概述
使用GPT-SoVITS训练声音模型,实现文本转语音功能。可以模拟出语气,语速。如果数据质量足够高,可以达到非常相似的结果。相比于So-VITS-SVC需要的显卡配置更低,数据集更小(我的笔记本NVIDIA GeForce RTX 4050 Laptop GPU跑起来毫无压力。)
使用
GPT-SoVITS项目地址(https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
项目集成了干声提取工具,声音剪切工具,语音文本校对工具等工具,你只需要一段高质量的语音即可在本地克隆声音。
下载项目
下载项目到本地,解压并打开,双击go-webui.bat,会打开控制台,稍等片刻会打开浏览器
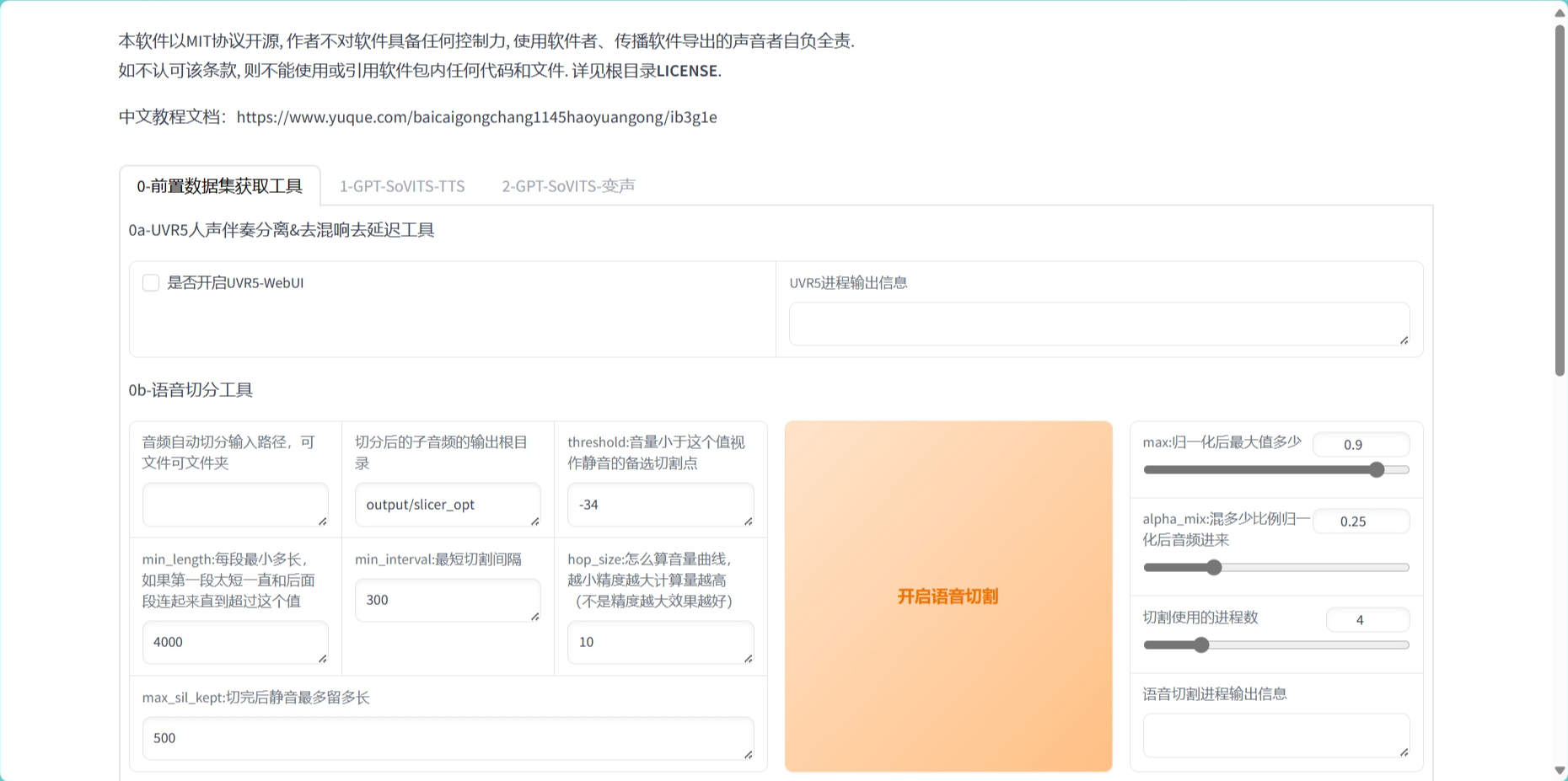
有两个标签页(前两个,第三个还没做好),一个是数据处理,得到干声数据集和语音文本。
一个是模型训练和推理。
