Stacked Hourglass Networks for Human Pose Estimation
用于人体姿态估计的堆叠沙漏网络

这是一篇关于人体姿态估计的研究论文,标题为“Stacked Hourglass Networks for Human Pose Estimation”,作者是 Alejandro Newell, Kaiyu Yang, 和 Jia Deng,来自密歇根大学。论文介绍了一种新颖的卷积神经网络架构,用于人体姿态估计任务。
论文地址:https://arxiv.org/pdf/1603.06937.pdf
源码链接:http://www-personal.umich.edu/~alnewell/pose
本文主要是介绍了一个在当时是新的姿态估计的网络结构。由于本人在研究自动驾驶领域中车道线识别[注] 时使用到此网络结构,故这里主要是对整个网络的结构和思想进行一个梳理,可以进一步明白后序一些基于此网络结构的工作,不涉及到 姿态估计领域 的一些见解和讨论,所以本文主要引出和介绍 hourglass 网络。
注:
《Key Points Estimation and Point Instance Segmentation Approach for Lane Detection》
论文:https://arxiv.org/abs/2002.06604
代码:https://github.com/koyeongmin/PINet
这项工作介绍了一种用于人类姿态估计任务的新颖卷积网络架构。特征在所有尺度上进行处理和整合,以最好地捕捉与身体相关的各种空间关系。此论文展示了自下而上、自上而下的重复处理与中间监督相结合对于提高网络性能至关重要。作者将该架构称为“堆叠沙漏”网络(hourglass),该网络基于池化和上采样的连续步骤,以产生最终的一组预测。在FLIC和MPII基准测试中取得了最先进的结果,超过了所有关于人体姿态估计领域的方法。
堆叠的沙漏模块组成:
作为视觉领域一个公认的问题,多年来,姿态估计一直困扰着研究人员,面临着各种艰巨的挑战。一个好的姿态估计系统必须对遮挡和严重变形具有鲁棒性,在罕见和新颖的姿势上取得成功,并且对由于服装和照明等因素导致的外观变化不变。早期的工作使用强大的图像特征和复杂的结构化预测来解决这些困难,前者用于产生局部解释,而后者用于推断全局一致的姿势。
在卷积神经网络(ConvNets)概念的提出以及使用下,其极大地重塑了这种传统的赛道,这是许多计算机视觉任务性能爆炸性增长的主要驱动力。最近的姿态估计系统普遍采用 ConvNets 作为其主要构建块,在很大程度上取代了手工制作的特征和图形模型;这种策略在标准基准上产生了巨大的改进。
