正则表达式(regular expression):
为什么使用正则表达式:
在软件开发过程中,经常会涉及到大量的关键字等各种字符串的操作,使用正则表达式能很大程度的简化开发的复杂度和开发的效率,所以python中正则表达式在字符串的查询匹配中,占据很重要的地位
'compile', 'copyreg', 'enum', 'error', 'escape', 'findall', 'finditer', 'fullmatch', 'functools', 'match', 'purge', 'search', 'split', 'sub', 'subn', 'template'
python中的re
该模块是pyhton用来支持正则表达式模块,所以我们如需写正则表达式,必须学习该模块
正则表达式的使用:
元字符:
. #匹配任意符号(\n也就是换行符不匹配)
\w #匹配有效符号
\d #匹配数字
\s #匹配空白位(空格,\t, \n ,\r)
^ #以什么开头
$ #以什么结尾
[ ] #列举中括号中的某一符号
[123456abc_]
[0123456789]
[0-9]
[a-z]
[0-9a-zA-Z]

>>> import re
>>>
>>> re.match("zhangbaoning", "zhangbaoning")
<re.Match object; span=(0, 12), match='zhangbaoning'>
>>> re.match("zhangbaoning", "zhangbaoning is good")
<re.Match object; span=(0, 12), match='zhangbaoning'>
>>> re.match(".", "zhangbaoning is good")
<re.Match object; span=(0, 1), match='z'>
>>> re.match(".", "Azhangbaoning is good")
<re.Match object; span=(0, 1), match='A'>
>>> re.match(".", "5Azhangbaoning is good")
<re.Match object; span=(0, 1), match='5'>
>>> re.match(".", "中国5Azhangbaoning is good")
<re.Match object; span=(0, 1), match='中'>
>>> re.match(".", "\r中国5Azhangbaoning is good")
<re.Match object; span=(0, 1), match='\r'>
>>> re.match(".", "\t\r中国5Azhangbaoning is good")
<re.Match object; span=(0, 1), match='\t'>
>>> re.match(".", "+\t\r中国5Azhangbaoning is good")
<re.Match object; span=(0, 1), match='+'>
>>>
>>>
>>>
>>> re.match("\w", "a")
<re.Match object; span=(0, 1), match='a'>
>>> re.match("\w", "A")<re.Match object; span=(0, 1), match='A'>
>>> re.match("\w", "456")<re.Match object; span=(0, 1), match='4'>
>>> re.match("\w", "_")<re.Match object; span=(0, 1), match='_'>
>>> re.match("\w", "_456")<re.Match object; span=(0, 1), match='_'>
>>> re.match("\w", "+_456")>>> re.match("\w", "中+_456")<re.Match object; span=(0, 1), match='中'>
>>>
>>>
>>>
>>> 中 = 10
>>> print(中)
10
>>> re.match("\d\d", "1assd24")>>> #re.match("\d\d", "1assd24") ==>match是从头匹配
>>> re.match("\d\d", "10assd24")<re.Match object; span=(0, 2), match='10'>
>>> re.match("\s\s", " ifyf")<re.Match object; span=(0, 2), match=' '>
>>> re.match("\s\s", " \tifyf")<re.Match object; span=(0, 2), match=' \t'>
>>> re.match("\s\s", " \n\tifyf")<re.Match object; span=(0, 2), match=' \n'>
>>> re.match("\s\s", "\n\tifyf")<re.Match object; span=(0, 2), match='\n\t'>
>>> re.match("\s\s", "\r\n\tifyf")<re.Match object; span=(0, 2), match='\r\n'>
>>>
>>>
>>>
>>>
>>> re.match("^\d\d\w", "23a is")<re.Match object; span=(0, 3), match='23a'>
>>> re.match("\d\d\w", "23a is")<re.Match object; span=(0, 3), match='23a'>
>>>
>>> re.findall("\d+", "我今年16岁,是一个花季少女,我静静的等着18岁")
['16', '18']
>>> re.findall("^\d+", "我今年16岁,是一个花季少女,我静静的等着18岁")
[]
>>> re.findall("^\d+", "123456我今年16岁,是一个花季少女,我静静的等着18岁")
['123456']
>>> re.findall(".*", "123456我今年16岁,是一个花季少女,我静静的等着18岁")
['123456我今年16岁,是一个花季少女,我静静的等着18岁', '']
>>> re.findall(".*\d$", "123456我今年16岁,是一个花季少女,我静静的等着18岁")
