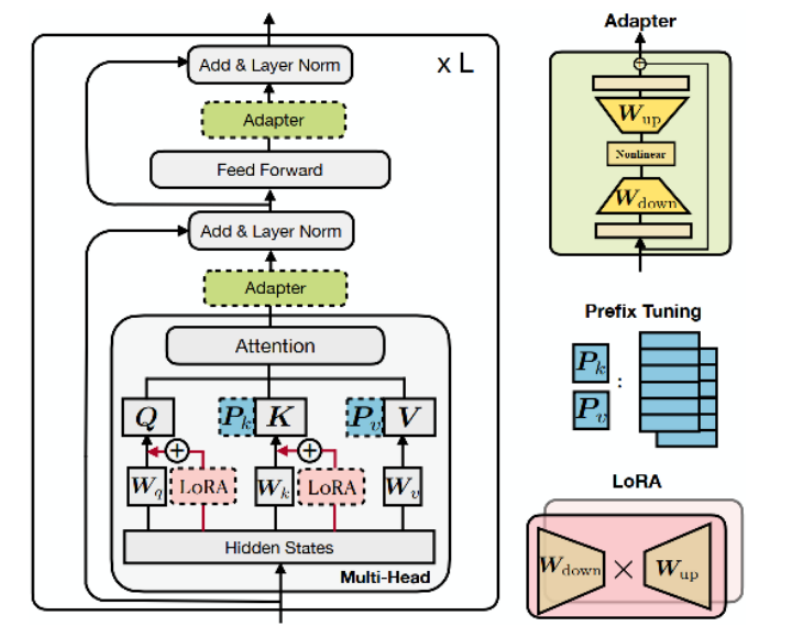
一、选题背景与意义
1.国内外研究现状
国外研究现状:
- 亚马逊(Amazon):作为全球最大的电商平台之一,亚马逊在数据挖掘和大数据方面具有丰富的经验。他们利用Spark等大数据技术,构建了一套完善的电商数据挖掘系统,通过对用户行为、商品销售等数据的分析,实现了个性化推荐、精准营销等功能。
- eBay:eBay也是一个在数据挖掘领域有所建树的电商平台。他们利用Spark等大数据技术,构建了一套强大的数据挖掘系统,通过分析用户购物行为、交易数据等,实现了对市场趋势的预测和用户行为的理解,并据此进行产品推荐和定价策略的优化。
国内研究现状:
- 阿里巴巴:作为中国最大的电商集团,阿里巴巴在大数据和数据挖掘方面有着丰富的经验。他们基于Spark等技术,构建了一系列针对电商数据挖掘的解决方案,包括用户画像、商品推荐、营销分析等,为电商企业提供了全方位的数据挖掘支持。
- 腾讯:腾讯也在电商数据挖掘领域有着自己的研究和实践。他们利用Spark等技术,构建了一套针对电商数据的挖掘系统,通过对用户行为、社交数据等的分析,实现了个性化推荐、社交化营销等功能。
综上所述,国内外在基于Spark的电商数据挖掘系统设计与实现方面都有着丰富的研究和实践经验。这些实例表明,利用Spark等大数据技术构建电商数据挖掘系统,可以为电商企业提供个性化推荐、精准营销、决策支持等方面的重要帮助,具有广阔的应用前景和市场潜力。
2.选题的目的及意义
- 提高电商企业竞争力:通过构建基于Spark的数据挖掘系统,可以对电商平台上的用户行为、商品销售、营销活动等数据进行全面的分析和挖掘。这样的系统可以帮助企业更好地了解用户需求、产品趋势和市场竞争态势,进而优化商品推荐、精准营销等策略,提高企业的竞争力。
- 实现智能化决策支持:通过对电商数据的深度挖掘和分析,可以得到更全面、准确的数据结果。在基于Spark的系统中,可以使用分布式计算和并行处理的优势,加快数据处理速度,实现实时决策支持。这对于电商企业来说非常重要,可以帮助企业快速反应市场变化,调整经营策略,提高决策效率。
