本次讲解一下于2020年发表在IEEE TRANSACTIONS ON NEURAL SYSTEMS AND REHABILITATION ENGINEERING上的专门处理EEG信号的EEG-Inception模型,该模型与EEGNet、EEG-ITNet、EEGNex、EEGFBCNet等模型均是专门处理EEG的SOTA。

我看到有很多同学刚入门,不太会看EEG的SCI论文,我这里简单说一下:
网页打开Pubmed,然后打上关键词 EEG CNN 然后呈现的都是诸如此类的文章,但文章水平有高有低,建议打上pubmed的插件,能显示期刊IF,建议只看3区以上的文章,好了,现在我们拿到一篇文章,使用ML/DL处理EEG/PPG/EMG的,然后我们需要关注的有:
论文关注点:
1、设计了**模型,提高了BCI ** 的任务的分类/预测的性能
2、数据选择与处理方式
3、模型是如何设计的、为何这样设计
4、本文模型与其他模型在多个数据上对比,提高了多少
5、模型可靠性评估方式
6、结论与意义
本科生来问我我理解,我会耐心教授他如何读文章,但是硕士来问我我一般不会有好脸色,都读研了,甚至研二了,自己研究方向的论文都不会看(还有的找都不会找),还能做什么?有些同学就等着喂,这种同学我该批评就批评,不批评是进步不了的。老师不管是正常的,这不是借口,这样的同学给我的感觉就是读幼儿园的小孩子,这么大的人了,学习还要一勺一勺喂,我也不是你硕导,我更没这责任和必要在如何读论文上一步步教你哇!人的精力都是有限的,每天还有很多同学微信问我技术问题的。现在都联网了,哪里不会,你可以直接查啊,比如我上面说的pubmed插件,一定还会有同学来问我,需要哪些插件,你知乎一搜答案多的是....心累。有些读研的同学,自学能力我感觉不如一些本科生都。批评该批评,你要是问我某论文的细节问题,那说明你学进去了,来问我我看到了肯定答疑。下面我们看文章,我会列出我读这个文章的重点标记:
Abstract:
