原文:https://blog.iyatt.com/?p=14465
1 前言
2024.4.8
昨天接了一个代写单子,要求用 Python 实现 sed 的部分功能。我用 Linux 也有几年了,基本的命令知道,但是几乎没有写涉及高级功能的 shell 脚本,所以对于正则表达式和三剑客的使用非常模糊。这次因为要模拟 sed 的功能,所以专门来过一下知识,但是因为我可能后续也很少用,慢慢会忘掉,所以写个记录,再次需要的时候查阅一下可以快速忆起。
2 环境
WSL2:Ubuntu 22.04.03
awk 5.1.0
grep 3.7
sed 4.8
3 正则表达式(Regual Expression)
3.1 基本正则表达式(Basic Regual Expression)
\begin{array}{|l|l|}
\hline
符号 & 描述 \\
\hline
\hat{} & 尖角号,用于模式的最左侧,如“\ \hat{}abc”,匹配以 abc 开头的行 \\
\hline
\$ & 美元符,用于模式的最右侧,如“abc\$\ ”,表示以 abc 结尾的行 \\
\hline
\hat{}\ \$ & 组合符,表示空行 \\
\hline
. & 匹配任意一个且只有一个字符,不能匹配空行 \\
\hline
\backslash & 转义字符,让特殊含义的字符表示字符本身,比如\ \backslash.代表英文句点这个符号本身,而不是 RE 中的特殊含义 \\
\hline
* & 匹配前一个字符0次或多次出现 \\
\hline
.* & 组合符,匹配所有内容 \\
\hline
\hat{}\ .* & 组合符,匹配任意多个字符开头的内容 \\
\hline
.*\$ & 组合符,匹配以任意多个字符结尾的内容 \\
\hline
[abc] & 匹配[]内的任意一个字符,也可以写作[a-c],表示a到c中的任意一个字符 \\
\hline
[\ \hat{}\ abc] & \hat{}\ 表示取反,即除了 a 或 b 或 c 的字符 \\
\hline
\end{array}
3.2 扩展正则表达式(Extended Regual Expression)
\begin{array}{|l|l|}
\hline
符号 & 描述 \\
\hline
+ & 匹配前面字段出现1次或多次 \\
\hline
[ab]+ & 匹配 a 或 b 字符一次或多次 \\
\hline
? & 匹配前一个字符0次或1次 \\
\hline
| & 或者,同时过滤多个 \\
\hline
() & 分组过滤,被括起来的内容表示一个整体 \\
\hline
a\{n,m\} & 匹配前一个字符最少n次,最多m次 \\
\hline
a\{n,\} & 匹配前一个字符最少n次 \\
\hline
a\{n\} & 匹配前一个字符正好n次 \\
\hline
a\{,m\} & 匹配前一个字符最多m次 \\
\hline
\end{array}
4 三剑客
4.1 grep
Global search REgular expression and Print out the line,简称 GREP,文本搜索工具
\begin{array}{|l|l|}
\hline
参数 & 描述 \\
\hline
-v & 排除匹配结果 \\
\hline
-n & 显示匹配行与行号 \\
\hline
-i & 不区分大小写 \\
\hline
-c & 只统计匹配的行数 \\
\hline
-E & 使用扩展正则表达式,如果不用这个参数,也可以在正则表达式的符号前面加上反斜杠 \\
\hline
--color=auto & 为 grep 过滤结果添加颜色 \\
\hline
-w & 只匹配过滤的单词 \\
\hline
-o & 只输出匹配的内容 \\
\hline
\end{array}
我这里的环境中默认已经加上了颜色参数

演示操作使用的 /etc/passwd 文件,复制出来并添加了一行空行
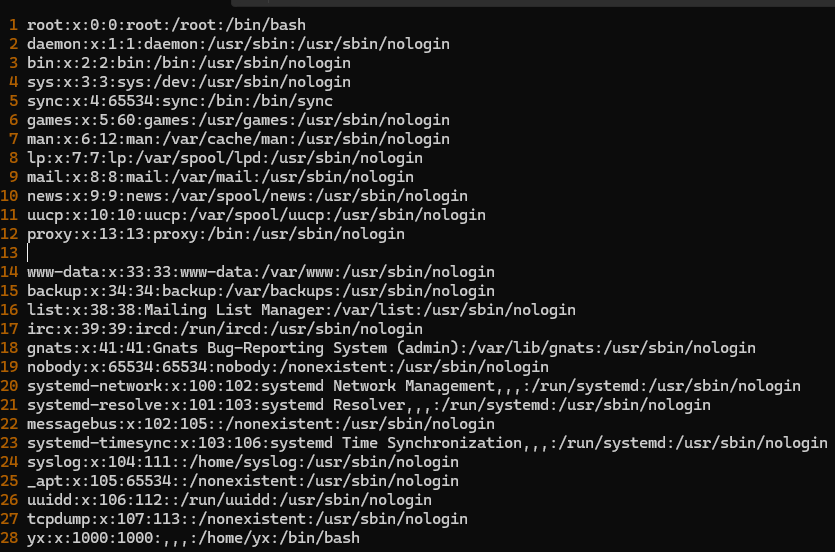
查找“/bin/bash”结尾的行

