背景
处于业务诉求,需要建立一个统一的调度平台,最终是基于 Dolphinscheduler 的 V1.3.6 版本去做二次开发。在平台调研建立时,这个版本是最新的版本 命运之轮开始转动
事故
表象
上班后业务部门反馈工作流阻塞,登录系统发现大量实例阻塞于 WAITTING_THREAD 状态,而且有比较多定时在凌晨执行的工作流,直到现在都未执行完,按往常执行效率推断应该早就执行结束了。
处理
通过该状态的触发点逻辑,可以找到是Master节点的问题,当调度线程池活跃线程打满,后续的实例都会处于WAITTING_THREAD 状态,剩下就是走流程了 dump线程 dump内存 重启节点。
分析
第一个疑点 stack中发现确实有大量线程处于 BLOCKED 和 TIMED_WAITING 状态
大量线程Block于类加载?😳

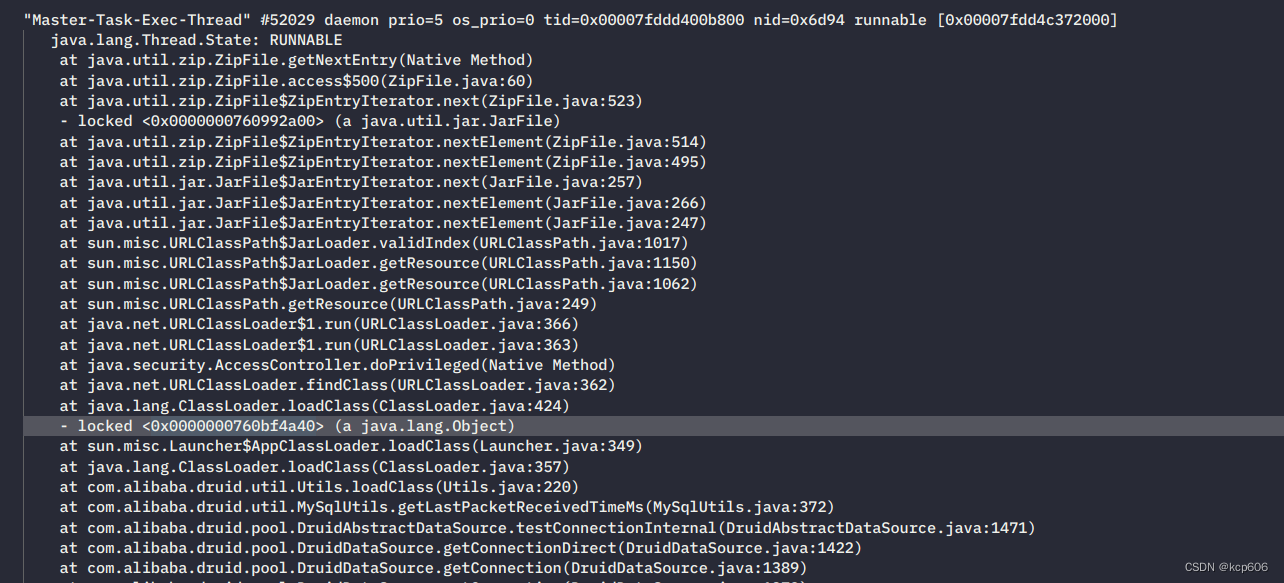 搜索后可以找到大致的原因,只能说确实问题很隐晦有性能影响,不过不会导致线程池拉满。
搜索后可以找到大致的原因,只能说确实问题很隐晦有性能影响,不过不会导致线程池拉满。
类似于Redis缓存中常会讨论的缓存穿透问题,此时JVM就是缓存,一堆Jar就是DB,JVM不停去扫描加载Jar去找这个不存在的驱动类,类加载又是同步的,其他线程都得等,极大影响了并发时的查询性能,恰好这里线程池又拉满了线程池中的任务都是在while(true)去查库中的数据记录的工作流状态是否执行结束,执行结束才会break 😨。
- 同事升级了MySQL驱动8.0,导致应用大量超时
