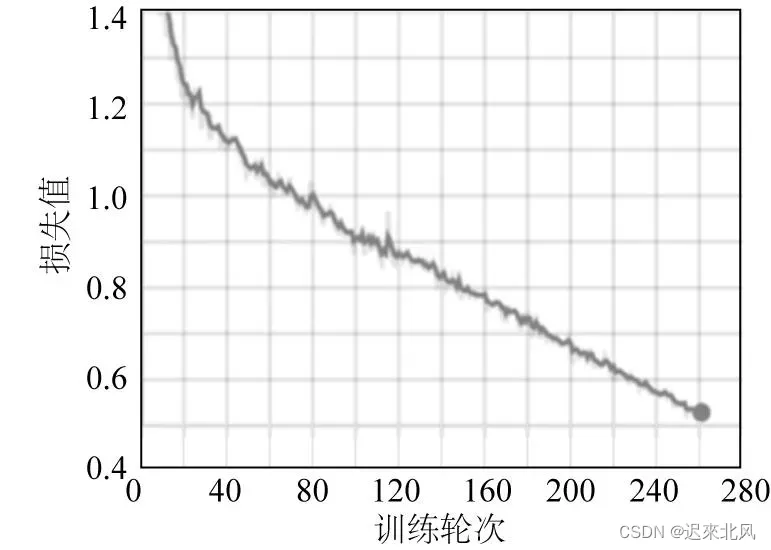
一、主要贡献
深度网络输入数据在逐层进行特征提取和空间变换时,会丢失大量的信息。针对 信息丢失问题,研究问题如下:
1)从可逆功能的角度对现有深度神经网络架构进行了理论分析,解释了许多过去难以解释的现象,设计了PGI 辅助可逆分支,可以用于各种深度的网络,并取得了出色的结果。
2)同时考虑了参数数量、计算复杂性、准确性和推理速度,设计的GELAN只使用传统卷积,以实现比基于最先进技术的深度卷积设计更高的参数使用率,同时显示出轻量、快速和准确的巨大优势。
3)结合所提出的PGI和GELAN,设计了YOLOv9在MS COCO数据集上的目标检测性能在各个方面大大超过了现有的实时目标检测器。
PS
截止20240416 的git 代码实现:
1)作者仅仅开源了c和e模型的配置文件,而且只有两个head,共计6个输出头,和论文的9头几乎对不上。
2)所谓的PGI作者解释的很学术范,实现就是复制一个backbone,然后结合辅助分支,感觉这个pgi的故事,其实就是两个不同大小的模型互相蒸馏,然后推理可以只保留某个(或大或小)的主分支。
3)关于GELAN的创新,主要就是ELAN的拓展,允许把里面最简单的CNN,套娃换为CSPNet等。
4)后文那个可视化(不同backbone的随机初始化权重得到的结果就能证明信息保留程度),我是真的没有看懂,首先网络都没有下采样,网络的结构是什么样的?其次我自己的拙见,也有人在issue中提问,这里的丢失信息和网络本来的拟合目标的能力有正相关吗?拟合过程本身也是一个统计并去冗余过程。
综上,个人目前建议大概看看论文就好,还是让子弹飞一飞吧,这个V9的名字靠这两个创新点+真正实现对不上文章感觉。。。。
二、主要思路
PGI
整个PGI的结构论文提到如下图d. 关于PGI讲的故事这里简单用作者在git issue的一张图吧,因为实现其实就是另一个并行backbone+辅助分支,所以感觉看看就好。


GELAN
就是ELAN的扩展,允许讲conv 变为任意模块,并验证有效性。
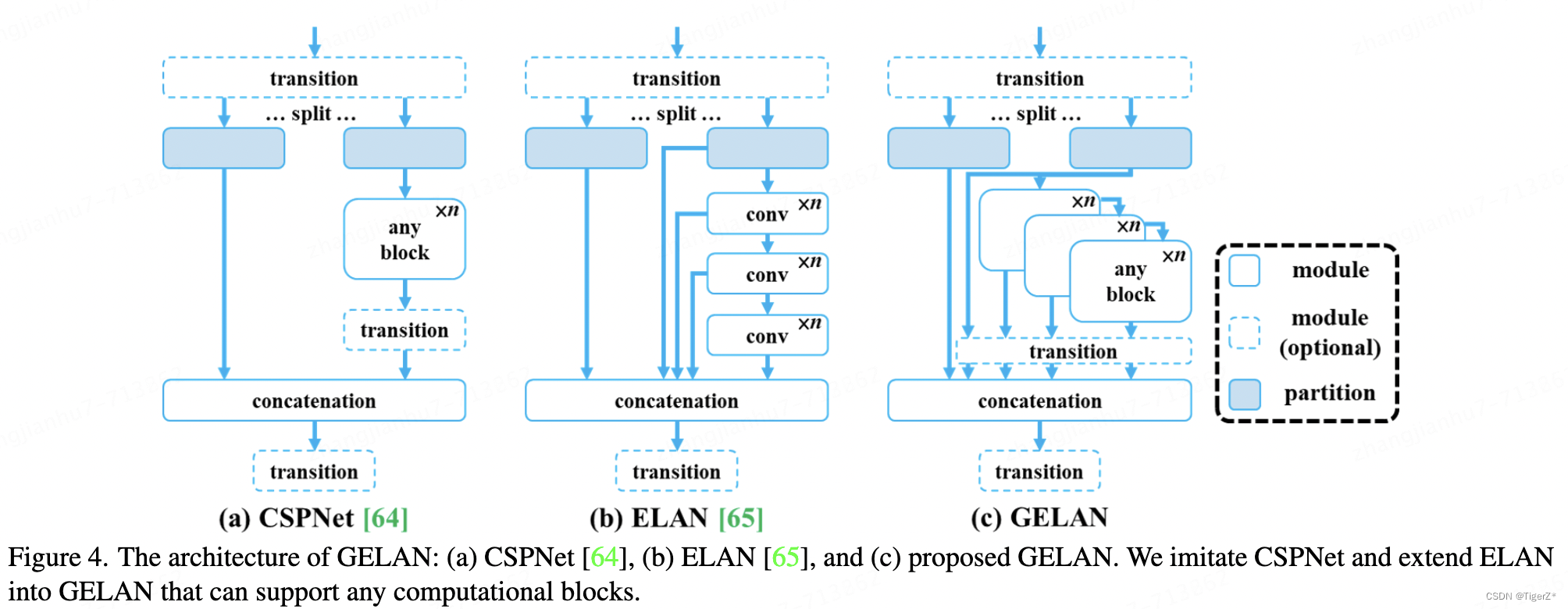
三、具体细节
正真实现的时候,官方放出来了c 和 e 的模型,都并不是论文中的3个head 9个输出,也在issue中被大家追问(手动狗头),下面是有人画出的c对应的网络图(原作者链接: Summary of YOLOv9 Architecture · Issue #355 · WongKinYiu/yolov9 · GitHub )。 
如何来看网络,其实主要参考三个文件:
1)模型配置文件: yolov9/models/detect/yolov9-c.yaml at main · WongKinYiu/yolov9 · GitHub