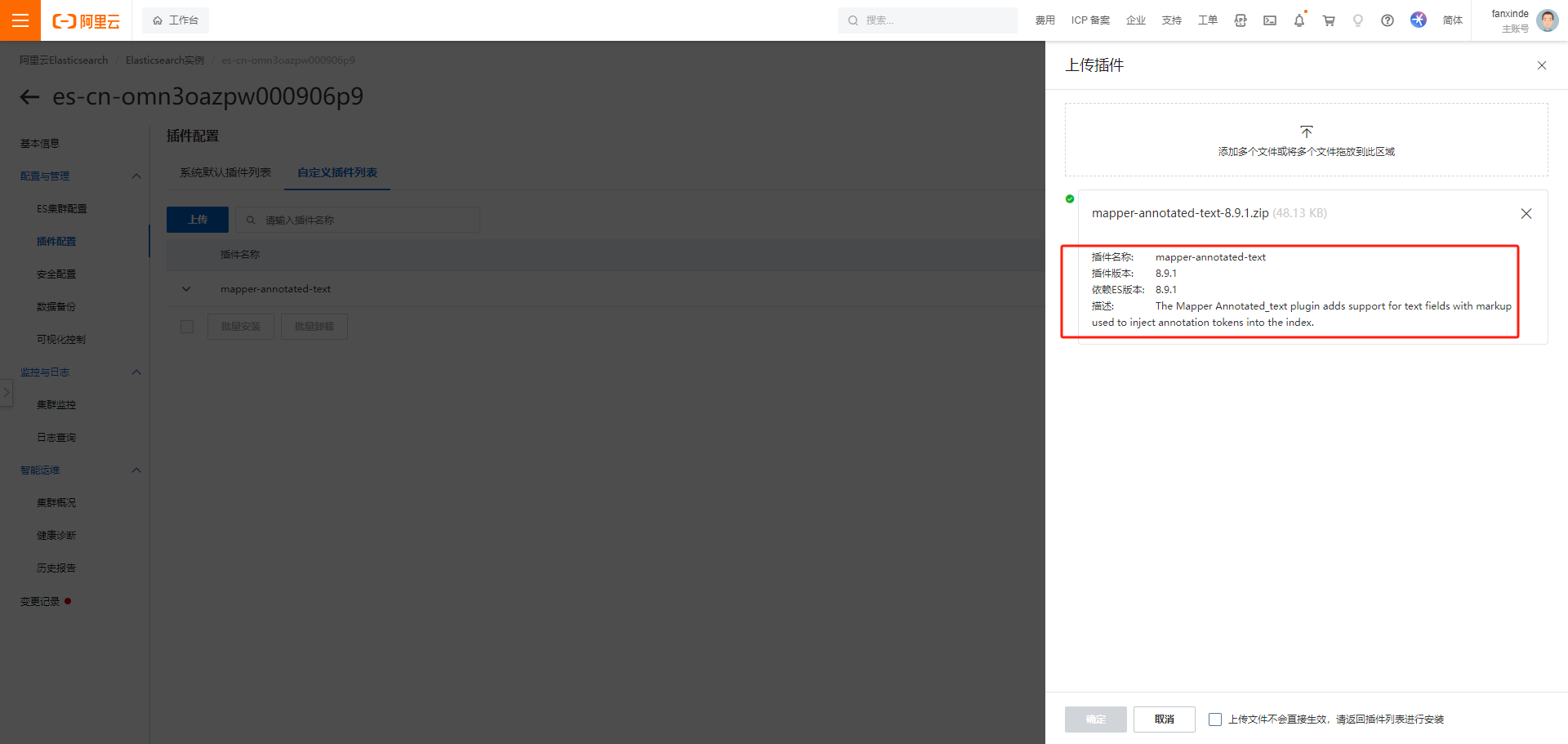
此论文作者继续沿着这条轨迹前进,引入了一种新颖的“堆叠沙漏”网络设计来预测人体姿势。该网络捕获并整合图像所有比例的信息。作者将该设计称为沙漏,基于对池化步骤的可视化,以及用于获得网络最终输出的后续上采样。与许多产生像素级输出的卷积方法一样,沙漏网络池化到非常低的分辨率,然后上采样并组合多个分辨率的特征。另一方面,沙漏与以前的设计不同,主要在于其更对称的拓扑结构。
作者通过将多个沙漏模块端到端连续放置在一起来扩展单个沙漏。这允许跨尺度重复自下而上、自上而下的推理。结合使用中间监督,重复的双向推理对于网络的最终性能至关重要。最终的网络架构在两个标准姿态估计基准(FLIC 和 MPII 人体姿态 )的最新技术基础上实现了重大改进。在MPII上,所有关节的平均精度提高了2%以上,膝盖和脚踝等更困难的关节提高了4-5%。

示例输出和示例热图
堆叠前沙漏模块与全卷积网络和其他设计紧密相连,这些设计在多个尺度上处理空间信息以进行密集预测。沙漏模块与其他设计的不同之处主要在于自下而上的处理(从高分辨率到低分辨率)和自上而下的处理(从低分辨率到高分辨率)之间的容量分布更对称。例如,完全卷积网络 和整体嵌套架构在自下而上的处理中都很重,但在自上而下的处理中很轻,它只包括跨多个尺度的预测的(加权)合并。作者不使用解池层或解卷层。取而代之的是,依靠简单的最近邻上采样和跳过连接进行自上而下的处理,另一个主要区别是,通过堆叠多个沙漏来执行重复的自下而上、自上而下的推理。
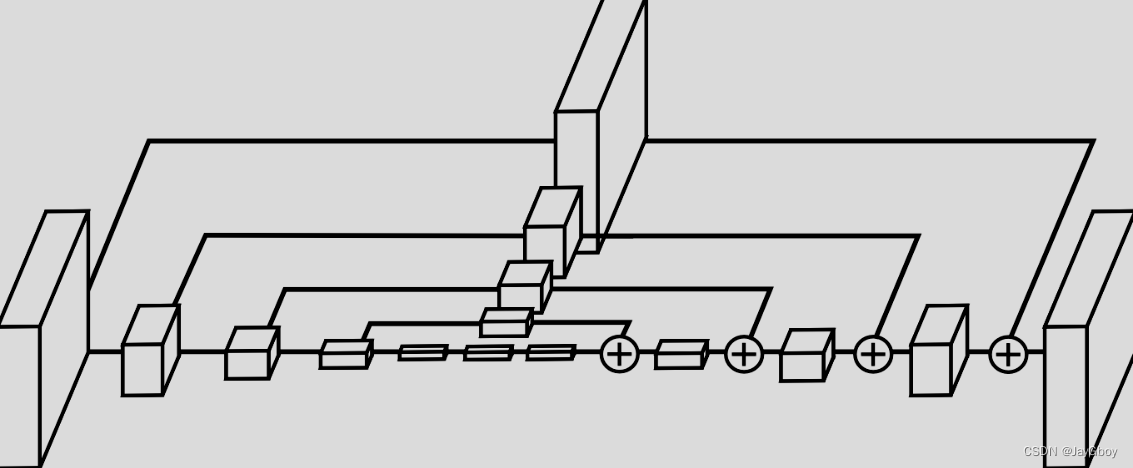
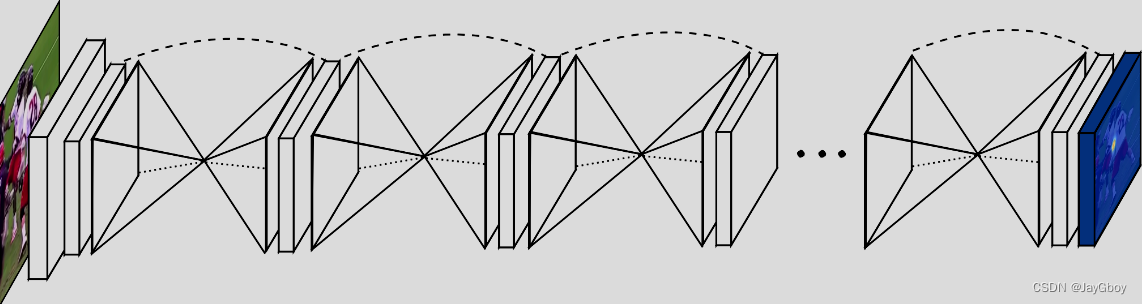
单个“沙漏”模块的图示
“hourglass” 结构很像 FCN,结构最大的不同点就是更加对称的容量分布(包括特征从高分辨率到低分辨率,从低分辨率到高分辨率),FCN 或者 holistically-nested 结构都是高分辨率到低分辨率(down-top)容量比较大、结构较复杂;低分辨率到高分辨率(top-down)结构较为简单。 这里的结构也与一些做分割,样本生成,去噪自编码器,监督/半监督特征学习等的结构很像,但是操作的本质不同, "hourglass" 没有使用 unpooling 操作或者是解卷积层,而是使用了最简单的最近邻上采样和跨层连接来做 top-down(上采样)。还有一个不一样的点是,本文工作堆叠了多个 “hourglass” 的结构来构建整个网络。