非 “/bin/bash” 结尾的行
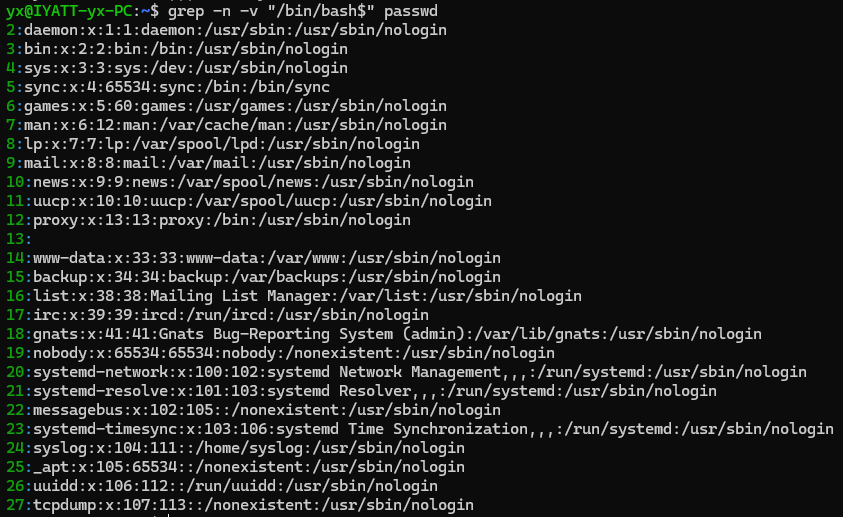
匹配以 yx 开头的行

找出空行

显示除去空行的内容,方式一
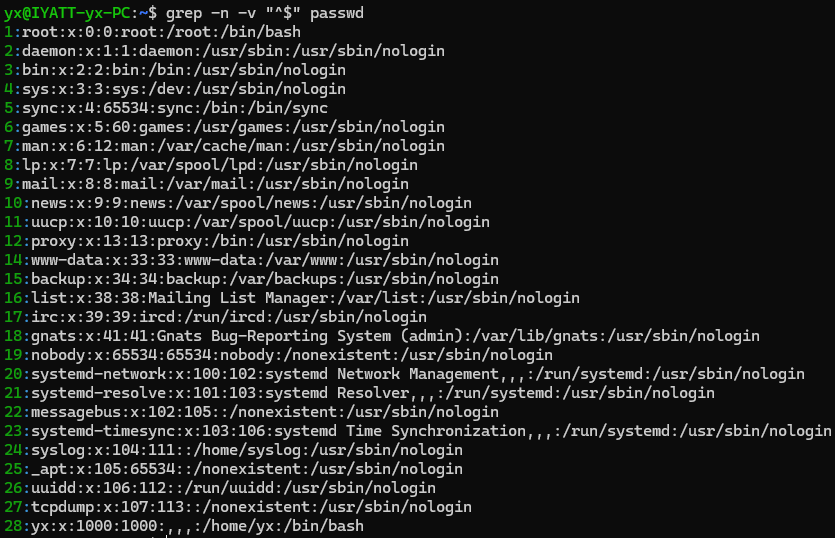
方式二

查找一个三个字符的字段,其中第一个字符为b,第三个字符为s,第二个不指定,只要是个字符就行

查找一个以 n 开头,o 结尾的字段

匹配以 log 开头的字段
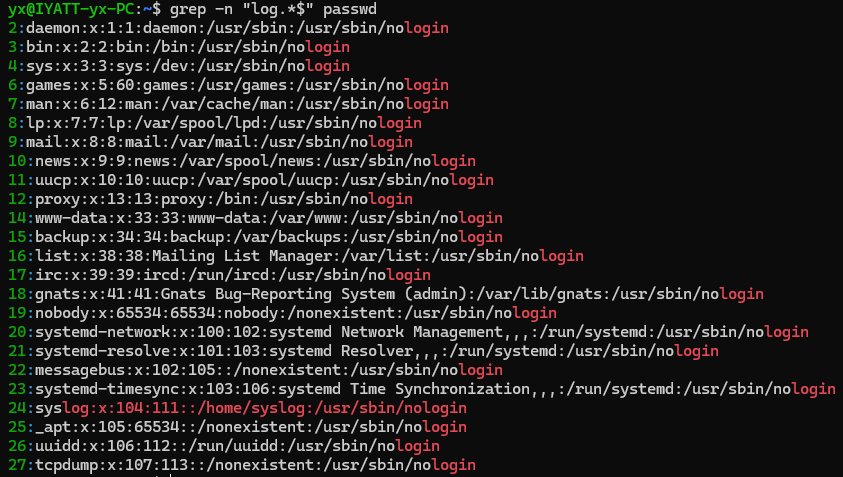
匹配以 stent 结尾的字段

匹配出现过英文逗号的行