数据处理所有参数都默认,只需要选择对应的数据文件路径即可。
数据处理
输入文件路径为绝对路径,输出的文件路径默认在该项目文件夹目录下。数据处理目标是得到一个语音文本文件和一个声音数据集。
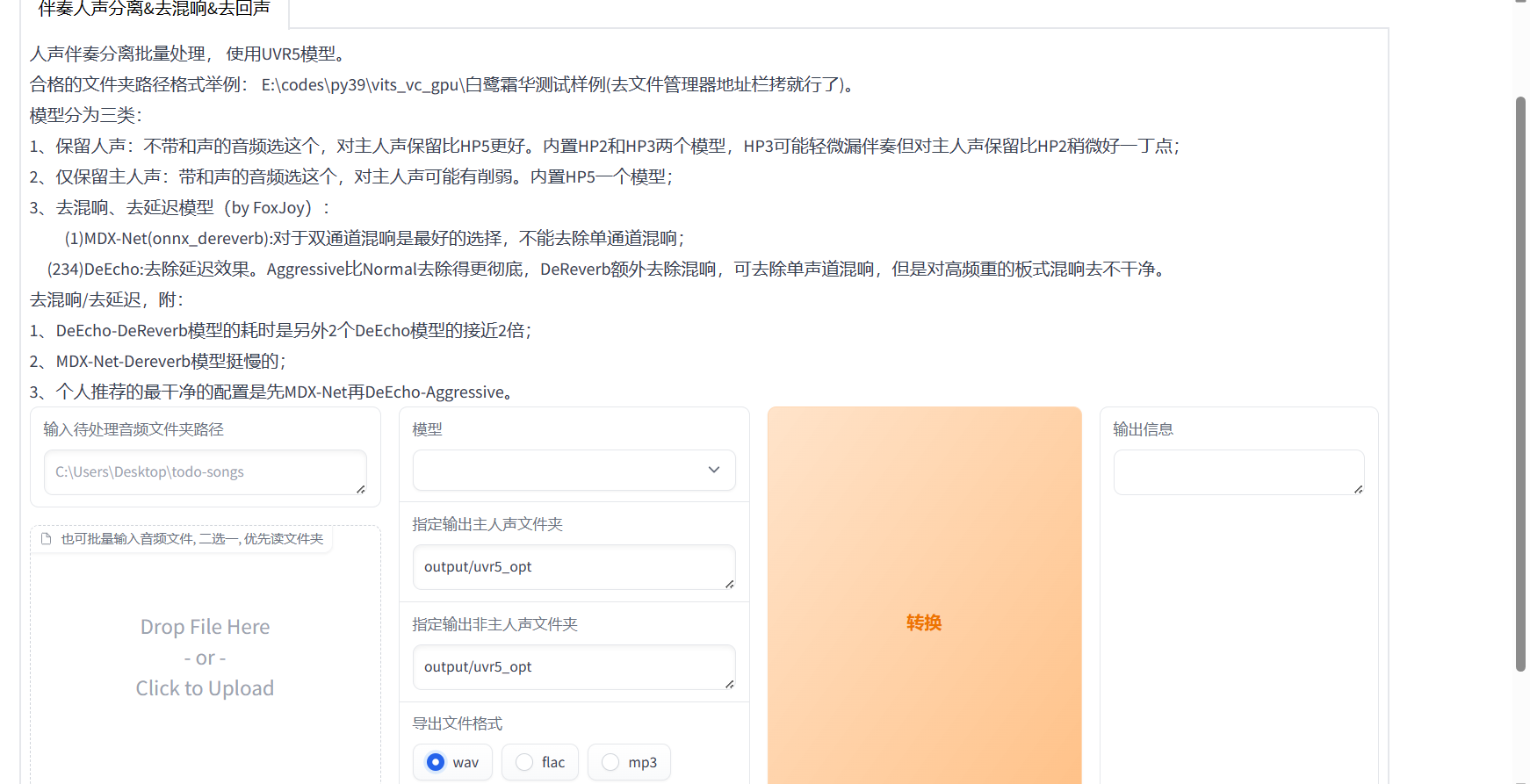
分离干声

这一步用于分离干声,选中该选项稍等一会会打开一个网页用于分离干声,输出格式选择wav。选择输入输出目录点击转换即可。
音频切分
语音降噪