- 推动电商行业发展:随着电商行业的快速发展,数据挖掘技术在电商领域的应用也日益重要。通过设计和实现基于Spark的电商数据挖掘系统,可以为电商行业提供一种可行的解决方案,并促进相关技术的发展和成熟。同时,该系统还可为其他领域的数据挖掘应用提供借鉴和参考,推动整个数据挖掘领域的发展。
二、研究内容与目标
具体研究内容
- 数据采集与清洗:设计有效的数据采集策略,从电商平台获取用户行为数据、商品销售数据、交易数据等多维度数据。对采集到的原始数据进行清洗和预处理,去除重复数据、异常数据和缺失数据,确保数据的准确性和完整性。
- 数据存储与管理:选择合适的大数据存储技术,如Hadoop HDFS或者Apache Cassandra等,搭建可扩展的数据存储系统。同时,利用Spark的数据处理能力,对数据进行分区、分片和索引,提高数据的读写效率和查询性能。
- 数据挖掘算法选择与应用:根据电商业务需求,选择适合的数据挖掘算法,如关联规则挖掘、聚类分析、分类算法、推荐系统等。基于Spark的机器学习库(如MLlib)或者深度学习框架(如TensorFlow、PyTorch),实现这些算法并应用于电商数据中。
- 用户画像与个性化推荐:通过分析用户行为数据,构建用户画像模型,了解用户的兴趣、购买习惯和需求。基于用户画像和商品特征,设计个性化推荐算法,为用户提供精准的商品推荐服务。
- 营销策略分析与优化:通过分析电商数据,了解用户参与活动的偏好、购买决策的因素等。针对不同的用户群体,设计营销策略,如优惠券发放、促销活动等,并通过实验和模型评估,优化营销策略的效果和ROI。
- 实时数据处理与监控:利用Spark Streaming技术,实现对实时数据的处理和分析。通过监控用户行为、交易数据等,及时发现异常情况和趋势变化,提醒相关部门采取相应的措施。
- 可视化与决策支持:基于Spark的数据可视化工具(如Apache Zeppelin或Tableau),将数据分析结果以图表、报表等形式展示出来,帮助企业管理层和决策者理解数据,并基于数据分析结果做出决策。