匹配存在 E 或 N 的行

匹配存在数字的行
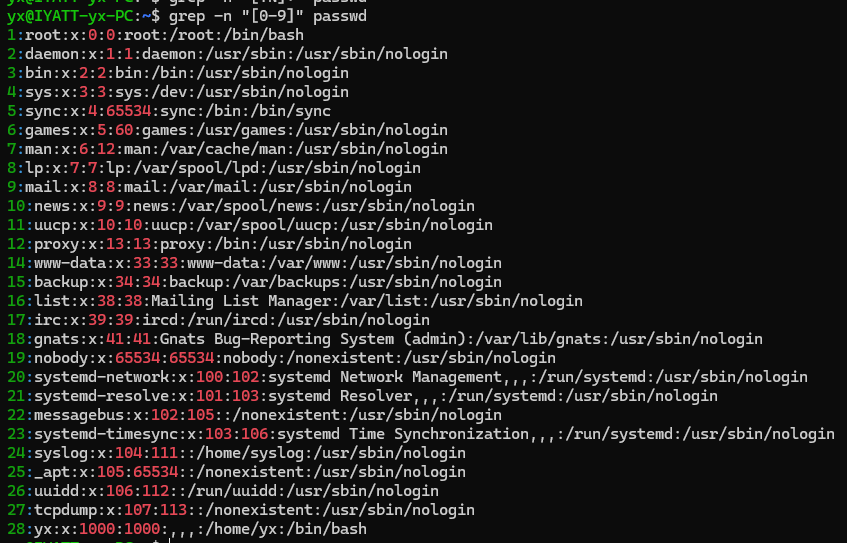
匹配存在大写字母或数字的行
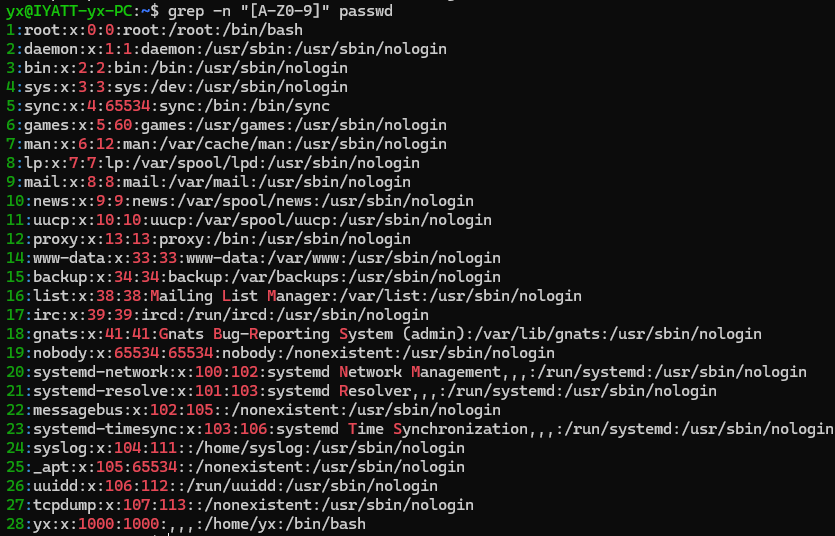

匹配存在大写字母或9的行

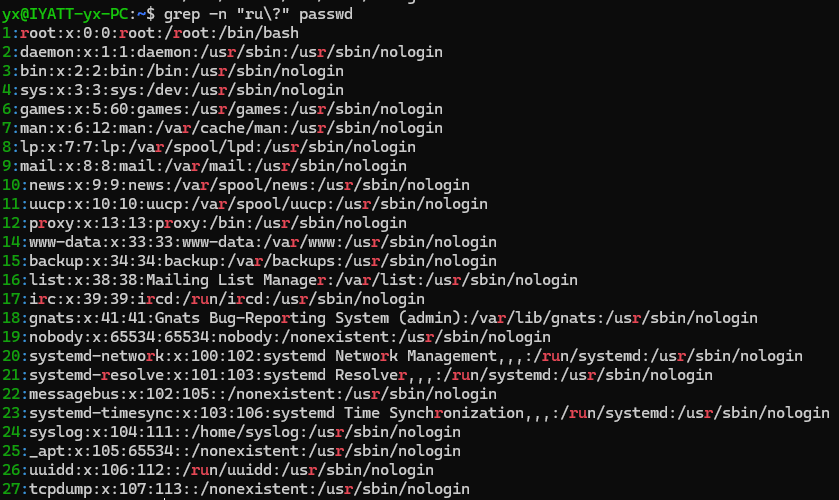
匹配r开头的字段,且下一个字段要么是u要么不是u
查找 usr 或 uid 字段(分组)
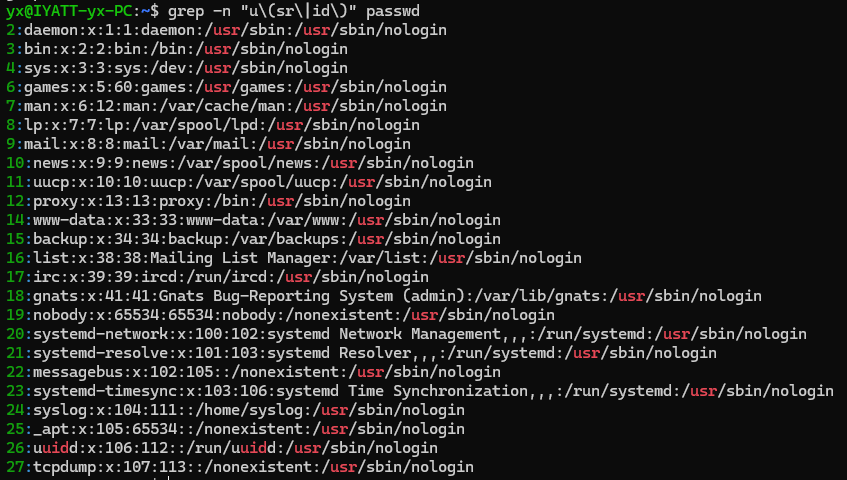
匹配开头结尾都是 yx 的字段(分组引用),用斜杠加数字引用前面括号的内容