hourglass网络架构
Hourglass Design(沙漏结构设计)
作者选择使用带有跳过图层的单个管道来保留每个分辨率的空间信息。该网络达到 4x4 像素的最低分辨率,允许应用较小的空间过滤器来比较图像整个空间的特征。
沙漏的设置如下:卷积和最大池化层用于处理分辨率非常低的特征。在每个最大池化步骤中,网络都会分支,并以原始预池化分辨率应用更多卷积。在达到最低分辨率后,网络开始自上而下的上采样序列和跨尺度的特征组合。为了将两个相邻分辨率的信息汇集在一起,对较低分辨率进行最近邻上采样,然后逐元素添加两组特征。沙漏的拓扑结构是对称的,因此对于下降过程中存在的每一层,都有一个相应的上升层。
top-down : 采用卷积层 + maxpooling
down-top : 采用最近邻上采样 + 跨层连接
在达到网络的输出分辨率后,应用连续两轮 1x1 卷积以产生最终的网络预测。网络的输出是一组热图,其中对于给定的热图,网络预测每个像素处关节存在的概率。
Layer Implementation(层的实现)
作者设计大量使用了残余模块。从不使用大于 3x3 的筛选器,并且瓶颈限制了每层的参数总数,从而减少了总内存使用量。网络中使用的模块如图所示。

Stacked Hourglass with Intermediate Supervision
这种通过端到端堆叠多个沙漏来进一步发展的网络架构,将一个沙漏的输出作为输入馈送到下一个沙漏中。为网络提供了一种重复自下而上、自上而下的推理机制,允许重新评估整个图像的初始估计和特征。这种方法的关键是预测可以应用损失的中间热图。预测是在通过每个沙漏后生成的,其中网络有机会处理本地和全局上下文中的特征。随后的沙漏模块允许再次处理这些高级特征,以进一步评估和重新评估更高阶的空间关系。这与其他姿态估计方法类似,这些方法在多个迭代阶段和中间监督下表现出强大的性能。
通过将中间预测映射到具有额外 1x1 卷积的更多通道,将它们重新集成回特征空间。这些特征与前一个沙漏阶段输出的特征一起被加回沙漏的中间特征中。生成的输出直接用作生成另一组预测的下一个沙漏模块的输入。在最终的网络设计中,使用了八个沙漏。需要注意的是,权重不会在沙漏模块之间共享,并且使用相同的基本事实对所有沙漏的预测应用损失。
训练结果
