作者:Sandra Gonzales
ChatGPT Plus 订阅者现在有机会创建他们自己的定制版 ChatGPT,称为 GPT,这替代了之前博客文章中讨论的插件。基于本系列的第一部分的基础 —— 我们深入探讨了在 Elastic Cloud 中设置 Elasticsearch 数据和创建向量嵌入 —— 这篇博客将指导你完成开发一个定制的 GPT 的过程,该 GPT 旨在与你的 Elasticsearch 数据无缝交互。

定制 GPT
与插件系统相比,GPT 标志着一项重大进步,为用户提供了一种更简便的方式来创建 ChatGPT 的定制版本。通过直观的用户界面,这种增强简化了定制过程,通常无需编码技能就可以应用于广泛的应用程序。除了基本的个性化定制之外,那些希望将 ChatGPT 与外部数据集成的用户可以通过自定义动作来实现这一点。用户可以选择在 GPT 商店分享这些定制的 GPT,将它们保留为个人使用,或者只在公司的 ChatGPT 团队计划中与你的公司工作空间共享。

如何实现 ChatGPT 与 Elasticsearch 的通信
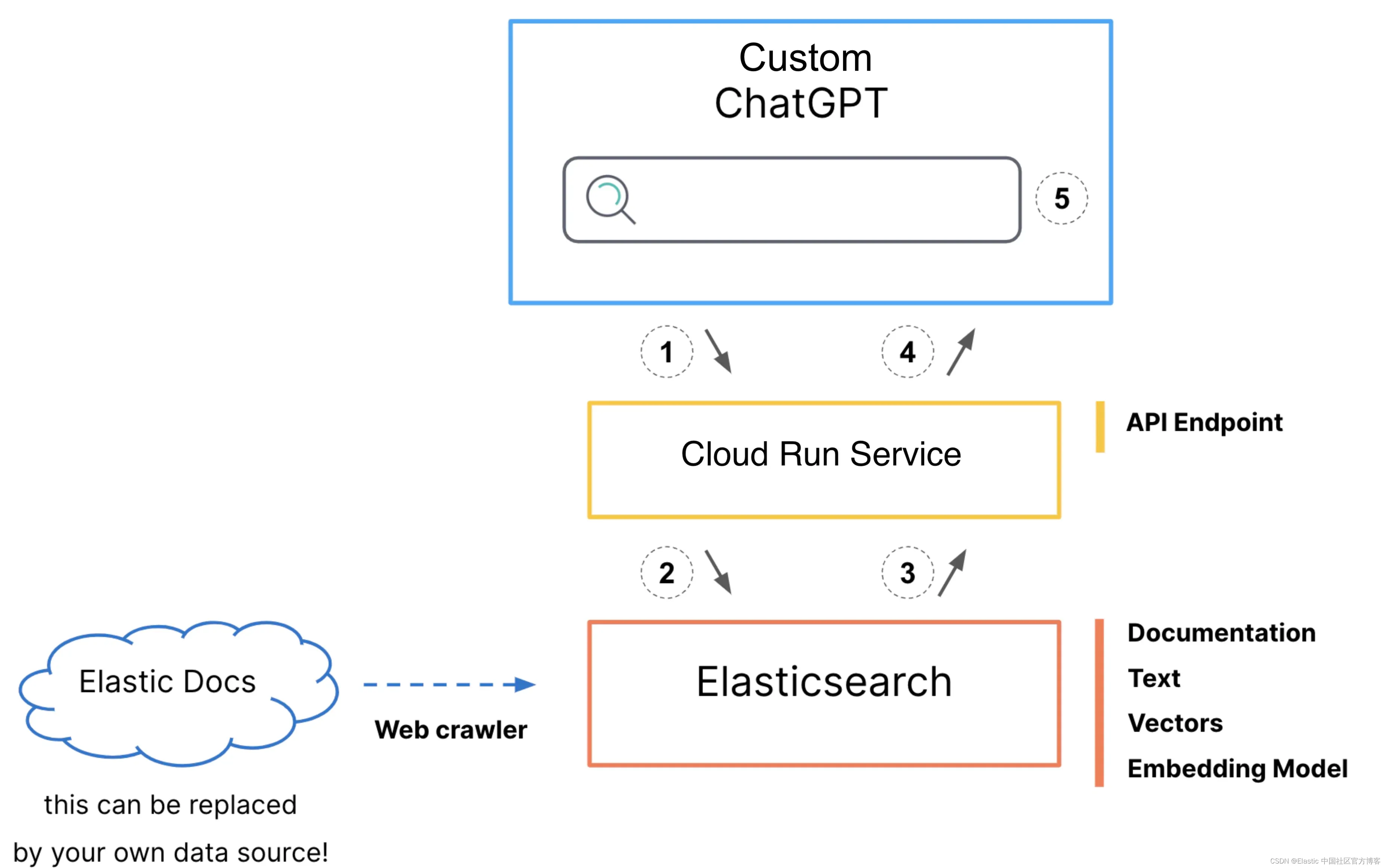
- ChatGPT 通过 Cloud Run 服务的 /search 端点发起调用。
- 服务将此输入用于创建 Elasticsearch 搜索请求。
- 查询响应与文档主体和 URL 一起返回给服务。
- 服务以文本形式将文档主体和 URL 返回给定制的 ChatGPT。
- 然后,此响应以文本形式中继回给 GPT,准备进行解释。
再次强调,此博客假设你已设置了 Elastic Cloud 账户,对内容进行了向量化处理,并拥有填充了数据的 Elasticsearch 集群,可供使用。如果你还没有完成所有设置,请参阅我们之前的帖子,了解详细的步骤。
代码
为了使我们的定制 GPT 得以实现,我们创建了一个服务,作为 ChatGPT 和我们的 Elasticsearch 数据之间的中间件。这个服务的核心是一个 Python 应用程序,它设置了一个 Quart 应用程序,并定义了 /search 端点。此外,我们使用一个Dockerfile来便于在Cloud Run上部署应用程序。