4.2 sed
stream editor,流编辑器,文本编辑工具(增删改查)
\begin{array}{|l|l|}
\hline
选项 & 描述 \\
\hline
-n & 取消默认 sed 输出,常与sed内置命令p一起使用 \\
\hline
-i & 直接将结果写入文件,否则只是修改读取到内存中的数据 \\
\hline
-e & 多次编辑,匹配多个规则,可以替代管道的使用 \\
\hline
-r或-E & 支持扩展正则表达式,如果不使用参数,也可以在正则表达式的符号前面加上反斜杠 \\
\hline
\end{array}
\begin{array}{|l|l|}
\hline
内置命令字符 & 描述 \\
\hline
a & append,追加,在指定行后面添加一行或多行 \\
\hline
d & delete,删除匹配行 \\
\hline
i & insert,插入一行或多行 \\
\hline
p & print,打印匹配行的内容 \\
\hline
s/正则表达式/用于替换的内容/g & 内容替换,g 代表全局匹配(匹配到的行中全部替换,不加只替换行中的第一个)\\
\hline
\end{array}
\begin{array}{|l|l|}
\hline
范围 & 描述 \\
\hline
空地址 & 全文处理 \\
\hline
单地址 & 指定某一行 \\
\hline
/pattern/ & 被模式匹配到的每一行 \\
\hline
范围区间 & 10,20\ 表示10到20行,\ 10,+5\ 表示第10行向下5行 \\
\hline
步长 & 1\sim2\ 表示从1开始,然后每间隔2行,即包含后续3、5、7、9\cdots \\
\hline
\end{array}
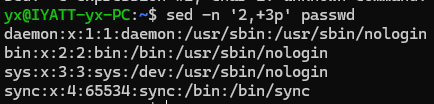
打印显示第 2、3 行
加上 -n 参数就不会显示没有匹配到的内容

打印第2行并往下继续3行
打印含 yx 的行

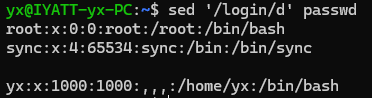
删除含有 login 的行
因为匹配到的行被删除了,这个时候要查看的是没有被删除的部分,所以不加 -n 参数,就会显示没有被匹配到的
另外,因为没有使用 -i 参数,所以文件内容实际不会修改,只是打印出修改后的效果
删除第2行开始到结尾

匹配存在 www 字段的行

从第 10 行开始匹配 nologin,并替换为 @@@@@

把 nologin 替换为 @@@@@@,同时把 yx 替换为 ####(管道)
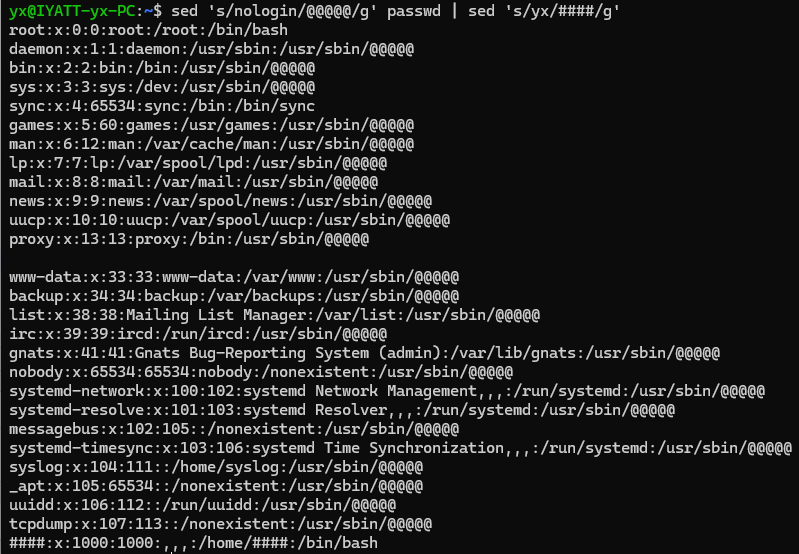
把 nologin 替换为 @@@@@@,同时把 yx 替换为 ####(参数多条件)
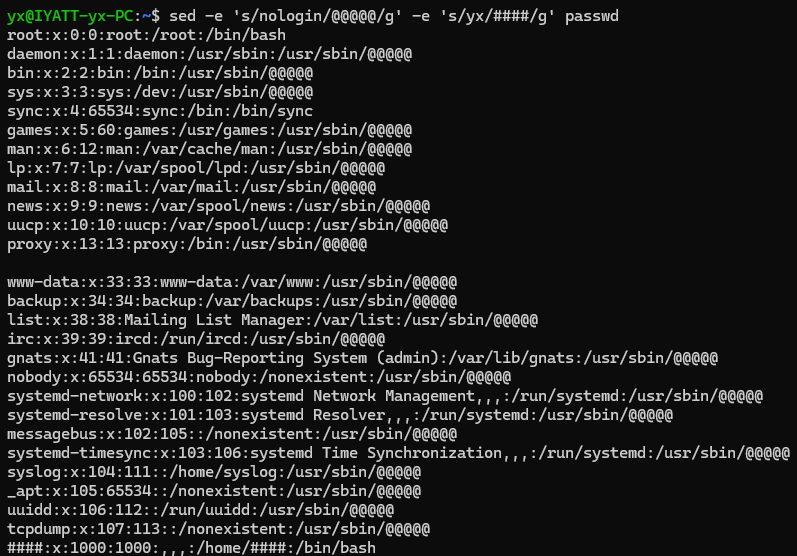
只替换行中出现的第一个 yx,不加 g 就只替换一个
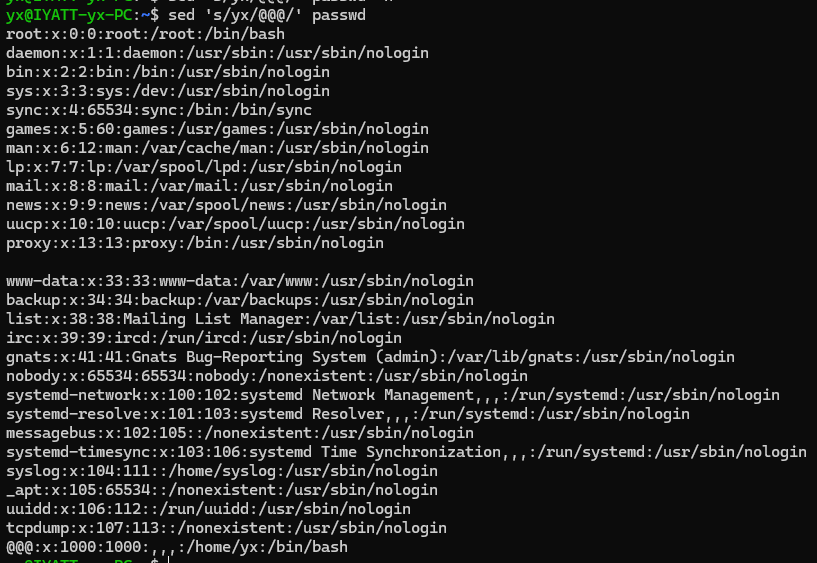
在最后一行后面加入 hello
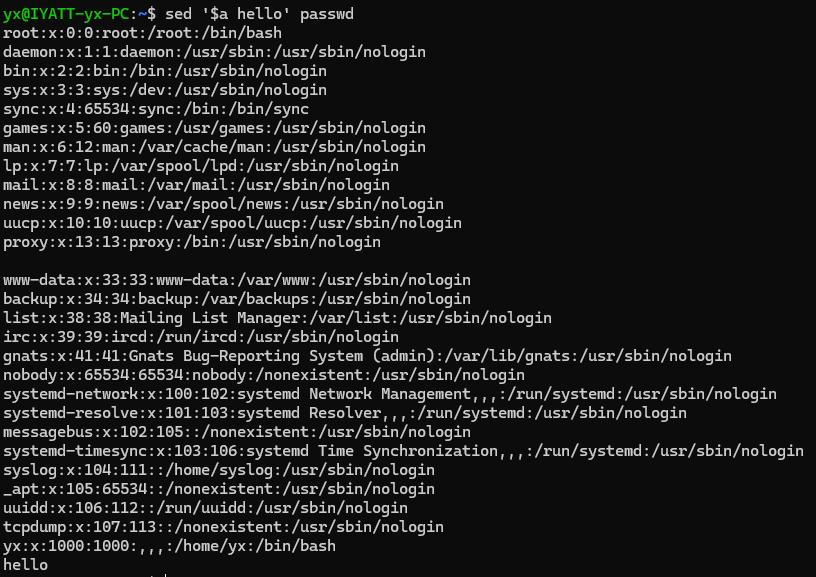
在第一行后追加 hello
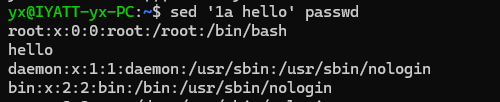
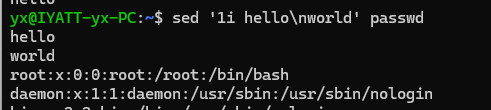
在第一行的位置插入 hello