预期研究结果
- 数据挖掘系统的构建:通过使用Spark等大数据处理框架,构建一套适用于电商数据的挖掘系统。该系统应能够支持海量数据处理、分布式计算、实时数据分析等功能,并提供友好的用户界面和高效的数据可视化。
- 数据挖掘算法的实现:对电商数据进行深入分析和挖掘,实现对用户行为、商品销售、营销活动等方面的全面监控和分析。采用机器学习、深度学习等算法,对用户画像、商品推荐、营销策略等方面进行优化,提高电商企业的竞争力和市场份额。
- 智能化决策支持:通过对电商数据的全面分析和挖掘,实现对市场趋势、用户需求等方面的精准预测和分析,并据此提供智能化决策支持。该支持应具备实时性、准确性和可靠性,帮助电商企业快速反应市场变化,调整经营策略。
- 应用示范和推广:将设计和实现的电商数据挖掘系统应用于实际电商企业中,验证其有效性和实用性。同时,通过论文发表、技术报告等形式,推广该系统的应用和实践,促进电商数据挖掘领域的发展和成熟。
三、研究方法与手段
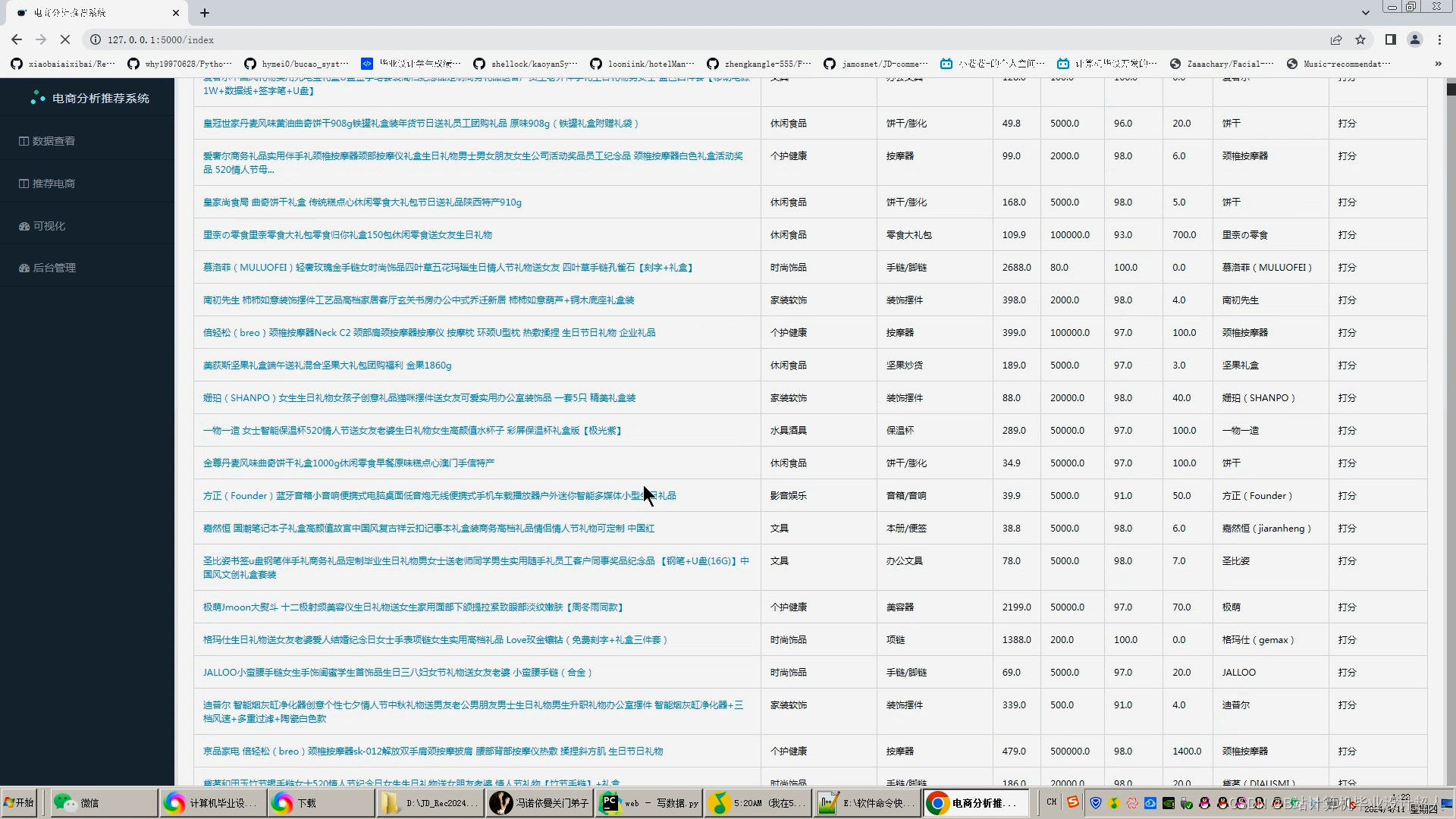
1.DrissionPage自动化爬虫框架采集天猫历史开源订单数据约1万亿条存入mysql数据库、.csv文件作为数据集(或使用开源数据集10TB大小);
2.使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs(含nlp情感分析);
3.使用hive数仓技术建表建库,导入.csv数据集;
4.离线分析采用hive_sql完成,实时分析利用Spark之Scala完成;
5.统计指标使用sqoop导入mysql数据库;
6.使用flask+echarts进行可视化大屏开发;
7.使用CNN、KNN卷积神经网络、TensorFlow、PyTorch、线性回归算法进行订单量预测;
四、参考文献
[1]田啸.大数据环境下计算机应用技术研究[J.]电脑知识与技术2022(14):246-247.