如果是自己的录音可能会有噪音需要降噪处理,如果是网上下载的歌曲干声不用进行该操作。

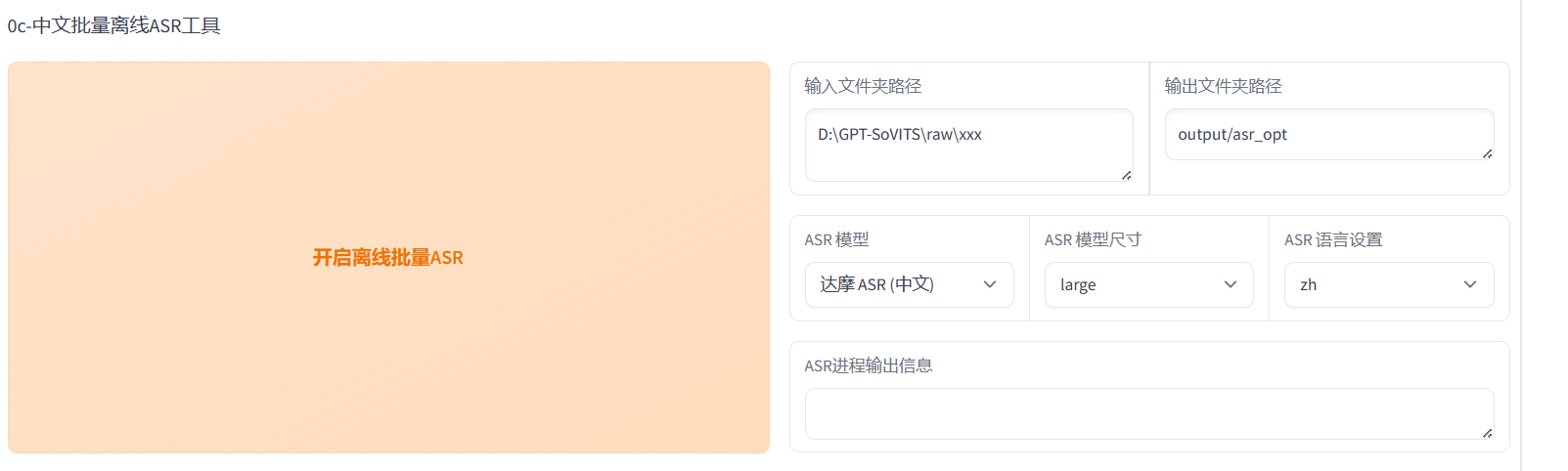
语音文本识别
识别处理好的声音数据,并得到对应的文本文件。
语音文本校对
注意输入路径是文件的路径,不是文件夹的路径。选中后会打开一个页面用于校对语音文本。

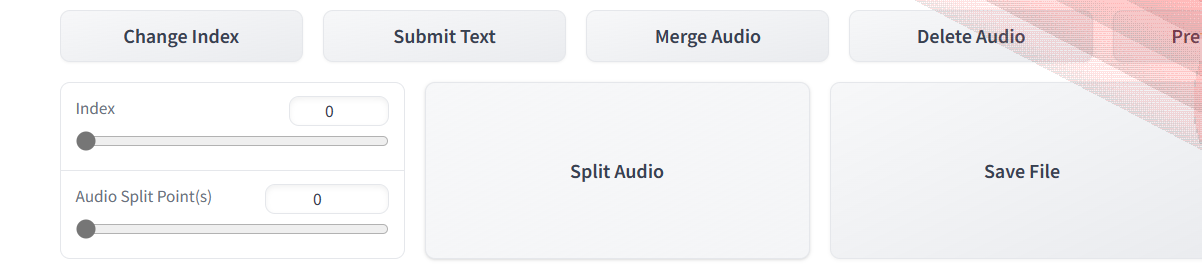
