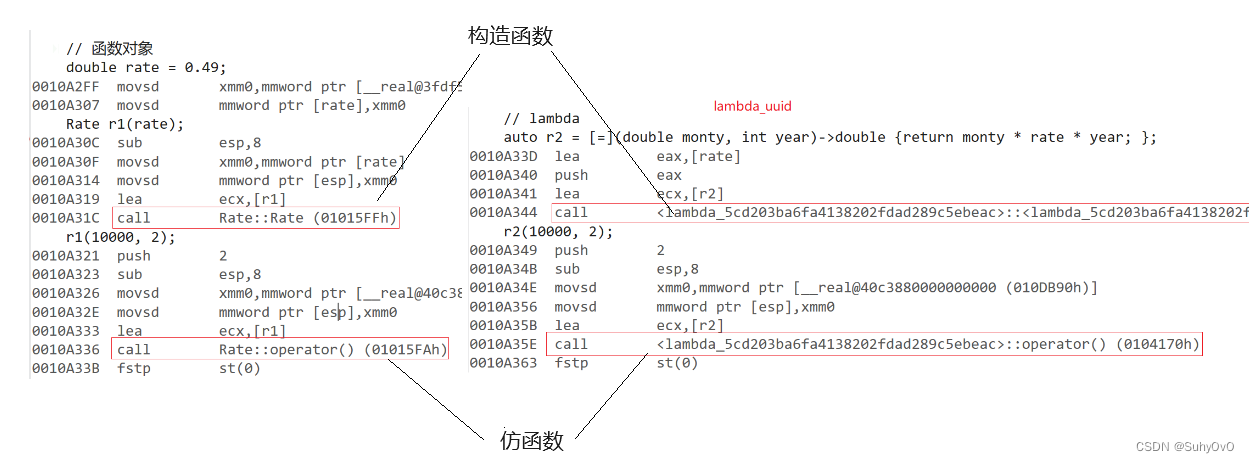
数据结构与算法课的一个实验,记录一下。
单纯想要了解利用栈求解迷宫的算法可以直接跳转到相应的小标题。
完整代码链接code_2024/mazeLab · LeePlace_OUC/code - 码云 - 开源中国 (gitee.com)
文章目录
- 要求
- 栈的实现
- MazeType类型的组织
- 迷宫的初始化和销毁
- 打印路径
- 单条路径求解
- 代码实现
- 测试
- 所有路径求解
- 代码实现
- 测试
- 对要求中其他点的回答
要求
-
基于教材和课件讲解内容,利用自己实现的栈结构完成可运行的迷宫求解程序
-
实现教材或课件中未给出的“可通”函数、“足迹打印”函数、“下一位置”函数、“打印不能通过的位置”函数等功能函数
-
实现MazeType数据类型,及可能会用到的数据对象(如,入口、出口、位置属性是墙或通路)、数据关系(如,位置之间的相邻关系)、基本操作(如,返回某个坐标位置是墙还是通路)
-
测试有通路和没通路等不同结果的输入迷宫
-
尝试进一步完善迷宫求解程序,使得从入口到出口有多条简单路径的迷宫的所有路径都能求解出来,或者从多条可行的路径中给出最短路径。
-
通过实验结果对比“入口-出口相对方向”和“探索方向的优先顺序”一致或不一致时,迷宫求解程序的运行效率。例如,当出口在入口的右下方向时,探索优先顺序是右下左上,或者上左下右时,程序运行“时间/效率/试过的位置数”是不一样的
-
分析“可通”函数原理,解释为什么迷宫求解程序得到的路径不会有环
栈的实现
首先要求实现自己的栈结构,模仿stl库里的stack接口,包含入栈push、出栈pop、获取栈顶元素top、判断栈是否为空empty等基本操作。
// 因为后续入栈的元素类型不确定,所以实现成类模板
template <typename T>
class Stack
{
private:T *_stack;int _top;int _size;public:// 默认构造函数,初始容量默认100Stack(int size = 100): _size(size), _top(-1){_stack = new T[size];}// 析构函数,直接释放掉开辟的数组空间即可~Stack(){delete[] _stack;}// 入栈操作void push(const T& x){// 首先判断栈是否满了,满了则需要扩容if (_top == _size - 1){T* newStack = new T[_size * 2];for (int i = 0; i < _size; i++)newStack[i] = _stack[i];delete[] _stack;_stack = newStack;_size *= 2;}if (_top < _size - 1)_stack[++_top] = x;}// 出栈,直接top--,当然栈中要有元素void pop(){if (_top >= 0)_top--;}// 获取栈顶元素,直接返回即可T& top(){return _stack[_top];}// 用top判空bool empty(){return _top == -1;}
};
这一步还是很简单的,没什么难度。
MazeType类型的组织
用一个全局的二维数组来存储迷宫,数组元素为0或1,1表示这个位置是墙。
因为需要取路径点进栈,所以需要组织数据结构描述迷宫中的路径点,只需要三个数据成员即可表示,横纵坐标和当前节点的前进方向,所以声明MazeType结构:
struct MazeType
