【k8s】监控与报警(qq邮箱+钉钉):Prometheus + Grafana + Alertmanager(超详细)
- 1、部署环境
- 2、基本概念简介
- 2.1、Prometheus简介
- 2.2、Grafana简介
- 2.3、Alertmanager简介
- 2.4、Prometheus + Grafana+Alertmanager监控架构
- 3、Prometheus部署
- 3.1 创建命名空间
- 3.2 创建服务账户
- 3.3 授权服务账户RBAC权限
- 3.4 创建数据目录
- 3.5 创建Configmap存储卷
- 3.6 通过Deployment 部署Prometheus
- 3.7 为prometheus Pod 创建一个service 实现四层代理
- 4、Node-Exporter部署
- 4.1、创建一个Node-Exporter 的YAML文件描述Deployment资源
- 4.2、应用配置文件
- 4.3、验证Node-Exporter是否部署成功
- 4.4、问题排查:Node-Exporter没有调度到(k8s-master)
- 4.5、Node-Exporter 的应用案例
- 5、Grafana部署
- 5.1、创建一个Grafana的YAML文件描述Deployment资源
- 5.2、应用配置文件
- 5.3、验证grafana部署
- 5.4、配置grafana接入prometheus 数据源
- 5.5、导入监控模板
- 6、Alertmanager部署
- 6.1、部署Altermanager发送qq邮箱报警
- 6.1.1、开启 163邮箱:IMAP/SMTP服务
- 6.1.2、获取授权密码
- 6.1.3、配置 Alertmanager
- 6.1.4、应用配置到k8s集群
- 6.1.5、创建prometheus和告警规则配置文件
- 6.1.6、部署prometheus和altermanager
- 6.1.7、通过deployment部署prometheus和altermanager
- 6.1.8、创建altermanager前端service,方便浏览器访问
- 6.1.9、部署完成后,有关问题解决
- 6.1.10、邮箱收取告警信息-测试
- 6.2、部署altermanager发送报警到钉钉群
- 6.1、创建钉钉机器人--电脑版钉钉
- 6.2、控制节点安装webhook插件
- 6.3、钉钉收取告警信息-验证
- 7、总结:
| 💖The Begin💖点点关注,收藏不迷路💖 |
Kubernetes是一个高度动态的容器编排平台,管理着大量的容器化应用程序。
为了保证这些应用程序的稳定性和性能,我们需要实施有效的监控和警报机制。在这篇文章中,我们将介绍如何使用Prometheus和Grafana构建一个完整的Kubernetes监控与报警系统。

1、部署环境
1、k8s控制节点:
IP:192.168.234.20,主机名:k8s-master。
2、使用 kubeadm 部署的 Kubernetes 集群
3、k8s工作节点:
IP:192.168.234.21,主机名:k8s-node01。
IP:192.168.234.22,主机名:k8s-node02。
4、docker版本V 20.10.7
[root@k8s-master ~]# docker --version
Docker version 20.10.7, build f0df350
[root@k8s-master ~]#
5、kubelet 版本V1.21.13
[root@k8s-master ~]# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.13", GitCommit:"80ec6572b15ee0ed2e6efa97a4dcd30f57e68224", GitTreeState:"clean", BuildDate:"2022-05-24T12:39:27Z", GoVersion:"go1.16.15", Compiler:"gc", Platform:"linux/amd64"}
[root@k8s-master ~]#
6、操作系统版本7.9
[root@k8s-master ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
[root@k8s-master ~]#
2、基本概念简介
2.1、Prometheus简介
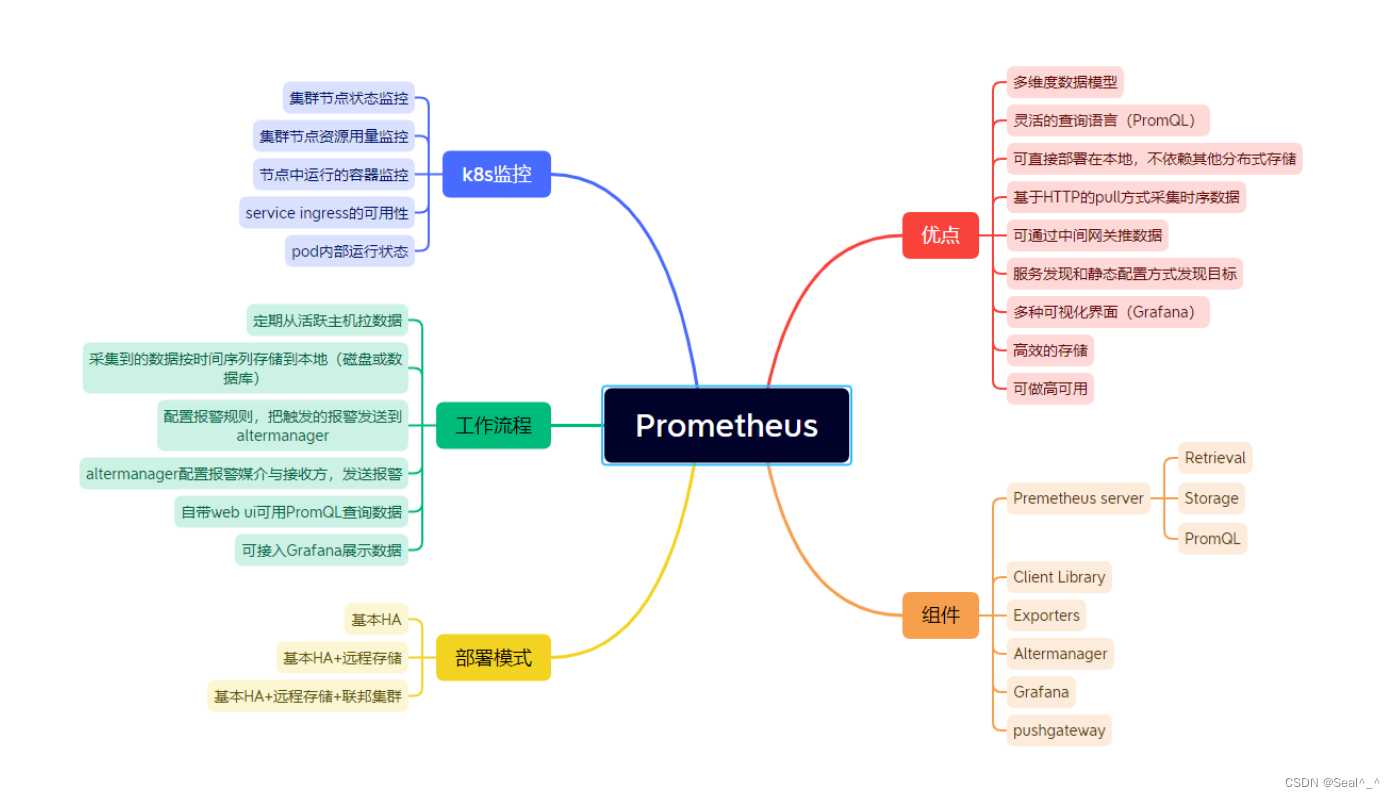
Prometheus是一个开源的系统监控和警报工具包,最初由SoundCloud开发。它具有多维数据模型、强大的查询语言(PromQL)、灵活的警报机制和可靠的数据存储。Prometheus通过HTTP协议定期拉取目标的数据,并将数据存储在本地时间序列数据库中。
2.2、Grafana简介
Grafana是一个开源的数据可视化和监控平台,它支持多种数据源,包括Prometheus、InfluxDB、Elasticsearch等。Grafana提供了丰富的可视化工具和仪表板编辑器,帮助用户创建漂亮而功能强大的监控仪表板。
2.3、Alertmanager简介
Alertmanager是Prometheus的一部分,用于处理警报通知。它可以根据定义的规则对Prometheus收集的监控数据进行分析,并触发警报。Alertmanager还支持多种通知方式,包括电子邮件、Slack、PagerDuty等,可以根据不同的场景和严重性级别配置警报通知策略。
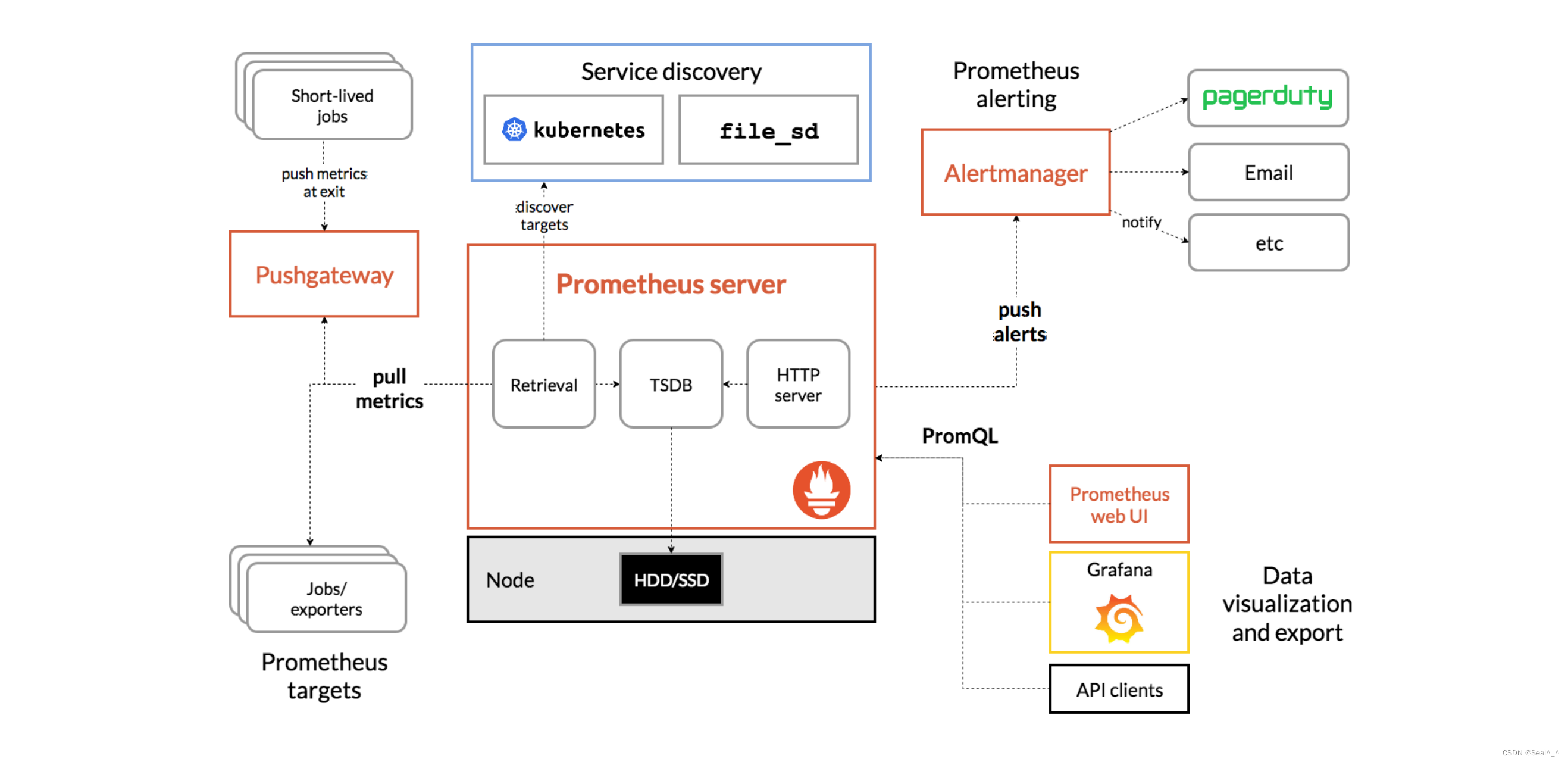
2.4、Prometheus + Grafana+Alertmanager监控架构
Prometheus Server:负责定期从目标中拉取指标数据,并将数据存储在本地时间序列数据库中。
Prometheus Alertmanager:负责处理警报规则并发送通知。
Grafana Server:用于创建、查看和共享监控仪表板。
Kubernetes集成:使用Prometheus的Kubernetes SD(Service Discovery)来自动发现和监视Kubernetes中的服务和Pod。
3、Prometheus部署
3.1 创建命名空间
Kubernetes中的命名空间提供了一种组织和管理集群资源的机制,可以实现资源的逻辑隔离、权限控制、资源管理、环境隔离等功能,有助于提高集群的安全性、可管理性和可观察性。
kubectl create namespace monitor-sa或者kubectl create ns monitor-sa

3.2 创建服务账户
创建服务账户在Kubernetes中是为了实现身份认证、授权访问、安全隔离、跟踪和监控以及与其他服务集成等功能。合理使用服务账户可以提高集群的安全性、可管理性和可观察性,确保工作负载之间的安全通信和权限控制。
kubectl create serviceaccount monitor -n monitor-samonitor: 指定要创建的服务账户的名称为 monitor。
-n monitor-sa: 指定将服务账户创建在名为 monitor-sa 的命名空间中。

3.3 授权服务账户RBAC权限
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
或者通过以下步骤(跳过):
1、创建一个用于创建服务账户、配置 RBAC 权限并授权给 Prometheus Pod 的 YAML 文件。
vim prometheus-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:name: monitornamespace: monitor-sa---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: monitor-clusterrolebinding
subjects:
- kind: ServiceAccountname: monitornamespace: monitor-sa
roleRef:kind: ClusterRolename: cluster-adminapiGroup: rbac.authorization.k8s.io
2、并使用以下命令将其应用到集群中:
kubectl apply -f prometheus-rbac.yaml

3.4 创建数据目录
为了数据持久化,控制节点默认是存在污点的,不会调度Pod,所以在node01工作节点创建数据存目录,调度到node01。
sudo mkdir /datasudo chmod 777 /data

3.5 创建Configmap存储卷
并使用以下命令将其应用到集群中:
vim prometheus-cfg.yamlkubectl apply -f prometheus-cfg.yaml