此网络在两个基准数据集上进行评估,即 FLIC 和 MPII Human Pose 。FLIC 由从电影中拍摄的 5003 张图像(3987 张训练,1016 张测试)组成。这些图像在上半身进行了注释,大多数人物都直视相机。MPII Human Pose 由大约 25k 张图像组成,带有多人的注释,提供 40k 注释样本(28k 训练,11k 测试)。没有提供测试注释,因此在所有的实验中,训练图像的子集上进行训练,同时在大约 3000 个样本的保留验证集上进行评估。MPII由从各种人类活动中拍摄的图像组成,并具有一系列具有挑战性的广泛表达的全身姿势。

示例输出

FLIC结果、MPII上的PCKh比较 、MPII人体姿势的结果
在 MPII 人体姿势数据集上的所有关节上都取得了最先进的结果。所有数字都可以在表中看到,PCK 曲线也可以在图中看到。在手腕、肘部、膝盖和脚踝等困难的关节上,比最新的最新结果平均提高了 3.5% ,平均错误率从 16.3% 下降到 12.8%。最终肘部准确率为91.2%,手腕准确率为87.1%。网络对MPII所做的预测示例如图所示。
堆叠沙漏网络的视觉应用
堆叠沙漏网络架构最初是为了人体姿态估计任务而设计的,但由于其能够有效地捕捉不同尺度的空间信息并在多个分辨率上进行特征整合,这种架构在其他计算机视觉任务中也显示出了潜力和应用价值。
例如在目标检测和识别领域,由于堆叠沙漏网络能够生成高分辨率的输出,它可以用来检测和识别图像中的物体。特别是在需要精确定位物体边界的情况下,这种网络架构可以提供有用的特征。
其次在语义分割任务中,需要对图像中的每个像素进行分类。堆叠沙漏网络通过自底向上和自顶向下的路径,能够有效地整合局部和全局信息,这对于提高分割的准确性是非常有帮助的。
堆叠沙漏网络的改进与优化
网络剪枝:
通过移除网络中不重要的权重和神经元来减少网络的复杂性。网络剪枝可以显著减少计算量,同时尽量保持网络性能。
量化:
将浮点数权重和激活值转换为低精度表示(如int8或int16),以减少模型大小和加快计算速度。量化后的模型可以在不显著降低性能的情况下加速推理过程。
多尺度检测:
优化网络的多尺度检测策略,减少在不同尺度上的重复计算。可以通过共享特征图或使用更有效的金字塔池化层来实现。
使用更高效的层:
替换网络中的一些层为更高效的实现。例如,使用深度可分离卷积(depthwise separable convolutions)代替标准卷积可以减少计算量。
模型并行化:
利用多GPU或多核CPU进行模型的并行计算,以加速前向传播和反向传播过程。
优化的采样策略:
在训练过程中,使用更有效的采样策略,如随机采样或分层采样,以减少不必要的计算。
轻量化设计:
设计轻量级的堆叠沙漏网络版本,通过减少层数、通道数和滤波器大小来降低模型复杂度。