目录
什么是Quartz?
Job详解
Trigger详解
1、优先级
2、misfire:错过触发
1)判断条件
2)产生原因(可能情况)
3)策略
Scheduler详解
JobDataMap详解
SpringBoot整合Quartz
引入依赖
定义Job类
配置调度器
监听
Quartz的基本配置
1、Scheduler配置
2、Seheduler线程池配置
3、JobStore作业存储配置
什么是Quartz?
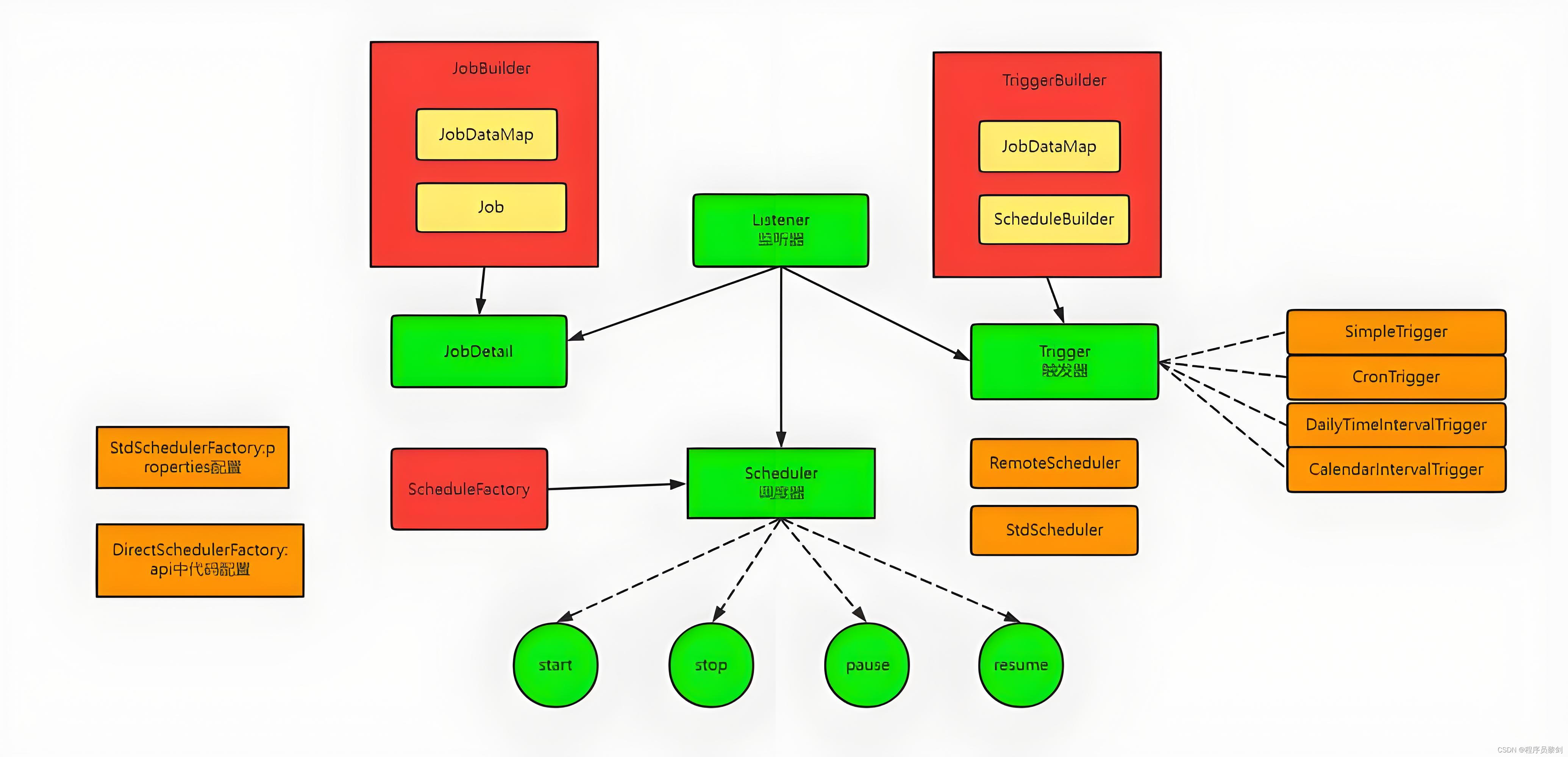
Quartz是一个框架,是SpringBoot御用的定时任务框架,有三大核心部分组成,分别是Job,Trigger、Scheduler。
Job:任务,可以理解成你要做什么事,具体要执行的业务逻辑,比如:发送短信、同步数据、发送邮件等。
Trigger:触发器,可以理解成你什么时候去做,用来定义Job触发条件、触发时间、触发间隔、终止时间等。
Scheduler:调度器,可以理解成你什么时候要去做什么事,它会启动Trigger去执行Job。
思维导图:
Job详解
Job:Job封装成JobDetail,设置属性
1)注解@DisallowConcurrentExecution:禁止并发地执行同一个job定义,同时需要保证任务顺序执行。
2)注解@PersistJobDataAfterExecution:持久化JobDetail中的JobDataMap(对trigger中的dataMap无效),如果一个任务不是持久化的,则当没有触发器关联它的时候,Quartz会从scheduler中删除它。
3)如果一个任务请求恢复,一般是该任务执行启动发生了系统崩溃或者其他关闭进程的操作
Trigger详解
1、优先级
1)同时触发的tigger之间才会比较优先级。
2)如果trigger是可以恢复的,在恢复后再调度时,优先级不变。
2、misfire:错过触发
1)判断条件
a. job到达触发时间时没有被执行。
b. 被执行的延迟时间超过了Quartz配置的misfireThreshold阈值。
2)产生原因(可能情况)
a. 当job到达触发时间时,所有线程都被其他job占用,没有可用的线程
b. 在job需要触发的时间点,scheduler停止了(可能是意外停止)
c. job使用了@DisallowConcurrentExecution注解,job不能并发执行,当达到下一 个job执行点的时候,上一个任务还没完成
d. job指定了过去的开始执行时间,例如当前时间时9点00分00秒,指定开始时间为8点00分00秒
3)策略
针对不同异常情况,Quartz提供了以下几种策略方案
a. 默认使用MISFIRE_INSTRUCTION_SMART_POLICY
b. SimpleTrigger
now*相关的策略的策略:会立即执行第一个misfire的任务,同时会修改startTime和repeatCount,因此会重新计算finalFireTime,原计划执行时间会被打乱。
next*相关的策略:不会立即执行misfire的任务,也不会修改startTime和repeatCount,因此finalFireTime不会被重新计算,misfire也是按照原计划进行执行。
c. CronTrigger
如图所示:
// 所有的misfile任务马上执行
public static final int MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY = -1;// 在Trigger中默认选择MISFIRE_INSTRUCTION_FIRE_ONCE_NOW 策略
public static final int MISFIRE_INSTRUCTION_SMART_POLICY = 0;// 合并部分misfire,正常执行下一个周期的任务。
public static final int MISFIRE_INSTRUCTION_FIRE_ONCE_NOW = 1;// 所有的misFire都不管,执行下一个周期的任务。
public static final int MISFIRE_INSTRUCTION_DO_NOTHING = 2;备注:
- calendar:用于排除时间段
- SimpleTrigger:具体时间点,指定时间间隔重复执行
- CronTrigger:cron表达式
Scheduler详解
顾名思义,即调度器,基于trigger的设定执行job
1、SchedulerFactory
1)创建Scheduler
2)DirectSchedulerFactory:在代码里定制Scheduler参数
3)StdSchedulerFactory:读取classpath下的quartz.properties配置来实例化Scheduler
2、JobStore
存储运行时的信息,包括Trigger、Scheduler、JobDetail,业务锁等
1)RAMJobStore:内存实现,轻量级,速度快,应用重启时相关信息都将丢失。
2)JobStoreTX:JDBC,事务有Quartz管理,通俗来讲就是不参与到全局事务中去,我这边做完数据库操作我就自己提交或者回滚
3)JobStoreCMT:JDBC,使用容器(全局)事务,不会自己去管理事务,在完成数据库操作时,它不会自己提交,由全局事务管理程序对全局事务进行统一的提交或者回滚
4)ClusteredJobStore:集群实现
5)TerracottaJobStore:Terracotta中间件
JobDataMap详解
主要功能和作用:
数据传递:允许你在调度任务时传递必要的参数。
状态共享:在不同的任务执行实例之间共享数据。
