs路径';,但是这个路径提前存在
六 Hive的分区
6.1静态分区 SP
借助于物理的文件夹分区,实现快速检索的目的。
一般对于查询比较频繁的列设置为分区列。
分区查询的时候直接把对应分区中所有数据放到对应的文件夹中。
6.1.1 单分区
1.创建表语法:
CREATE TABLE IF NOT EXISTS t_student (
sno int,
sname string
) partitioned by(grade int)
row format delimited fields terminated by ',';
2.加载数据
先数据在Linux创建文件,再上传到hdfs的表目录下
load data local inpath '/usr/local/soft/bigdata29/grade2.txt' into table t_student partition(grade=2);
3.加载数据的时候一定要把分区要确定好,不能不是这个分区的内容加入到这个分区里面
6.1.2 多分区
1.创建表语法
CREATE TABLE IF NOT EXISTS t_teacher (
tno int,
tname string
) partitioned by(grade int,clazz int)
row format delimited fields terminated by ',';
2.加载数据
在Linux创建数据文件,再上传到hdfs的表目录下
load data local inpath '/usr/local/soft/bigdata29/grade22.txt' into table t_teacher partition(grade=2,clazz=2);
3.分区的字段不能少于2个,比如说男生女生就没必要分区了
6.1.3 查看分区
show partitions 表名r;
6.1.4 添加分区
alter table 表名 add partition (字段名);
alter table 表名 add partition (字段名) location '指定数据文件的路径';
例如:
alter table t_teacher add partition (grade=3,clazz=1) location '/user/hive/warehouse/bigdata29.db/t_teacher/grade=3/clazz=1';
6.1.5 删除分区
alter table 表名 drop partition (字段名);
6.2 动态分区
-
动态分区(DP)dynamic partition
-
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。
-
详细来说,静态分区的列是在编译时期通过用户传递来决定的;动态分区只有在SQL执行时才能决定。
6.2.1 开启动态分区
1.先创建分区表
CREATE TABLE IF NOT EXISTS t_student_d (
sno int,
sname string
) partitioned by (grade int,clazz int)
row format delimited fields terminated by ',';
2.创建原始数据表(外部)
CREATE EXTERNAL TABLE IF NOT EXISTS t_student_e (
sno int,
sname string,
grade int,
clazz int
)
row format delimited fields terminated by ','
location "/bigdata29/teachers";
3.在本地创建文件 然后将数据导入t_student_e表中
4.insert overwrite table t_student_d partition (grade,clazz) select * from t_student_e;
6.3 分区的优缺点
1.优点:
避免全盘扫描,加快查询速度
2.缺点
可能产生大量小文件
数据倾斜问题
七 Hive分桶
7.1 概念
数据分桶的适用场景: 分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可形成合理的分区,尤其是需要确定合适大小的分区划分方式 不合理的数据分区划分方式可能导致有的分区数据过多,而某些分区没有什么数据的尴尬情况 分桶是将数据集分解为更容易管理的若干部分的另一种技术。 分桶就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去。(都各不相同)
7.2 原理
Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
-
bucket num = hash_function(bucketing_column) mod num_buckets
-
列的值做哈希取余 决定数据应该存储到哪个桶
7.3 作用
方便抽样
使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便
提高join查询效率
获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
7.4 实例
1.先创建数据
2.创建普通的表
create table person
(
id int,
name string,
age int
)
row format delimited
fields terminated by ',';
3.加载数据到普通的表中
4.创建分桶表
create table psn_bucket
(
id int,
name string,
age int
)
clustered by(age) into 4 buckets
row format delimited fields terminated by ',';
这里使用clustered by对表中的列名分桶,后面的4表示分成4个
5.将数据加载到分桶表中
insert into psn_bucket select * from person;
后面是普通表的查询语句
7.5 分桶于分区的区别
1.分区用的是partitioned by 关键字声明的,分桶是clustered by 和into buckets 分成几个桶的关键字声明的
2.分区的在hdfs上面表示的是一个文件夹,分桶表示的是一个文件
3.分区的依据是通过指定分区的字段的值来进行分区的,分桶是指定分桶的字段的哈希值除以桶的个数取余来进行分桶的
八 Idea连接Hive
package com.shujia.jcbc;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;public class JcbcHive {public static void main(String[] args) throws Exception {//加载驱动Class.forName("org.apache.hive.jdbc.HiveDriver");//创建与hive的连接对象Connection conn = DriverManager.getConnection("jdbc:hive2://master:10000/bigdata29");//创建操作hive的对象Statement state = conn.createStatement();ResultSet resultSet = state.executeQuery("select * from emp ");while (resultSet.next()){String empno = resultSet.getString(1);String hiredate = resultSet.getString(2);String sal = resultSet.getString(3);String deptno = resultSet.getString(4);System.out.println(empno+", "+hiredate+", "+sal+", "+deptno);}//释放资源conn.close();}
}




![[BT]BUUCTF刷题第14天(4.10)](https://img-blog.csdnimg.cn/direct/d412f42d241a46eba7eacefef7593b4b.png)