在自然语言处理(NLP)领域,Transformer模型因其卓越的性能而广受欢迎。然而,传统的Transformer模型在处理极长输入序列时面临着显著的挑战,尤其是在内存和计算资源的消耗上。最近,一篇名为《Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention》的谷歌论文提出了一种创新的解决方案——Infini-attention模型,它能够有效地扩展Transformer模型以处理无限长的输入序列,同时保持有界的内存和计算资源。
无限上下文的挑战
传统的Transformer模型依赖于自注意力机制来处理输入序列,但这种机制在处理长序列时会导致内存占用和计算时间呈二次方增长。这意味着,随着输入序列长度的增加,所需的内存和计算资源会急剧增加,从而限制了模型在实际应用中的可行性。
Infini-attention的创新之处
Infini-attention模型通过引入一种新的注意力技术——压缩记忆(compressive memory),解决了这一挑战。压缩记忆是一种固定大小的存储结构,它通过参数化的关联矩阵来存储和检索信息。这种方法使得模型能够在处理长序列时保持较低的内存占用,并且能够无限扩展其上下文窗口。
压缩记忆的工作原理
压缩记忆的关键在于它的参数化存储机制。它不是简单地存储每个输入序列的键值对,而是通过更新关联矩阵中的参数来存储新信息。这种存储方式允许模型在有限的存储空间内有效地保留长期和短期的上下文信息。此外,压缩记忆采用增量更新和遗忘策略来平衡信息的保存与更新,确保模型能够适应不断变化的数据流。
Infini-attention与Transformer-XL对比
Transformer-XL
- 分段处理:Transformer-XL通过将输入序列分割成多个段,并在每个段上应用自注意力机制。
- 记忆缓存:它引入了记忆机制,通过缓存之前段的键值对(KV)状态,并将它们与当前段的状态一起用于自注意力计算,从而扩展了上下文窗口。
- 循环机制:Transformer-XL利用循环机制来维持对过去段的记忆,这有助于在处理当前段时考虑长期依赖关系。
Infini-attention
- 压缩记忆:Infini-attention通过压缩记忆机制来存储长期信息,而不是简单地缓存过去的KV状态。这种机制允许模型在有限的存储空间内保留长期上下文。
- 线性注意力:它采用了线性注意力机制,这是一种与关联矩阵相结合的注意力方法,可以更高效地处理长序列。
- 流式处理:Infini-attention设计为能够以流式方式处理输入,这意味着它可以连续地处理并记忆无限长的序列,而不受输入长度的限制。
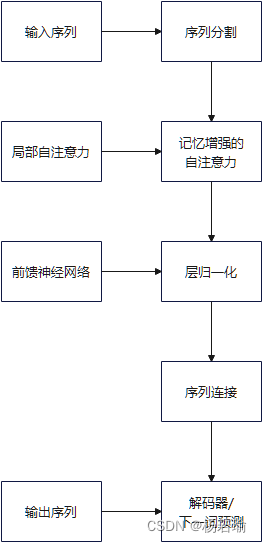
图为本人在阅读论文后理解的Transformer-XL每一次循环的处理过程
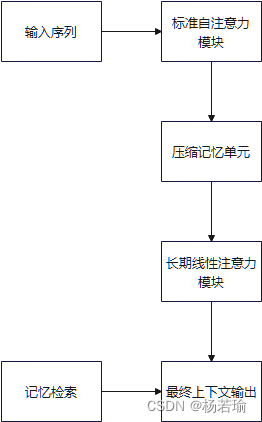
图为本人在阅读论文后对Infini-attention处理过程的理解
性能对比
内存占用:
Transformer-XL:通过缓存过去的KV状态来扩展上下文窗口,这会增加内存占用,尤其是在处理非常长的序列时。
Infini-attention:采用压缩记忆机制,能够在处理长序列时保持较低的内存占用。这种方法使得模型能够以有界内存处理无限长的输入序列。
上下文窗口的扩展:
Transformer-XL:虽然通过缓存过去的KV状态来扩展上下文窗口,但它仍然受限于最近的几个段,因为它只缓存了最后一个段的KV状态。
Infini-attention:能够无限地扩展上下文窗口,同时保持有界的内存占用。这意味着Infini-attention可以处理更长的上下文信息,而不会受到内存限制的影响。
长序列处理能力:
Transformer-XL:在处理长序列时,由于内存占用的增加,可能会遇到性能瓶颈。
Infini-attention:特别设计用于处理长序列,通过流式处理和压缩记忆机制,能够有效地处理无限长的输入序列,同时保持高效的计算和内存使用。
实验结果:
Transformer-XL:在长上下文任务上表现出色,但可能在更长序列的任务上遇到挑战。