{int x; // 横坐标int y; // 纵坐标int dir; // 方向,0:向右、1:向下、2:向左、3:向上// 简单的构造函数MazeType(int x = 0, int y = 0, int dir = 0): x(x), y(y), dir(dir){}
};
后面用栈求路径时会有几种操作,比如判断当前这个位置是否是终点、是否可通,留下足迹表示这个点走过了,这个点下一步应该走到那个位置,留下足迹表示这个点在当前路径下是不可通的等等。将这些基本操作实现为成员函数。
下面依次进行实现,首先判断是否是终点,很简单,实现一个判断逻辑相等运算符重载即可,后面用的时候直接if (pos == out):
bool operator==(MazeType &a)
{return x == a.x && y == a.y;
}
然后是判断是否可通,很简单,只要当前位置在迷宫中的标识是0就是可通的,如果是1则是墙不可通,或者是在栈中的(也会进行相应标识)也不可通:
bool IsPass()
{if (maze[x][y] == 0)return true;return false;
}
然后是留下足迹表示这个点走过了,也就是在栈中:
void FootPrint()
{maze[x][y] = dir + 2;
}
这里直接将迷宫中对应位置设置成方向号+2,因为不能和0、1重了,所以直接这样设了,还方便后续直接打印路径。
接下来是求下一个路径点,也很简单,直接根据方向号加减对应坐标即可:
MazeType NextPos()
{MazeType next(x, y);switch (dir){case 0: // 向右,列数加1next.y++;break;case 1: // 向下,行数加1next.x++;break;case 2: // 向左,列数减1next.y--;break;case 3: // 向上,行数减1next.x--;break;}return next;
}
最后是留下足迹表示从这个点走下去走不通,这个一般是在路径点所有方向遍历完之后出栈用:
void MakePrint()
{maze[x][y] = -1;
}
所以完整的MazeType结构的定义如下:
struct MazeType
{int x;int y;int dir;MazeType(int x = 0, int y = 0, int dir = 0): x(x), y(y), dir(dir){}bool operator==(MazeType &a){return x == a.x && y == a.y;}bool IsPass(){if (maze[x][y] == 0)return true;return false;}void FootPrint(){maze[x][y] = dir + 2;}MazeType NextPos(){// next的dir直接缺省,默认为0,这个一定要注意,千万不要写成next(x, y, dir)// 别问,问就是一开始写错了,debug好久MazeType next(x, y);switch (dir){case 0: // 向右,列数加1next.y++;break;case 1: // 向下,行数加1next.x++;break;case 2: // 向左,列数减1next.y--;break;case 3: // 向上,行数减1next.x--;break;}return next;}void MakePrint(){maze[x][y] = -1;}
};
迷宫的初始化和销毁
