一.模型简介:
SENet的全称叫Squeeze-and-Excitation Networks(挤压-激励网络,简称SENet),于2017年提出,并拿下了当年的ImageNet分类比赛的冠军。ResNet是2015年ImageNet的冠军,2016年ResNeXt(由ResNet和Inception网络结合而成)拿下了亚军。论文链接:Squeeze-and-Excitation Networks
这个网络通过学习channel之间的相关性,提出了针对通道的注意力机制,在增加了一点计算量的代价下,较大的提高了网络的效果。模型的原理图如下所示:
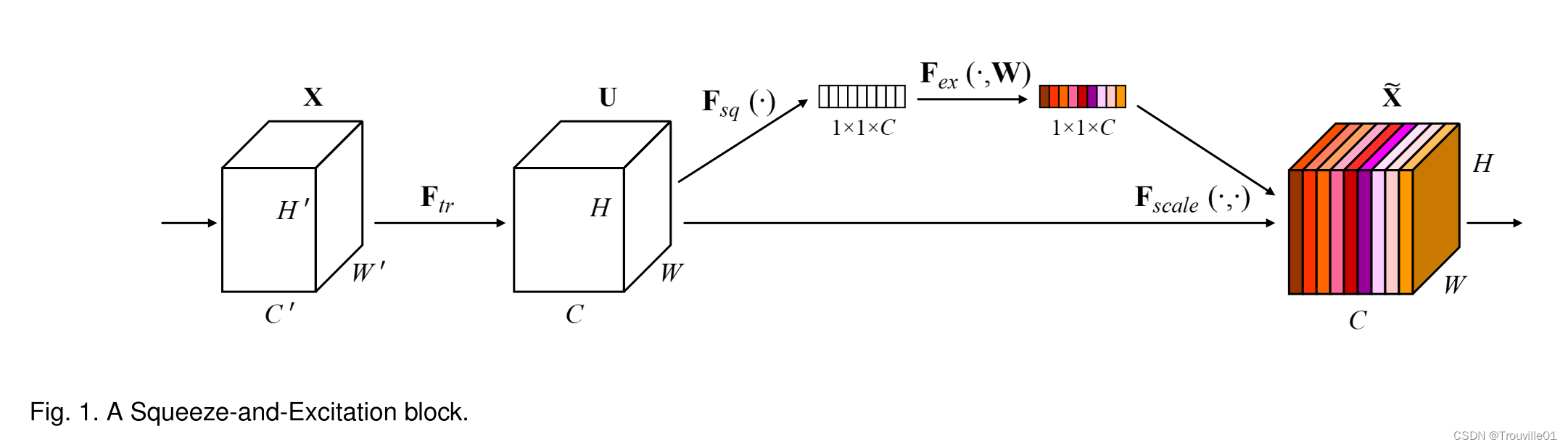
从原理图中大家可能理解优点困难,结合代码便比较容易理解了。使用pytorch实现的SE注意力机制的代码实现如下:
class SELayer(nn.Module):def __init__(self, channel, reduction=16):super(SELayer, self).__init__()# 1. squeeze过程,使用全局平均池化来获得具有全局感受野的特征图,输出特征图形状为1*1*Cself.avg_pool = nn.AdaptiveAvgPool2d(1)# 2. excitation过程,使用全连接层对squeeze之后的特征图进行非线性变换self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()# 全局平均池化后展平得到形状为b*c的张量y = self.avg_pool(x).view(b, c)# 进行非线性变换后将形状调整为b*c*1*1y = self.fc(y).view(b, c, 1, 1)# 3. 特征重标定,使用得到的结果作为权重,乘到输入特征上。expand_as是调整y的形状与x一致。return x * y.expand_as(x)可以看出SE注意力机制其实特别简单,它只针对特定的特征图做了一些变换工作,并不改变特征图的形状。这种注意力机制实现简单,使其可以任意加在某一个CNN网络的实现过程中。
SE注意力机制的工作步骤:
1.获取特征图x的形状 [b,c,H,W];
2.Squeeze过程。对特征图进行平均池化,调整形状为[b,c]; 对特征图的空间维度进行压缩,生成通道描述符。
3.Excitation过程。对输出的特征图进行非线性变换并调整形状为[b,c,1,1]; 对通道进行压缩,学习不同通道的依赖关系。
4.特征重标定。将得到的结果作为注意力权重与输入特征图x进行相乘,返回结果。
总结来说,就是3个比较重要的过程:Squeeze,Excitation, 特征重标定。SE注意力机制通过明确建模通道之间的相互依赖性,可以自适应地重新校准通道特征响应。