最终完整的prometheus-cfg.yaml配置文件,内容如下:
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: monitor-sa
data:prometheus.yml: |global:scrape_interval: 15sscrape_timeout: 10sevaluation_interval: 1mscrape_configs:- job_name: 'kubernetes-node'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: 'kubernetes-node-cadvisor'kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name
配置详解:
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: monitor-sa
data:prometheus.yml: | # 用于配置 Prometheus 的全局设置和抓取配置global: # 全局配置scrape_interval: 15s # 抓取间隔为每15秒scrape_timeout: 10s # 单次抓取超时时间为10秒evaluation_interval: 1m # 指标评估间隔为每1分钟scrape_configs: # 抓取配置列表- job_name: 'kubernetes-node' # 任务名称为 'kubernetes-node',用于监控 Kubernetes 节点kubernetes_sd_configs: # 使用 Kubernetes 服务发现配置- role: node # 角色为节点relabel_configs: # 重标签配置- source_labels: [__address__] # 源标签为 __address__regex: '(.*):10250' # 使用正则表达式匹配地址端口为10250replacement: '${1}:9100' # 替换为端口9100target_label: __address__ # 目标标签为 __address__action: replace # 替换操作- action: labelmap # 标签映射操作,动态生成标签regex: __meta_kubernetes_node_label_(.+) # 匹配节点标签- job_name: 'kubernetes-node-cadvisor' # 任务名称为 'kubernetes-node-cadvisor',用于监控 Kubernetes 节点的 cAdvisor 指标kubernetes_sd_configs: # 使用 Kubernetes 服务发现配置- role: node # 角色为节点scheme: https # 使用 HTTPS 访问节点tls_config: # TLS 配置ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # CA 证书路径bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 令牌路径relabel_configs: # 重标签配置- action: labelmap # 标签映射操作,动态生成标签regex: __meta_kubernetes_node_label_(.+) # 匹配节点标签- target_label: __address__ # 目标标签为 __address__replacement: kubernetes.default.svc:443 # 替换为 Kubernetes 默认服务地址- source_labels: [__meta_kubernetes_node_name] # 源标签为节点名称regex: (.+) # 匹配所有字符target_label: __metrics_path__ # 目标标签为 __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor # 替换为 cAdvisor 指标路径- job_name: 'kubernetes-apiserver' # 任务名称为 'kubernetes-apiserver',用于监控 Kubernetes API 服务器kubernetes_sd_configs: # 使用 Kubernetes 服务发现配置- role: endpoints # 角色为端点scheme: https # 使用 HTTPS 访问端点tls_config: # TLS 配置ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # CA 证书路径bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 令牌路径relabel_configs: # 重标签配置- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] # 源标签为命名空间、服务名称和端口名称action: keep # 保留标签regex: default;kubernetes;https # 匹配默认命名空间、Kubernetes 服务和 HTTPS 端口- job_name: 'kubernetes-service-endpoints' # 任务名称为 'kubernetes-service-endpoints',用于监控 Kubernetes 服务端点kubernetes_sd_configs: # 使用 Kubernetes 服务发现配置- role: endpoints # 角色为端点relabel_configs: # 重标签配置- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] # 源标签为 Prometheus 抓取注解action: keep # 保留标签regex: true # 匹配值为 true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] # 源标签为 Prometheus 方案注解action: replace # 替换操作target_label: __scheme__ # 目标标签为 __scheme__regex: (https?) # 匹配值为 HTTP 或 HTTPS- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] # 源标签为 Prometheus 路径注解action: replace # 替换操作target_label: __metrics_path__ # 目标标签为 __metrics_path__regex: (.+) # 匹配所有字符- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] # 源标签为地址和端口注解action: replace # 替换操作target_label: __address__ # 目标标签为 __address__regex: ([^:]+)(?::\d+)?;(\d+) # 匹配地址和端口replacement: $1:$2 # 替换地址和端口- action: labelmap # 标签映射操作,动态生成标签regex: __meta_kubernetes_service_label_(.+) # 匹配服务标签- source_labels: [__meta_kubernetes_namespace] # 源标签为命名空间action: replace # 替换操作target_label: kubernetes_namespace # 目标标签为 kubernetes_namespace- source_labels: [__meta_kubernetes_service_name] # 源标签为服务名称action: replace # 替换操作target_label: kubernetes_name # 目标标签为 kubernetes_name3.6 通过Deployment 部署Prometheus
使用 Kubernetes 的节点亲和性(Node Affinity)功能。节点亲和性允许你指定节点选择标准,根据这些标准,Kubernetes 调度器会尝试将 Pod 调度到满足条件的节点上。
1、创建一个YAML文件描述Deployment资源,并包含Prometheus容器的配置。
vim prometheus-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitor-salabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: server#matchExpressions:#- {key: app, operator: In, values: [prometheus]}#- {key: component, operator: In, values: [server]}template:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:nodeName: k8s-node01 # 指定pod调度到哪个节点上 serviceAccountName: monitorcontainers:- name: prometheusimage: registry.aliyuncs.com/google_containers/prometheus:v2.2.1imagePullPolicy: IfNotPresentcommand:- prometheus- --config.file=/etc/prometheus/prometheus.yml- --storage.tsdb.path=/prometheus # 数据存储目录- --storage.tsdb.retention=720h # 数据保存时长- --web.enable-lifecycle # 开启热加载ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheus/prometheus.ymlname: prometheus-configsubPath: prometheus.yml- mountPath: /prometheus/name: prometheus-storage-volumevolumes:- name: prometheus-configconfigMap:name: prometheus-configitems:- key: prometheus.ymlpath: prometheus.ymlmode: 0644- name: prometheus-storage-volumehostPath:path: /datatype: Directory
配置详解:
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-server # 部署名称为 prometheus-servernamespace: monitor-sa # 命名空间为 monitor-salabels:app: prometheus # 标签为 app: prometheus
spec:replicas: 1 # 副本数为1selector:matchLabels:app: prometheus # 匹配标签为 app: prometheuscomponent: server # 匹配标签为 component: servertemplate:metadata:labels:app: prometheus # Pod 标签为 app: prometheuscomponent: server # Pod 标签为 component: serverannotations:prometheus.io/scrape: 'false' # Prometheus 抓取设置为 false,不抓取该 Pod 的指标spec:nodeName: k8s-node01 # 指定将 Pod 调度到节点 k8s-node01serviceAccountName: monitor # 使用 serviceAccountName 为 monitor 的服务账号containers:- name: prometheus # 容器名称为 prometheusimage: registry.aliyuncs.com/google_containers/prometheus:v2.2.1 # Prometheus 镜像imagePullPolicy: IfNotPresent # 如果本地没有该镜像,则从远程拉取command:- prometheus # 启动命令为 prometheus- --config.file=/etc/prometheus/prometheus.yml # 指定配置文件路径- --storage.tsdb.path=/prometheus # 数据存储目录路径为 /prometheus- --storage.tsdb.retention=720h # 数据保存时长为720小时- --web.enable-lifecycle # 开启热加载功能ports:- containerPort: 9090 # 容器监听端口为 9090protocol: TCP # 使用 TCP 协议volumeMounts:- mountPath: /etc/prometheus/prometheus.yml # 挂载配置文件路径name: prometheus-config # 挂载的配置文件名称为 prometheus-configsubPath: prometheus.yml # 挂载的子路径为 prometheus.yml- mountPath: /prometheus/ # 挂载数据存储目录路径name: prometheus-storage-volume # 挂载的存储卷名称为 prometheus-storage-volumevolumes:- name: prometheus-config # 配置文件卷名称为 prometheus-configconfigMap:name: prometheus-config # 使用的 ConfigMap 名称为 prometheus-configitems:- key: prometheus.yml # ConfigMap 中的键为 prometheus.ymlpath: prometheus.yml # 挂载到容器中的路径为 prometheus.ymlmode: 0644 # 权限设置为 0644- name: prometheus-storage-volume # 存储卷名称为 prometheus-storage-volumehostPath:path: /data # 宿主机路径为 /datatype: Directory # 类型为目录类型2、应用Deployment YAML文件来创建部署:
kubectl apply -f prometheus-deployment.yaml

3、查看prometheus是否部署成功:
kubectl get pods -n monitor-sa

3.7 为prometheus Pod 创建一个service 实现四层代理
prometheus 在k8s 集群中创建完成后,无法在集群外部访问。可以创建一个 NodePort 类型的 Service 代理Pod。允许通过集群节点的 IP 地址和指定的端口访问 Prometheus。
1、首先,创建一个名为 prometheus-service.yaml 的配置文件,并添加以下内容:
vim prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:name: prometheusnamespace: monitor-salabels:app: prometheus
spec:type: NodePort # 指定 Service 的类型为 NodePortports:- port: 9090 # Service 暴露的端口targetPort: 9090 # Pod 中运行的应用程序所监听的端口protocol: TCPselector:app: prometheus # 选择具有 app: prometheus 标签的 Podcomponent: server # 选择具有 component: server 标签的 Pod
2、应用配置文件
使用 kubectl apply 命令将配置文件应用到 Kubernetes 集群中:
kubectl apply -f prometheus-service.yaml
3、验证 Service 是否创建成功
运行以下命令来验证 Service 是否已成功创建:
kubectl get svc -n monitor-sa

你会看到 prometheus-service 的类型为 NodePort,它公开了端口 30766,允许外部流量访问 Prometheus 服务。
4、访问 Prometheus
现在,可以使用任何 Kubernetes 集群节点的 IP 地址和指定的 NodePort来访问 Prometheus 服务。在浏览器中访问 http://192.168.234.20:30682来访问 Prometheus。
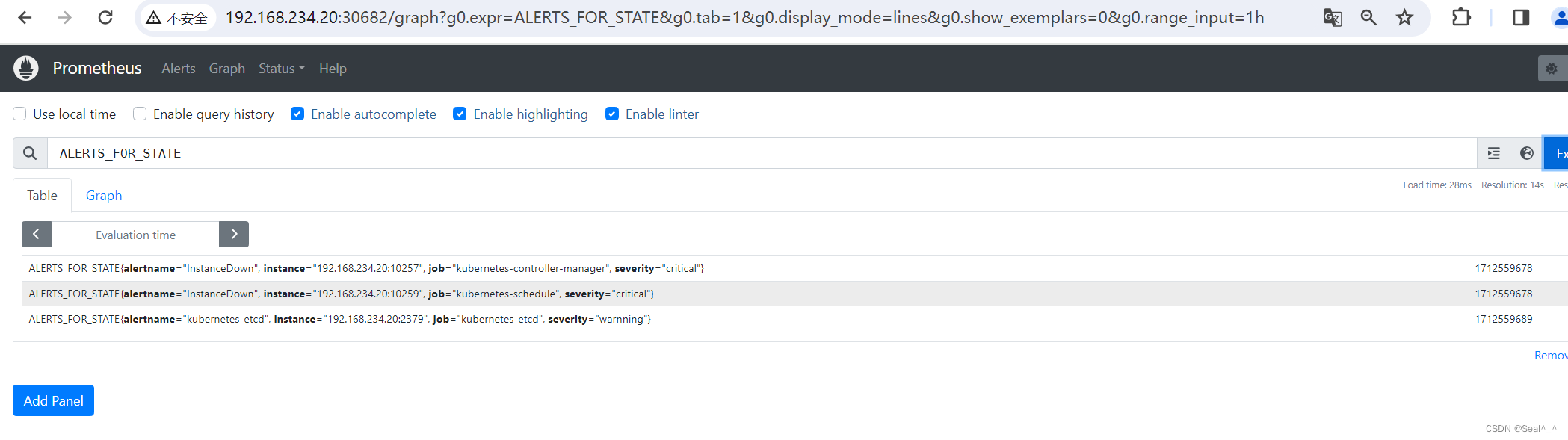
这样,你就可以在 Kubernetes 集群外部访问 Prometheus 服务了。
4、Node-Exporter部署
Node Exporter 是 Prometheus 的一个官方组件,默认监听端口9100,用于收集系统的各种指标。它是一个独立的二进制文件,可以在需要监控的服务器上运行,以收集关于硬件、操作系统和应用程序的各种指标。这些指标包括 CPU 使用率、内存使用情况、磁盘 I/O、网络统计和许多其他系统信息。
4.1、创建一个Node-Exporter 的YAML文件描述Deployment资源
vim node-export.yaml
apiVersion: apps/v1 # 指定使用的Kubernetes API版本。
kind: DaemonSet # 可以保证k8s集群的每个节点都运行完全一样的pod
metadata:name: node-exporter # 资源的名称为node-exporter。namespace: monitor-sa # 资源所属的命名空间为monitor-sa。labels:name: node-exporter # 给资源添加了一个名为node-exporter的标签。
spec:selector:matchLabels:name: node-exporter # 选择标签名为node-exporter的Pod。template:metadata:labels:name: node-exporter # 给Pod添加了一个名为node-exporter的标签。spec:hostPID: true # 指定Pod使用宿主机的PID命名空间。hostIPC: true # 指定Pod使用宿主机的IPC命名空间。hostNetwork: true # 指定Pod使用宿主机的网络命名空间。containers:- name: node-exporter # 容器的名称为node-exporter。image: prom/node-exporter:v0.16.0 # 容器所使用的镜像。ports:- containerPort: 9100 # 将容器的9100端口暴露出来。resources:requests:cpu: 0.15 # 这个容器运行至少需要0.15核cpusecurityContext:privileged: true # 开启特权模式args:- --path.procfs- /host/proc- --path.sysfs- /host/sys- --collector.filesystem.ignored-mount-points- '"^/(sys|proc|dev|host|etc)($|/)"' # 忽略挂载点。volumeMounts:- name: devmountPath: /host/dev # 挂载/dev目录到容器中。- name: procmountPath: /host/proc # 挂载/proc目录到容器中。- name: sysmountPath: /host/sys # 挂载/sys目录到容器中。- name: rootfsmountPath: /rootfs # 挂载根文件系统到容器中。tolerations:- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "NoSchedule" # 不允许调度。volumes:- name: prochostPath:path: /proc # 挂载主机的/proc目录。- name: devhostPath:path: /dev # 挂载主机的/dev目录。- name: syshostPath:path: /sys # 挂载主机的/sys目录。- name: rootfshostPath:path: / # 挂载主机的根文件系统。
4.2、应用配置文件
使用 kubectl apply 命令将配置文件应用到 Kubernetes 集群中:
kubectl apply -f node-export.yaml

4.3、验证Node-Exporter是否部署成功
kubectl get pods -n monitor-sa -o wide
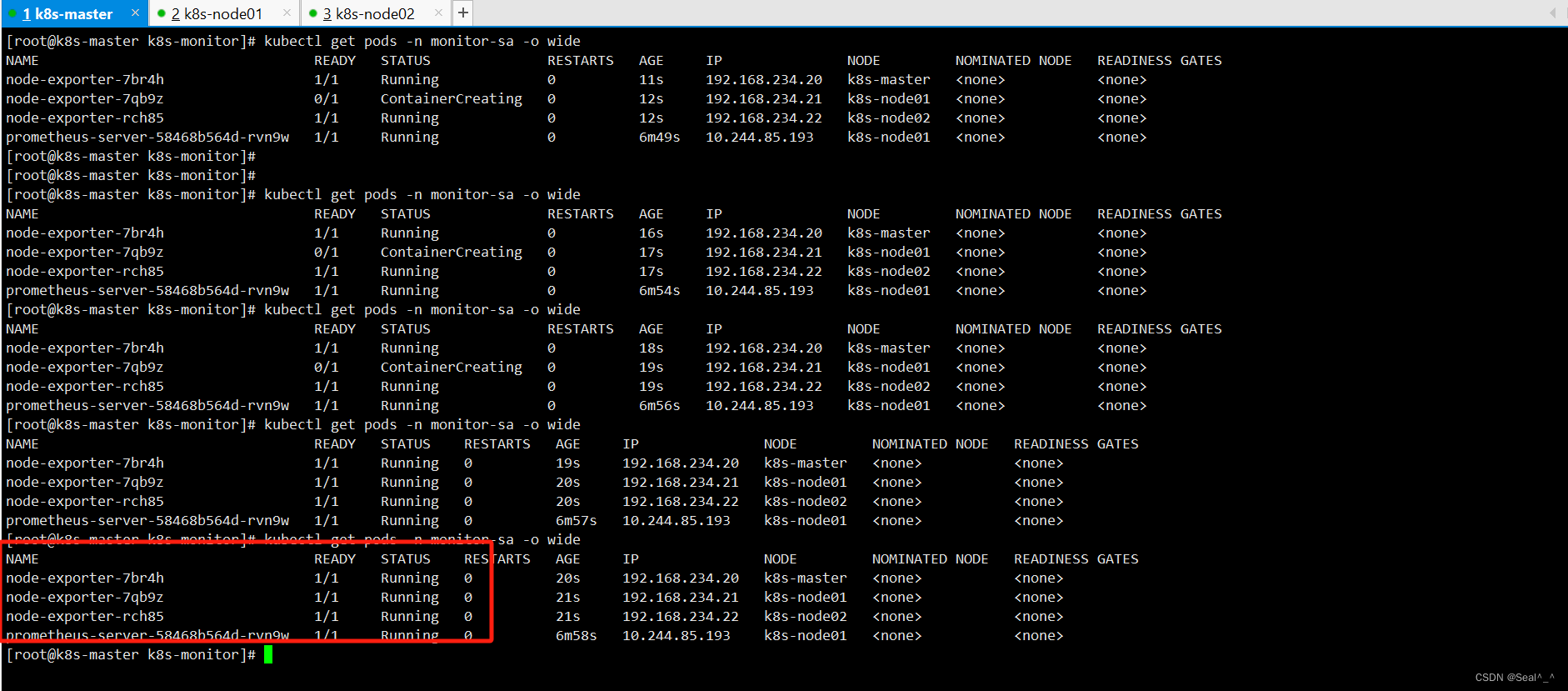
4.4、问题排查:Node-Exporter没有调度到(k8s-master)
已对前面配置文件修改,这里可跳过
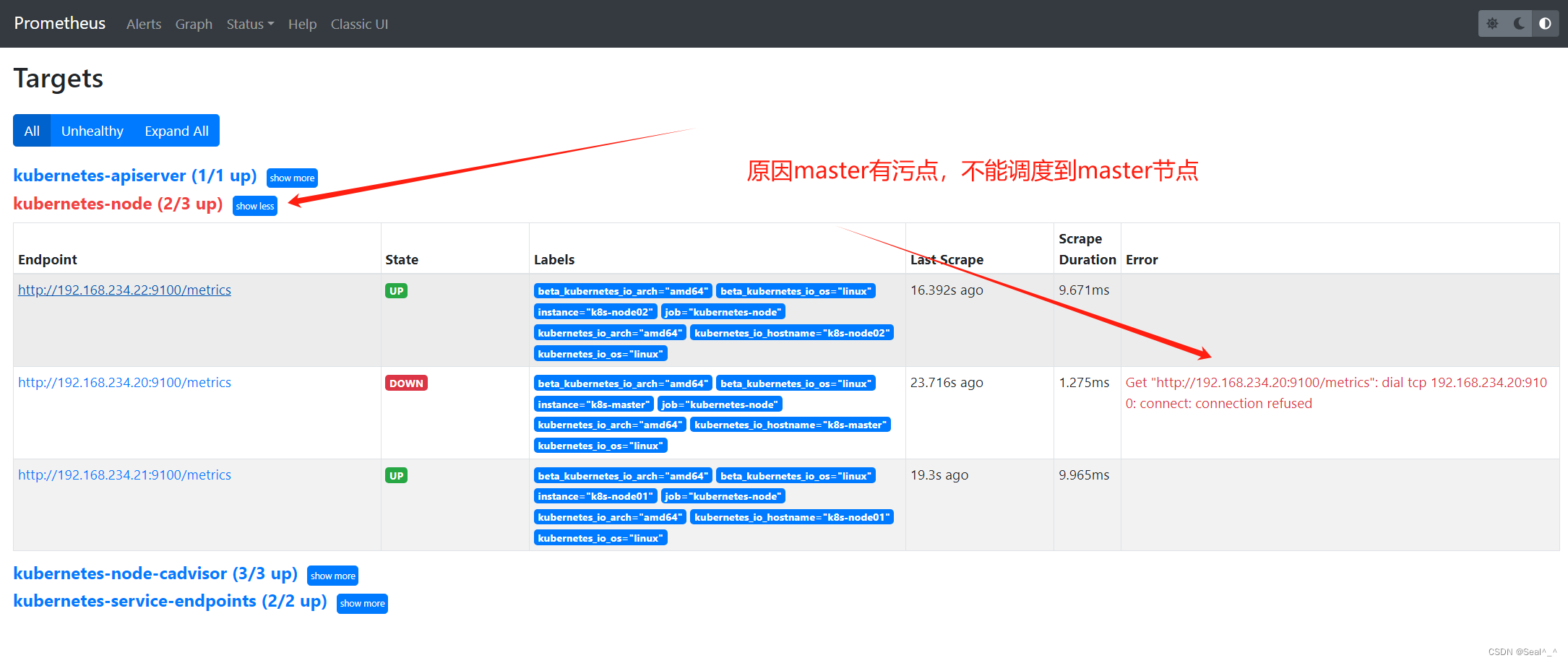
Kubernetes 的默认配置是,Master 节点会被标记有一个污点,以防止普通的 Pod 在 Master 节点上运行。这是为了确保 Master 节点不会被普通应用程序所占用,保证集群的稳定性和安全性。因此,默认情况下,如果一个 Pod 没有设置容忍度(tolerations),它将不会被调度到具有 Master 污点的节点上。
但是,在某些情况下,可能需要在 Master 节点上运行一些特定的应用或者监控程序。在这种情况下,你可以为这些 Pod 添加容忍度(tolerations),以允许它们被调度到具有 Master 污点的节点上。
使该 DaemonSet 能够调度到默认有污点的 Kubernetes 主节点(k8s-master),可以在 tolerations 部分添加一个容忍污点的配置。具体来说,你可以添加一个容忍 master 节点的污点的容忍配置,如下所示:
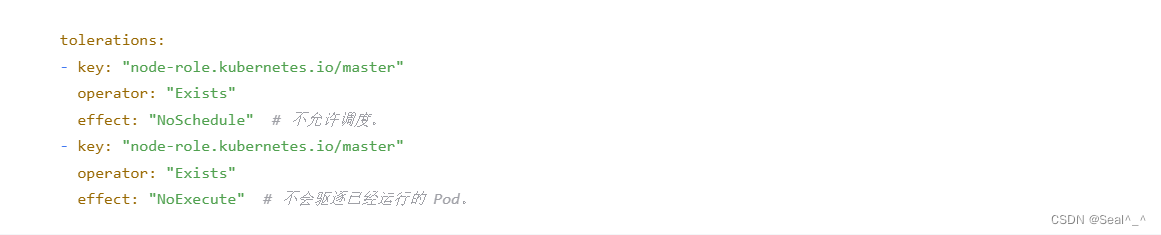
1、查看master节点污点
显示节点(Node)的详细信息,而 grep Ta 则用于过滤显示包含 “Ta” 的行。在 Kubernetes 中,“Ta” 通常指的是污点(Taints),它们用于标记节点,以便限制哪些 Pod 可以被调度到该节点上。
[root@k8s-master k8s-monitor]# kubectl describe node | grep Ta
Taints: node-role.kubernetes.io/control-plane:NoSchedule
Taints: <none>
Taints: <none>
[root@k8s-master k8s-monitor]# 2、修改node-export.yaml
vim node-export.yaml修改为实际的master污点,前面配置错了。# - key: "node-role.kubernetes.io/master"
- key: "node-role.kubernetes.io/control-plane"
3、重新使用 kubectl apply 命令将配置文件应用到 Kubernetes 集群中:
kubectl apply -f node-export.yaml
4、验证:
kubectl get pods -n monitor-sa -o wide
monitor-sa 中3个不同的node-exporter Pod,它们分别被调度到了三个不同的节点上运行。

