当一个子查询介于select 与from之间,这种子查询就叫标量子查询。
标量子查询类似于函数,在结果集返回的每一行增加一个函数列。
标量的意思就是对于一个具体的输入值输出的的是一个特定的值,不是随机的值。
----在函数中也有这个概念。如果定以了标量,在分区裁剪的时候就可以使用partition single,而不是partition all
1、定义
标量子查询是一个子查询,它只从一行中返回一个列值。
标量子查询表达式的值是子查询的可选列表项的值。
如果子查询返回 0 行,则标量子查询表达式的值为 NULL。
如果子查询返回多行,则报错。
可以在大多数要求表达式 (expr) 的语法中使用标量子查询表达式。
在所有情况下,标量子查询必须包含在其自己的括号中,即使其句法位置已将其定位在括号内(例如,当标量子查询用作内置函数的参数时)。
2、他不能用在如下条件中:
不能作为列的默认值
不能作为cluster的哈希表达式(hash)
不能用在 DML 语句的返回子句中
不能作为基于函数的索引的基础
不能用在check约束中
Scalar Subquery Expressions
A scalar subquery expression is a subquery that returns exactly one column value from one row. The value of the scalar subquery expression is the value of the select list item of the subquery. If the subquery returns 0 rows, then the value of the scalar subquery expression is NULL. If the subquery returns more than one row, then Oracle returns an error.
标量子查询表达式是一种从一行只返回一个列值的子查询。标量子查询表达式的值就是子查询的选择列表项的值。如果子查询返回0行,则标量子查询表达式的值为NULL。如果子查询返回多于一行,Oracle将返回一个错误。
You can use a scalar subquery expression in most syntax that calls for an expression (expr). In all cases, a scalar subquery must be enclosed in its own parentheses, even if its syntactic location already positions it within parentheses (for example, when the scalar subquery is used as the argument to a built-in function).
在大多数调用表达式(expr)的语法中,都可以使用标量子查询表达式。在任何情况下,标量子查询都必须用自己的圆括号括起来,即使它的语法位置已经把它放在圆括号中(例如,当标量子查询用作内置函数的参数时)
Scalar subqueries are not valid expressions in the following places:
标量子查询在以下位置不是有效的表达式:
(1)As default values for columns
作为列的默认值
(2)As hash expressions for clusters
作为集群的散列表达式
(3)In the RETURNING clause of DML statements
在DML语句的返回子句中
(4)As the basis of a function-based index
作为基于函数的索引的基础
(5)In CHECK constraints
在检查约束
(6)In GROUP BY clauses
按group by 子句
(7)In statements that are unrelated to queries, such as CREATE PROFILE
在与查询无关的语句中,如CREATE PROFILE
尽量避免使用标量子查询,假如主表示返回大量数据,主表的连接列基数很高,那么子查询中的表会被多次扫描,从而严重影响SQL性能。如果主表数据量小,或者主表的连接列基数很低 (标量子查询会缓存distinct后的值对应的结果集),那么这个时候我们也可以使用标量子查询,但要记得要给子查询中表的连接列建立索引。
Q: 如何优化SQL中标量子查询
可以将标量子查询等价改写为外连接,从而使它们可以进行HASH连接。
Q:为什么要将标量子查询改写为外连接而不是内连接呢?
因为标量子查询是一个传值的过程,如果主表传值给子查询,子查询没有查询到数据,这个时候会显示NULL。如果将标量子查询改写为内连接,会丢失没有关联上的数据。
select d.dname, d.loc,
(select max(e.sal) from emp e where e.deptno = d.deptno) max_sal
from dept d;
DNAME LOC MAX_SAL
-------------- ------------- ----------
ACCOUNTING NEW YORK 5000
RESEARCH DALLAS 3000
SALES CHICAGO 2850
OPERATIONS BOSTON
4 rows selected.