- druid连接池引起的线程blocked
100多个线程处于 TIMED_WAITING ,通过栈可以看出都是在死循环查库,等工作流实例运行结束好做收尾工作
Github 代码
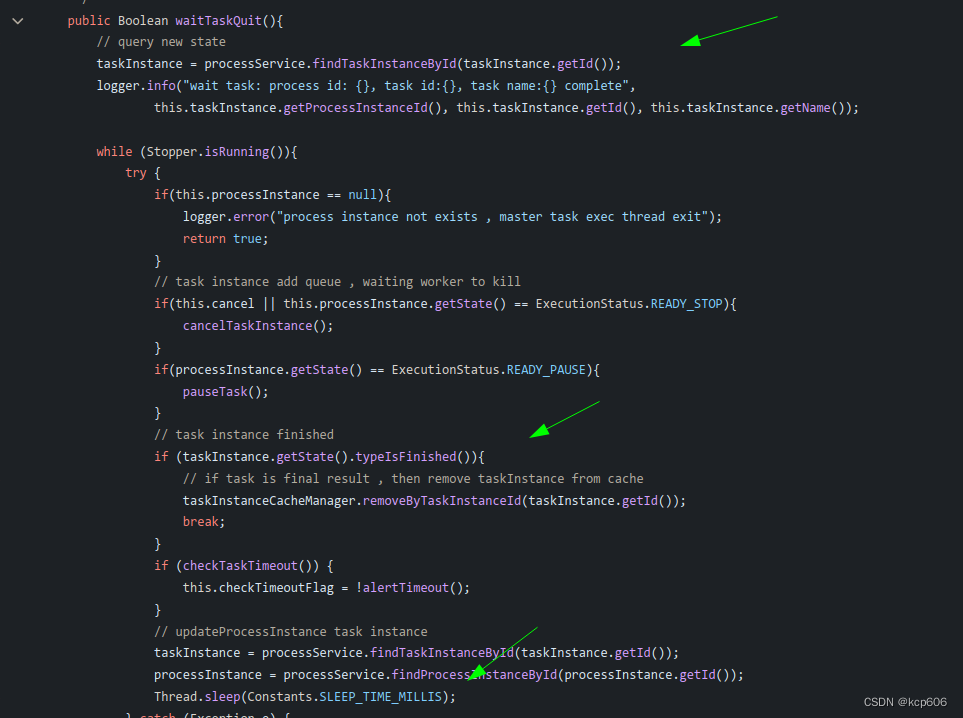 那为什么工作流中的任务 无法更新状态呢,导致监控任务的线程拉满,监控工作流的线程池拉满, 想通过分析内存的dump找到那几个线程池的状态和等待队列,也没看出问题,因为提交任务的时候判断了活跃线程,所以等待队列是空的,而且也没有异常的大对象,只有一堆等待回收的ZipEntry
那为什么工作流中的任务 无法更新状态呢,导致监控任务的线程拉满,监控工作流的线程池拉满, 想通过分析内存的dump找到那几个线程池的状态和等待队列,也没看出问题,因为提交任务的时候判断了活跃线程,所以等待队列是空的,而且也没有异常的大对象,只有一堆等待回收的ZipEntry 没错 上面频繁加载Jar去找驱动类导致的 😅
此时就没头绪了,然后在MAT里瞎逛,这里看看那里点点,在看对象分布时发现有些Queue实例是没有关联到线程池的而是独立存在,逐个扫了下看等待的数量发现了突破口,有个queue积压了很多任务此时用OQL查找效率更高 ,通过GCROOT看到了这个队列定义的地方和消费的逻辑。
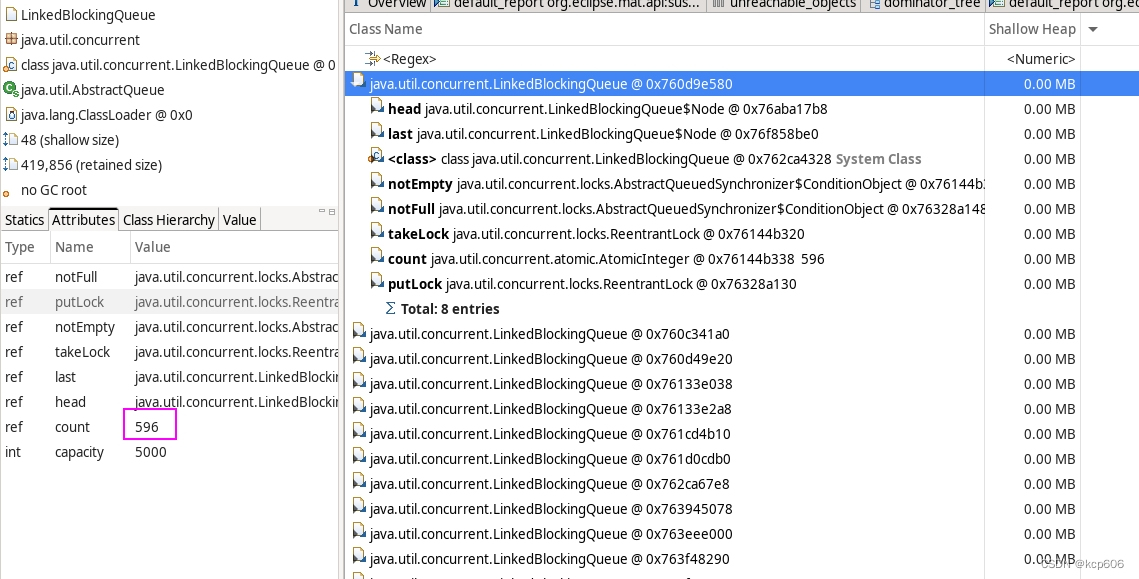 > Github 代码
> Github 代码
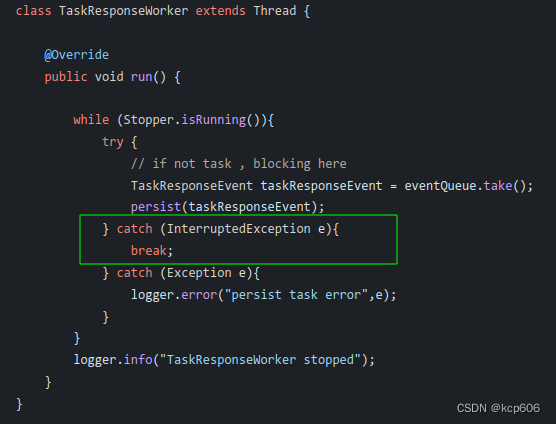