Prometheus web ui刷新:

4.5、Node-Exporter 的应用案例
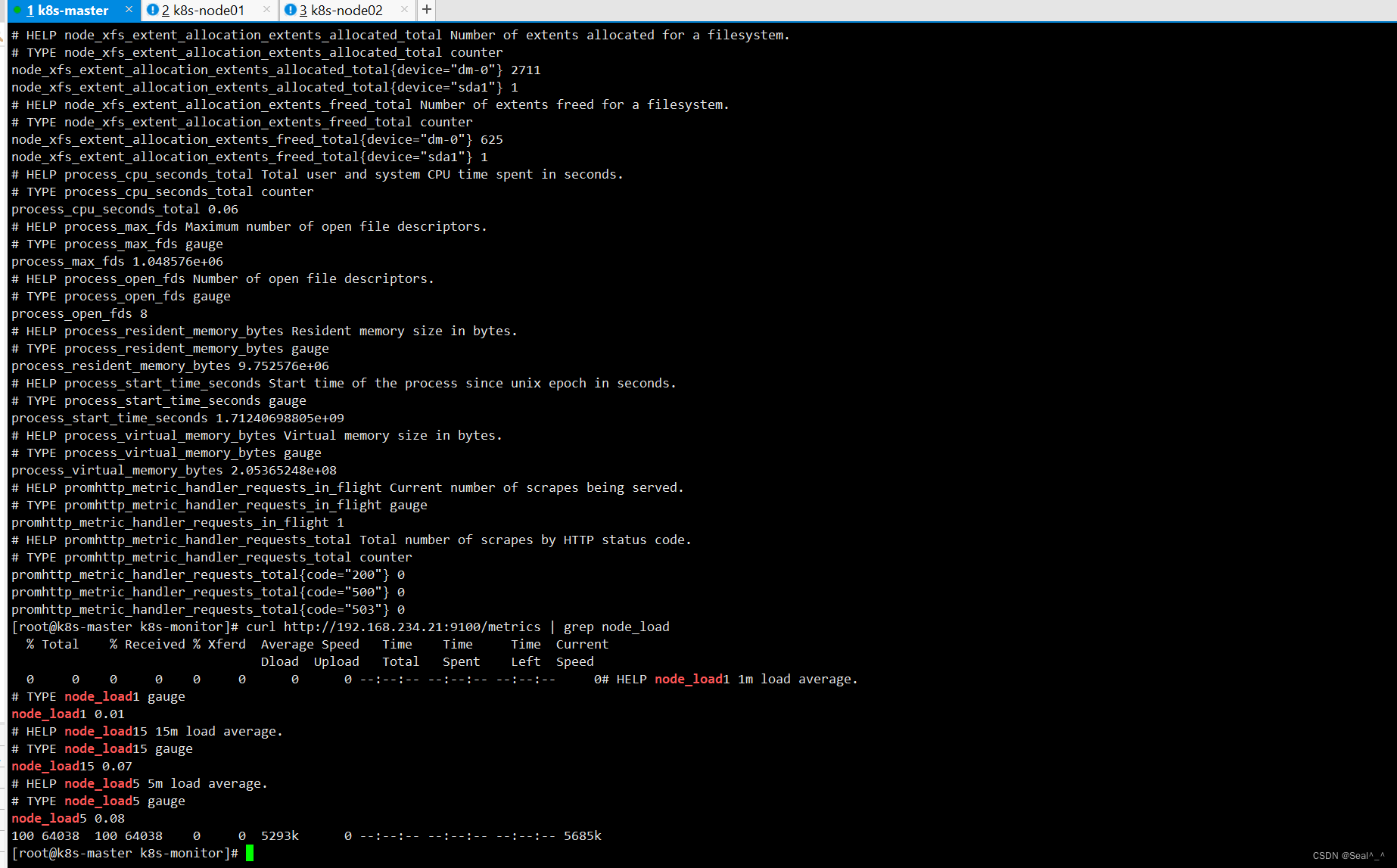
1、查看当前主机获取到的所有监控数据
curl http://192.168.234.21:9100/metrics
2、查看Cpu使用情况
curl http://192.168.234.21:9100/metrics | grep node_cpu_seconds3、查看主机负载
curl http://192.168.234.21:9100/metrics | grep node_load
5、Grafana部署
5.1、创建一个Grafana的YAML文件描述Deployment资源
vi grafana-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: monitoring-grafana # 部署的名称为 monitoring-grafananamespace: kube-system # 部署在 kube-system 命名空间中
spec:replicas: 1 # 副本数量为 1selector:matchLabels:task: monitoring # 标签选择器,选择 task: monitoring 的 Podk8s-app: grafana # 标签选择器,选择 k8s-app: grafana 的 Podtemplate:metadata:labels:task: monitoring # Pod 的标签 task: monitoringk8s-app: grafana # Pod 的标签 k8s-app: grafanaspec:containers:- name: grafana # 容器名称为 grafanaimage: registry.aliyuncs.com/google_containers/heapster-grafana-amd64:v5.0.4 # 使用的镜像(请确保有拉取了该镜像或者您有访问该镜像的权限)ports:- containerPort: 3000 # 容器监听的端口protocol: TCPvolumeMounts:- mountPath: /etc/ssl/certs # 挂载的卷路径name: ca-certificates # 卷的名称readOnly: true- mountPath: /var # 挂载的卷路径name: grafana-storage # 卷的名称env:- name: INFLUXDB_HOST # 环境变量:InfluxDB 主机value: monitoring-influxdb- name: GF_SERVER_HTTP_PORT # 环境变量:Grafana 服务器 HTTP 端口value: "3000"# 下面的环境变量用于通过 Kubernetes API 服务器代理访问 Grafana。# 在生产环境中,建议删除这些环境变量,为 Grafana 设置认证,并使用 LoadBalancer 或公共 IP 暴露 Grafana 服务。- name: GF_AUTH_BASIC_ENABLED # 环境变量:启用基本认证value: "false"- name: GF_AUTH_ANONYMOUS_ENABLED # 环境变量:启用匿名访问value: "true"- name: GF_AUTH_ANONYMOUS_ORG_ROLE # 环境变量:匿名用户角色value: Admin- name: GF_SERVER_ROOT_URL # 环境变量:Grafana 服务器根 URL# 如果仅使用 API 服务器代理,请设置此值:# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxyvalue: /volumes:- name: ca-certificates # 卷的名称hostPath:path: /etc/ssl/certs # 主机路径- name: grafana-storage # 卷的名称emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:labels:# 用作集群附加组件 (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)# 如果不作为附加组件使用,请将此行注释掉。kubernetes.io/cluster-service: 'true'kubernetes.io/name: monitoring-grafananame: monitoring-grafana # 服务名称为 monitoring-grafananamespace: kube-system # 服务部署在 kube-system 命名空间中
spec:# 在生产环境中,我们建议通过外部负载均衡器或公共 IP 访问 Grafana。# type: LoadBalancer# 您也可以使用 NodePort 将服务暴露在随机生成的端口上# type: NodePortports:- port: 80 # 服务端口targetPort: 3000 # 目标端口selector:k8s-app: grafana # 选择器选择 k8s-app: grafana 的 Podtype: NodePort # 服务类型为 NodePort5.2、应用配置文件
kubectl apply -f grafana-pod.yaml

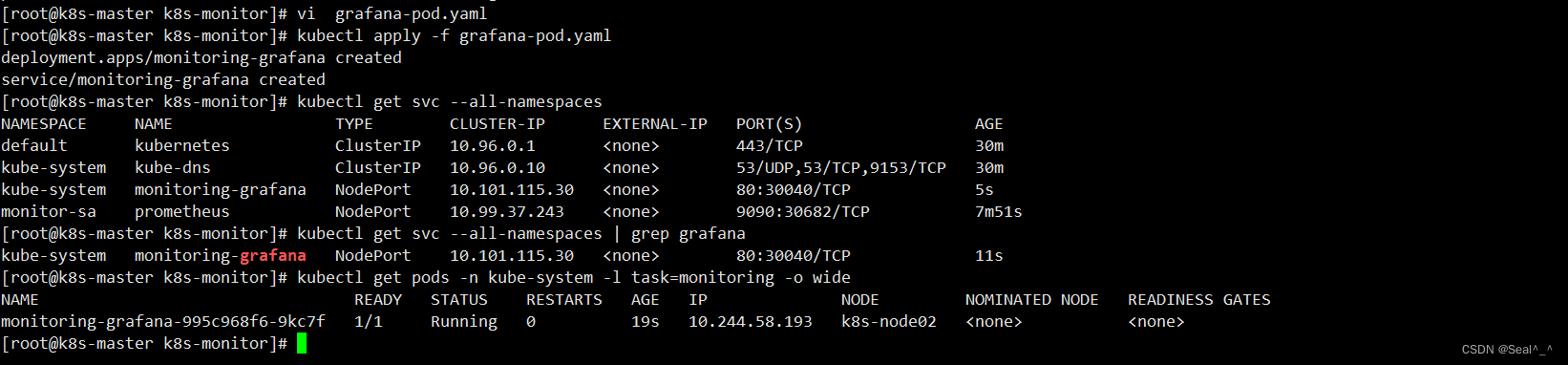
5.3、验证grafana部署
1、查看k8s 集群所有的Service资源
kubectl get svc --all-namespaces
2、grep命令过滤grafana
kubectl get svc --all-namespaces | grep grafana
3、获取位于命名空间 kube-system 中,标签为 task=monitoring 的所有 Pod 的信息,并显示详细信息
kubectl get pods -n kube-system -l task=monitoring -o wide
3、访问grafana的web界面
在浏览器的地址栏中输入 URL:http://192.168.234.20:30040/。
5.4、配置grafana接入prometheus 数据源
把Prometheus 采集到的数据通过grafana可视化展示。
1、grafana界面接入prometheus 数据源
➡️ Create your first data soure
➡️ 填写配置信息
Name:Prometheus
Type :Prometheus
URL:http://prometheus.monitor-sa.svc:9090
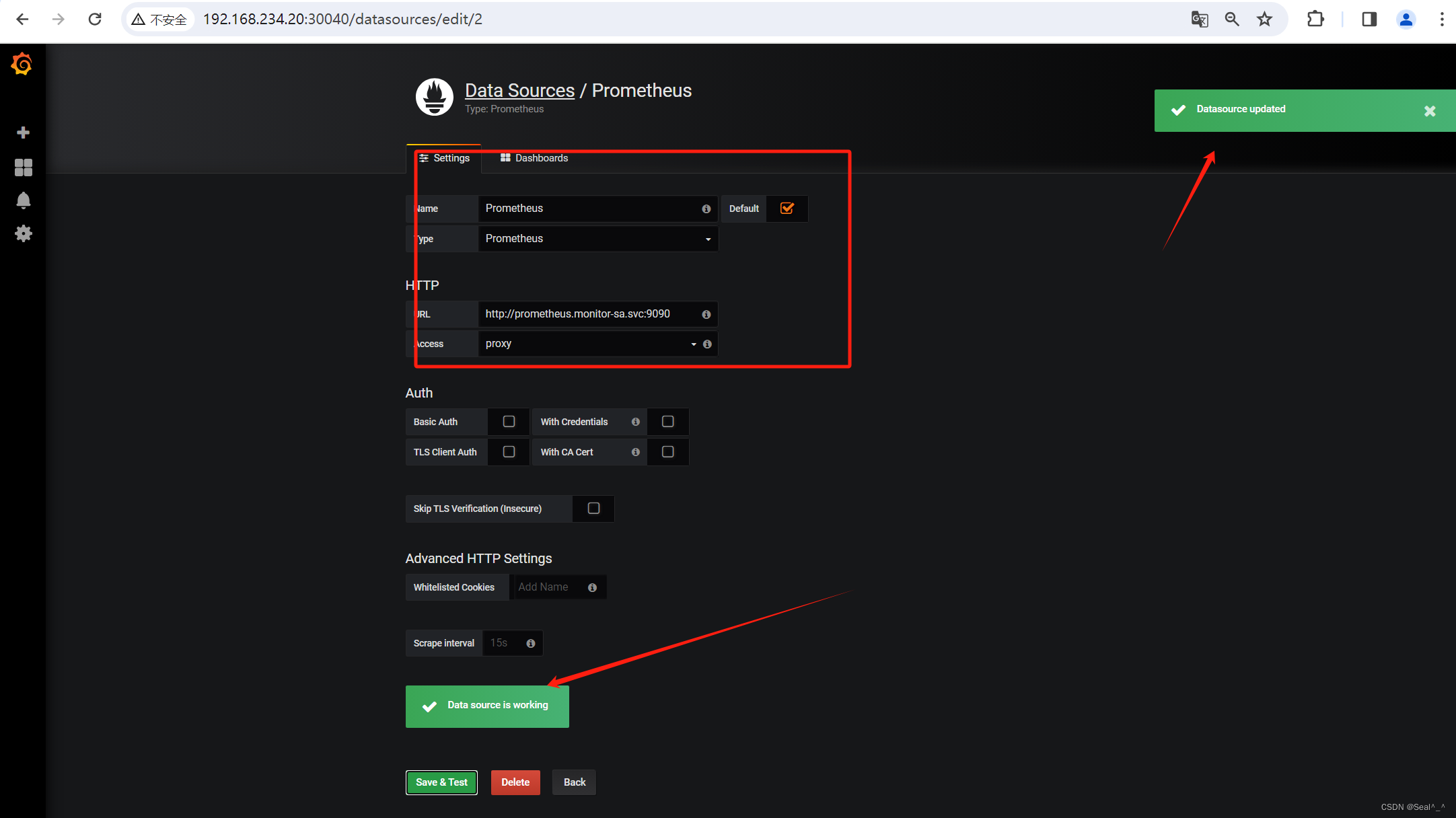
➡️ 保存配置信息