这一模块主要是处理输入的,输入格式为迷宫的行号和列号,接下来几行就是0/1迷宫了,加下来两行是起点和终点的坐标,对于这一部分关键变量直接定义成全局的,减少设计参数的负担。
首先是初始化迷宫,对于迷宫的输入,要求不包括边界,边界在代码中手动添加,就是一圈1,这样就不用考虑是否越界的问题了:
int** maze, row, col;void InitMaze()
{cout << "请输入迷宫的行数和列数:";cin >> row >> col;// 申请空间maze = new int*[row + 2];for (int i = 0; i < row + 2; i++)maze[i] = new int[col + 2];// 初始化迷宫的边界for (int i = 0; i < row + 2; i++){maze[i][0] = 1;maze[i][col + 1] = 1;}for (int i = 0; i < col + 2; i++){maze[0][i] = 1;maze[row + 1][i] = 1;}// 输入迷宫数据cout << "请输入迷宫的数据:" << endl;for (int i = 1; i <= row; i++)for (int j = 1; j <= col; j++)cin >> maze[i][j];
}
对应的是销毁,也就是释放空间:
void DestroyMaze()
{for (int i = 0; i < row + 2; i++)delete[] maze[i];delete[] maze;
}
起点终点的输入处理也在这块写了。终点和起点用两个MazeType对象表示,也设置成全局的:
MazeType in, out;
void InitStartAndEnd()
{cout << "请输入起点的坐标:";cin >> in.x >> in.y;cout << "请输入终点的坐标:";cin >> out.x >> out.y;
}
这块对输入的处理均没有考虑容错,假设所有输入都是合法的。
打印路径
为了形象一点,直接把路径从迷宫中标出来,墙用■来表示,如果路径存在的的话用箭头来标识:
void PrintPath()
{for (int i = 0; i < row + 2; i++){for (int j = 0; j < col + 2; j++){if (maze[i][j] == 1)cout << "■ ";else if (maze[i][j] == 2)cout << "→ ";else if (maze[i][j] == 3)cout << "↓ ";else if (maze[i][j] == 4)cout << "← ";else if (maze[i][j] == 5)cout << "↑ ";elsecout << " ";}cout << endl;}
}
单条路径求解
代码实现
利用栈其实就是dfs。
一开始起始点入栈,然后取栈顶元素作为当前路径点,判断该路径点是否可通,如果可通,则走到下一个点,下一个点入栈,继续重复这个过程。
如果不可通,则需要进行回退,也就是出栈,取新的栈顶元素,也就是上一个点,换一个方向继续走,如果所有 方向都走完了,说明从这个点只会走到死路,留下死路标记,这个点出栈,继续重复。
如果走到了终点就打印路径然后返回,如果走着走着栈为空了,则说明不存在从起点到终点的路径。
明白这个过程代码还是容易写的:
Stack<MazeType> stack; // 栈对象也定义成全局的
bool MazePath()