使用 \n 换行,在第一行位置插入两行
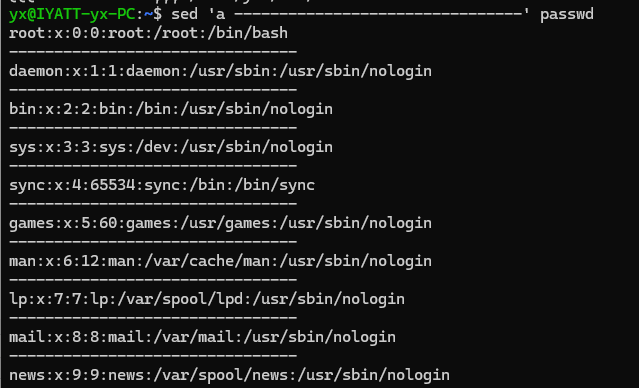
不指定行数,进行追加,对每一行都生效
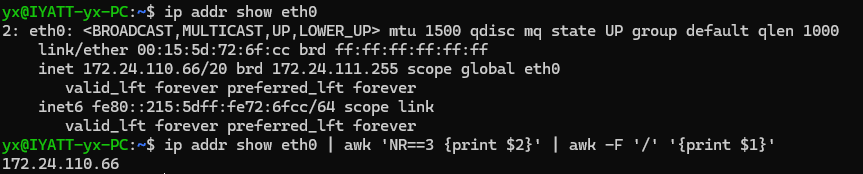
获取本机 eth0 网卡 IPv4
首先筛选出结果的第三行,然后替换去除 “inet ” 开头,再替换去除 “/数字 brd…” 即可得到纯 IPv4 字段