出现Data source is working,说明Prometheus数据源成功被Grafana接入了。
5.5、导入监控模板
Grafana 的仪表盘模板页面,其中包含了各种与 Kubernetes 相关的仪表盘模板。
https://grafana.com/grafana/dashboards/?search=kubernetes
➡️ 导入监控模板
导入刚才下载的json文件。
🍀 模板1(监控node状态):
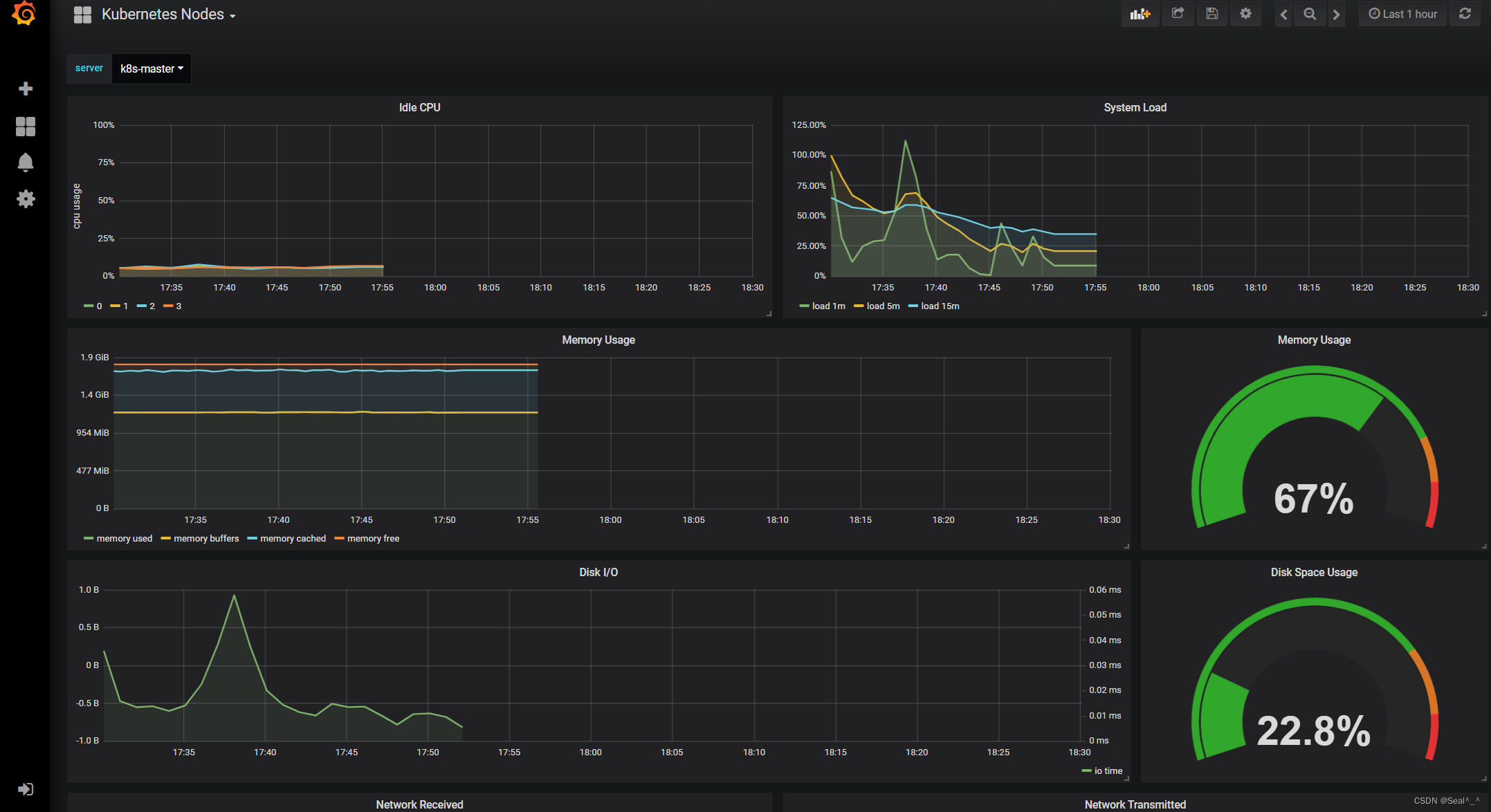
🍀 模板2(监控node状态):
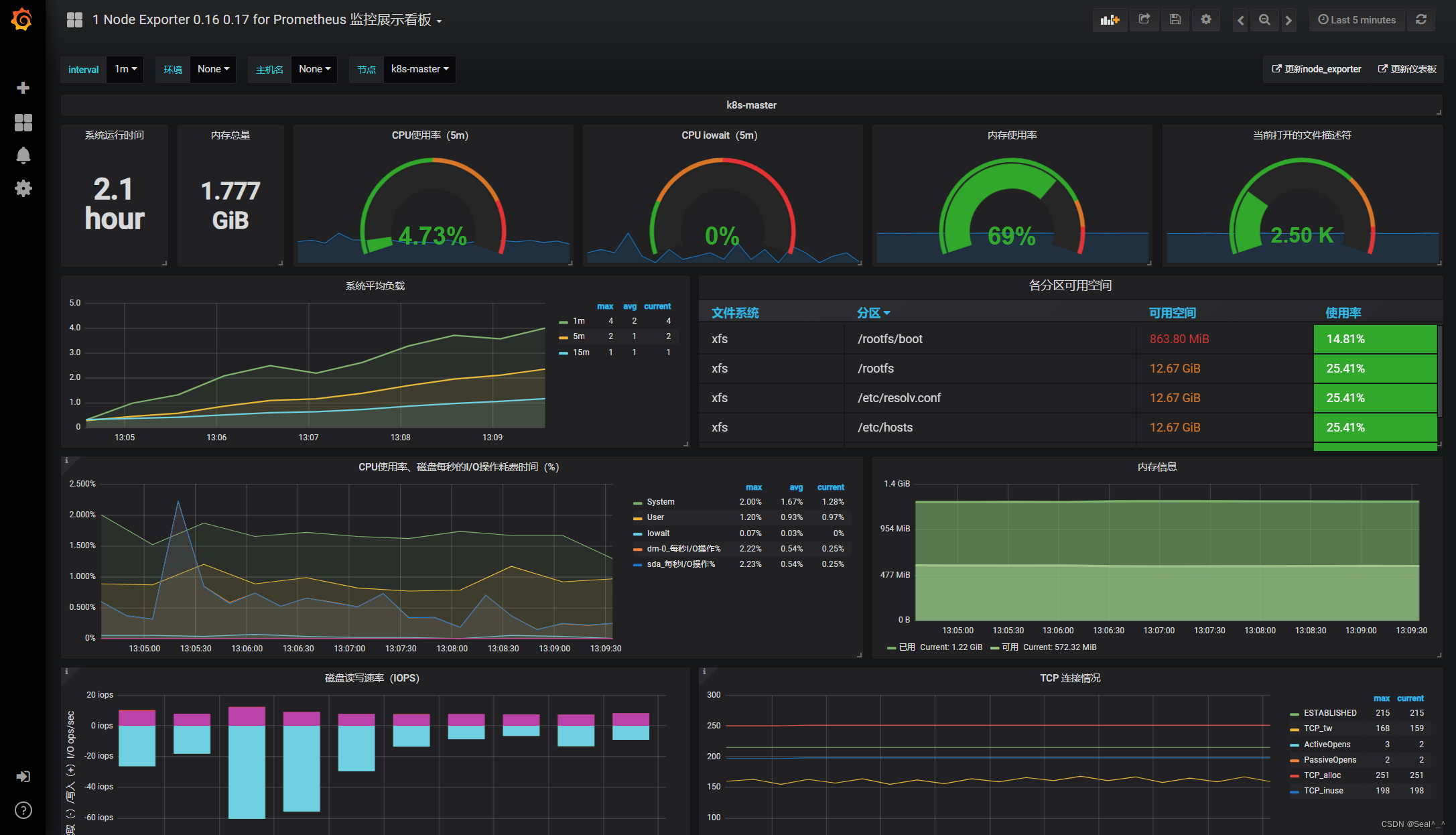
🍀 模板3(监控容器状态):
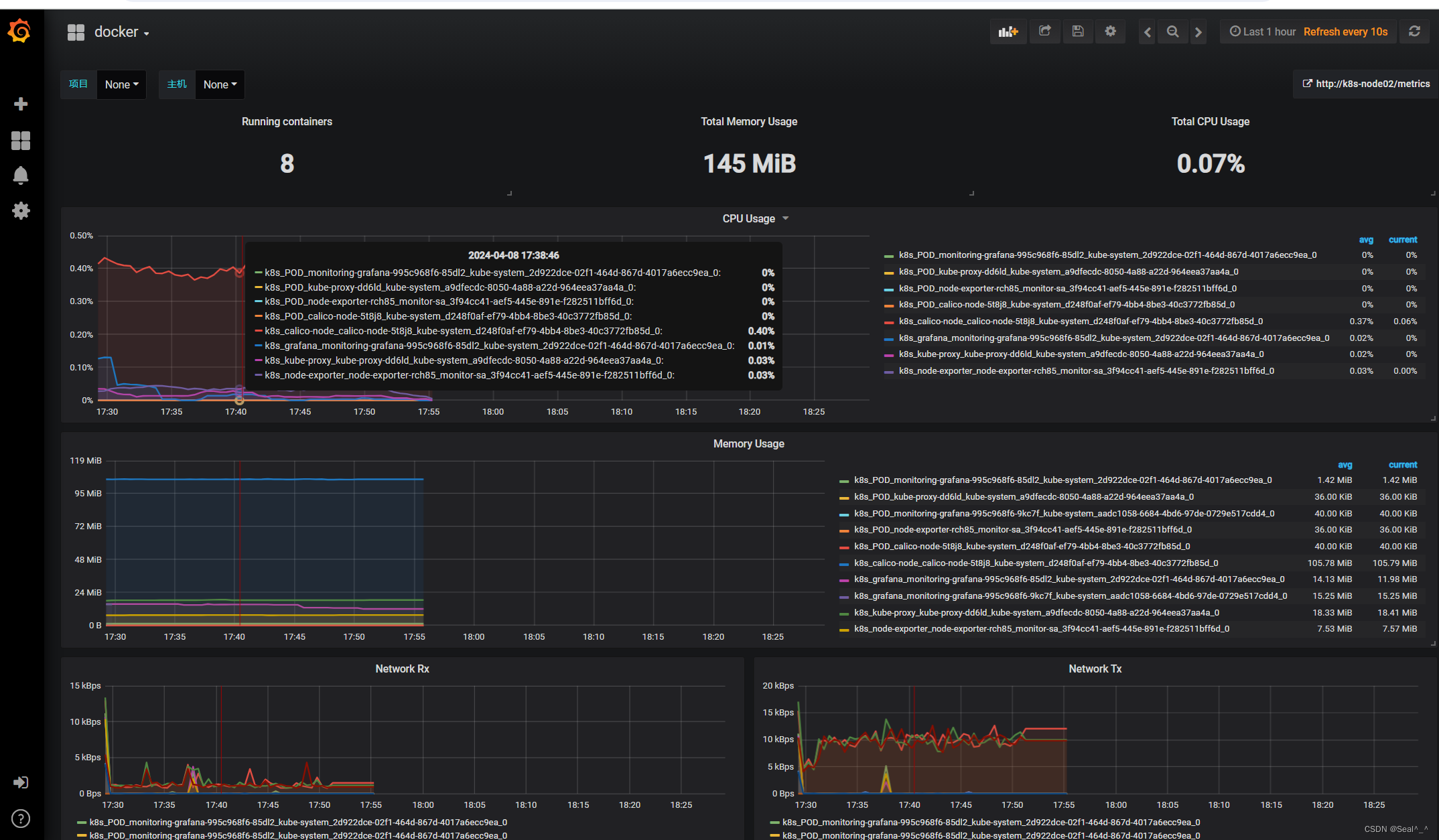
6、Alertmanager部署
6.1、部署Altermanager发送qq邮箱报警
6.1.1、开启 163邮箱:IMAP/SMTP服务
在邮箱设置中找到并开启 IMAP/SMTP 服务,按照提示发送验证码进行验证。
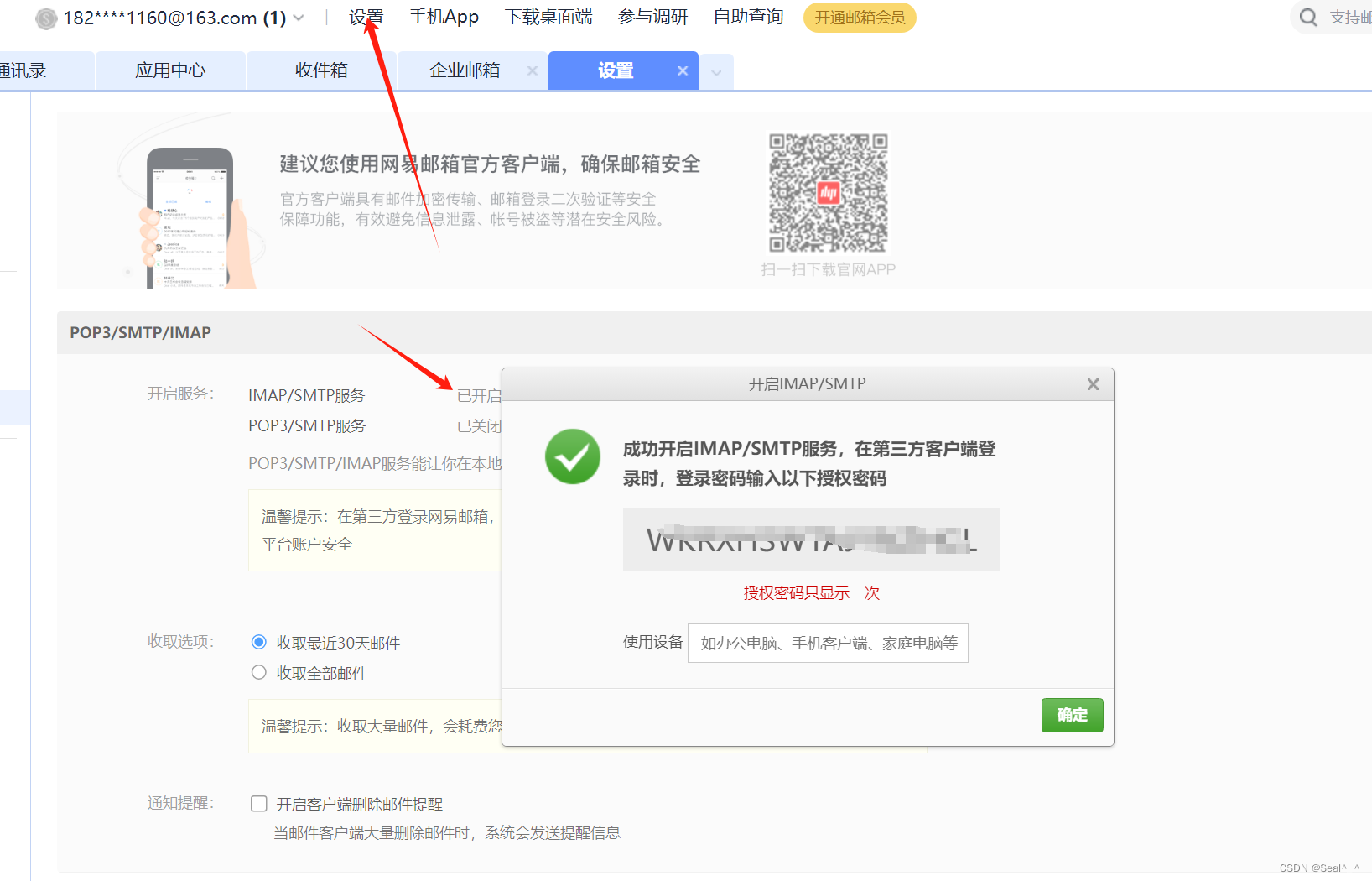
6.1.2、获取授权密码
验证成功后,你会获得一个授权密码(复制先保存),这个密码用于通过 SMTP 服务器发送邮件。
6.1.3、配置 Alertmanager
编辑一个 Alertmanager 的配置文件 alertmanager-email-163cfg.yaml。
并配置它以使用 SMTP 发送邮件到你的 163 邮箱。示例配置如下:
vim alertmanager-email-163cfg.yaml
kind: ConfigMap
apiVersion: v1
metadata:name: alertmanagernamespace: monitor-sa
data:alertmanager.yml: |- # altermanager配置文件global: resolve_timeout: 1m smtp_smarthost: 'smtp.163.com:25' # 发送者的SMTP服务器smtp_from: '182307****@163.com' # 发送者的邮箱smtp_auth_username: '18230*******' # 发送者的邮箱用户名(不是邮箱名)smtp_auth_password: 'OBGYGQJGJDUNZMKC' # 发送者授权密码(上面获取到的)smtp_require_tls: falseroute: # 配置告警分发策略group_by: [alertname] # 采用哪个标签作为分组依据group_wait: 10s # 组告警等待时间(10s内的同组告警一起发送)group_interval: 10s # 两组告警的间隔时间repeat_interval: 10m # 重复告警的间隔时间receiver: default-receiver # 接收者配置receivers:- name: 'default-receiver' # 接收者名称(与上面对应)email_configs: # 接收邮箱配置- to: '4963430***@qq.com' # 接收邮箱(填要接收告警的邮箱)send_resolved: true # 是否通知已解决的告警
请确保替换示例配置中的以下内容:
‘你的发件邮箱地址’:用于发送邮件的邮箱地址,通常也是你的 163 邮箱地址。
‘你的163邮箱地址’:你的 163 邮箱地址。
‘你的163邮箱授权密码’:你在步骤 2 中获得的授权密码。
‘你的收件邮箱地址’:接收报警的邮箱地址。
6.1.4、应用配置到k8s集群
kubectl apply -f alertmanager-email-163cfg.yaml # 应用配置