{MazeType curpos = in; // curpos表示当前走到的位置,初始化为起点int steps = 1; // steps记录当前探索过的步数,不是实际路径长度do // 用do-while省去初始化步骤{if (curpos.IsPass()) // 当前位置可通,留下足迹然后找下一个位置{curpos.FootPrint(); // 留下足迹stack.push(curpos); // 当前位置入栈if (curpos == out) // 走到终点{cout << "找到路径,一共探索了" << steps << "步:" << endl;PrintPath(); // 打印路径return true;}curpos = curpos.NextPos(); // 迭代到下一位置继续steps++; // 探索步数+1}else // 当前位置不可通,回溯,需要依次取栈顶元素,也就是上一个点,换方向走{if (!stack.empty()) // 栈不为空,还有可以换方向的路径点{MazeType tmp = stack.top();stack.pop();// 当前路径点的所有方向都走过了,需要标记为死路然后继续取栈顶元素while (tmp.dir == 4 && !stack.empty()){tmp.MakePrint();tmp = stack.top();stack.pop();}// 当前路径点还可以变方向,换个方向入栈,然后从新的点继续走if (tmp.dir < 4){tmp.dir++; // 换个方向stack.push(tmp); // 重新入栈tmp.FootPrint(); // 更新足迹curpos = tmp.NextPos(); // 更新新方向的下一个点steps++; // 探索步数+1}}}} while (!stack.empty());// 走到这里说明栈中已经没有路径点了,即起点的四个方向都探索遍了,无路可走return false;
}
这个问题的解空间可以用树来表示,根节点为起点,四个分支,每个分支指向下一个点,然后下一个点又有四个分支…如果用dfs其实是不好求解最短路径的,不过可以求所有路径。求最短路径还得是bfs。
测试
测试代码写在main函数中,如下:
int main()
{InitMaze();InitStartAndEnd();bool flag = MazePath();if (!flag){cout << "没有找到路径,迷宫无解:" << endl;PrintPath();}DestroyMaze();return 0;
}
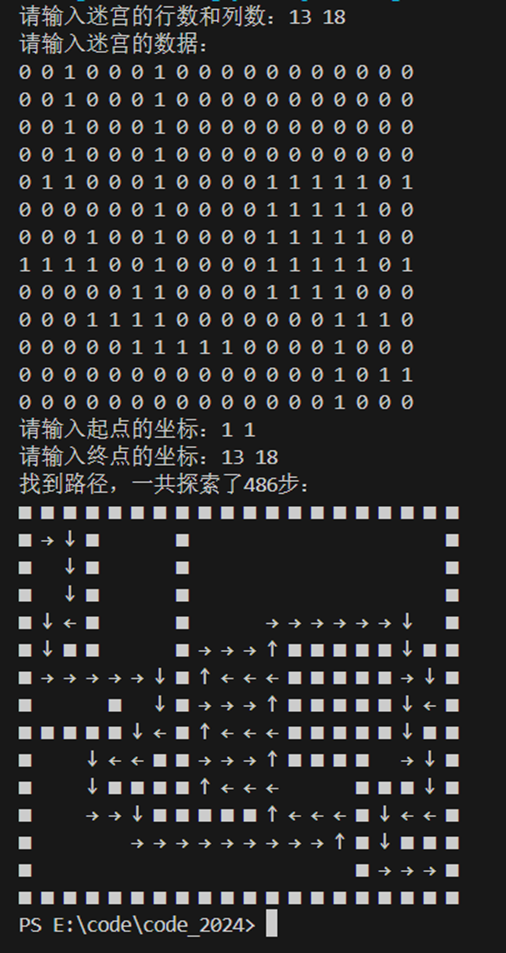
提供两组测试用例,一组有路径,一组没路径:
13 18
0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
0 1 1 0 0 0 1 0 0 0 0 1 1 1 1 1 0 1
0 0 0 0 0 0 1 0 0 0 0 1 1 1 1 1 0 0
0 0 0 1 0 0 1 0 0 0 0 1 1 1 1 1 0 0
1 1 1 1 0 0 1 0 0 0 0 1 1 1 1 1 0 1
0 0 0 0 0 1 1 0 0 0 0 1 1 1 1 0 0 0
0 0 0 1 1 1 1 0 0 0 0 0 0 0 1 1 1 0
0 0 0 0 0 1 1 1 1 1 0 0 0 0 1 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0
1 1
13 18
