本资源主要包含第2-4问,第一问直接使用传统图像处理即可,需要有很多步骤,这一步大家自己写就行。
2 第2问,甲骨文识别
2.1 先处理源文件
原文件有jpg和json文件,都在一个文件夹下,需要对json文件进行处理,主要是将其转换为yolov8所使用的格式,大体代码如下所示:
# 详情加q 596520206
def convert(height, width, box):dw = 1. / (width)dh = 1. / (height)x = (box[0] + box[2]) / 2.0 - 1y = (box[1] + box[3]) / 2.0 - 1w = box[2] - box[0]h = box[3] - box[1]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, h
2.2 划分训练集和测试集
处理完之后,所有的图片分为两个文件夹,一个是图片,一个是标签,但是需要划分为训练集和测试集,代码如下:
for file in train_files:shutil.copy(file, os.path.join(train_images_folder, os.path.basename(file)))for file in val_files:shutil.copy(file, os.path.join(val_images_folder, os.path.basename(file)))# 复制对应的标签文件到相应的文件夹中
for file in train_files:label_file = os.path.join(labels_folder, os.path.splitext(os.path.basename(file))[0] + '.txt')if os.path.exists(label_file):shutil.copy(label_file, os.path.join(train_labels_folder, os.path.basename(label_file)))
处理完之后的图片
2.3 训练和验证模型
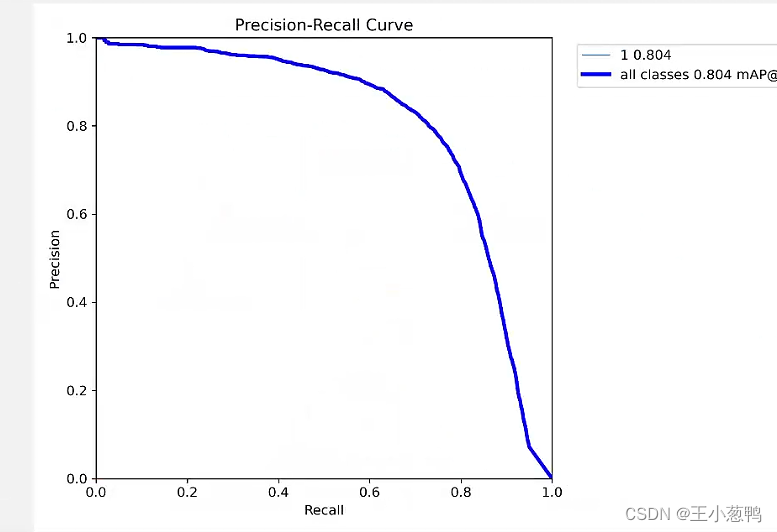
配置好data.yaml文件,即可训练和验证,中间截图如下:
会发现大多数的都能展示出来

3 第3问,对给定的文件进行识别
注意,有的图片是单通道,需要转换为3通道,如图所示:
if len(img.shape) == 2:# 处理单通道图像# 创建一个全零的三通道图像height, width = img.shapecolor_image = np.zeros((height, width, 3), dtype=np.uint8)# 复制单通道图像到每个通道color_image[:, :, 0] = img # 将灰度图像复制到蓝色通道color_image[:, :, 1] = img # 将灰度图像复制到绿色通道color_image[:, :, 2] = img # 将灰度图像复制到红色通道img = color_image
第3问对图片进行检测例子:

4 第4问
这问要先搭建一个分类模型,单独训练这个模型,然后将第2问检测的图片截图,放入到这个模型进行预测,结果如下所示:


for xyxy, label in zip(xyxy_all,predict_label_all):x0 = xyxy[0]y0 = xyxy[1]x1 = xyxy[2]y1 = xyxy[3]color = (0, 255, 0) # 矩形的颜色,这里是绿色draw.rectangle([(x0, y0), (x1,y1)], outline=color)draw.text((x0, y0-30), label, (255, 0, 0), font=font)cv2charimg = cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR)cv2.imwrite(os.path.join(out_file_path, image_name), cv2charimg)
通过代码发现有些能识别处理,Q 596520206