JobDetail: JobDetail是Job的具体实例,包含了任务的详细信息和配置。它是任务的描述符,用于定义任务的各种属性,如任务的名称、组名、任务类、任务数据等。
SpringBoot整合Quartz
引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-quartz</artifactId></dependency>定义Job类
然后定义一个Job,也就是我们的业务逻辑,如:QuartzJob 如下所示:
import org.quartz.DisallowConcurrentExecution;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.PersistJobDataAfterExecution;
import org.quartz.SchedulerException;
import org.springframework.scheduling.quartz.QuartzJobBean;import java.util.Date;/*** @description:* @author: 黎剑* @create: 2024-04-13 22:58**/
@PersistJobDataAfterExecution
@DisallowConcurrentExecution
public class QuartzJob extends QuartzJobBean {@Overrideprotected void executeInternal(JobExecutionContext context) throws JobExecutionException {try {Thread.sleep(2000);System.out.println(context.getScheduler().getSchedulerInstanceId());System.out.println("taskName=" + context.getJobDetail().getKey().getName());System.out.println("执行时间:" + new Date());} catch (InterruptedException e) {e.printStackTrace();} catch (SchedulerException e) {e.printStackTrace();}}
}配置调度器
接着定义个调度器,一个调度器可以出调度多个调度器以及多个任务,所以调度器可以设置一个,放到spring容器中。,如下:
import org.quartz.Scheduler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.config.PropertiesFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;import javax.sql.DataSource;
import java.io.IOException;
import java.util.Properties;
import java.util.concurrent.Executor;/*** @description: 调度器配置* @author: 黎剑* @create: 2024-04-13 23:04**/
@Configuration
public class SchedulerConfig {@Autowiredprivate DataSource dataSource;@Beanpublic Scheduler scheduler() throws IOException {return schedulerFactoryBean().getScheduler();}@Beanpublic SchedulerFactoryBean schedulerFactoryBean() throws IOException {SchedulerFactoryBean factory = new SchedulerFactoryBean();factory.setSchedulerName("cluster_scheduler");// 注入数据源factory.setDataSource(dataSource);// 选填factory.setApplicationContextSchedulerContextKey("application");factory.setQuartzProperties(quartzProperties());// 读线程池配置factory.setTaskExecutor(schedulerThreadPool());// 等待设置其他属性return factory;}@Beanpublic Properties quartzProperties() throws IOException {PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();propertiesFactoryBean.setLocation(new ClassPathResource("/spring-quartz.properties"));propertiesFactoryBean.afterPropertiesSet();return propertiesFactoryBean.getObject();}@Beanpublic Executor schedulerThreadPool() {ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();// 处理器的核心数taskExecutor.setCorePoolSize(Runtime.getRuntime().availableProcessors());// 最大线程数taskExecutor.setMaxPoolSize(Runtime.getRuntime().availableProcessors());// 容量taskExecutor.setQueueCapacity(Runtime.getRuntime().availableProcessors());return taskExecutor;}