运行如下:
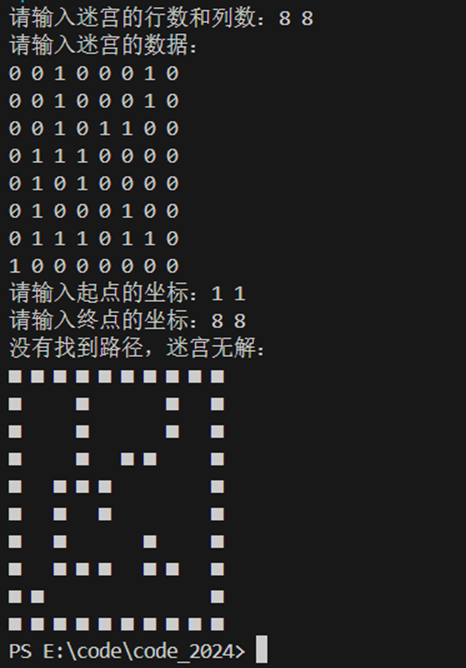
无路径的测试用例:
8 8
0 0 1 0 0 0 1 0
0 0 1 0 0 0 1 0
0 0 1 0 1 1 0 0
0 1 1 1 0 0 0 0
0 1 0 1 0 0 0 0
0 1 0 0 0 1 0 0
0 1 1 1 0 1 1 0
1 0 0 0 0 0 0 0
1 1
8 8
运行如下:
所有路径求解
代码实现
这次测试用例就简化一下,用一个3*3的无墙迷宫:
3 3
0 0 0
0 0 0
0 0 0
1 1
3 3
求所有路径和求单条路径的区别在于当走到终点时,不应直接返回,而是回溯继续走。
如果只考虑到这点,修改代码后跑出来的结果如下:
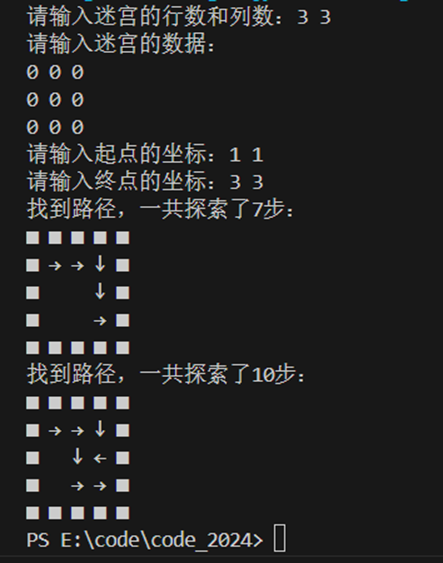
这其实是因为前面的路径点不会“回头”的原因。比如这个点已经是向下了,那它以后都不会再向右,因为回溯到该点的时候它的方向还是保留的上一条路径中的方向,所以会沿着上一条路径的方向走下去。
比如这个点已经是向下了,那它以后都不会再向右,但实际向右的话还有路。
一个解决方法是找到一条路径后从头再走一遍,但是这样效率极低,并且不好处理相同路径。
换个角度,每个点只会走一次,所有方向走完之后会被设置为死路点,但是在另一条路径中又会走到之前的点。
所以采取在每个点的所有方向都走一遍之后不将其设置为不可通,而改为初始未走过的状态,这样以后还可以走到该点。
给MazeType类型增加一个清除足迹的函数:
void ClearPrint()
{maze[x][y] = 0;
}
改进后的MazePath函数如下:
bool flag = false;
Stack<MazeType> stack;
void MazePath()
{MazeType curpos = in;int steps = 1;do{if (curpos.IsPass()){curpos.FootPrint();stack.push(curpos);if (curpos == out){flag = true;cout << "找到路径,一共探索了" << steps << "步:" << endl;PrintPath();// 继续寻找其他路径,根节点出栈curpos = stack.top();stack.pop();curpos.ClearPrint(); // 清除根节点的痕迹,保证以后还能走到根节点curpos = stack.top();curpos.dir++; // 上一个点换个方向,继续向下走steps--; // 这个是否需要--存疑,不太确定,但还是写了continue; // 不要返回,继续循环}curpos = curpos.NextPos();steps++;}else{if (!stack.empty()){MazeType tmp = stack.top();stack.pop();while (tmp.dir == 4 && !stack.empty()){tmp.ClearPrint(); // 四个方向都走不通,清除足迹tmp = stack.top();stack.pop();}if (tmp.dir < 4){tmp.dir++;stack.push(tmp);tmp.FootPrint();curpos = tmp.NextPos();steps++;}}}} while (!stack.empty());
}
我写完之后其实还是有点怀疑的,毕竟当一个点四个方向都试过时候就清楚它的足迹,这样不会导致死循环吗?