6.1.5、创建prometheus和告警规则配置文件
创建一个 prometheus-alertmanager-cfg.yaml 文件,用于配置 Prometheus 的 Alertmanager 的配置文件。定义不同的报警规则和如何处理这些报警的方式。
你可编辑或者下载上传:
https://download.csdn.net/download/qq_41840843/89094986
vim prometheus-alertmanager-cfg.yaml
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: monitor-sa
data:prometheus.yml: |rule_files:- /etc/prometheus/rules.ymlalerting:alertmanagers:- static_configs:- targets: ["localhost:9093"]global:scrape_interval: 15sscrape_timeout: 10sevaluation_interval: 1mscrape_configs:- job_name: 'kubernetes-node'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: 'kubernetes-node-cadvisor'kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name - job_name: kubernetes-podskubernetes_sd_configs:- role: podrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_pod_annotation_prometheus_io_scrape- action: replaceregex: (.+)source_labels:- __meta_kubernetes_pod_annotation_prometheus_io_pathtarget_label: __metrics_path__- action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2source_labels:- __address__- __meta_kubernetes_pod_annotation_prometheus_io_porttarget_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- action: replacesource_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- action: replacesource_labels:- __meta_kubernetes_pod_nametarget_label: kubernetes_pod_name- job_name: 'kubernetes-schedule'scrape_interval: 5sstatic_configs:- targets: ['192.168.234.20:10251']- job_name: 'kubernetes-controller-manager'scrape_interval: 5sstatic_configs:- targets: ['192.168.234.20:10252']- job_name: 'kubernetes-kube-proxy'scrape_interval: 5sstatic_configs:- targets: ['192.168.234.21:10249','192.168.234.22:10249']- job_name: 'kubernetes-etcd'scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crtcert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crtkey_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.keyscrape_interval: 5sstatic_configs:- targets: ['192.168.234.20:2379']rules.yml: |groups:- name: examplerules:- alert: kube-proxy的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: kube-proxy的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: scheduler的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: scheduler的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: controller-manager的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: controller-manager的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: apiserver的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: apiserver的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: etcd的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: etcd的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: kube-state-metrics的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: coredns的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: coredns的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: kube-proxy打开句柄数>600expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kube-proxy打开句柄数>1000expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>600expr: process_open_fds{job=~"kubernetes-schedule"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>1000expr: process_open_fds{job=~"kubernetes-schedule"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>600expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>1000expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>600expr: process_open_fds{job=~"kubernetes-apiserver"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>1000expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>600expr: process_open_fds{job=~"kubernetes-etcd"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>1000expr: process_open_fds{job=~"kubernetes-etcd"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 600for: 2slabels:severity: warnning annotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 1000for: 2slabels:severity: criticalannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"value: "{{ $value }}"- alert: kube-proxyexpr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: schedulerexpr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-controller-managerexpr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-apiserverexpr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-etcdexpr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kube-dnsexpr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000for: 2slabels:severity: warnningannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: HttpRequestsAvgexpr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"value: "{{ $value }}"threshold: "1000" - alert: Pod_restartsexpr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0for: 2slabels:severity: warnningannotations:description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"value: "{{ $value }}"threshold: "0"- alert: Pod_waitingexpr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"value: "{{ $value }}"threshold: "1" - alert: Pod_terminatedexpr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"value: "{{ $value }}"threshold: "1"- alert: Etcd_leaderexpr: etcd_server_has_leader{job="kubernetes-etcd"} == 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"value: "{{ $value }}"threshold: "0"- alert: Etcd_leader_changesexpr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"value: "{{ $value }}"threshold: "0"- alert: Etcd_failedexpr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"value: "{{ $value }}"threshold: "0"- alert: Etcd_db_total_sizeexpr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"value: "{{ $value }}"threshold: "10G"- alert: Endpoint_readyexpr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"value: "{{ $value }}"threshold: "1"- name: 物理节点状态-监控告警rules:- alert: 物理节点cpu使用率expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90for: 2slabels:severity: ccriticalannotations:summary: "{{ $labels.instance }}cpu使用率过高"description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90for: 2slabels:severity: criticalannotations:summary: "{{ $labels.instance }}内存使用率过高"description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"- alert: InstanceDownexpr: up == 0for: 2slabels:severity: criticalannotations: summary: "{{ $labels.instance }}: 服务器宕机"description: "{{ $labels.instance }}: 服务器延时超过2分钟"- alert: 物理节点磁盘的IO性能expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"- alert: 入网流量带宽expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入网络带宽过高!"description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: 出网流量带宽expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流出网络带宽过高!"description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: TCP会话expr: node_netstat_Tcp_CurrEstab > 1000for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"- alert: 磁盘容量expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"kubectl delete -f prometheus-cfg.yaml # 删除原有配置kubectl apply -f prometheus-alertmanager-cfg.yaml # 应用刚创建的配置

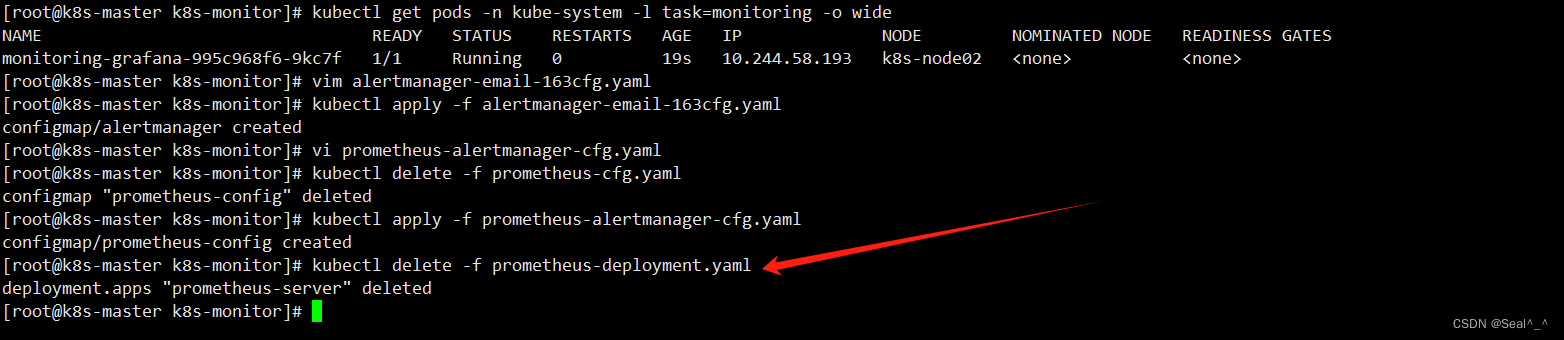
6.1.6、部署prometheus和altermanager
先删除之前安装的 Prometheus,然后创建一个包含 Prometheus 和 Alertmanager 的 Pod。
kubectl delete -f prometheus-deployment.yaml
6.1.7、通过deployment部署prometheus和altermanager
1、生成 etcd-certs(部署 Prometheus 所需的 etcd 证书)
kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
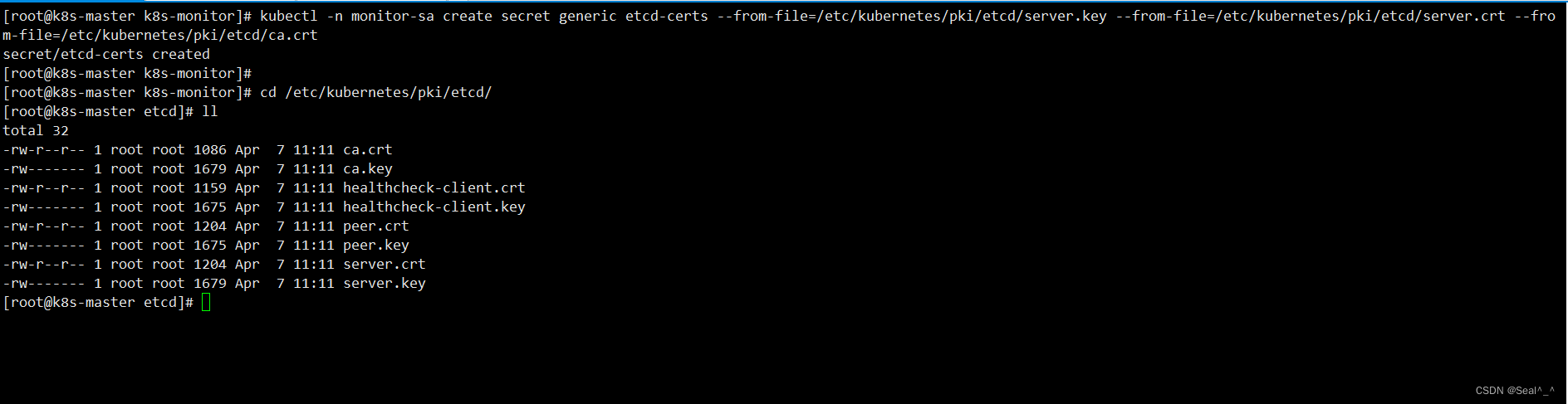
这将在 monitor-sa 命名空间下创建一个名为 etcd-certs 的 Secret。Secret 中包含了 server.key、server.crt 和 ca.crt 这三个文件,它们是部署 Prometheus 所需的 etcd 证书。
要不后面会报错:
[root@k8s-master k8s-monitor]# kubectl describe pod prometheus-server-7d5dbd84fb-xdr5r -n monitor-sa
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
Events:Type Reason Age From Message---- ------ ---- ---- -------Warning FailedMount 9s kubelet Unable to attach or mount volumes: unmounted volumes=[k8s-certs], unattached volumes=[prometheus-storage-volume k8s-certs kube-api-access-bh6jn alertmanager-config alertmanager-storage localtime prometheus-config]: timed out waiting for the conditionWarning FailedMount 4s (x9 over 2m12s) kubelet MountVolume.SetUp failed for volume "k8s-certs" : secret "etcd-certs" not found
[root@k8s-master k8s-monitor]# 
2、编辑文件 prometheus-alertmanager-deploy.yaml 的内容,根据自己的环境修改 nodeName 的值。
vim prometheus-alertmanager-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitor-salabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: server#matchExpressions:#- {key: app, operator: In, values: [prometheus]}#- {key: component, operator: In, values: [server]}template:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:nodeName: k8s-node01 ## 将prometheus pod调度到k8s-node01serviceAccountName: monitorcontainers:- name: prometheusimage: prom/prometheus:v2.2.1 ##镜像imagePullPolicy: IfNotPresentcommand:- "/bin/prometheus"args:- "--config.file=/etc/prometheus/prometheus.yml"- "--storage.tsdb.path=/prometheus"- "--storage.tsdb.retention=24h"- "--web.enable-lifecycle"ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheusname: prometheus-config- mountPath: /prometheus/name: prometheus-storage-volume- name: k8s-certsmountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/- name: alertmanagerimage: prom/alertmanager:v0.14.0imagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/alertmanager.yml"- "--log.level=debug"ports:- containerPort: 9093protocol: TCPname: alertmanagervolumeMounts:- name: alertmanager-configmountPath: /etc/alertmanager- name: alertmanager-storagemountPath: /alertmanager- name: localtimemountPath: /etc/localtimevolumes:- name: prometheus-configconfigMap:name: prometheus-config- name: prometheus-storage-volumehostPath:path: /datatype: Directory- name: k8s-certssecret:secretName: etcd-certs- name: alertmanager-configconfigMap:name: alertmanager- name: alertmanager-storagehostPath:path: /data/alertmanagertype: DirectoryOrCreate- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/Shanghai
3、将部署文件应用到 Kubernetes 集群中:
kubectl apply -f prometheus-alertmanager-deploy.yaml
4、查看prometheus是否部署成功
kubectl get pods -n monitor-sa | grep prometheus
查看日志:
kubectl logs prometheus-server-7cf6749bb-7znqh -n monitor-sa -c prometheuskubectl logs prometheus-server-7cf6749bb-7znqh -n monitor-sa -c alertmanager
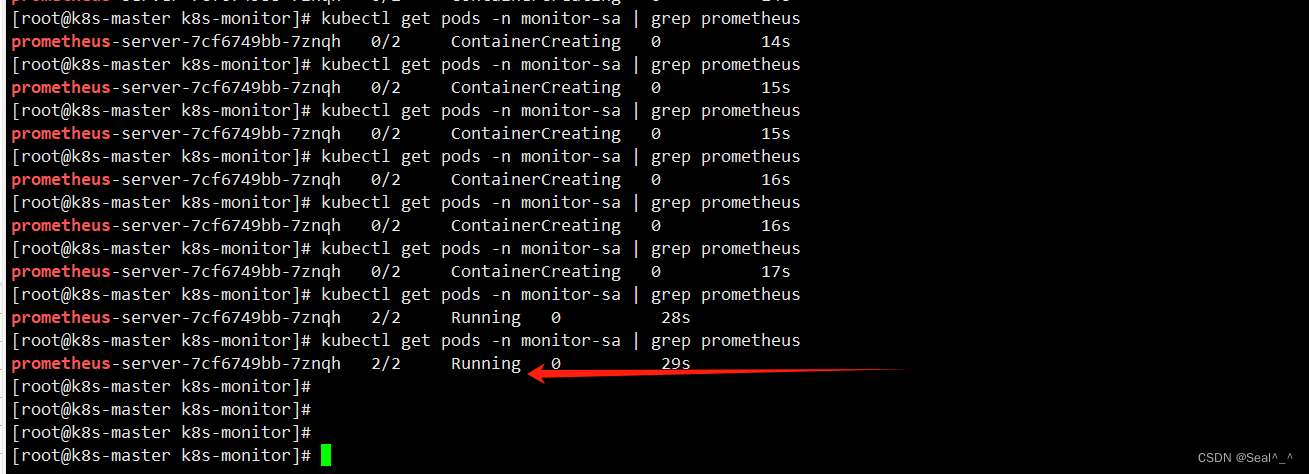
确认 Prometheus 的 Pod 状态为 Running,这表明 Prometheus 已经成功部署并且正在正常运行。
6.1.8、创建altermanager前端service,方便浏览器访问
1、在控制节点创建yaml文件
vim altermanager-svc.yaml
apiVersion: v1
kind: Service
metadata:labels:name: prometheuskubernetes.io/cluster-service: 'true'name: alertmanagernamespace: monitor-sa
spec:ports:- name: alertmanagernodePort: 30066port: 9093protocol: TCPtargetPort: 9093selector:app: prometheussessionAffinity: Nonetype: NodePort
2、应用配置文件
kubectl apply -f altermanager-svc.yaml