近年来,深度学习模型因其优异的性能和从原始数据中提取复杂特征的能力而受到脑电图(EEG)分类任务的关注。特别是卷积神经网络(CNN)在基于事件相关电位(ERP)等不同控制信号的脑机接口(BCI)中表现出了良好的结果。在这项研究中,我们提出了一种新的CNN,称为EEG-Inception,它提高了基于erp的辅助脑机接口的准确性和校准时间。据我们所知,EEGInception是第一个集成了用于ERP检测的Inception模块的模型,它与轻量级架构中的其他结构有效地结合在一起,提高了我们方法的性能。该模型在73名受试者中得到验证,其中31人有运动障碍。
结果表明,与rLDA、xDAWN +黎曼几何、CNN-BLSTM、DeepConvNet和EEGNet相比,EEG-Inception的命令解码准确率分别提高了16.0%、10.7%、7.2%、5.7%和5.1%,优于之前的5种方法。此外,EEG-Inception需要很少的校准试验来实现最先进的性能。

INTRODUCTION:
没啥说的,简要概述前几十年人们使用ML处理EEG的历程和不足。我们直接看最后一段:
本研究的主要目标是设计、开发和测试一种新颖的CNN,以提高基于erp的拼写器的准确性和校准时间。为此,我们的模型,称为EEG-Inception,有效地集成了Inception模块和其他针对EEG处理优化的结构。此外,本研究使用的数据集共有73名受试者(42名对照,31名重度残疾人)的701615项观察结果,是相关研究中样本量最大的。利用该数据集,我们设计了一种新的训练策略,使用跨主题迁移学习和微调来减少测试对象所需的校准时间。最后,我们对基于erp的拼写器中最成功的先前方法进行了直接和公平的比较。值得注意的是,大多数研究都没有对严重残疾受试者(这些系统的最终用户)的新分类算法进行评估。这是脑机接口文献中常见的局限性,可能是由于缺乏残疾受试者的公共数据集[30]。为了解决这个问题,我们在http://dx.doi.org/10.21227/6bdr-4w65[31]中发布了本研究中使用的代码和数据库,为基于erp的拼写器提供了一个新的公共基准。

读到这我们知道了,创新了个模型叫EEG-Inception,用于提高ERP的准确性的,并设计了一种新的训练策略,使用跨被试的迁移学习和微调来减少测试所需的校准时间,代码开源了(啥?没说这模型好不好?肯定好,不好也要好,不然他发不了论文)