[2]侯聪聪.计算机软件技术在大数据时代的应用[J].电脑知识与技术2023(14):240-241.北京:清华大学出版社,2016.335-340
[3]于知言.计算机应用技术在大数据时代的运用前景研究[J].知识文库2021(15):107.
[4]李超科.计算机大数据分析及云计算网络技术发展探究[J].计算机产品与流通2020(11):12
[5]吴晓玲,邱珍珍.基于云存储架构的分布式大数据安全容错存储算法[J].中国电子科学研究院学报2022,13(6):720-724.
[6]张若愚.Python 科学计算[M].北京:清华大学出版社.2022
[7]RobertCimman,Eduart Rohan-Multiscale finite element calculations in Python using SfePy.-2022.vol.45
[8]Linwei He,Matthew Gibert-A Python script for adaptive layout optimization of trusses. -2022.vol.69
[9]Elservierjournal-Python programming on win64.-2022.6.2
[10]王磊. 对Mysql数据库的访问方法的研究[J]. 网络安全技术与应用,2021,(04):138-139.
[11]丛宏斌,魏秀菊,王柳,朱明,曾勰婷,刘丽英. 利用PYTHON解析网络上传数据[J]. 中国科技期刊研究,2023,24(04):736-739.
[12]卫启哲. 试论动态开发语言Python研究[J]. 电脑编程技巧与维护,2022,(14):23-24.
[13]陈威,韦佳,张洁. 海量地震数据移动存储设备的现状分析[J]. 物探装备,2023,23(05):291-293+299.
[14]许沫. 生活模块仪表详细设计浅析[J]. 内蒙古石油化工,2021,39(14):79-80.
[15]范晶. 模拟上行系统测试平台介绍[J]. 中国新技术新产品,2021,(01):31-32.


核心算法代码分析如下:
# -*- coding: utf-8 -*-
from selenium.webdriver import Chrome # 导⼊⾕歌浏览器的类
# from selenium.webdriver.chrome.options import Options
import time
import re
import pymysql
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
import time
import csv
import os
import requests
import random## 创建浏览器所带的参数
options = Options()
options.add_argument('--incognito')
options.add_experimental_option('excludeSwitches', ['enable-automation'])
web = webdriver.Chrome(executable_path=r'D:\JD_Rec2024\web\liping\chromedriver.exe',options=options)def getpinpai(url):web.get(url)## 睡一会,等资源加载完毕#time.sleep(60)yzm = input('手动登录然后点击开始爬取数据:')list = web.find_elements_by_xpath('.//ul[@class="J_valueList v-fixed"]/li')brand_names = []for li in list:brand_name = li.find_element_by_xpath(".//a").textif len(brand_name) > 0:brand_names.append(brand_name)print(brand_name)else:breakprint(len(brand_names))return brand_namesdef getdata(url, pinpai):web.get(url)# time.sleep(3)time.sleep(random.randint(2, 5))# rows = []list = web.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li')for li in list:# title=i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')title = li.find_element_by_xpath('.//div[@class="p-name p-name-type-2"]/a/em').text# price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0]price = li.find_element_by_xpath('.//div[@class="p-price"]/strong/i').text# product_id = i.xpath('.//div[@class="p-commit"]/strong/a/@id')[0].replace("J_comment_","")product_id_ = li.find_element_by_xpath('.//div[@class="p-commit"]/strong/a')product_id = product_id_.get_attribute('id').replace("J_comment_", "")try:# shop = i.xpath('.//div[@class="p-shop"]/span/a/text()')[0]shop = li.find_element_by_xpath('.