Python 应用程序连接到我们的 Elastic Cloud 集群,执行一个结合了 BM25 和 kNN 查询的混合搜索,并返回相关的文档主体和 URL。这使得我们的定制 GPT 能够实时访问和利用 Elasticsearch 数据。
完整的代码请参考 GitHub 存储库。这包括了用于 Cloud Run 部署的 Python 应用程序和 Dockerfile。
部署服务
关于使用 Google Cloud Platform(GCP)部署服务的详细步骤,请参考我们之前关于 ChatGPT 插件的博客文章中的部署部分。在那里,你将找到一份逐步指南,指导你在 GCP 上设置和部署你的服务。
创建 GPT
登录你的 ChatGPT Plus 账户后,通过你的个人资料导航到 “My GPTs”(我的 GPT)找到 “Create a GPT”(创建 GPT)链接。或者,你的对话上方的 “Explore GPTs”(探索GPT)部分也可以进入 GPT 商店,在那里你可以找到创建 GPT 的链接。

配置 GPT
GPT 编辑器提供了两种配置你的 GPT 的方式:通过对话提示进行引导设置的 “Create”(创建)标签,以及用于直接配置输入的 “Configure”(配置)标签。为了配置 Elastic Docs Assistant,我们将主要使用手动配置,以精确定义我们的 GPT 的设置。

为你的 GPT 指定一个名称,例如 “Elastic Docs Assistant”,并添加一个简短的描述,突出其功能。
在 Instructions(指令栏) 下,定义你的 GPT 的主要角色,并为其提供展示信息的指令:
You are an Elasticsearch Docs Assistant. Your function is to assist users with docs on Elastic products by querying the defined /search action. Answer the user's query using only the information from the /search action response. If the response contains no results, respond "I'm unable to answer the question based on the information I have from Elastic Docs." and nothing else. Be sure to include the URL at the bottom of each response.切换到 “Create”(创建)标签,让 ChatGPT 生成对话开始提示和一个 logo。或许我会上传我自己的 logo。

我们不会上传任何知识文件,因为我们使用的所有数据都在 Elasticsearch 中。相反,我们将定义一个动作。
定义一个动作
这是我们将数据连接到 Elasticsearch 的地方。点击 “Create a new action”(创建新动作)将带我们进入动作编辑器。
首先,我在我的环境中设置了一个自定义头部名称,用于定义我在端点服务中使用的 API 密钥。
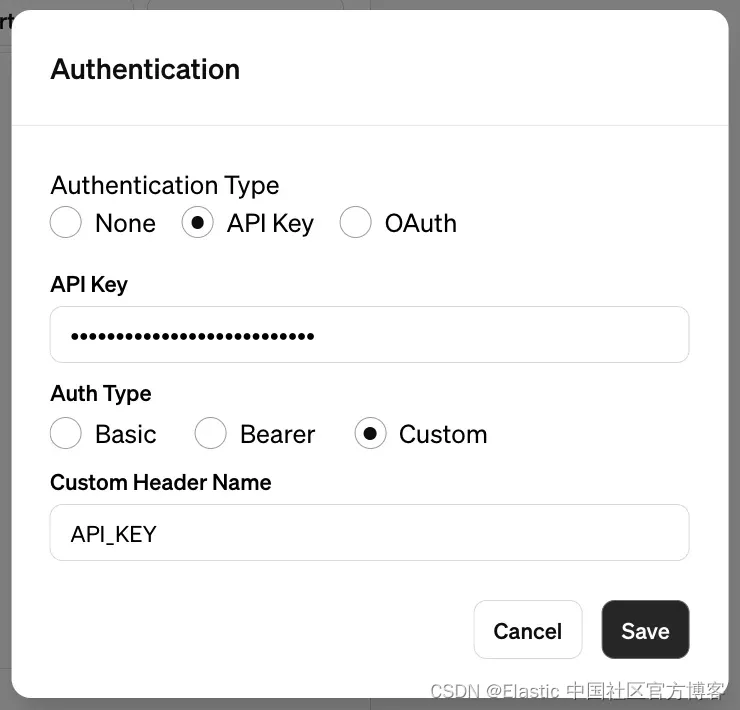
然后我复制我的 OpenAPI 规范:
openapi: 3.0.1
info:title: ElasticDocs_CustomGPT description: Retrieve information from the most recent Elastic documentationversion: 'v1'
servers:- url: YOUR_SERVICE_URL
paths:/search:get:operationId: searchsummary: retrieves the document matching the queryparameters:- in: queryname: queryschema:type: stringdescription: use to filter relevant part of the elasticsearch documentation responses:"200":description: OK
输入这些信息后,我们的模式将被自动验证,并显示一个搜索动作,任何错误都会显示为红色。如果一切都看起来不错,这就是预览窗格特别有用的地方。你不仅可以测试动作以确认其功能,而且助手还提供有关请求的调试信息。这对于根据服务的响应来完善你的 GPT 的回答非常有帮助。