RELATED WORK:
本节概述了先前的研究,这些研究提出了在脑机接口框架中进行ERP检测的深度学习模型[22]-[28]。表1总结了这些方法,突出了它们的主要贡献、评估方法、研究对象和结果。可以看出,cnn是最受欢迎的方法。其中,Lawhern等人[26]提出的EEGNet模型是最成功的模型之一,它使用深度和可分离卷积来提供鲁棒和紧凑的架构。事实上,这个模型赢得了ERP检测发起的科学挑战
由国际医学与生物工程联合会(IFMBE)于2019年颁发[32]。值得注意的是,第二名是由另一个深度学习模型CNNBLSTM取得的,该模型结合了一个卷积层提取空间模式和基于双向长短期记忆单元(bidirectional long-short term memory units, BLSTM)的2个循环层来学习时间模式[28]。rnn在EEG处理中的应用很少,尤其是在ERP检测中[14]。这可能是因为这些架构在计算方面非常昂贵,比cnn的训练时间要长得多。然而,rnn是专门为处理时间序列而设计的,这使得它们成为cnn处理EEG的一个有希望的替代方案
值得注意的是,据我们所知,之前的研究未能在运动障碍受试者身上测试他们的深度学习模型。Liu等[25]、Cecotti和Gräser[22]分别只纳入了2名和3名健康受试者。在这方面,众所周知,由于与患者疾病相关的个别方面,如神经损伤、视力障碍、持续注意能力有限、不自主震颤或认知能力有限等,患者的分类准确率通常较低[9],[10]。此外,这些症状在个体之间是高度可变的,甚至在具有相同条件的人之间也是如此,这使得严重残疾的受试者尤其具有异质性,对ERP检测具有挑战性。因此,需要对该组进行综合评估,以评估用于辅助脑机接口应用的新模型的性能。


本节列举了之前使用CNN处理ERP的模型,重点点出了EEGNet,对其给予高度的评价:最成功的Model,是里程碑
Subjects and Signals:
数据做了简单的预处理,没有自己弄些公式设计特征作为输入,预处理有:

降采样至128Hz,带通滤波0.5-45,工频滤波50Hz,共同平均参考CAR、提取1s的epoch
