- 论文链接: https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf
- 全文由『说文科技』原创出品。版权所有,翻版必究。
这篇发表于2016年九月的文章,在搜索推荐仍然基于矩阵分解的时代,抛出了基于深度学习的召回排序模型,无异于朝平静的湖面扔出了一枚重磅炸弹。如大家所见,在这十年里,基于深度学习的搜推模型几乎已成圭臬。看到这里,你怎么还能说google不伟大?

1. 摘要
YouTube 代表着现存最大规模以及最复杂的工业级推荐系统。首先文章高屋建瓴般地描述了这个系统,同时展示出了由深度学习带来的极佳的性能提升。根据经典的两阶段信息检索,本文也分成两部分:基于深度学习的候选者生成模型和基于深度学习的排序模型。同时给出了一个巨大用户量级的推荐系统的设计、迭代维护等实践经验(为了让读者阅读到最后,这部分经验被原文作者放在了文末的Conclusion 中)。
摘要中的三个关键点:
- 推荐系统由两类模块构成:
candidate generation and ranking; - 当前的推荐系统仍然是基于矩阵分解,而用
deep neural network的工作还非常少。 => 本文提出使用deep learning 的recommendation system; - 给出YouTube维护系统的经验教训。
2. 当前挑战
推荐系统现存挑战主要有三方面,分别是推荐系统的伸缩性、新颖性和(数据中的)噪声。
2.1 伸缩性
在小数据集上运行良好的模型很难在大规模的任务上表现优秀。对于YouTube这类应用,需要对有着高度专业分布式学习算法以及高效的服务系统。
2.2 新颖性
如何平衡旧有资源和新资源之间的推荐权重?旧资源中有很多是经过历史沉淀的,经过用户筛选的,质量肯定会高一些,而新颖的资源的时鲜性较好,但是质量可能参差不齐。
这一点,我对我司的推荐系统推荐的使用存在一定的疑惑,我不太清楚是由于我个人的事实认知错误,还是百度当前的推荐针对此方面做了改进。但我的观点很明显:『一个推荐系统必须要有推荐旧资源的能力』。如果只做新颖资源的分发,就很难把优秀的ugc资源沉淀起来,也就很难做高质量,这就导致很难提升用户体验,也无法帮助到用户寻找到高优资源(这违背了搜推是做优秀资源分发的本质)。
本文中多处提到资源的新颖性问题:

2.3 噪声
- 系统很难获取用户的真实满意度,而会对有噪声的隐式反馈信号建模。

3. 问题思考
3.1. 为啥要替换矩阵分解?
原因如下图所述:可以将任意连续、分类的特征方便的融入到模型中。

4. 模型
这些东西大家都太熟悉了,也没有太多要分析的了。这里我偷个懒,不赘述了,如果有疑问的地方,还请评论告知,我再补齐。
4.1. deep cadidate generation model
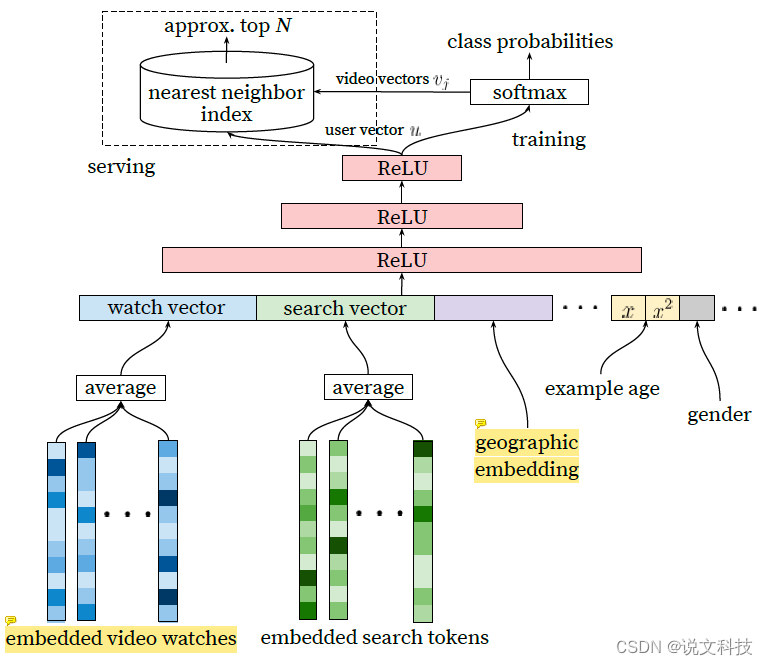
这个模型还挺有意思的。疯狂的拼接了一大批的 embedding。因为这些信号的来源各不相同,所以被作者称之为『Heterogeneous Signals』。
4.2. deep ranking network
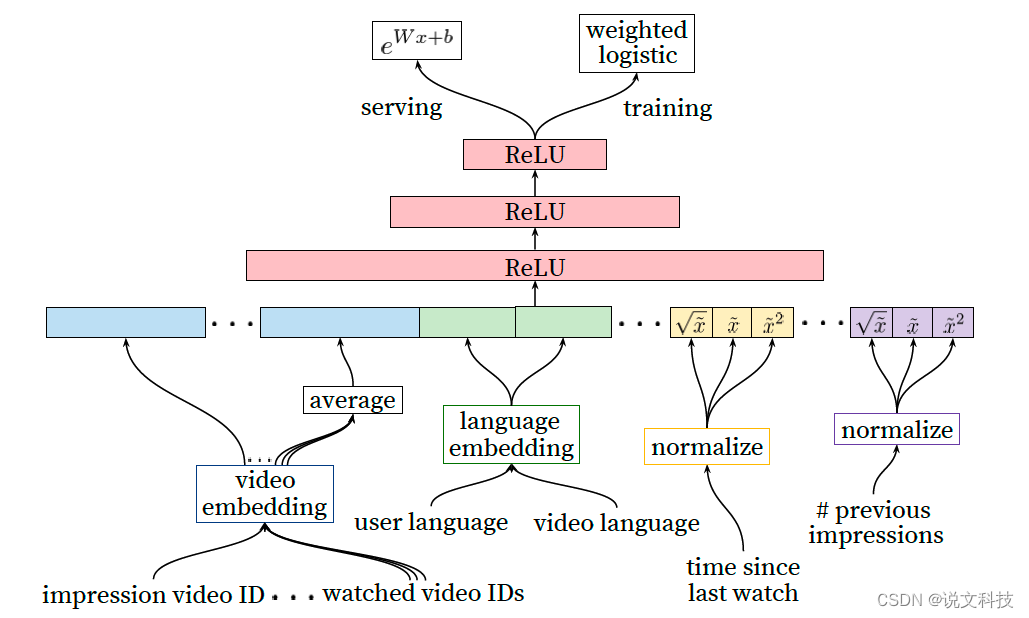
5. 细节知识
5.1. ID 的空间过大该如何处理?
这里的ID指的是对视频、搜索query的编号,简言之就是把视频做编号处理,然后每个编号对应一个embedding。
5.2. oov问题
oov指的是Out-of-vocabulary,其实这是深度学习中一个常见的问题。Out-of-vocabulary values are simply mapped to the zero embedding.
5.3 『Example Age』 特征
这块儿我看了两遍才弄明白,麻了。理解后,才对作者的聪明才智惊艳到。我先把这部分的全文给贴上,方便大家做对照:


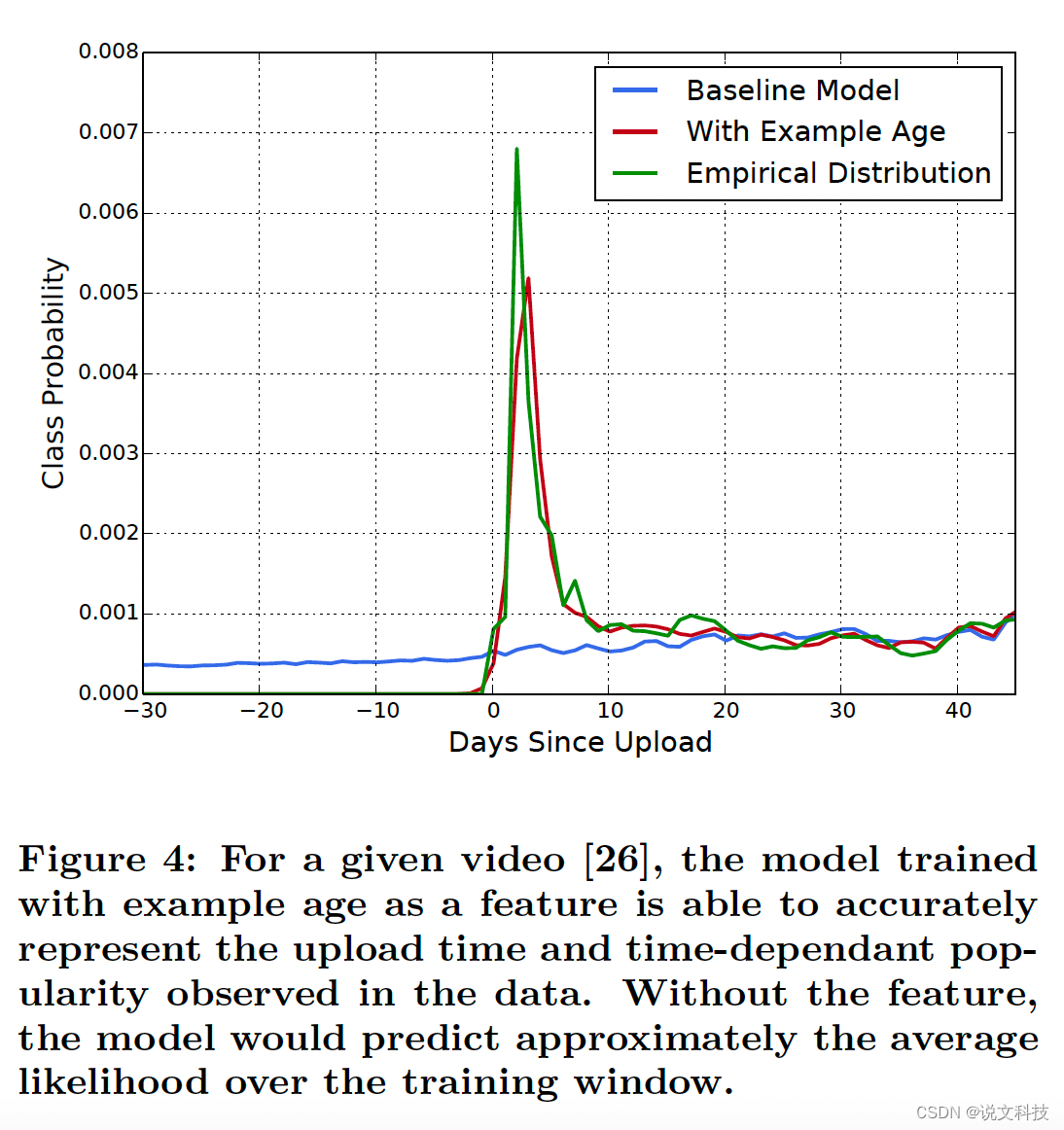
逐段拆解上面这个原文:
第一段:讲了youtube 上传的视频量大之外,还说用户其实更喜欢新颖的内容。但是YouTube作为一个著名的应用,除了简单推荐用户想观看的新视频这首要因素外,还有一个关键的现象需要考虑:提升并且传播(propagating) 重要的内容。
通过这一段就可以清晰地知道,作者想传达的意思是:他们的系统想实现的是两方面的功能,第一要推荐用户喜欢观看的;第二提升并且传播重要的内容。
第二段:机器学习通常展现出对过去的隐式偏差,原因是它们在训练的时候就是从历史的样例数据中预测未来。(作者这里没有给出一个具体的引用不太合适)接着作者说到,真实世界的视频流行度分布是高度不稳定的,但是我们的训练集中的分布确实稳定的。用训练数据集中的分布去模拟一个动态变化的分布显然是不合理的。于是为了解决这个问题,作者提出:将训练数据的年龄作为一个特征用于训练。而在预测时,则会将这个age设置成0或者是一个偏负值,用于标识是在inference。
看到这里,是不是有点儿惊讶到你?真的挺为作者的聪明惊喜到。很多训练样本其实也是有『年龄』而言的,所以这一部分也不容忽视。
第三段:给出一个case 分析。这个case想说明的就是:在使用『example age』这个特征作为训练特征后,模型有能力精准的表示出视频的上传时间,同时给出(样本数据中存在的)与时间相关的流行度【刚开始发布时,分类的概率高;随着时间推移,分类的概率就低了】。而在没有该特征的情况下,该模型将在训练窗口上近似地预测平均似然。
6. 可借鉴的经验教训
作者在文中介绍到,维护一个拥有广大用户的推荐系统,有很多经验教训值得学习。这部分的内容作者写在了 Conclusion 中,几个关键点总结如下。
6.1. 用户倾向喜欢新颖的内容

用户更喜欢新颖的内容。 这一点,通读全文后就会有一个非常明显的观感。作者在文中反复提及『资源新颖』,比如上述的『example age』就是为了考虑内容新颖度(视频的生命周期)而加入的一个训练特征。
6.2 推荐系统受益于『描述用户同item的历史行为数据』这类特征

这类特征比如:观看时长。现如今几乎每名推荐算法工程师都知道观看时长是一个非常重要的特征,但是不可忽视,这是Google在2016年提出的文章。
6.3 将观看时长融入到逻辑回归模型中

再详细点儿说,是这样的:
融合了观看时长的逻辑回归模型通过预测观看时长的效果(这个效果可能是其它的某些指标)是要比预测点击率好的。