[]
>>> re.findall(".*\d$", "123456我今年16岁,是一个花季少女,我静静的等着18")
['123456我今年16岁,是一个花季少女,我静静的等着18']
>>> re.findall("^\d.*\d$", "123456我今年16岁,是一个花季少女,我静静的等着18")['123456我今年16岁,是一个花季少女,我静静的等着18']
>>> re.match("\d[abc].*","238sadfdgfrgrs")
>>> re.match("\d[abc].*","2sadfdgfrgrs")>>> re.match("\d[abc].*","2caadfdgfrgrs")
<re.Match object; span=(0, 13), match='2caadfdgfrgrs'>>>> re.match("[0123456789]", "5")
<re.Match object; span=(0, 1), match='5'>
>>> re.match("[a-z]", "d")
<re.Match object; span=(0, 1), match='d'>
>>> re.match("[0-9]", "8")
<re.Match object; span=(0, 1), match='8'>
>>> re.match("[0-9A-Za-z_]", "8")
<re.Match object; span=(0, 1), match='8'>
>>> re.match("[0-9A-Za-z_]", "_")
<re.Match object; span=(0, 1), match='_'>
>>> re.match("[0-9A-Za-z_]", "t")
<re.Match object; span=(0, 1), match='t'>
>>> re.match("[0-9A-Za-z_]", "W")
<re.Match object; span=(0, 1), match='W'>反义符:
\w #特殊符号
\D #非数字
\S #非空白位
[^] #非列举,和[ ]正好相反

>>> re.match("\D","A10086")
<re.Match object; span=(0, 1), match='A'>
>>> re.match("\D","a10086")
<re.Match object; span=(0, 1), match='a'>
>>> re.match("\w","a10086")
<re.Match object; span=(0, 1), match='a'>
>>> re.match("\s","a10086")
>>> re.match("\S","a10086")
<re.Match object; span=(0, 1), match='a'>>>> re.findall("^\d.*", "ladohig")
[]
>>> re.findall("^\d.*", "1adohig")
['1adohig']
>>> re.findall("^[0-9].*", "1adohig")
['1adohig']
>>> re.findall("[^0-9].*", "1adohig")
['adohig']
>>> re.findall("[^abcd].*", "a1adohig")
['1adohig']
转义符:
>>> print("\n123")123
>>> print("\\n123")
\n123
>>> url = "d:\\a\\d\\c.txt"
>>> print(url)
d:\a\d\c.txt
>>>>>> re.match("c:\\\\a\\\\d\\\\c.txt", url)
>>> re.match(r"c:\\a\\d\\c.txt", url)
>>> # re.match(r"c:\\a\\d\\c.txt", url) 加r,表示正则表达式
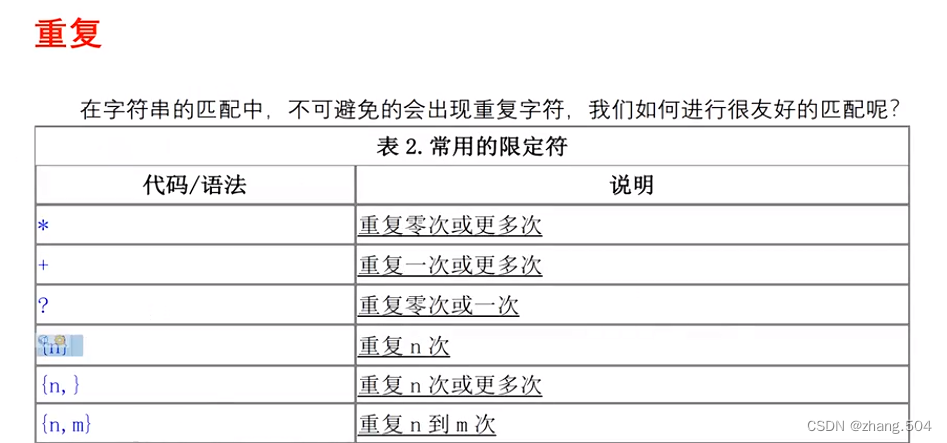
位数问题:
* #匹配任何位(0到多位)
+ #匹配1到多位
? #匹配0或者1位
{n} #确切的有n位
{m,n} #[m,n]区间内的任意值
{n,} # >= n
>>> #位数问题:
>>>
>>>
>>> re.findall("\d+", "我今年16岁,是一个花季少女,我静静的等着18岁")
['16', '18']
>>> re.findall("\d*", "我今年16岁,是一个花季少女,我静静的等着18岁")
['', '', '', '16', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '18', '', '']
>>> re.findall("\d*", "我今年16岁,是一个花季少女,我静静的等着18岁")
['', '', '', '16', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '18', '', '']
>>>
>>>
>>>
>>>
>>> re.findall(r"1[3456789]\d{9}", "18709319726")
['18709319726']
>>> re.findall(r"1[3456789]\d{9}", "18709319726564886165jkgukgi136986155464")
['18709319726', '13698615546']
>>>
>>> [a-zA-Z_0-9]{4,20}@openlab\.comFile "<stdin>", line 1[a-zA-Z_0-9]{4,20}@openlab\.com^
SyntaxError: unexpected character after line continuation character
>>> re.match(r"[a-zA-Z_0-9]{4,20}@openlab\.com", "zhangbaoning@openlab.com")
<re.Match object; span=(0, 24), match='zhangbaoning@openlab.com'>
>>> re.match(r"[a-zA-Z_0-9]{4,20}@openlab.com", "zhangbaoning@openlabacom")
<re.Match object; span=(0, 24), match='zhangbaoning@openlabacom'>
>>>