3、查看service在物理机的映射端口
kubectl get svc -n monitor-sa

4、浏览器访问测试
控制节点IP+端口(192.168.234.20:30066)
6.1.9、部署完成后,有关问题解决
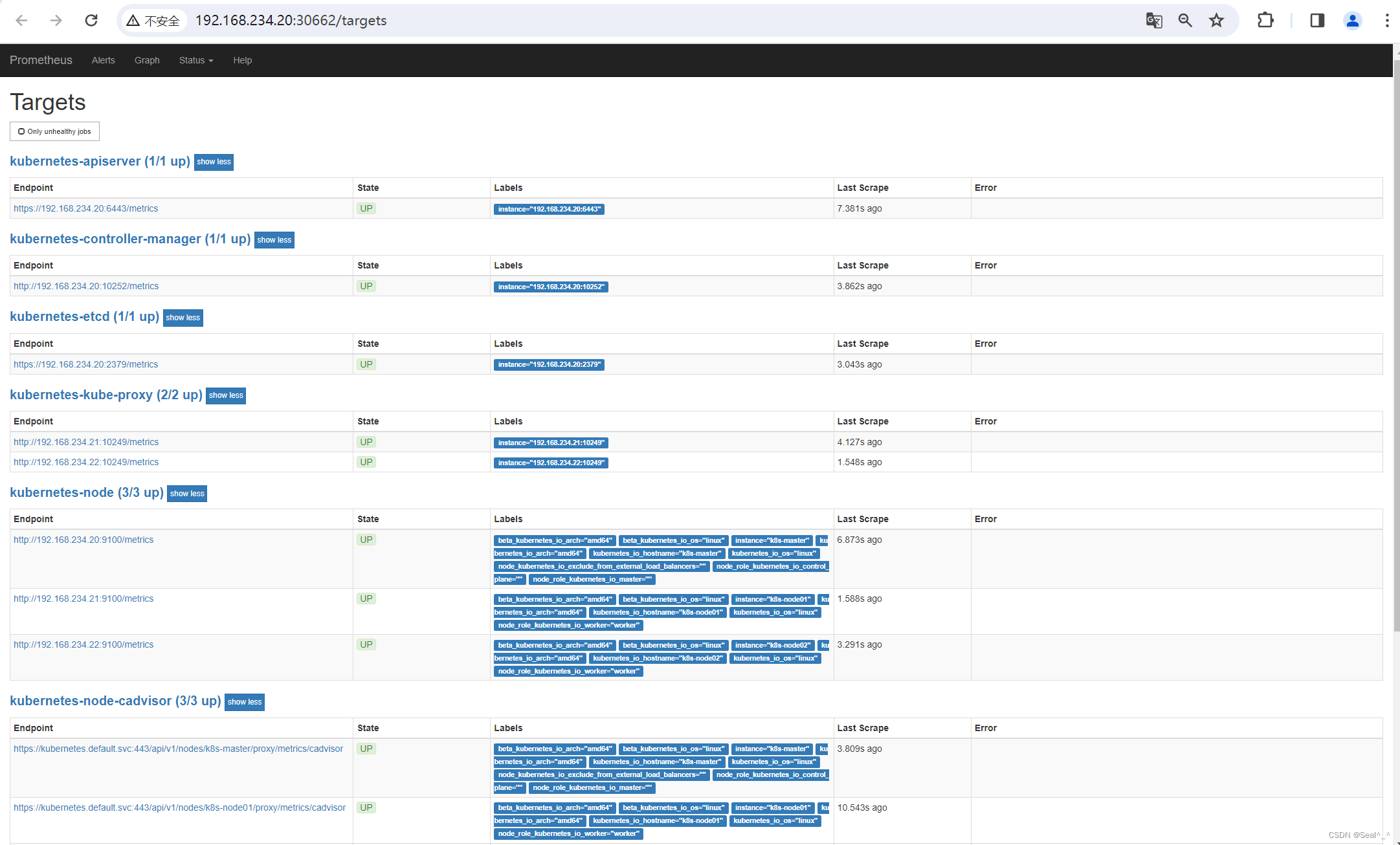
http://192.168.234.20:30682/targets
在Prometheus 页面有报错:
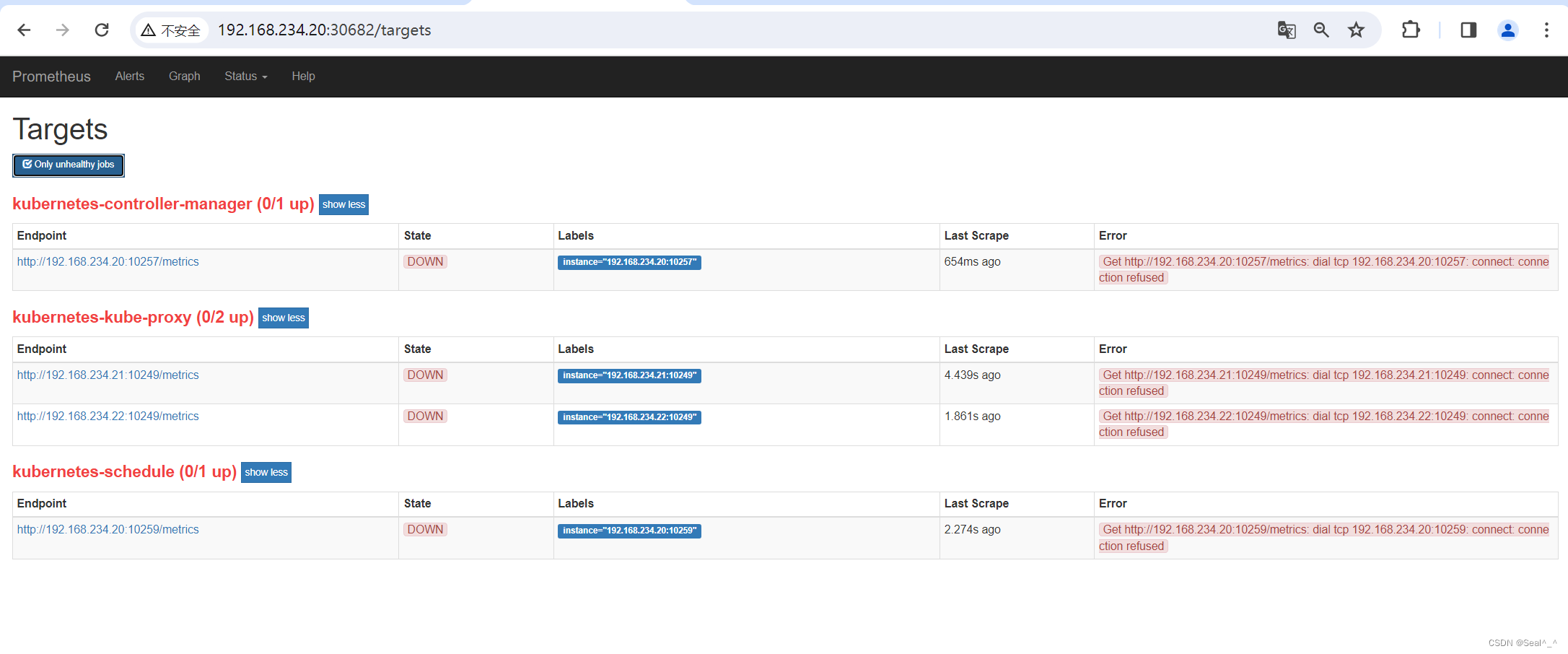
Kubernetes 中的控制器管理器(kubernetes-controller-manager)、调度器(kubernetes-scheduler)和 kube-proxy(kubernetes-kube-proxy)无法连接到它们依赖的端口,按如下方法处理:
通过修改他们绑定的端口来解决,具体通过修改kubernetes-controller-manager.yaml,kubernetes-scheduler.yaml,文件中的参数来将他们绑定到物理节点上。然后重启各节点的kubelet。
1、解决过程:
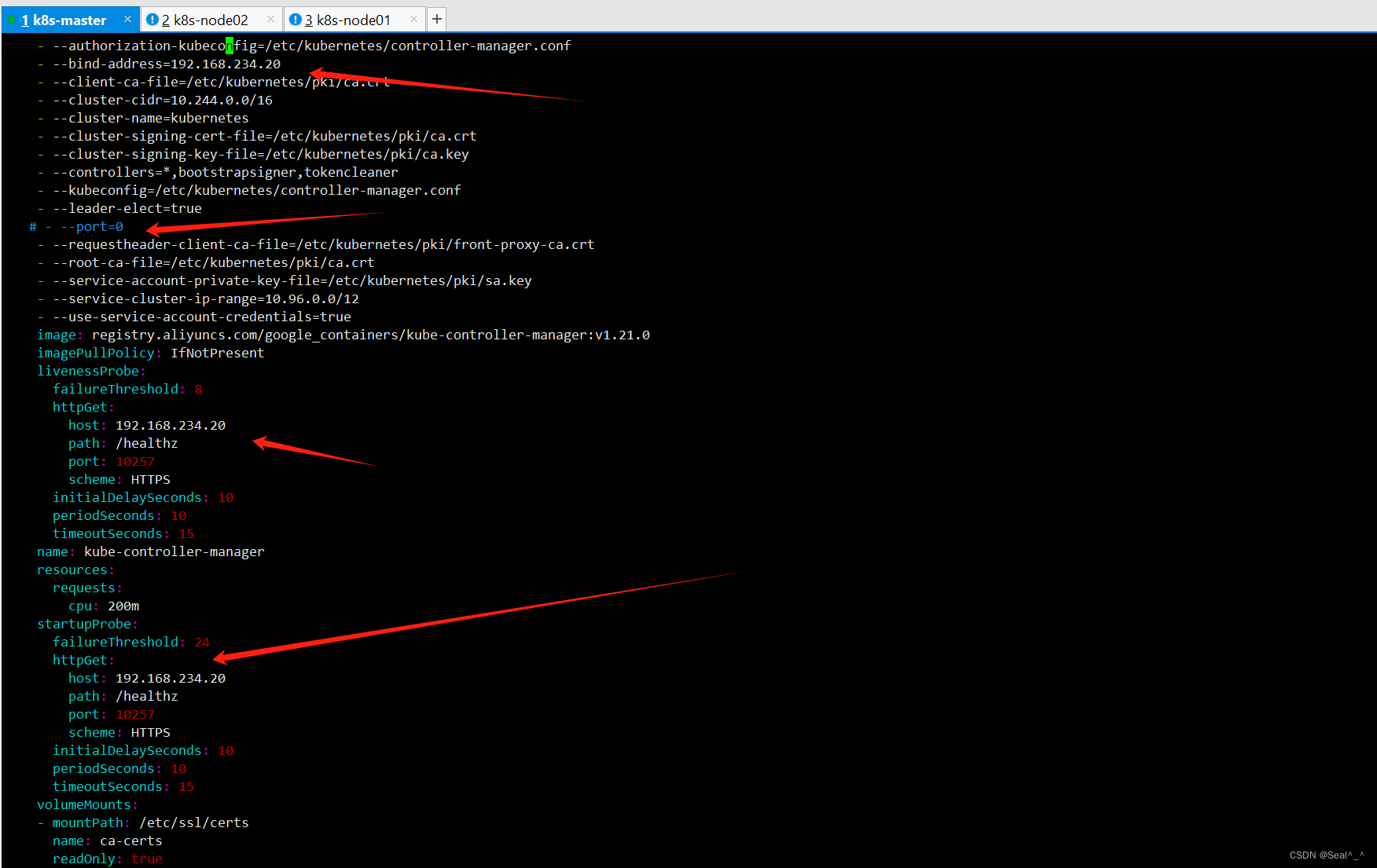
vim /etc/kubernetes/manifests/kube-controller-manager.yaml1、编辑控制器管理器配置文件:并修改其中的参数。把--bind-address=127.0.0.1 变成--bind-address=192.168.234.20把 httpGet:字段下的 hosts 由 127.0.0.1 变成 192.168.234.20把--port=0 删除,其中192.168.234.20为master控制节点IP。vim /etc/kubernetes/manifests/kube-scheduler.yaml2、编辑调度器配置文件:并修改其中的参数。把--bind-address=127.0.0.1 变成--bind-address=192.168.234.20把 httpGet:字段下的 hosts 由 127.0.0.1 变成 192.168.234.20把--port=0 删除,其中192.168.234.20为master控制节点IP。3、重启 kubelet:在每个节点上重启 kubelet 服务,以使新的配置生效。sudo systemctl restart kubeletkube-controller-manager.yaml:
kube-scheduler.yaml:
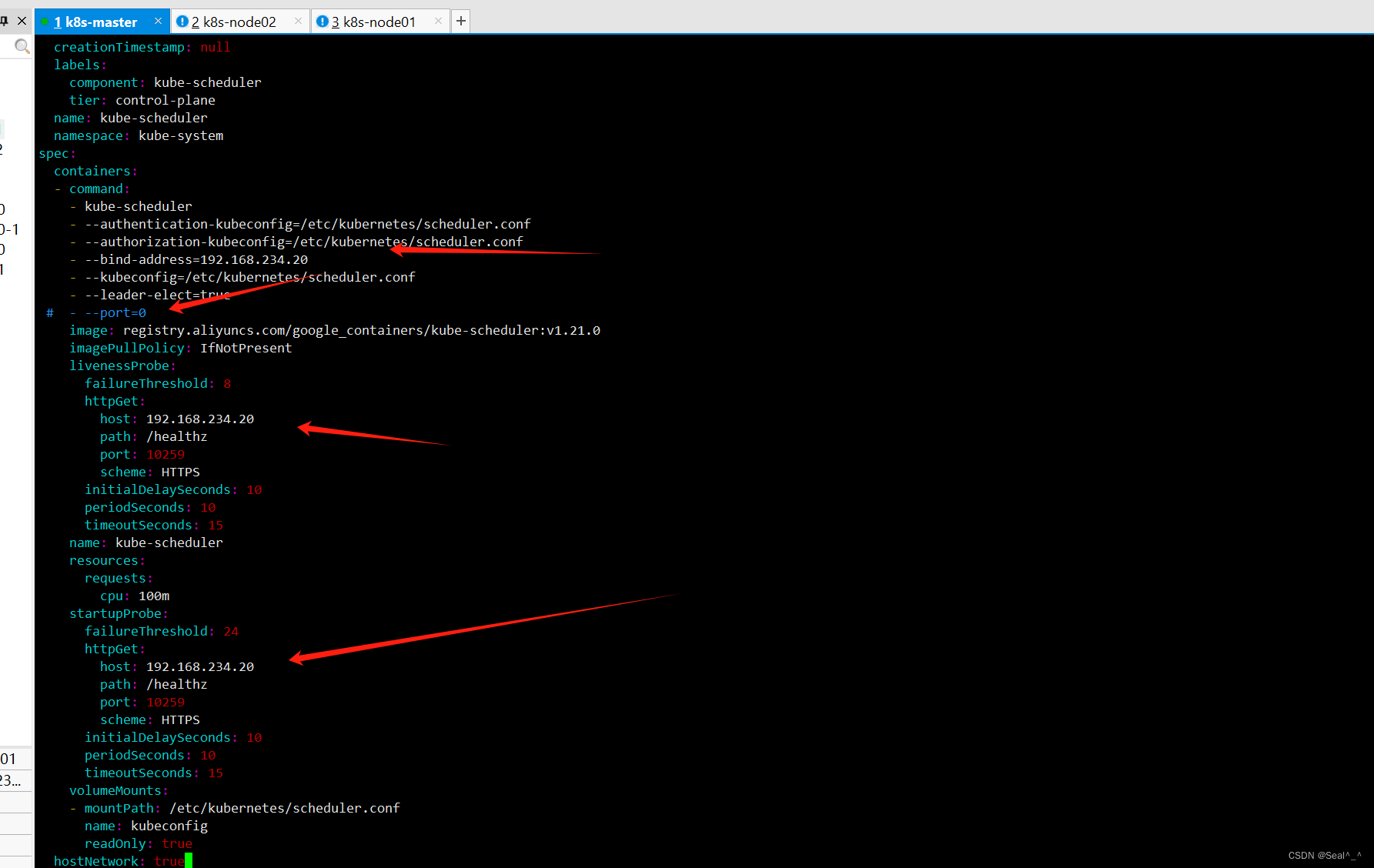
4、修改kubernetes-kube-proxy组件的端口映射地址。
编辑 kube-proxy 的 ConfigMap 来修改默认端口的绑定地址。4.1:运行以下命令编辑 kube-proxy 的 ConfigMap:kubectl edit configmap kube-proxy -n kube-system4.2:修改端口绑定地址:在编辑器中找到 metricsBindAddress 这一项,并将其修改为 0.0.0.0:10249,表示监听所有网络接口的指定端口。metricsBindAddress: "0.0.0.0:10249"4.3:重启 kube-proxy Pod:运行以下命令删除 kube-proxy Pod,Kubernetes 将自动重新创建它,以使新的配置生效:kubectl get pods -n kube-system | grep kube-proxy | awk '{print $1}' | xargs kubectl delete pods -n kube-system
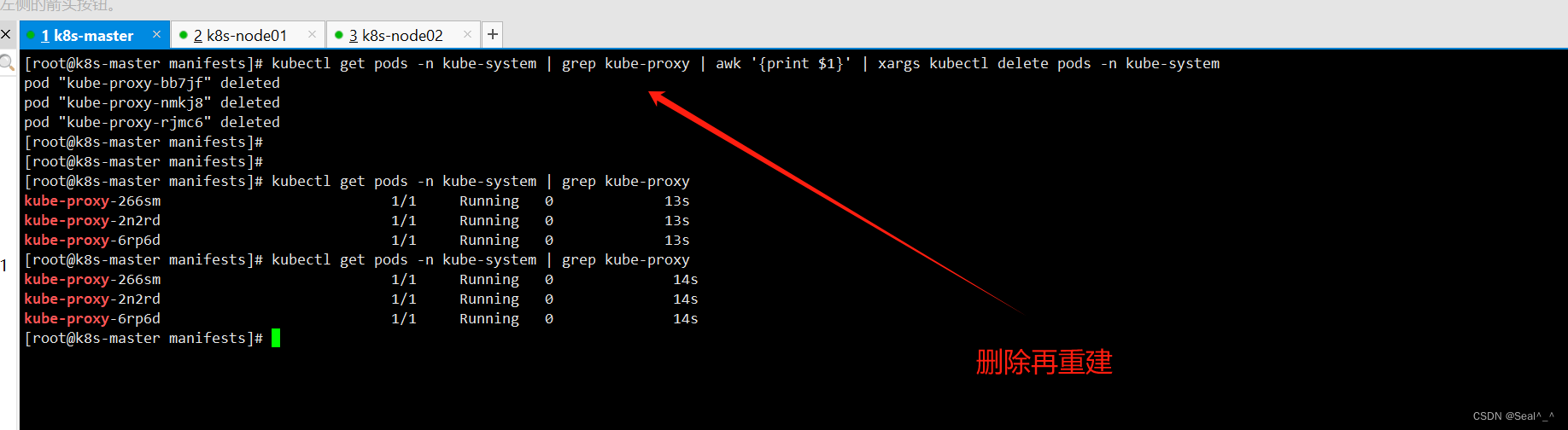
2、再次刷新Prometheus界面:
获取 Kubernetes 集群中 kube-system 命名空间下的所有 Pod 列表:
kubectl get pods -n kube-system
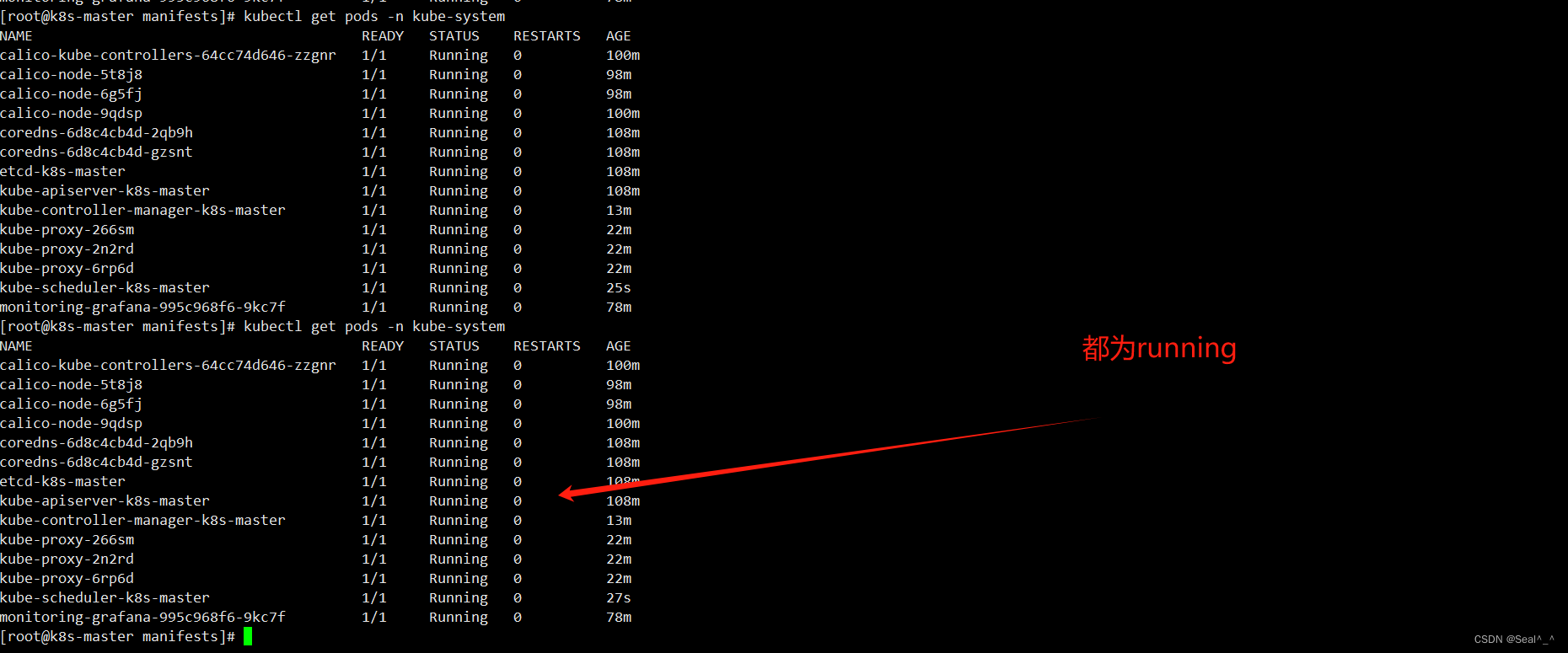
kubernetes-schedule (0/1 up)
kubernetes-controller-manager (0/1 up)
kube-proxy (0/1 up)
问题解决:
一个报警信息在生命周期内有下面3种状态:
inactive: 表示当前报警信息既不是firing状态也不是pending状态
pending: 表示在设置的阈值时间范围内被激活了
firing: 表示超过设置的阈值时间被激活了
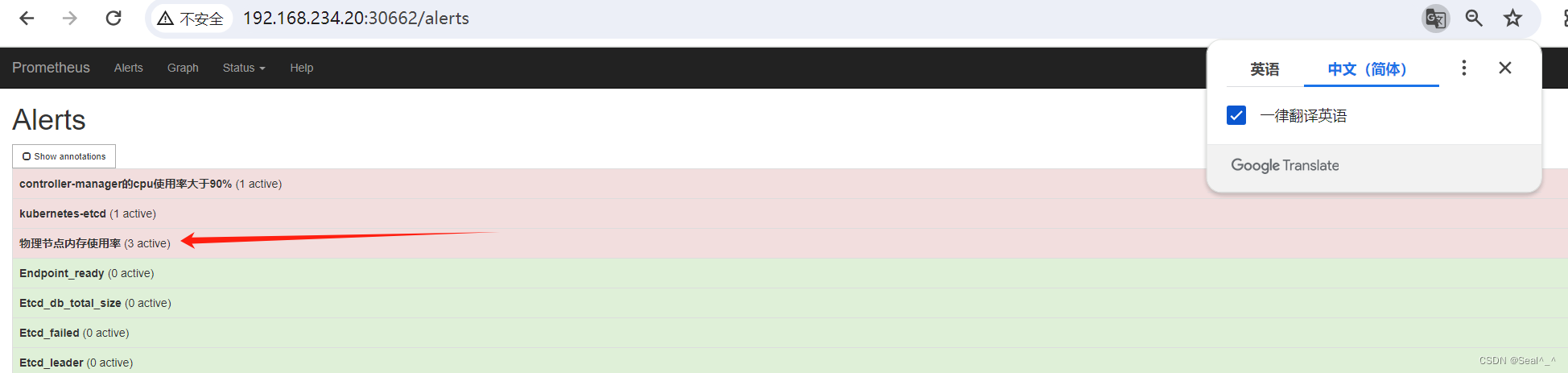
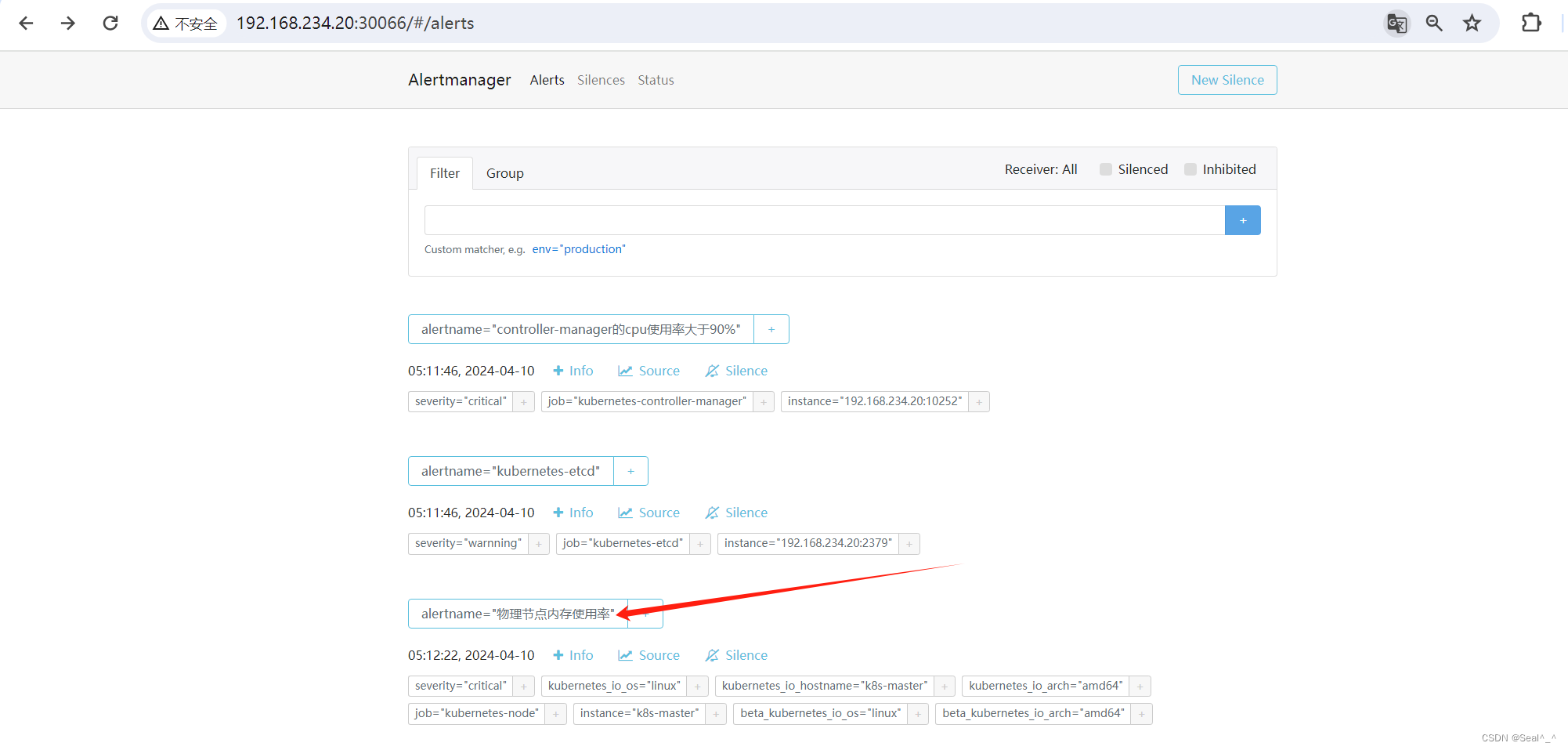
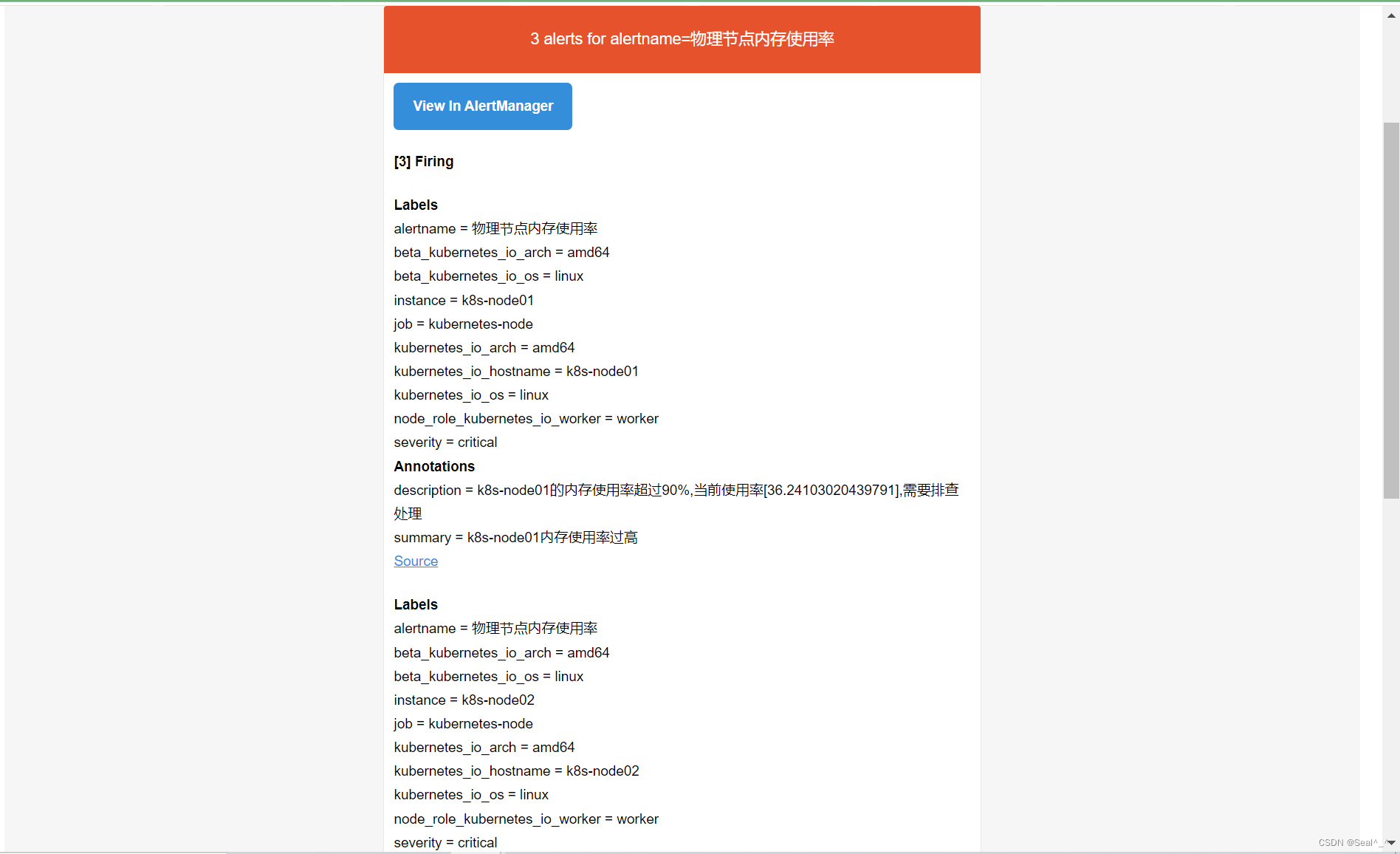
6.1.10、邮箱收取告警信息-测试
1、修改物理节点内存使用率 > 10%