有些识别的字可能有问题,需要手动去修改一下,以及一些停顿处需要增加或删除标点符号。修改后需要点击Submit Text保存。
训练和推理
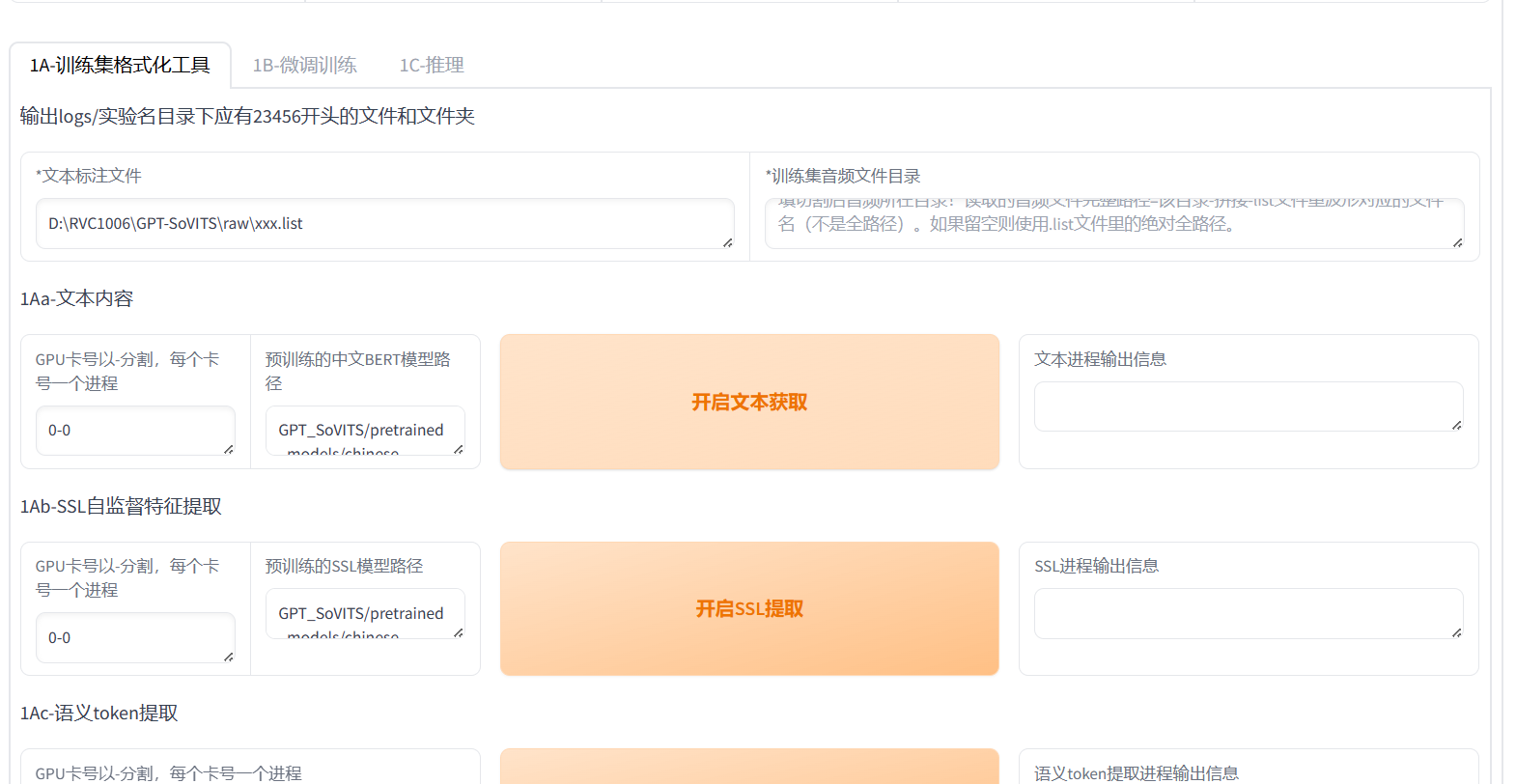
训练集格式化
填写三个打星号的文本框即可,其他不用管。然后点击最下方的开启一键三连,等待完成之后就可以进行训练。

模型训练
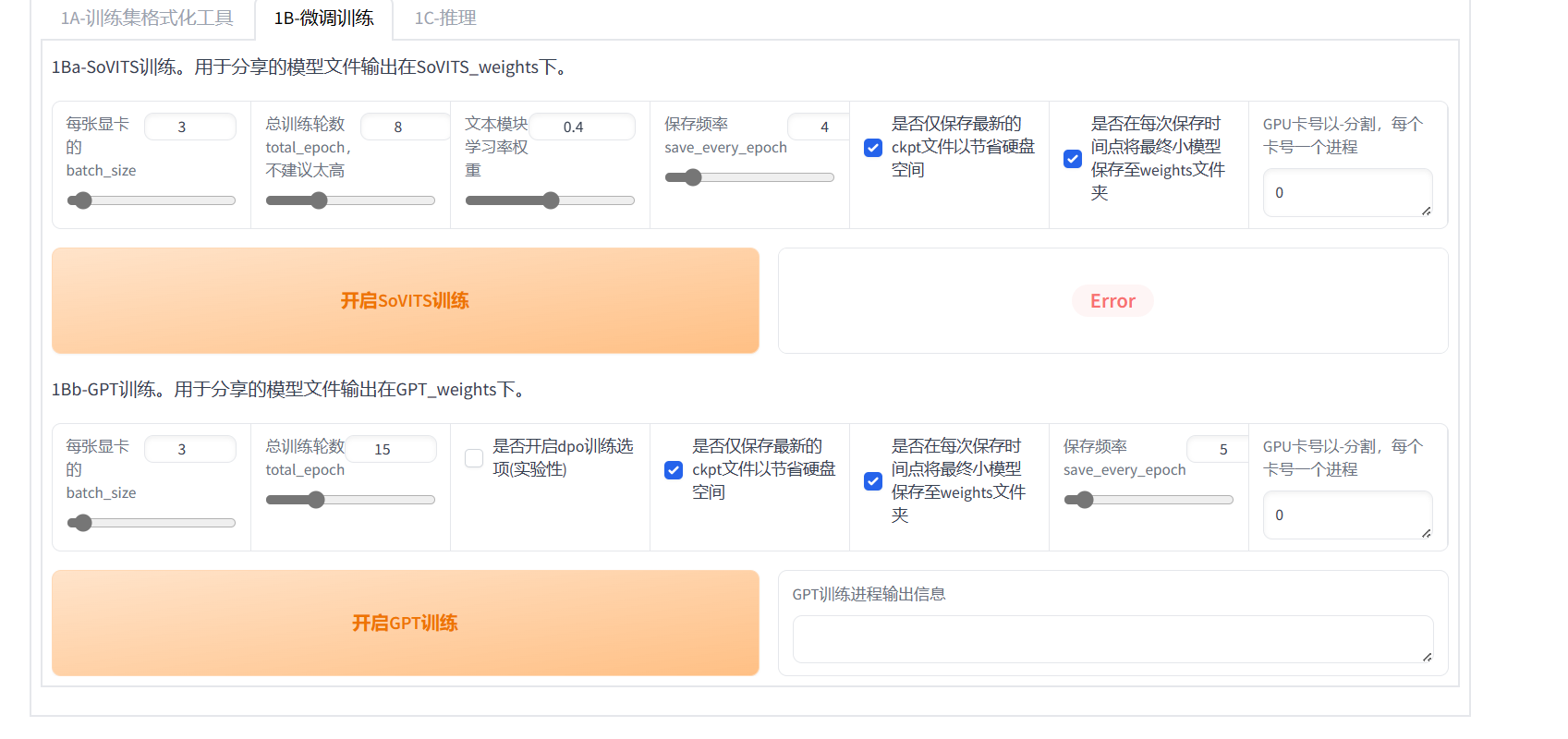
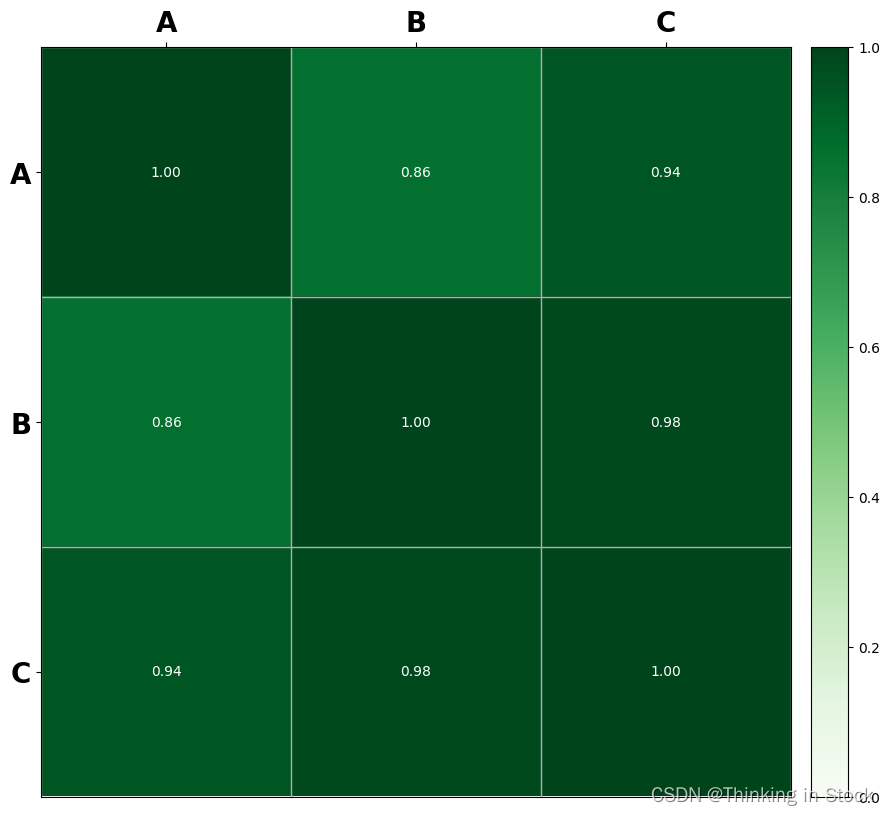