Novel CNN: EEG-Inception:
我们来看下模型结构,我先列出我读到这里的标记:




首先要关注的是模型需要注意的地方Note:每层Conv2D = torch.nn.Conv2d+BN+RELU+Drop,并不仅仅代表一层二维卷积!,下面我们看模型图和结构图:
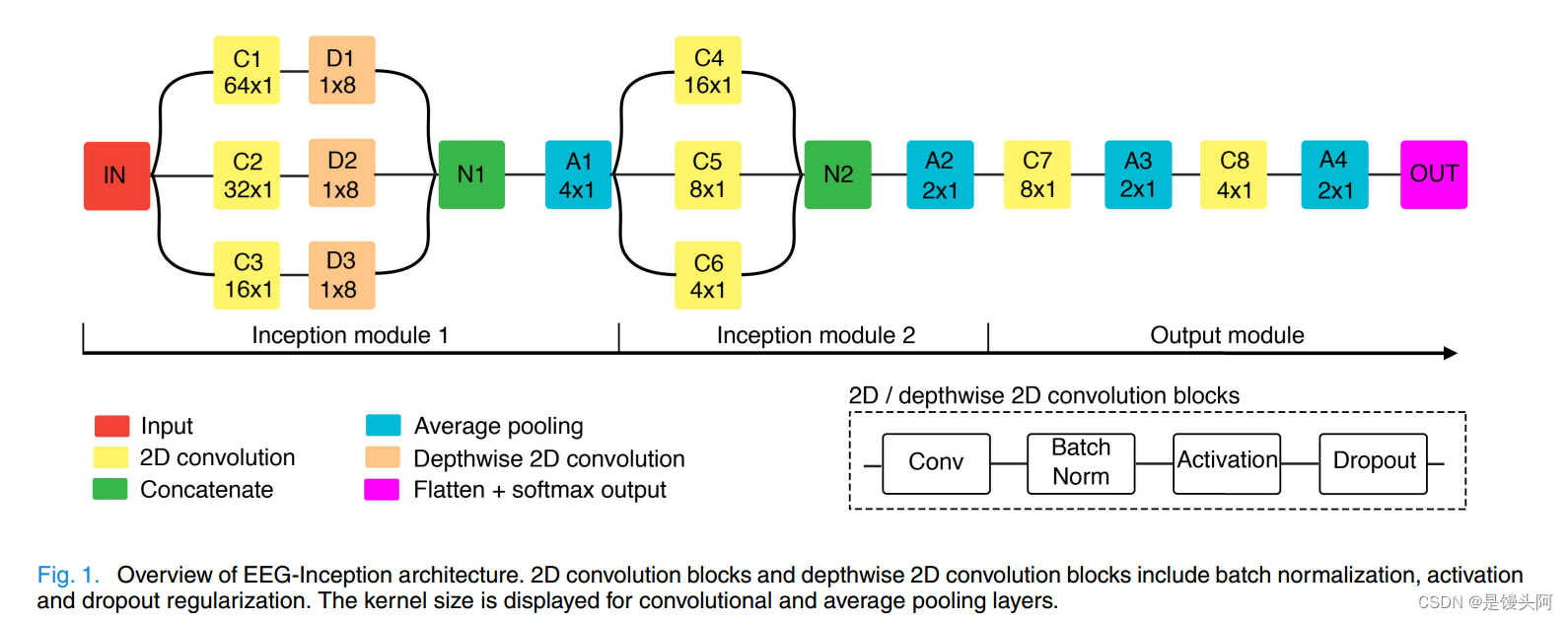
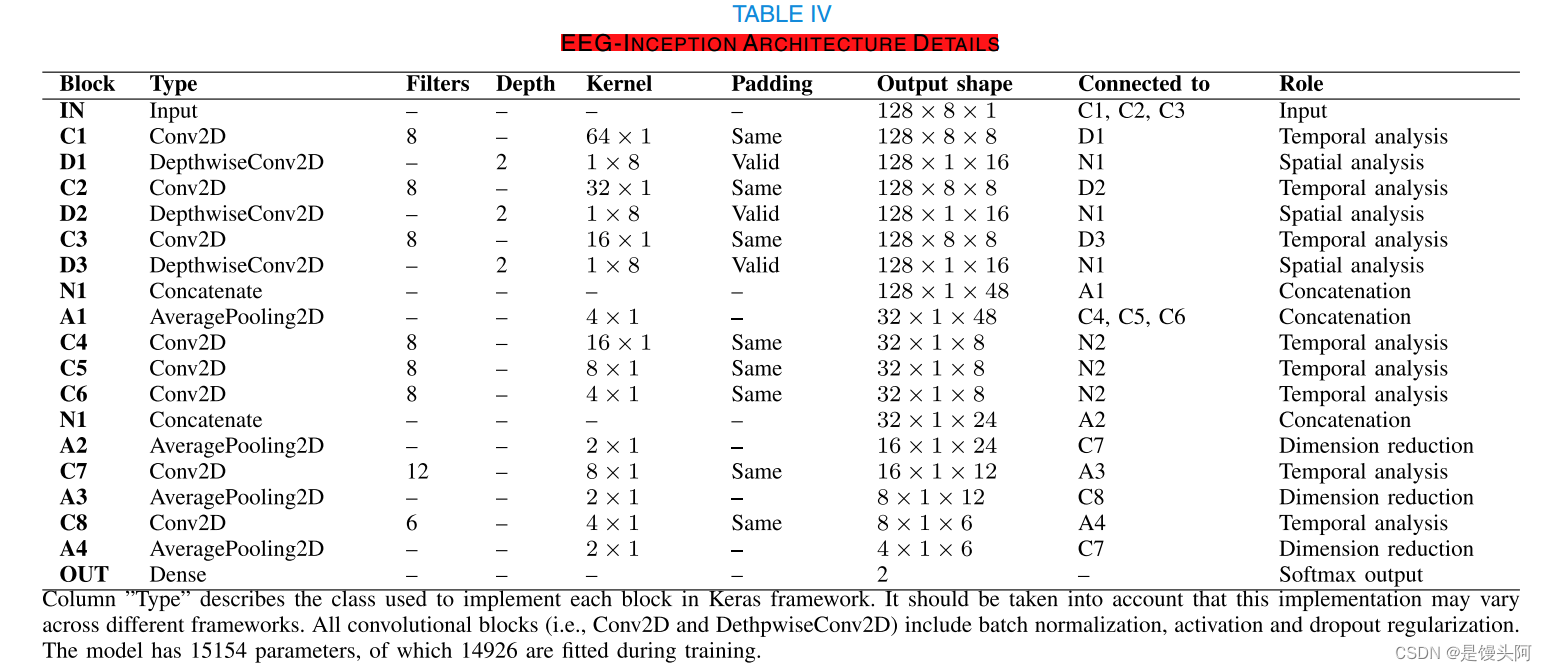
其实只要看结构图就可以了,足够详细了,我也自己重新画了整个模型结构,下面使用我自己画的图进行讲解,重点就在模型是咋设计的,对我们有啥启发:
模型结构设计:[还是按照EEGNet的三个Block设计的,我和你说了多少遍了,设计创新模型,主体框架就要按照EEGNet的3个block设计,这就是模型房子的大梁!你可以设计4个block,但最少不低于3个,这是通往SOTA的康庄大道!]
输入=(128,8,1):128hz采样率 = 1s的数据,8个通道,又扩出一个维度为1
一、Block-1
第一个block交叉提取时间、空间特征信息,顺序为:
1、先时间卷积:时间卷积核(A,1)的设计与采样率密切相关(核为采样率128的几分之几,则时间尺寸为整个时间尺寸的几分之几,例:卷积核设计为(64,1),则在500ms的尺寸上提取特征)
2、后空间卷积:EEG-Inception在block1中多次提取,空间卷积核大小(1,B) = Channel

Block-1结构图,盗图必究
Block-1解析:
对8个通道,1000ms=128的数据逐级提取特征
1、先时间、后空间
2、时间卷积、空间卷积堆叠使用
3、时间卷积核提取3个不同时间尺寸(500ms、250ms、125ms,分别对应64、32、16卷积核大小)长度的特征,空间卷积核都是8=channel
4、时间卷积padding=same,空间卷积padding=valid
5、滤波器:
3层时间卷积都是8(这里我思考是与原始EEG通道有关,我们在设计滤波器时也可以参照)
3层深度卷积深度都是2,把前一层的Conv2D滤波器数量*2加倍