Prometheus 页面:
Alertmanager页面:
QQ邮箱页面:

6.2、部署altermanager发送报警到钉钉群
6.1、创建钉钉机器人–电脑版钉钉
可以按照以下步骤在钉钉中创建自定义机器人:
https://open.dingtalk.com/document/robots/custom-robot-access
6.2、控制节点安装webhook插件
1、webhook插件下载地址:
https://download.csdn.net/download/qq_41840843/89112406
tar zxvf prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz
cd prometheus-webhook-dingtalk-0.3.0.linux-amd64

# 解压tar zxvf prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gzcd prometheus-webhook-dingtalk-0.3.0.linux-amd64

2、启动钉钉报警插件:
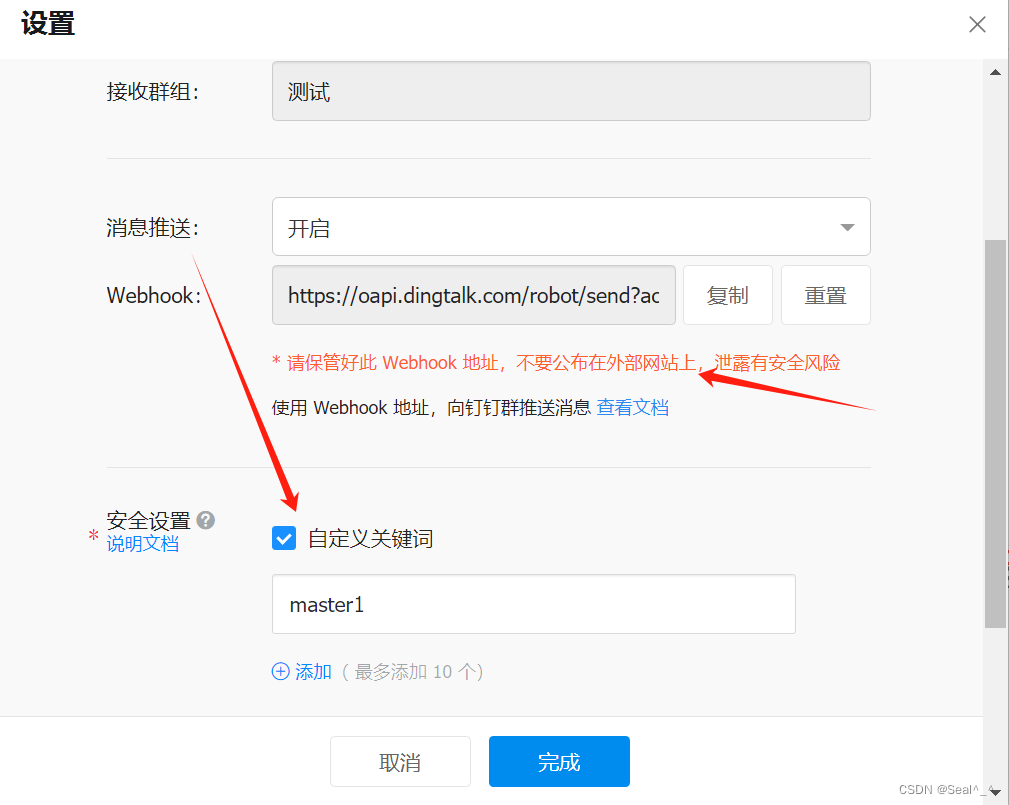
后台 启动"prometheus-webhook-dingtalk"的程序,并将其监听地址设置为"0.0.0.0:8060",同时配置了一个钉钉机器人的配置文件,其中"master1"是配置的一个别名,指向钉钉机器人的 webhook 地址。
nohup ./prometheus-webhook-dingtalk --web.listen-address="0.0.0.0:8060" --ding.profile="master1=https://oapi.dingtalk.com/robot/send?access_token=你自己的token值" &其中master1为关键词。