select d.dname, d.loc, e.max_sal
from dept d
left join (select max(sal) max_sal, deptno from emp group by deptno) e
on d.deptno = e.deptno;
DNAME LOC MAX_SAL
-------------- ------------- ----------
ACCOUNTING NEW YORK 5000
RESEARCH DALLAS 3000
SALES CHICAGO 2850
OPERATIONS BOSTON
--------------标量子查询的执行计划
背景
群中小伙伴遇到生产环境SQL执行1小时都没有出来,是一个insert select,如下是查询语句部分,从语句写法来看应该是N:N关系,这个是标量子查询语句.类似NL,不能使用HASH JOIN(FILTER具有去重功能),外层表结果集越大,内层表被循环次数越多。适合外层表满足条件结果集少且内层表走高效执行计划的场景,这个例子外层表是50万,内层表是6万。结果集就是小于等于50万.最多循环50万次,如果循环1次是10msm,那么执行时间5000s(符合生产环境超过1小时无法执行出来),如果是1ms,那么执行时间是500s.如果0.5ms,50s.在循环传值情况下,单次执行时间*总次数=理论时间.所以外层表特别大的情况,此时改写来成外连接来提升效率,否则生产环境会遇到性能问题。
具体SQL
SELECT DISTINCT TO_CHAR(APPLY.ADD_TIME, 'yyyymmdd') CAL_NUMBER,
APPLY.APPLY_ID,
(SELECT XUB.EXPIRE_TIME
FROM (SELECT *
FROM TMP_DM_RPT_MICCN_COM_UPG0 C ORDER BY C.ADD_TIME DESC) XUB WHERE XUB.COM_ID = APPLY.COM_ID AND XUB.ADD_TIME <= APPLY.ADD_TIME AND ROWNUM < 2) AS LAST_EXPIRE_TIME,
DECODE(APPLY.APPLY_TYPE, 0, '组织', 1, '个体') APPLY_TYPE,
APPLY.COM_ID,
APPLY.ORDER_TIME,
APPLY.UPDATE_TIME,
APPLY.LAST_CHECK_TIME
FROM ODS_MEMBER_UPGRADE_APPLY_CN APPLY;
【原执行计划】
备注:本地模拟数据构造相同的执行计划,差别在于数据量而已(不影响执行计划)
ODS_MEMBER_UPGRADE_APPLY_CN:5万,TMP_DM_RPT_MICCN_COM_UPG0:6万与生产在一个数理级别.不过从执行计划来单次是2ms+300buffer gets成本.
存在问题:
1、内层表没有索引,全表扫描加上排序
2、被驱动次数为50万次数
如果尝试创建一个索引,验证下效果?
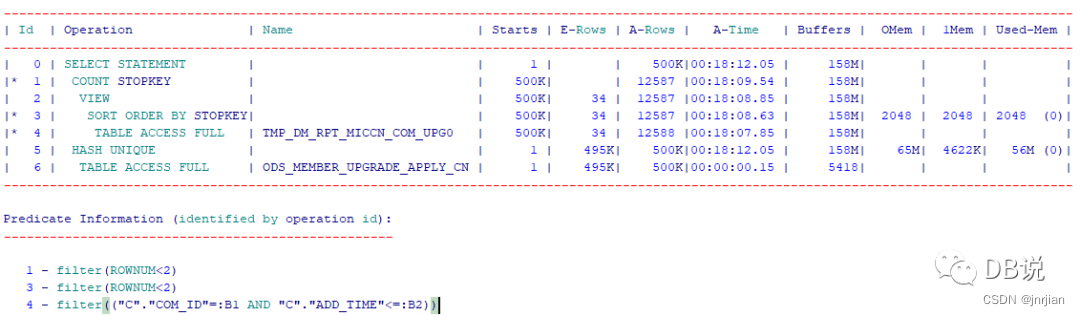
【新执行计划】
1、创建索引,在被驱动表上创建索引即可,驱动表无需创建索引
create index idx01_DM_RPT_MICCN_COM_UPG0 on TMP_DM_RPT_MICCN_COM_UPG0(COM_ID,ADD_TIME)
2、执行计划性能
1、创建索引后,被驱动表走索引降序扫描方式,无需进行排序
2、buffer gets从158M下降到528K,执行时间从18分钟下降2分钟.单次执行效率:0.2ms+1个buffer gets(相比之前单次执行是2ms+300buffer gets( 158M/500k).)