emmm 这段代码怎么说呢,如果是普通逻辑,那唯一的问题是吞了中断的异常,以及粗糙的继承Thread直接start,不利于生命周期管理。
但是这里的逻辑是为了触发更新上面两个线程池疯狂扫描的那个工作流实例表的状态,那这就有隐患了。一旦这个线程挂掉,整个系统就会逐渐不可用了,从线程stack中也确认了没这个线程,由于在应用的日志中没有看到停止和异常的日志,那就只能刚好是吞异常的地方导致线程停止了😇 墨菲定律YYDS
优化:
- 循环中catch提高到Throwable级别,把退出的事情交给 Runtime的hook实现。
- 或者用Scheduler线程池定时消费队列?这样的话即使线程挂掉了线程池也会补线程进来。
- 或者从队列消费任务后将任务提交到线程池执行
前提是队列中的事件允许无序消费
第二个疑点 只有一个Master节点出问题
Master搭建的是集群
TODO
优化
- 增加关键流程处的技术和业务指标告警,及时发现和处理问题。
- 例如关键的几个线程池一旦活跃线程达到多少阈值后就通过机器人或邮件告警相关负责人及时响应
- 加强对MAT jstack等工具的熟悉程度和异常指标的敏感度,提高解决问题效率
总结
其实前面铺垫了1.3.6版本的选择,只能说生不逢时了,因为那会这个项目还是处于孵化状态,后几年才正式发布。
现在最新的版本大部分基础技术模块都重写或优化了,包括线程和线程池管理,用 Micrometer 埋点,加入了更细致的技术指标的监控和告警。
但是从这个平台运行到现在已经有大量的调度在跑,要迁移的话就不是一个P0能扛得住了😇,这下有点船大难调头的意味了,只能在现有的架构上打补丁或者说打地鼠 DDDD。