batch_size:计算一次更新梯度的样本数量,影响训练速度。
total_epoch:训练轮次,影响模型质量,理论上来说越大越好。
GPT模型对结果影响不大,训练个10-15轮即可。SoVITS可以多训练一些。
其他保持默认即可。
推理
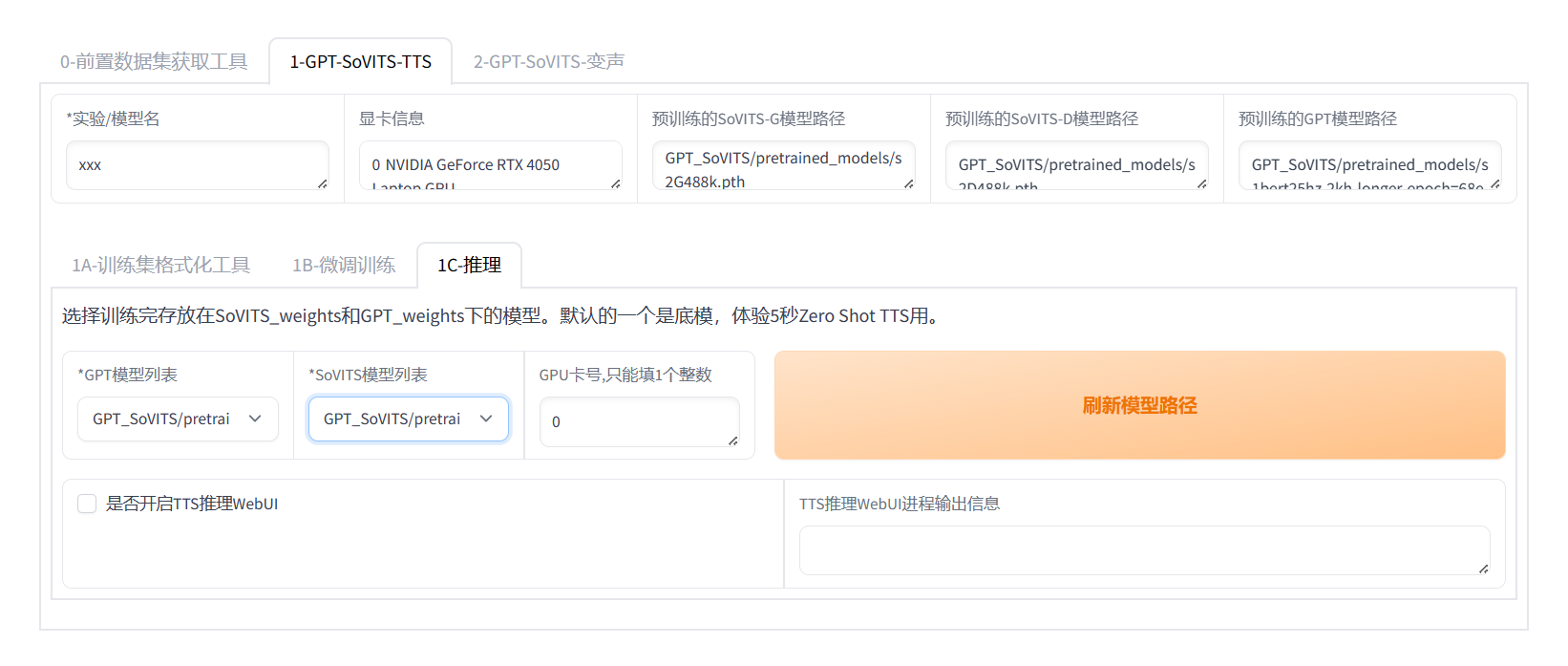
刷新一下模型路径,选择训练好的模型。选择数字最大的即可。选中开启TTS推理页面。