}监听
然后,应该在springboot容器启动完成后,自动去启动我们的任务调度,如何实现呢? 可以通过监听器来实现,springboot中的监听器。 如下:
import org.quartz.CronScheduleBuilder;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
import org.quartz.TriggerKey;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationListener;
import org.springframework.context.event.ContextRefreshedEvent;
import org.springframework.stereotype.Component;/*** @description:* @author: 黎剑* @create: 2024-04-13 23:23**/
@Component
public class StartApplicationListener implements ApplicationListener<ContextRefreshedEvent> {@Autowiredprivate Scheduler scheduler;@Overridepublic void onApplicationEvent(ContextRefreshedEvent event) {// 开启调度// 可以先判断触发器是否存在/*** JobDetail有一个类型为JobKey的重要属性key,相当于是该任务的键值,JobDetail注册到任务调度器Schedule中的时候,key值不允许重复。***整个任务调度过程中,Quartz都是通过Jobkey来唯一识别JobDetail的。试图将重复键值的JobDetail注册到任务调度器中而不指定覆盖的话,是不被允许的。***** JobKey可以通过JobBuiler的withIdentity方法指定,该方法接收name或name+group参数,从而唯一确定一个任务JobDetail。** 如果在JobDetail创建过程中不指定JobKey的话,Quartz会通过UUID的方式为该任务生成一个唯一的key值。** ***所以,同一个Job实现类(也就是同一个任务),可以通过不同的JobKey值注册到任务调度器中、绑定不同的触发器执行!*/TriggerKey triggerKey = TriggerKey.triggerKey("trigger1", "group1");try {Trigger trigger = scheduler.getTrigger(triggerKey);if (trigger == null) {// 触发器TriggerBuilder.newTrigger().withIdentity(triggerKey).withSchedule(CronScheduleBuilder.cronSchedule("0/10 * * * * ?")).build();//JobDetail jobDetail = JobBuilder.newJob(QuartzJob.class).withIdentity("job1", "group1").build();scheduler.scheduleJob(jobDetail, trigger);scheduler.start();}} catch (SchedulerException e) {e.printStackTrace();}}
}Quartz的基本配置
1、Scheduler配置
#============================================================================
# Scheduler 调度器属性配置
#============================================================================
# 调度标识名 集群中每一个实例都必须使用相同的名称,可以为任意字符串,对于scheduler来说此值没有意义,但是可以区分同一系统中多个不同的实例
org.quartz.scheduler.instanceName = ClusterQuartz
# ID设置为自动获取 每一个必须不同
org.quartz.scheduler.instanceId= AUTOorg.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false# 默认false,若是在执行Job之前Quartz开启UserTransaction,此属性应该为true。
#Job执行完毕,JobDataMap更新完(如果是StatefulJob)事务就会提交。默认值是false,可以在job类上使用@ExecuteInJTATransaction注解,
# 以便在各自的job上决定是否开启JTA事务。
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false
#一个scheduler节点允许接收的trigger的最大数,默认是1,这个值越大,定时任务执行的越多,但代价是集群节点之间的不均衡。