3、修改Alertmanager配置文件
修改接收者receiver ‘default-receiver’, '为dingding。
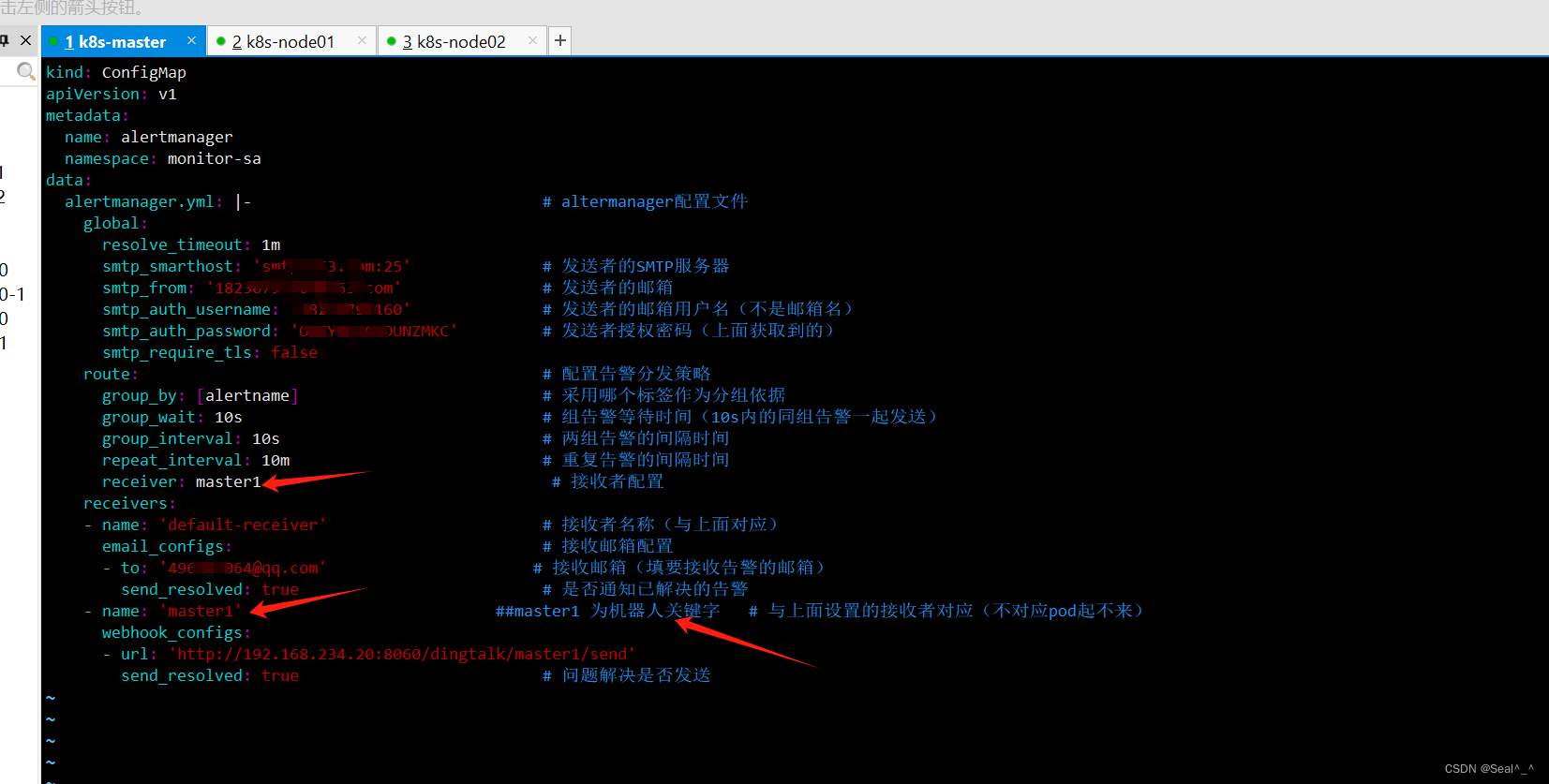
------
receiver: master1 # 接收者配置
-------- name: 'master1' # 与上面设置的接收者对应(不对应pod起不来)webhook_configs:- url: 'http://192.168.234.20:8060/dingtalk/master1/send'send_resolved: true # 问题解决是否发送
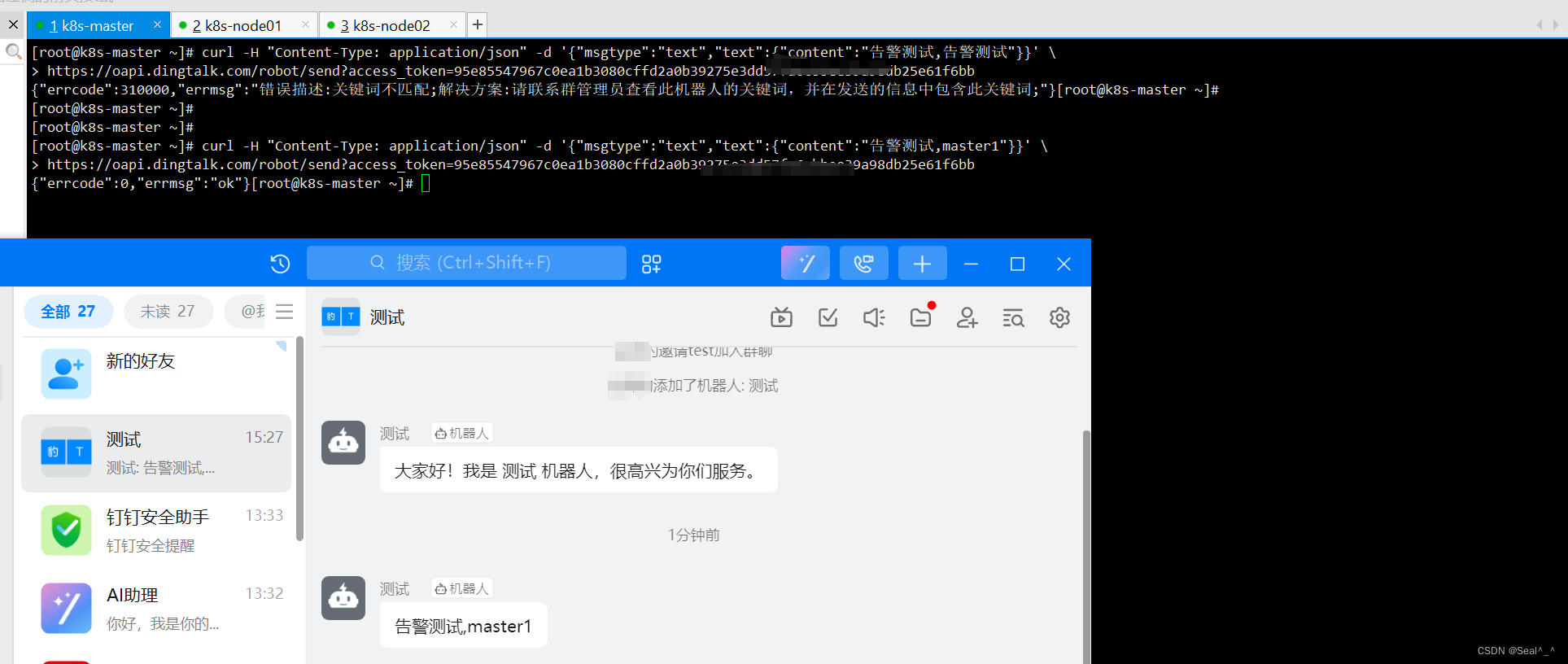
4、命令请求测试
curl -H "Content-Type: application/json" -d '{"msgtype":"text","text":{"content":"告警测试,master1"}}' \
https://oapi.dingtalk.com/robot/send?access_token=95e85547967c0ea1b3080cffd2a0b39275e3dd57fa6cbbee39a98232346bb## 注意要含有你设置的关键字
5、使配置生效
kubectl delete -f alertmanager-email-163cfg.yaml # 删除原Alertmanager配置
kubectl apply -f alertmanager-email-163cfg.yaml # 使新配置生效
kubectl delete -f prometheus-alertmanager-cfg.yaml # 删除原prometheus配置
kubectl apply -f prometheus-alertmanager-cfg.yaml # 使新配置生效
kubectl delete -f prometheus-alertmanager-deploy.yaml # 删除原deployment
kubectl apply -f prometheus-alertmanager-deploy.yaml # 创建新的deployment
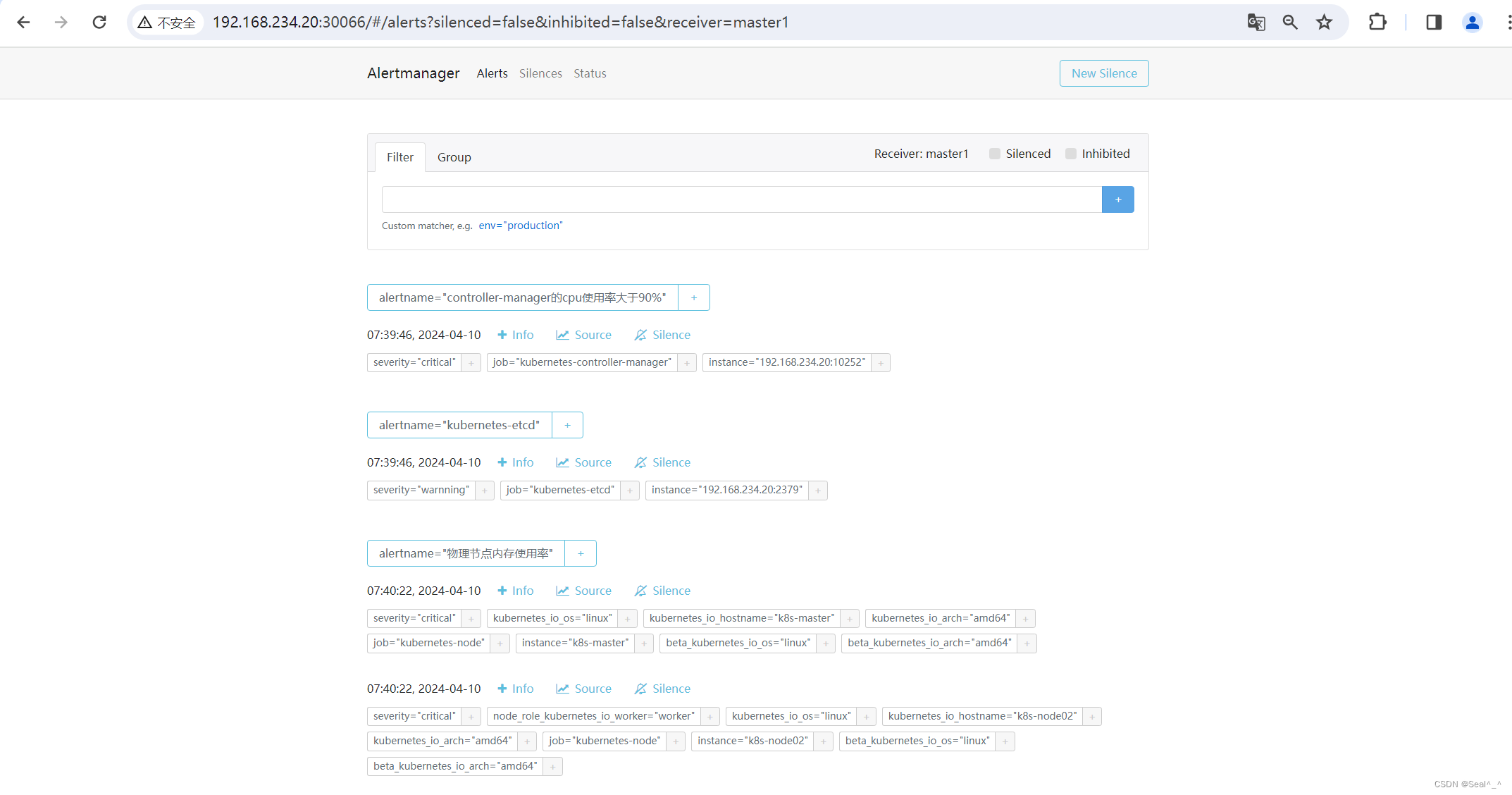
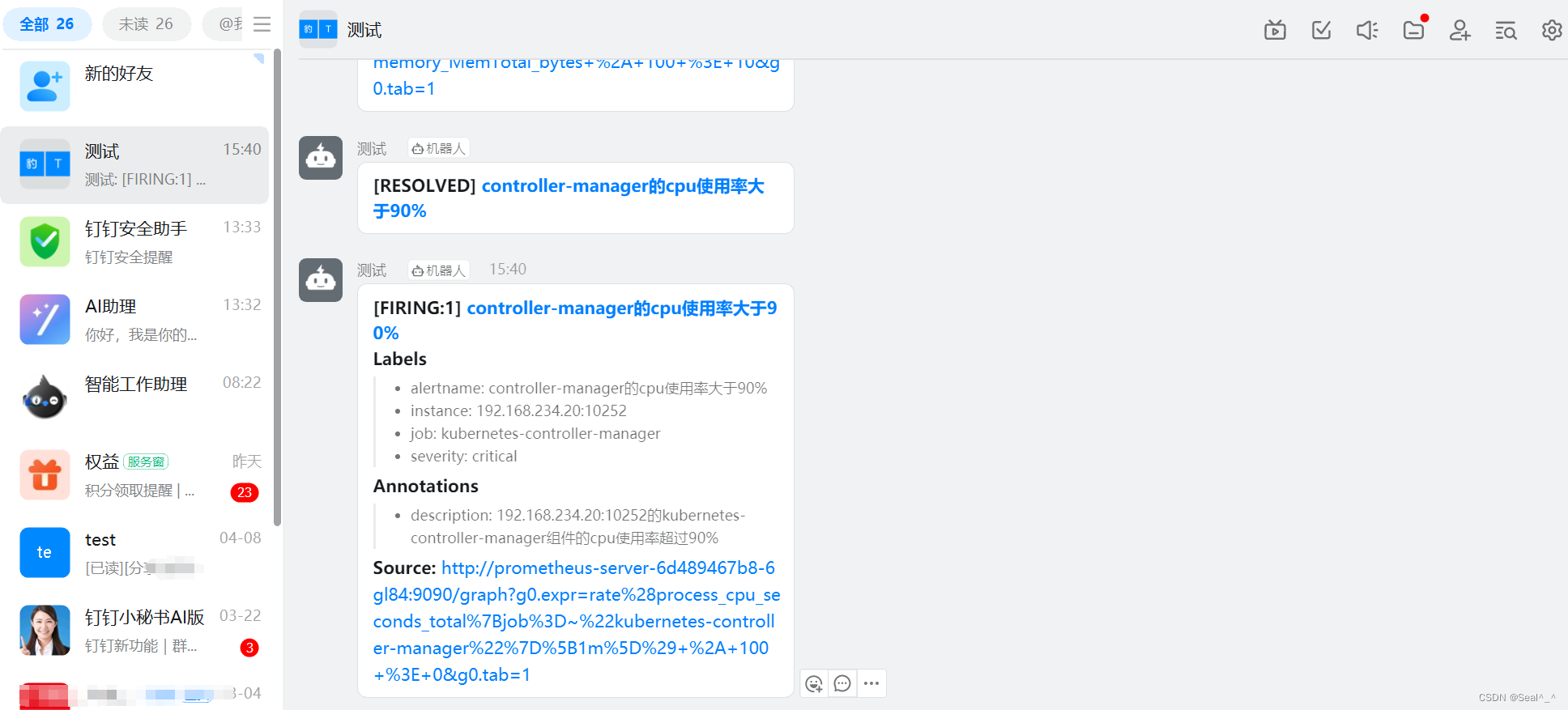
6.3、钉钉收取告警信息-验证
7、总结:
1、常用命令:
1、 创建命名空间
kubectl create namespace <namespace_name>2、列出所有的命名空间
kubectl get namespaces3、创建一个服务账号
kubectl create serviceaccount <service_account_name>4、在指定的命名空间中创建一个名为 <service_account_name> 的服务账号
kubectl create serviceaccount <service_account_name> --namespace=<namespace_name>5、应用(或创建/更新)Kubernetes 资源kubectl apply -f **.yaml6、删除 Kubernetes 资源,如部署、服务、配置映射
kubectl delete -f **.yaml
2、注意事项
1、版本兼容性: 确保所选工具的版本与您的 Kubernetes 版本兼容。不同的 Kubernetes 版本可能需要不同版本的监控工具来支持。
2、资源消耗: Prometheus 和 Grafana 是资源密集型的应用程序,特别是在大型集群中监控大量指标时。确保为它们分配足够的资源,并监视它们的性能以避免资源不足。

| 💖The End💖点点关注,收藏不迷路💖 |