6、时间卷积Conv2D = torch.nn.Conv2d+BN+RELU+Drop
7、N1把三个空间卷积的输出合并,此时输出 = ·128*1*48(每层空间卷积输出=128*1*16)
8、平均二维池化:降维,核=4*1,与下个block的时间卷积核大小设置有关,下个block若要提取时间特征【提取空间特征核大小还是不变】,则提取同一时间尺寸核大小缩小4倍(负相关)
此时经过池化后的shape=32*1*48
二、Block-2
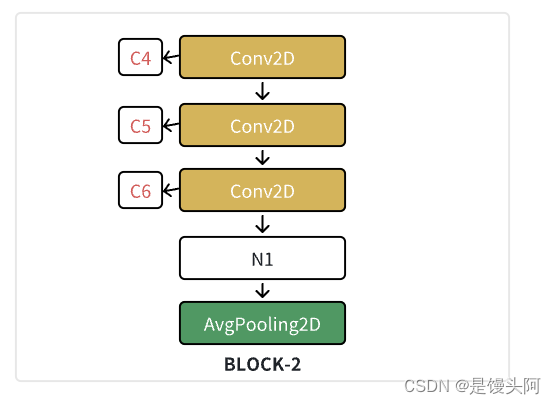
Block-2结构图,盗图必究
Block-2解析:
一、3个时间卷积(C4、C5、C6)通过堆叠的方式,在更高的、抽象的层次上提取额外的、更加精细化的500ms、250ms、125ms三个时间尺度的时间信息,因为上个block的平均池化=4*1,所以这三层卷积相较于block-1的三个时间卷积核大小分别除以4
二、卷积填充 = same,F=8=channel,核大小分别为16*1,8*1,4*1 每层卷积出来的shape相同=32*1*8
三、N1合并三次时间特征信息 = 32*1*24
四、池化 = 2*1(依旧是偶数,成倍的增加/减小)= 16*1*24
三、Block-3
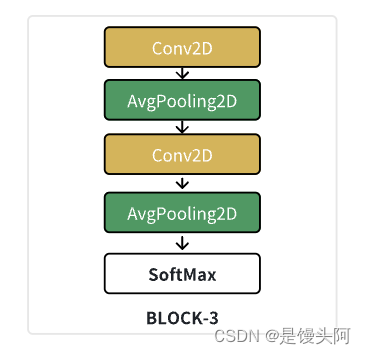
Block-3解析:
1、使用2层二维卷积提取最有价值的特征用于分类(这里就不是提取时间、空间特征了,而是在已经提取的特征上提选取有利于分类的特征,纯粹是提取特征的,没有时间、空间相关性),卷积核大小分别=8*1,4*1
2、二维卷积和二维池化交叉使用,2层池化核大小都是2*1,进一步降维作用
3、两层卷积的滤波器大小分别为F = 12、F = 6,F逐渐减小,起到了和池化一样降维的作用,并避免过拟合(这里前面F一直=8,其实也就是经历了8-12-6的起伏,也符合滤波器的倒瓶颈先进的结构)
EEG-Inception:
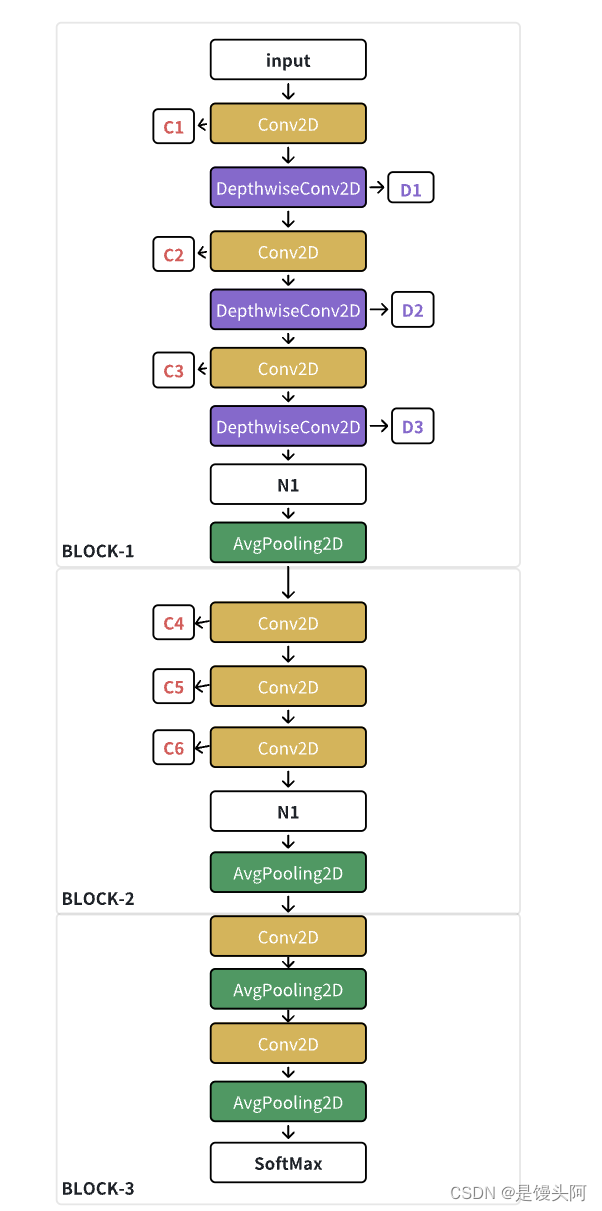
EEG-Inception结构图,盗图必究
剩下的就是实验对比和总结了,基本大差不差,不说了