org.quartz.scheduler.batchTriggerAcquisitionMaxCount=12、Seheduler线程池配置
#============================================================================
# 配置ThreadPool
#============================================================================
# 线程池的实现类(一般使用SimpleThreadPool即可满足几乎所有用户的需求)
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool# 指定线程数,一般设置为1-100直接的整数,根据系统资源配置
org.quartz.threadPool.threadCount = 10# 设置线程的优先级(可以是Thread.MIN_PRIORITY(即1)和Thread.MAX_PRIORITY(这是10)之间的任何int 。默认值为Thread.NORM_PRIORITY(5)。)
org.quartz.threadPool.threadPriority = 5#加载任务代码的ClassLoader是否从外部继承
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread= true#是否设置调度器线程为守护线程
org.quartz.scheduler.makeSchedulerThreadDaemon=true3、JobStore作业存储配置
#============================================================================
# 配置JobStore
#============================================================================
# JobDataMaps是否都为String类型,默认false
# 若是true的话,便可不用让更复杂的对象以序列化的形式保存到BLOB列中
org.quartz.jobStore.useProperties=false# 存储相关信息表的前缀,默认QRTZ_
org.quartz.jobStore.tablePrefix = QRTZ_# 是否加入集群
#是否是应用在集群中,当应用在集群中时必须设置为TRUE,否则会出错。
#如果有多个Quartz实例在用同一套数据库时,必须设置为true。
org.quartz.jobStore.isClustered = true# 调度实例失效的检查时间间隔 ms
#只用于设置了isClustered为true的时候,设置一个频度(毫秒),用于实例报告给集群中的其他实例。
#这会影响到侦测失败实例的敏捷度。
org.quartz.jobStore.clusterCheckinInterval = 5000# 当设置为“true”时,此属性告诉Quartz 在非托管JDBC连接上调用setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED)。
org.quartz.jobStore.txIsolationLevelReadCommitted = true# 数据保存方式为数据库持久化,选择JDBC的存储方式
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX# 数据库代理类,一般org.quartz.impl.jdbcjobstore.StdJDBCDelegate可以满足大部分数据库
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate#这个值必须datasource的配置信息
org.quartz.jobStore.dataSource = myDataSource#最大能忍受的触发超时时间,如果超时则认为“失误”
org.quartz.jobStore.misfireThreshold = 60000#这是JobStore能处理的错过触发的Trigger的最大数量。处理太多(2打)很快就会导致数据库表被锁定够长的时间,
#这样会妨碍别的(还未错过触发)trigger执行的性能。
org.quartz.jobStore.maxMisfiresToHandleAtATime=20#设置这个参数为true会告诉Quartz从数据源获取连接后不要调用它的setAutoCommit(false)方法。
#在少数情况下是有用的,比如有一个驱动本来是关闭的,但是又调用这个关闭的方法。但是大部分情况下驱动都要求调用setAutoCommit(false)
org.quartz.jobStore.dontSetAutoCommitFalse=false#这必须是一个从LOCKS表查询一行并对这行记录加锁的SQL。假设没有设置,默认值如下。
#{0}会在运行期间被前面配置的TABLE_PREFIX所代替
org.quartz.jobStore.selectWithLockSQL=SELECT * FROM {0}LOCKS WHERE LOCK_NAME = ? FOR UPDATE#值为true时告知Quartz(当使用JobStoreTX或CMT)调用JDBC连接的setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE) 方法。这有助于某些数据库在高负载和长时间事务时锁的超时。
org.quartz.jobStore.txIsolationLevelSerializable=false