//div[@class="p-shop"]/span/a').textexcept:shop = ''title = ' '.join(title)# print("title"+str(title))# print("price="+str(price))# print("product_id="+str(product_id))# print("shop="+str(shop))# print("-----")print(product_id, title.replace('\n', ''), price, shop, pinpai)# rows.append([product_id,title.replace('\n',''),price,shop,pinpai])#价格,标题,链接,店铺名称,品牌,型号,好评数,差评数,销售总数,类型1,类型2jiage=pricebiaoti=titlelianjie='https://item.jd.com/'+product_id+'.html'dianpumingcheng=shop#pinpiaxinghao=pinpaipid=product_id'''抓评论'''comment_url = "XXXXX"if pid == '商品id':returnelse:comment_url = comment_url + pidprint('评论API地址', comment_url)comment_r = requests.get(comment_url, headers=kv)p_comment = []# for comment in comment_r.json()["CommentsCount"]:# p_comment.append([comment['ProductId'], comment["CommentCountStr"], comment["AverageScore"],# comment["GoodCountStr"], comment["DefaultGoodCountStr"],# comment["GoodRate"], comment["AfterCountStr"], comment["VideoCountStr"],# comment["PoorCountStr"], comment["GeneralCountStr"]])#好评数,差评数,销售总数,类型1,类型2haopingshu=comment_r.json()["CommentsCount"][0]['GoodCountStr'].replace('+','')chapingshu=comment_r.json()["CommentsCount"][0]['PoorCountStr'].replace('+','')xiaoshouzongshu=comment_r.json()["CommentsCount"][0]['CommentCountStr'].replace('+','')leixing1=pinpaileixing2=pinpai#价格, 标题, 链接, 店铺名称, 品牌, 型号, 好评数, 差评数, 销售总数, 类型1, 类型2print(jiage,biaoti,lianjie,dianpumingcheng,pinpai,xinghao,haopingshu,chapingshu,xiaoshouzongshu,leixing1,leixing2)with open('result.csv', mode='a', encoding='utf-8', newline='') as f1:writer = csv.writer(f1)writer.writerow([jiage,biaoti,lianjie,dianpumingcheng,pinpai,xinghao,haopingshu,chapingshu,xiaoshouzongshu,leixing1,leixing2])# return rows# def savedata(data):
# if os.path.exists('result.csv'):
# with open('result.csv', mode='a+', encoding='utf-8', newline='') as f:
# wirter = csv.writer(f)
# wirter.writerow(data)
# else:
# with open('result.csv', mode='a+', encoding='utf-8', newline='') as f:
# wirter = csv.writer(f)
# wirter.writerow(['商品id', '标题', '价格', '店铺', '品牌'])
# wirter.writerow(data)# def getcommit(pid):# # cookie信息每个人都不同,需登录到京东网站,通过浏览器查看cookie信息
# }
# '''抓评论'''
# comment_url = "xxxx"
# if pid == '商品id':
# return
# else:
# comment_url = comment_url + pid
# print('评论API地址', comment_url)
# comment_r = requests.get(comment_url, headers=kv)
# p_comment = []
# for comment in comment_r.json()["CommentsCount"]:
# p_comment.append([comment['ProductId'], comment["CommentCountStr"], comment["AverageScore"],
# comment["GoodCountStr"], comment["DefaultGoodCountStr"],
# comment["GoodRate"], comment["AfterCountStr"], comment["VideoCountStr"],
# comment["PoorCountStr"], comment["GeneralCountStr"]])
# # 总评数,平均得分,好评数,默认好评,好评率,追评数,视频晒单数,差评数,中评数
# # 将抓取的结果保存到本地CSV文件中
# with open('result1.csv', mode='a', encoding='utf-8', newline='') as f1:
#
# writer = csv.writer(f1)
# writer.writerow(
# ['商品id', '总评数', '平均得分', '好评数', '默认好评', '好评率', '追评数', '视频晒单数', '差评数',
# '中评数'])
# for item in p_comment:
# print('评价数据', item)
# writer.writerow(item)# brandnames =getpinpai('xxxxx')
brandnames = getpinpai('xxxxx')print(brandnames)
for brandname in brandnames:for page in range(1, 3):url = 'xxxxxx'# print(url.format(keyword=item,page=page))url = url.format(keyword=brandname, page=page)data = getdata(url, brandname)