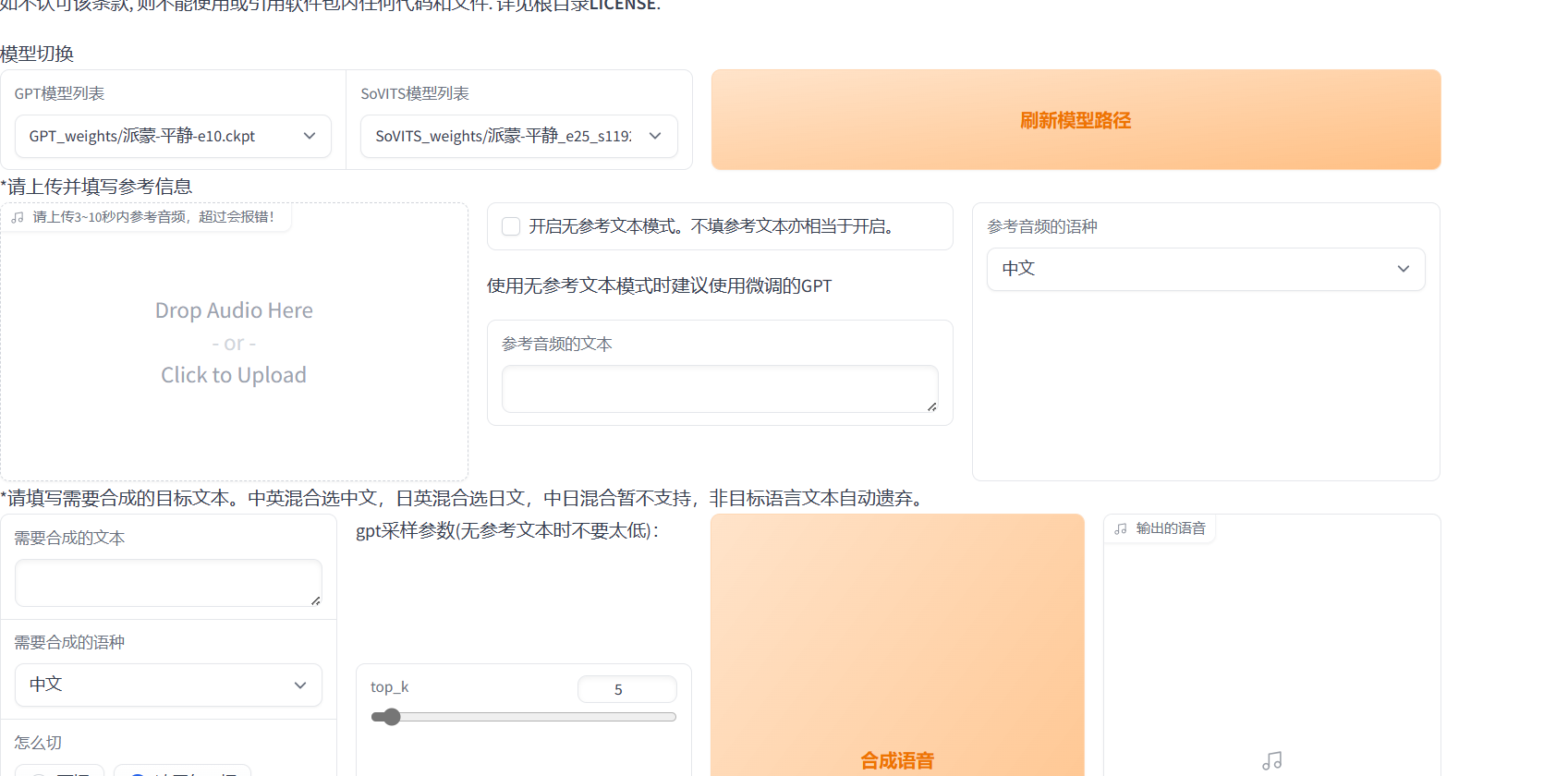
刷新模型路径,选择匹配的GPT和SoVITS模型。
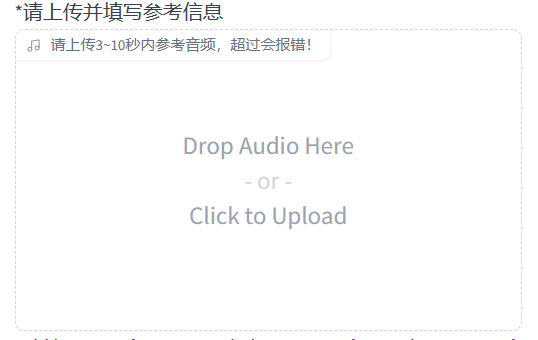
需要上传说话者一段3-10秒内的声音片段。这个声音片段会影响生成结果的语速和情绪(这个声音片段对结果影响很大)。
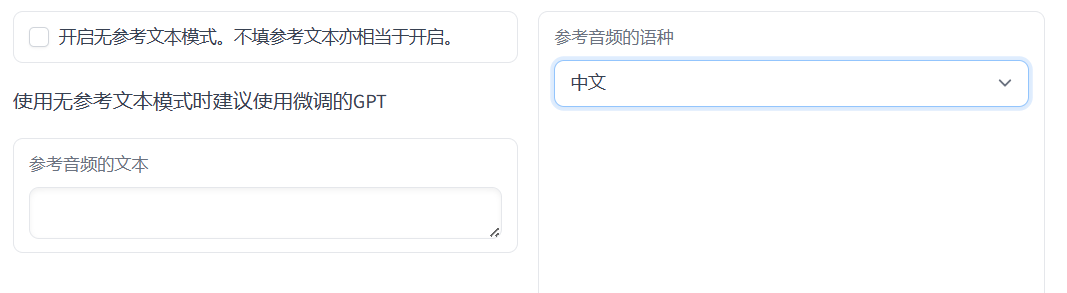
上传的音频文本和语言类型。