其实结合一下dfs遍历路径树就好理解了,求出所有路径也就是遍历完整颗树时,回到了根节点,此时栈中只剩起点,并且起点的四个方向都走完了,此时清楚其走过的痕迹,然后出栈,接下来栈就空了,循环不会再继续了。
所以如果有路径的话,在求完所有路径之后,循环也就停了。
测试
还是用一开始给的测试用例,结果如下:
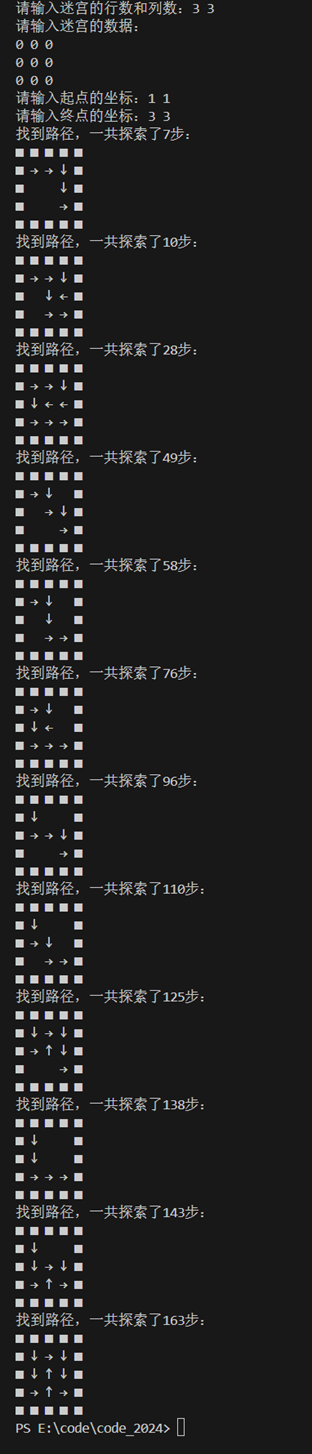
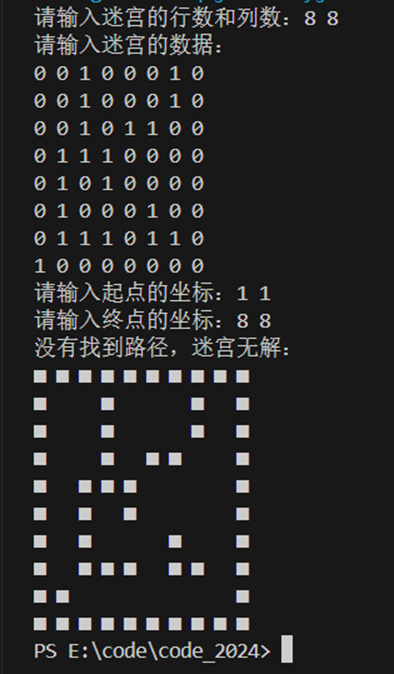
用没有路径的用例进行测试,结果也是对的:
对于最短路径,可以在打印的时候统计一下有多少个箭头,箭头的数量就是路径的长度,箭头数最少的那个就是最短路径,可以使用额外的数据结构进行保存,就不展开说了。不推荐用dfs求最短路径。
对要求中其他点的回答
通过实验结果对比“入口-出口相对方向”和“探索方向的优先顺序”一致或不一致时,迷宫求解程序的运行效率。
对这点程序早有准备,使用一个steps变量进行计数,下面使用求单路径的代码进行测试。
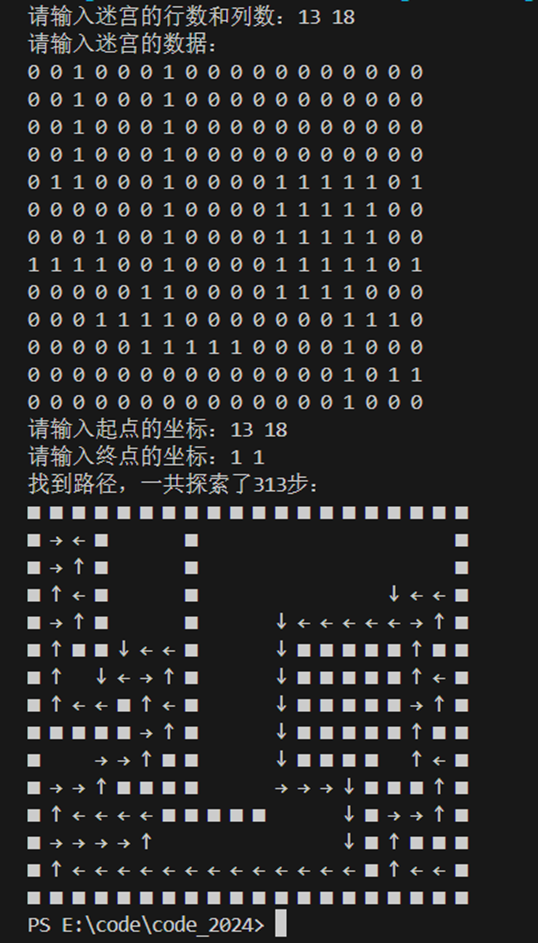
我设置的探索优先顺序是右下左上,测试用例提供的起点是(1, 1),终点是(13, 18),为左上到右下,优先级设置的比较合理,不会出现大量的点往上或往左走,上面求得的探索过的次数为486次。
下面将终点和起点反过来,起点在右下,终点在左上。
此时测试结果如下:
结果有点尴尬,竟然更快了。。
显然这还和迷宫的地形有关,沿着右下左上的优先级使中间那一部分点直接沿着墙根走了,所以会快很多。
下面取消所有墙,重新进行几组测试。
测试数据如下:
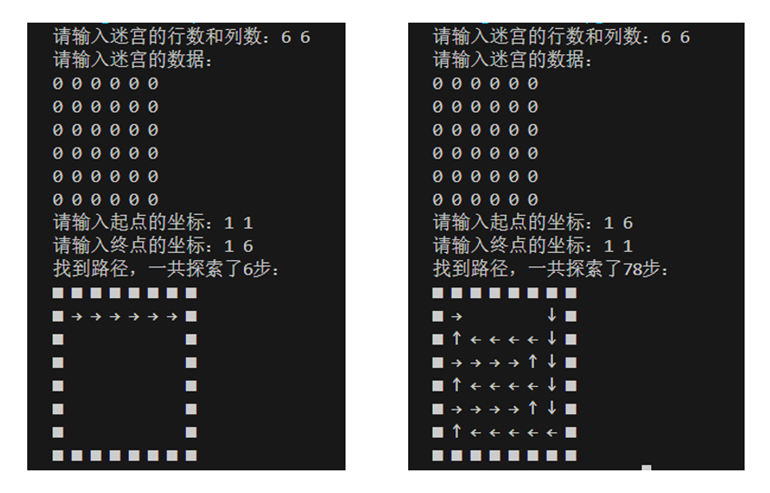
6 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0第一组:(1,1)->(1,6) vs (1,6)->(1,1):
第二组:(1,1)->(6,6) vs (6,6)->(1,1):
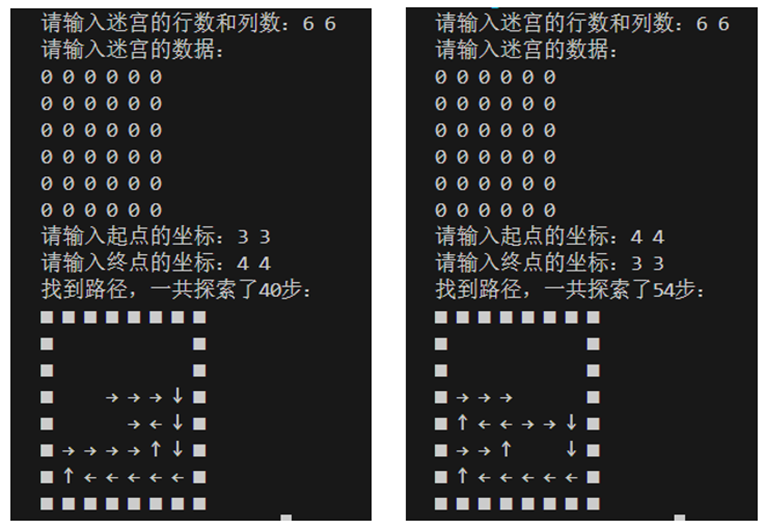
第三组:(3,3)->(4,4) vs (4,4)->(3,3):
可见在排除迷宫结构的因素下,当参照起点和终点的相对位置设置方向优先级时,是可以提高求解效率的。

分析“可通”函数原理,解释为什么迷宫求解程序得到的路径不会有环
可通函数是在maze中该点标记为0才可通,当点入栈之后,标记会变成方向数+2,当四个方向遍历结束后,标记会变成-1,表示在当前探索的路径中该点不可通,所以每个点只会走一次,而如果走出环至少要有一个点走两次,所以在寻找当前这条路径时不会有环。
![QFS [VLDB‘13] 论文阅读笔记](https://img-blog.csdnimg.cn/direct/85b17ef90a8841f18c8691926ad8b023.png#pic_center)