疑问:如果数理级别提升,从50万变成5000万,理想执行时间为120s*100=12000/3600=3.3H(实际情况随着表大小变化以及系统负载情况等情况,执行时间应该更长)
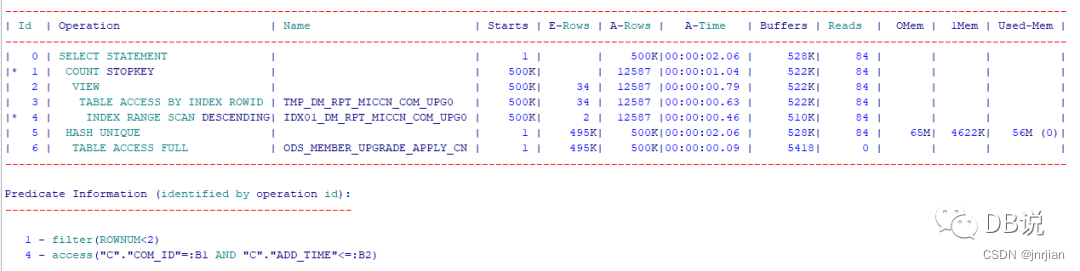
---标量子查询的执行计划时反的,驱动表表在下面,因为 ID=4中是变量,这个变量是从下面驱动表来的
3、问题
数量级上升后,索引作用也弱化很多,因为filter类似嵌套循环,大表应该改成hash join,如何等价改成?需要了解标量子查询特征:
1、外层表传值到内层表,找到结果,则为NULL
2、如果匹配到则返回最多有且只有1行1列值,返回多行则会报错。
基于以上特征:必须改写成外连接且需要去重
【改写后SQL&执行计划】
1、left join ---没有看到left join
因为标量子查询是一个传值的过程,如果主表传值给子查询,子查询没有查询到数据,这个时候会显示NULL。如果将标量子查询改写为内连接,会丢失没有关联上的数据。
select distinct CAL_NUMBER,
APPLY_ID,
EXPIRE_TIME,
XADD_TIME,
APPLY_TYPE,
COM_ID,
ORDER_TIME,
UPDATE_TIME,
LAST_CHECK_TIME
from (select TO_CHAR(APPLY.ADD_TIME, 'yyyymmdd') CAL_NUMBER,
APPLY.APPLY_ID,
XUB.EXPIRE_TIME,
XUB.ADD_TIME XADD_TIME,
DECODE(APPLY.APPLY_TYPE, 0, '组织', 1, '个体') APPLY_TYPE,
APPLY.COM_ID,
APPLY.ORDER_TIME,
APPLY.UPDATE_TIME,
APPLY.LAST_CHECK_TIME,
row_number() over(partition by APPLY.COM_ID, XUB.COM_ID order by XUB.ADD_TIME desc) RN
FROM YTRPT.ODS_MEMBER_UPGRADE_APPLY_CN APPLYLEFT
JOIN YTRPT.TMP_DM_RPT_MICCN_COM_UPG0 XUB
ON APPLY.COM_ID = XUB.COM_ID
and XUB.ADD_TIME <= APPLY.ADD_TIME)
where rn = 1
------这个在ETL下好像很常见
2、执行计划
1、执行时间从128s下降到2s(这个里面没有算网络返回时间),buffer gets从528K下降到5700.效率提升N倍。
2、效率是提升N倍,但是否等价这个如何验证?为了验证准备,我们沟通10条数据进行验证。
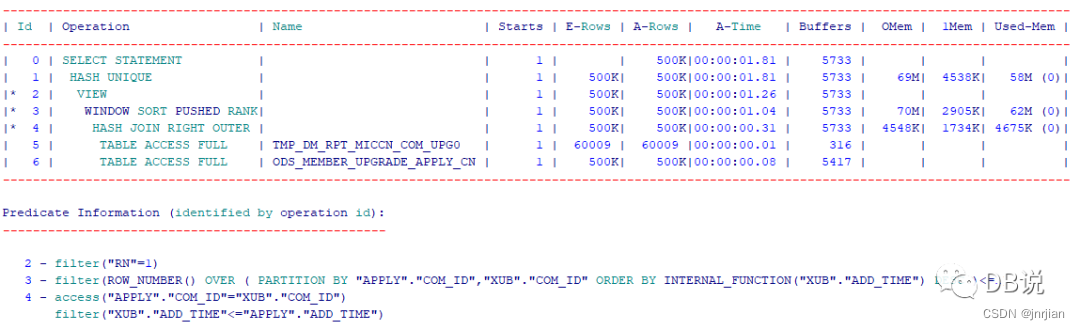
等价验证
1、构造2个小表AA、BB(来自原表数据)
备注:2个表满足:N:1,1:1,1:N,N:N关系
2、验证结果集--2者结果集相同,说明改写是正确的.
1、原始SQL结果集
2、LEFT JOIN结果集
总结
通过了解标量子查询固有特征,在大结果集存在性能问题,索引在一定量结果集下能够改善性能,如呈现数据量增长后,单次执行时间*总执行次数得到时间是可能是一个恐怖的值,程序执行时间可能是小时或者天单位,那么程序的性能是不可结果,大结果集必须改成JOIN方式能够大大提升性能。
改写主要是等价的,需要关注表之间关系是1:1,还是1:N、N:N的,如是自己构造数据,需要考虑各种可能性,否则性能可能提升,但与原SQL不等价。