另外一种思路,也是类似,对第三行的首位替换消除,然后打印出修改的行

4.3 awk
格式化文本
\begin{array}{|l|l|}
\hline
内置变量 & 描述 \\
\hline
\$n & 指定分隔符后,当前记录的第n个字段(分割后的第n列) \\
\hline
\$0 & 整行的所有字段(所有列) \\
\hline
NF & Number\ of\ fields,分割后一行的字段数 \\
\hline
FS & Field\ Separator,输入字段分隔符,默认是空格 \\
\hline
OFS & Output\ Field\ Separator,输出字段分割符,默认为空格 \\
\hline
NR & Number\ of\ records,当前记录数,行数 \\
\hline
RS & Record\ Seporator,输入记录分割符(输入换行符),指定输入时的换行符 \\
\hline
ORS & Output\ Record\ Seporator,输出记录分割符,输出时的换行符号 \\
\hline
FNR & File\ Number\ of\ the\ current\ Record,各文件分别计数的行号 \\
\hline
FILENAME & 当前文件名 \\
\hline
ARGC & 命令行参数个数 \\
\hline
ARGV & 存储命令行输入的参数的数组 \\
\hline
\end{array}
\begin{array}{|l|l|}
\hline
参数 & 描述 \\
\hline
-F & 指定分割符 \\
\hline
-v & 定义或修改内部变量 \\
\hline
-f & 从脚本文件读取 awk 命令 \\
\hline
\end{array}
\begin{array}{|l|l|}
\hline
关系符 & 描述 \\
\hline
\lt & 小于 \\
\hline
\lt= & 小于等于 \\
\hline
== & 等于 \\
\hline
!= & 不等于 \\
\hline
\gt= & 大于等于 \\
\hline
\gt & 大于 \\
\hline
\sim & 匹配正则。如x\sim/正则/ \\
\hline
!\sim & 不匹配正则。如x!\sim/正则/ \\
\hline
\&\& & 逻辑与,条件同时满足 \\
\hline
|| & 逻辑或,满足任一条件 \\
\hline
\end{array}
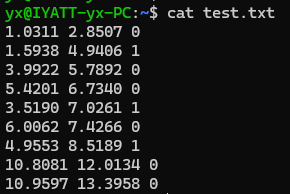
利用一段下面格式的文本演示
1.0311 2.8507 0
1.5938 4.9406 1
3.9922 5.7892 0
5.4201 6.7340 0
3.5190 7.0261 1
6.0062 7.4266 0
4.9553 8.5189 1
10.8081 12.0134 0
10.9597 13.3958 0
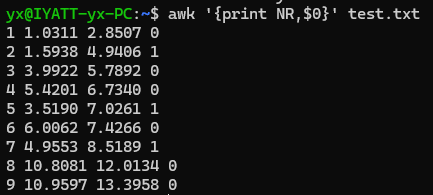
打印文件每行内容

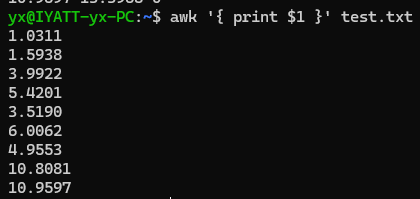
打印文件每行的第一列内容
打印文件每行的第三列内容

打印第第1列和第3列并指定输出分割符为“ ** ”
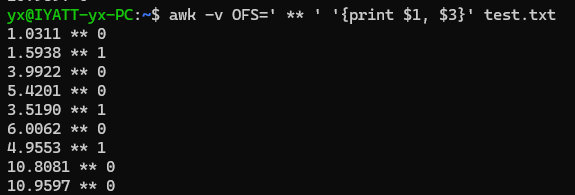
指定输出分割符为制表符
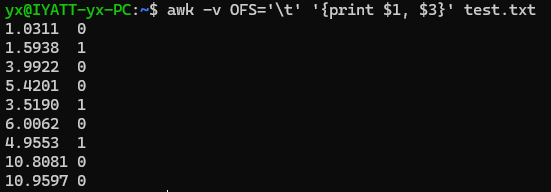
awk 默认识别的分割符为空格,这里演示一下手动指定分割符。
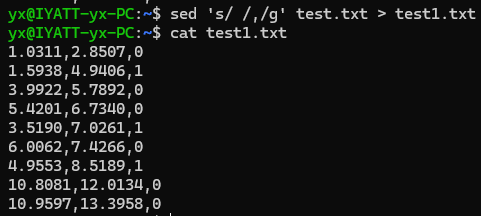
用sed把文件里的空格分割符替换为英文逗号再另存为新文件
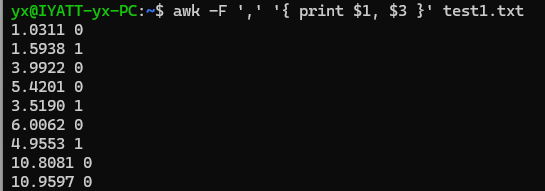
用 -F 参数指定分割符,然后打印第1、3行
为 FS 变量赋值设置分割符

