创造通用具身智能,即创造能够在物理世界中敏捷、灵巧和理解的智能体——就像动物或人类一样——是人工智能 (AI) 研究人员和机器人专家的长期目标之一。动物和人类不仅是自己身体的主人,能够流畅而轻松地执行和组合复杂的动作,而且还可以感知和理解他们的环境,并利用他们的身体来影响世界上的复杂结果。
近些年基于学习的方法加速了这方面研究,特别是,深度强化学习(深度RL)已被证明能够解决模拟角色和物理机器人的复杂运动控制问题。高质量的四足机器人已经广泛使用,但是,致力于控制人形机器人和两足动物的工作要少得多,这在稳定性、机器人安全性、自由度数量和合适硬件的可用性方面带来了额外的挑战。现有的以学习为基础的工作比较有限,侧重于学习和转移不同的基本技能,如走路、跑步、爬楼梯和跳跃。人形控制的最新技术使用基于目标模型的预测控制,从而限制了该方法的通用性。
Google DeepMind 发表的Science Robotic 工作重点是基于学习的人形机器人的全身控制,用于长期任务。特别是使用深度RL来训练低成本的现成机器人来踢多机器人足球,远远超出这种机器人直观期望的敏捷性和流畅性水平。像足球这样的运动展示了人类感觉运动智能的许多特征,这在机器人社区中得到了认可,特别是通过RoboCup计划。 他们考虑了完整足球问题的一个子集,并训练了一个智能体在模拟中玩简化的一对一(1v1)足球,并直接将学习到的策略部署到真实的机器人上(下图)。他们专注于本体感觉和动作捕捉观察中的感觉运动全身控制。
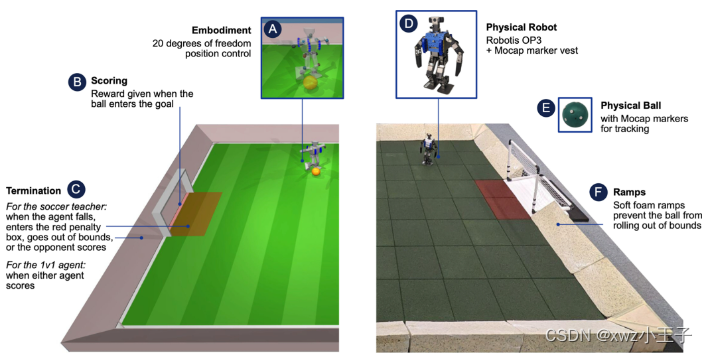
在第一阶段,他们训练了两种技能:一种是从地上站起来,另一种是在面对未经训练的对手时进球。在第二阶段,他们通过提炼技能并以自我游戏的形式使用多智能体训练来训练智能体完成完整的 1v1 足球任务,其中对手是从智能体本身的部分训练副本池中抽取的。因此,在第二阶段,智能体学会了结合以前学到的技能,将它们提炼成完整的足球任务,并预测和预测对手的行为。他们使用了一小组塑形奖励、领域随机化以及随机推送和扰动来改进探索并促进安全转移到真实机器人。

未来工作的一个令人兴奋的方向是培训由两个或更多代理组成的团队。在这种情况下,应用他们提出的方法来训练智能体是很简单的。在他们对 2v2 足球的初步实验中,看到智能体学会了分工,这是一种简单的协作形式:如果队友离球更近,那么智能体就不会接近球。然而,它也学到了更少的敏捷行为。从先前的仿真工作中获得的见解可用于提高此设置下的性能。
未来工作的另一个重要方向是仅从机载传感器中学习,而没有来自动作捕捉系统的外部状态信息。与可以直接访问球、球门和对手位置的基于状态的智能体相比,基于视觉的智能体需要从有限的高维以自我为中心的相机观察历史中推断信息,并随着时间的推移整合部分状态信息。