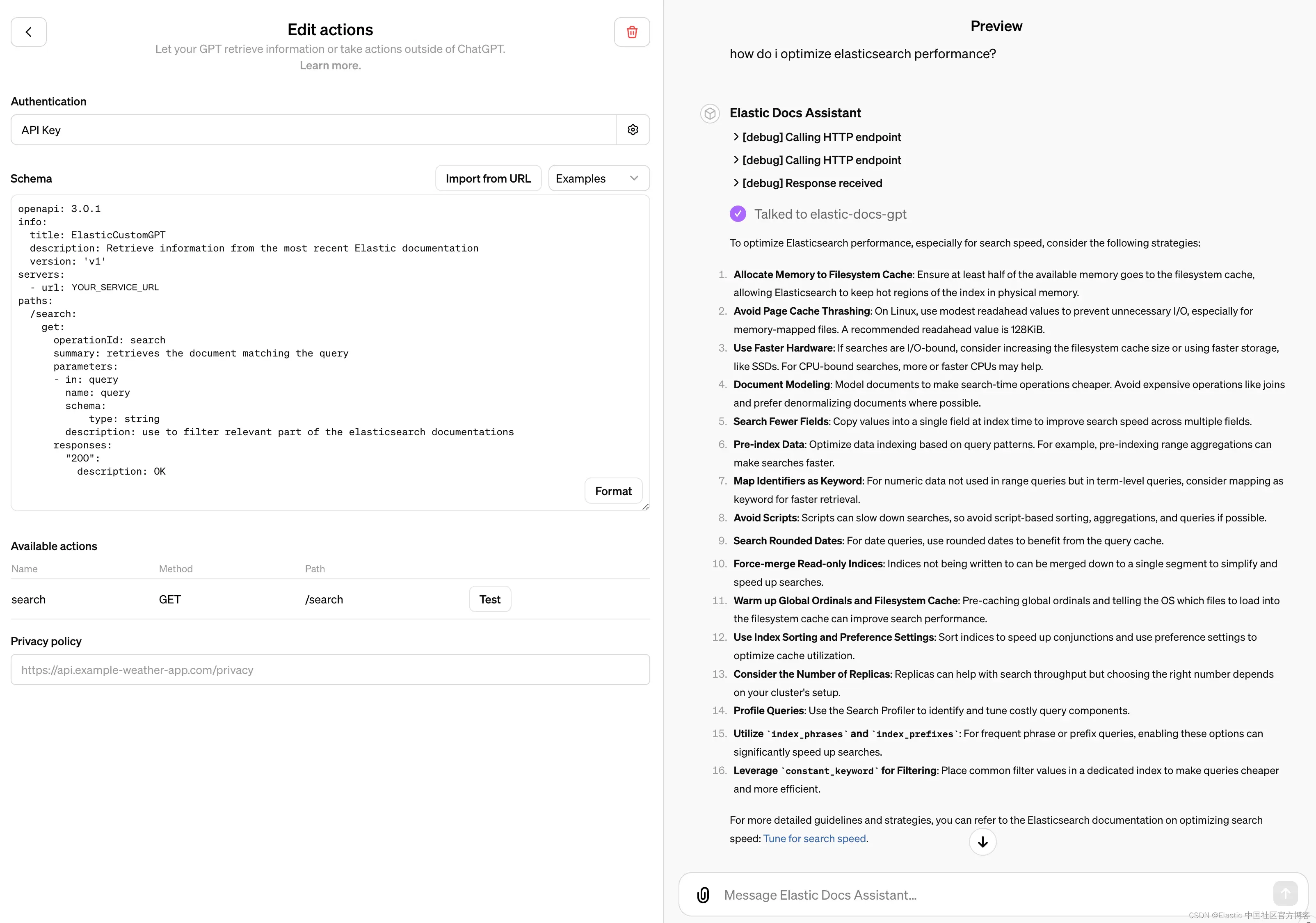
通过配置 GPT 指令以动态修改其动作请求,可以实现更进一步的定制,例如在用户输入发送到服务之前重写用户输入,或者根据用户输入中的某些条件添加请求查询参数。这消除了传统编码逻辑的需要,前提是你的端点被设计为支持这些修改。
发布 GPT
点击预览窗格上方右上角的 “Publish”(发布),即可转到你新创建的 GPT。
展望未来
通过利用 Elasticsearch 进行动态的、数据驱动的对话,探索定制 GPT 的过程仅仅揭示了可能性的一角。通过利用 ChatGPT 的界面,并将其连接到外部数据,我们为定制化和具有上下文丰富性的交互引入了新的维度,使用了最先进的 AI 模型。
你今天就可以尝试本博客中讨论的所有功能!通过注册免费的 Elastic Cloud 试用版开始吧。
在本博客文章中,我们可能使用了第三方生成AI工具,这些工具由各自的所有者拥有和操作。Elastic 对这些第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任或义务,也不对你使用此类工具可能引起的任何损失或损害负责。在使用含有个人、敏感或机密信息的 AI 工具时,请小心谨慎。你提交的任何数据可能会用于 AI 训练或其他目的。无法保证你提供的信息将被保密或安全。在使用任何生成 AI 工具之前,你应该熟悉其隐私实践和使用条款。
Elastic、Elasticsearch 及相关标志是 Elasticsearch N.V. 在美国及其他国家的商标、标志或注册商标。所有其他公司和产品名称都是其各自所有者的商标、标志或注册商标。
准备在你的应用中构建 RAG 吗?想尝试不同的 LLMs 与向量数据库? 查看我们在 Github 上的 LangChain、Cohere 等样本笔记本,并加入即将开始的Elasticsearch 工程师培训!
原文:ChatGPT and Elasticsearch: Creating Custom GPTs with Elastic Data — Elastic Search Labs