自定义输出第一列和第三列

打印第 5 行的内容

打印第 5 行第 1 列
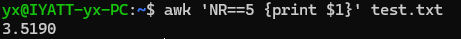
打印第2到4行的第2列

输出并显示行号
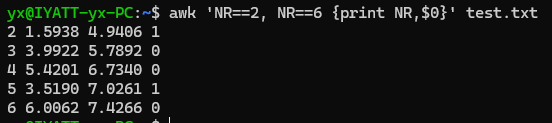
输出2到6行,并添加行号
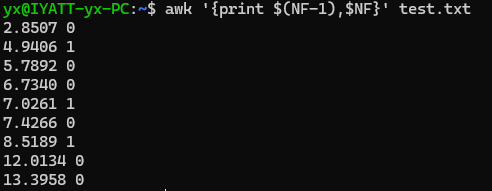
打印倒数第2行和倒数第一行
指定输入换行符为一个空格
遇到空格就换行
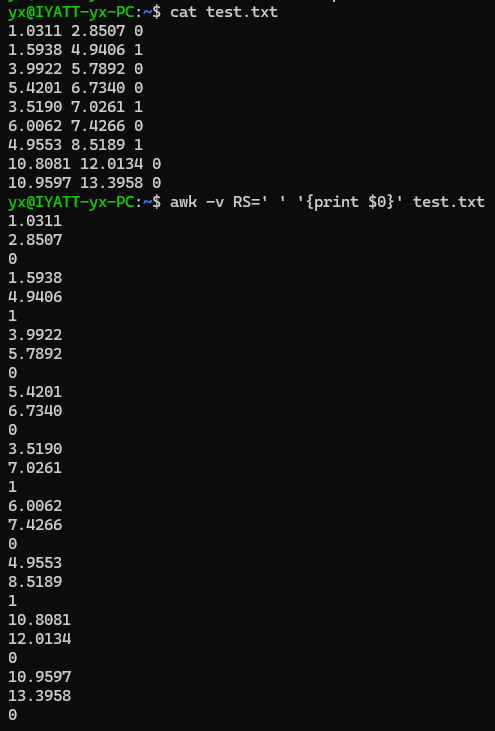
指定输出换行符为“ ##\n”
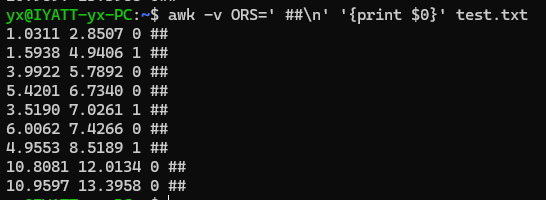
文件处理前后

打印当前文件名,行号,行数据
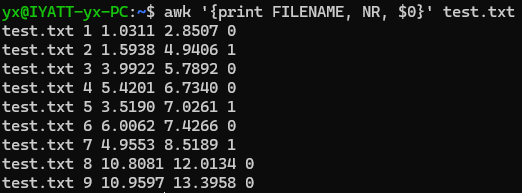
打印出参数个数和参数内容
注意数组下标从 0 开始计数
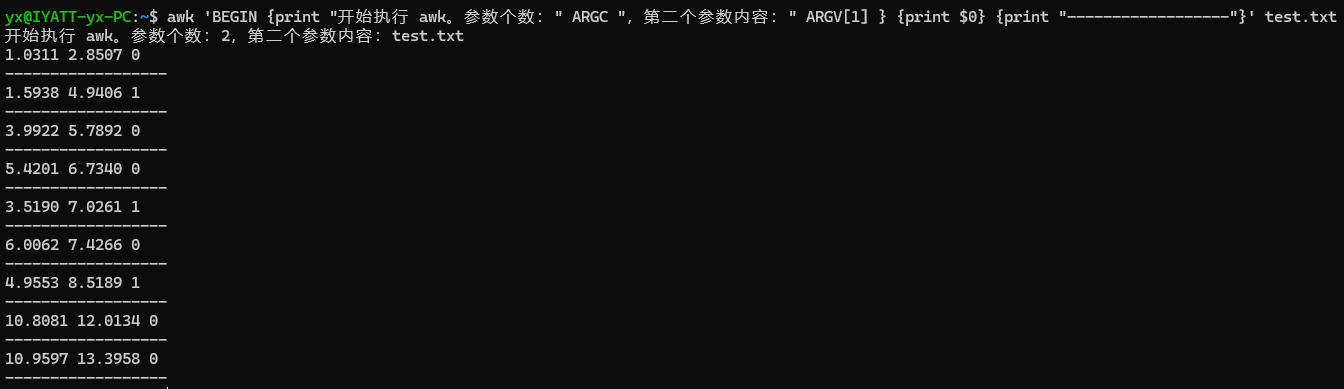
传递参数内容研究
可以发现第一个是 awk 命令本身,后面就是传入的非 awk 命令选项的参数

自定义变量 var

引用 shell 变量

printf 格式化输出,和 C 语言的 printf 格式化符差不多。另外 print 会自动添加换行符,而 printf 不会。
可以用 %g 打印小数,尾部有 0 就会自动丢弃。而用 %f 打印小数则会显示6位小数。%d 匹配整数。