Infini-attention:在长上下文语言建模、1M长度的密钥检索任务和500K长度的书籍摘要任务上取得了更好的性能。特别是在内存压缩比方面,Infini-attention实现了114倍的压缩率,显著优于Transformer-XL。
适应性和泛化能力:
Transformer-XL:需要特定的缓存机制来处理长序列,这可能会影响其在不同任务上的适应性。
Infini-attention:由于其设计允许即插即用的持续预训练和长上下文适应,因此在不同长度的序列任务上具有更好的泛化能力。
压缩记忆是如何运作的
1、存储键值对(KV):
在传统的Transformer注意力机制中,每个输入序列段都会生成对应的键(K)和值(V)矩阵。随着序列的进行,这些KV对会累积,导致内存占用迅速增加。
Infini-attention模型在处理每个新的输入段时,会将当前段的KV对存储到一个称为压缩记忆(compressive memory)的特殊结构中。
2、压缩记忆:
压缩记忆是一个固定大小的结构,它通过参数化的关联矩阵(associative matrix)来存储和检索信息。这意味着无论输入序列的长度如何,压缩记忆的大小都保持不变,从而实现了对内存的有效压缩。
新的KV对被添加到压缩记忆中,而不是简单地覆盖或丢弃旧的KV对。这样做可以保留长期上下文信息,同时避免了内存占用的无限制增长。
3、记忆更新和检索:
当处理新的输入段时,Infini-attention会从压缩记忆中检索与当前注意力查询(Q)相关的信息。这一过程涉及到一个线性注意力机制,它使用Q和压缩记忆之间的关联来检索旧的值(V)。
检索到的信息会与当前段的局部注意力输出结合起来,形成最终的上下文表示。这个过程允许模型同时利用长期记忆和当前上下文信息。
4、增量更新:
一旦检索完成,模型会更新压缩记忆以包含新的KV对。这个过程是增量的,意味着新的信息会被添加到记忆中,而不是完全替换旧的信息。
更新规则可能会采用一些特殊的机制(如delta规则)来优化记忆的更新过程,确保新旧信息的有效整合。
为什么无论输入序列的长度如何,压缩记忆的大小都保持不变?
压缩记忆(compressive memory)之所以能够在处理不同长度的输入序列时保持大小不变,是因为它采用了一种固定参数数量的存储机制,而不是依赖于输入序列长度的动态数组或数据结构。以下是压缩记忆保持大小不变的几个关键原因:
1、参数化存储:压缩记忆通过一个预定义的、固定大小的参数矩阵来存储信息。这个矩阵被称为关联矩阵(associative matrix),它的大小是在模型初始化时确定的,并且在整个模型训练和推理过程中保持不变。
2、信息绑定和检索:在压缩记忆中,新的信息不是简单地存储为独立的键值对,而是通过更新关联矩阵中的参数来实现的。这意味着新输入的信息会与已有的记忆内容结合,而不是单独存储,从而节省了存储空间。
3、增量更新:当新的输入序列到来时,压缩记忆不是替换掉所有旧的信息,而是通过增量更新机制来调整关联矩阵中的参数。这种更新策略确保了记忆内容的连续性和相关性,同时避免了内存占用的无限制增长。
4、记忆压缩:压缩记忆的设计目标是在保持必要信息的同时,尽可能减少存储的冗余。通过优化记忆更新和检索过程,压缩记忆能够有效地利用有限的参数空间来存储更多的信息。
5、遗忘机制:为了维持记忆的有效性和相关性,压缩记忆可能会采用某种形式的遗忘机制,例如通过时间窗口或重要性衰减来丢弃旧的或不再相关的信息。
通过这些设计原则,压缩记忆能够在处理不同长度的输入序列时,有效地保持其大小不变,从而使得模型能够在有限的资源下处理无限长的序列。这种方法在提高模型的效率和扩展性方面具有显著优势,尤其是在处理大规模数据集和复杂任务时。
实际应用前景
Infini-attention模型的提出为处理长文本数据提供了新的可能性。它在长上下文语言建模、密钥检索任务和书籍摘要等任务上展现出了卓越的性能。这种模型特别适合于需要理解和生成长篇幅内容的任务,例如文档分类、问答系统、机器翻译、教育和学习系统等领域。
结论
Infini-attention模型的提出标志着Transformer模型在处理长序列数据方面的一大进步。通过压缩记忆机制,它不仅能够有效地管理内存和计算资源,还能够捕捉和整合长期依赖关系。这一突破性的工作为未来的NLP研究和应用开辟了新的道路,预示着更加高效和强大的语言模型的诞生。