需要生成的语音文本
标点符号会影响生成结果的停顿。把文本粘贴进去,选择语言和文本切割方式,参数默认,点击合成语音等待生成结果。即使训练的数据没有英文和日文,也可以生成英文和日文音频。
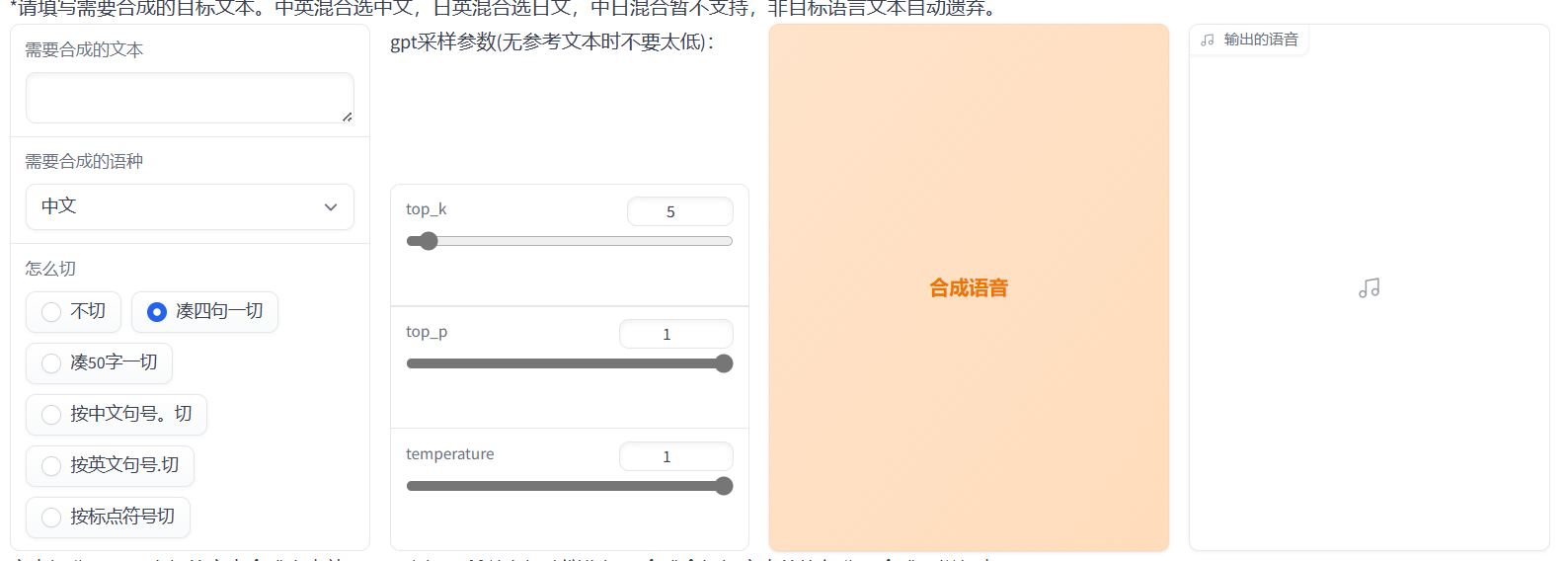
文本切割工具
和上面的文本切割功能一样。将大段文字切割。

注意
模型训练过程中GPU会发热,请在有人监控的情况下进行,温度过高及时停止(在控制台输入CTRL+C)以防发生意外。