只打印第一行和第三行

行数大于 2,且第一列有 5 或 9 的行才打印

第一列没有 5 和 9 的行才打印

利用 awk 提取 eth0 网卡的 IPv4 地址
筛选出第 3 行第 2 列,但是这个字段由 IP/20 组成,再次指定分割符为 /,提取第一列即可得到纯 IP 字段
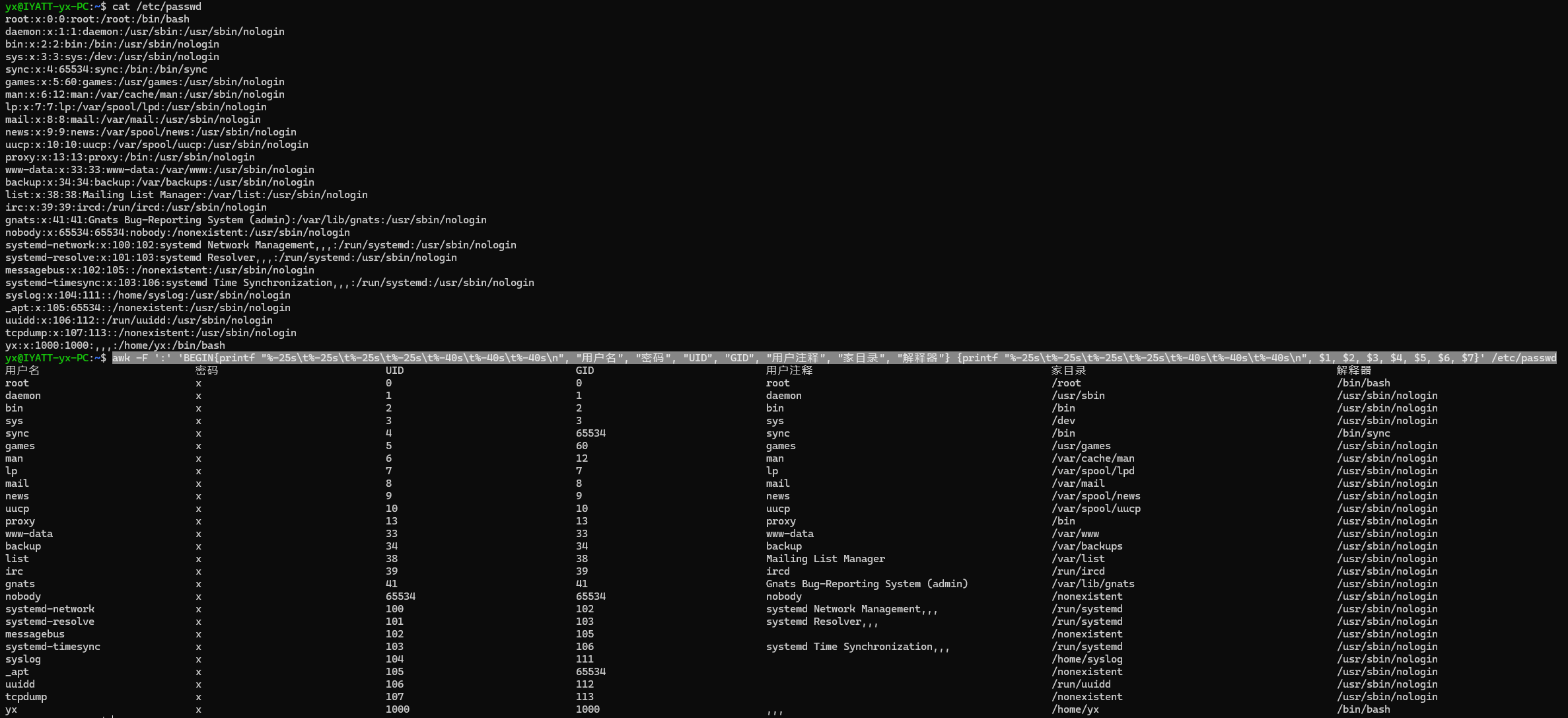
格式化输出 /etc/passwd 文件
%-25s 中 - 表示左对齐,25 表示字符串长度为 25,不足则填充空格
awk -F ':' 'BEGIN{printf "%-25s\t%-25s\t%-25s\t%-25s\t%-40s\t%-40s\t%-40s\n", "用户名", "密码", "UID", "GID", "用户注释", "家目录", "解释器"} {printf "%-25s\t%-25s\t%-25s\t%-25s\t%-40s\t%-40s\t%-40s\n", $1, $2, $3, $4, $5, $6, $7}' /etc/passwd
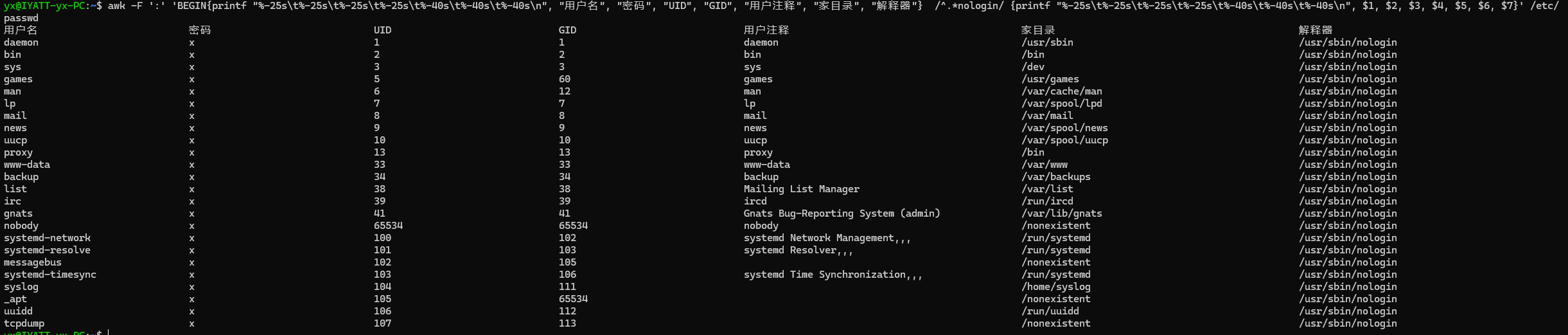
只打印 nologin 结尾的
awk -F ':' 'BEGIN{printf "%-25s\t%-25s\t%-25s\t%-25s\t%-40s\t%-40s\t%-40s\n", "用户名", "密码", "UID", "GID", "用户注释", "家目录", "解释器"} /^.*nologin/ {printf "%-25s\t%-25s\t%-25s\t%-25s\t%-40s\t%-40s\t%-40s\n", $1, $2, $3, $4, $5, $6, $7}' /etc/passwd