2)模型实现文件: yolov9/models/yolo.py at main · WongKinYiu/yolov9 · GitHub 这里作者也实现了不同的类对应不同的分支头数,但是目前开源的代码实现了TripleDetect类,但是没有使用。
3)loss文件: yolov9/utils/loss_tal_dual.py at main · WongKinYiu/yolov9 · GitHub 这里作者实现了三个loss:loss_tal.py、loss_tal_dual.py、oss_tal_triple.py
再围观看一下GELAN的代码
class RepNCSPELAN4(nn.Module):# csp-elandef __init__(self, c1, c2, c3, c4, c5=1): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()self.c = c3//2self.cv1 = Conv(c1, c3, 1, 1)self.cv2 = nn.Sequential(RepNCSP(c3//2, c4, c5), Conv(c4, c4, 3, 1))self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))self.cv4 = Conv(c3+(2*c4), c2, 1, 1)def forward(self, x):y = list(self.cv1(x).chunk(2, 1))y.extend((m(y[-1])) for m in [self.cv2, self.cv3])return self.cv4(torch.cat(y, 1))def forward_split(self, x):y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in [self.cv2, self.cv3])return self.cv4(torch.cat(y, 1))1、input
640*640,正常的预处理。
2、backbone
主要就是多了一条(或两条分支)backhone。
backbone使用了’RepNCSPELAN4 ‘模块。
3、neck & head
主要是增加了辅助头。
4、loss function
loss为DFL Loss + CIoU Loss,匹配策略为TaskAlign样本匹配,和YOLOv8、YOLOE、YOLOv6等算法保持一致。
5、trics
推理时可以去掉分支,见参考链接部分。
6、inference
测试阶段(非训练阶段)过程
四、结果
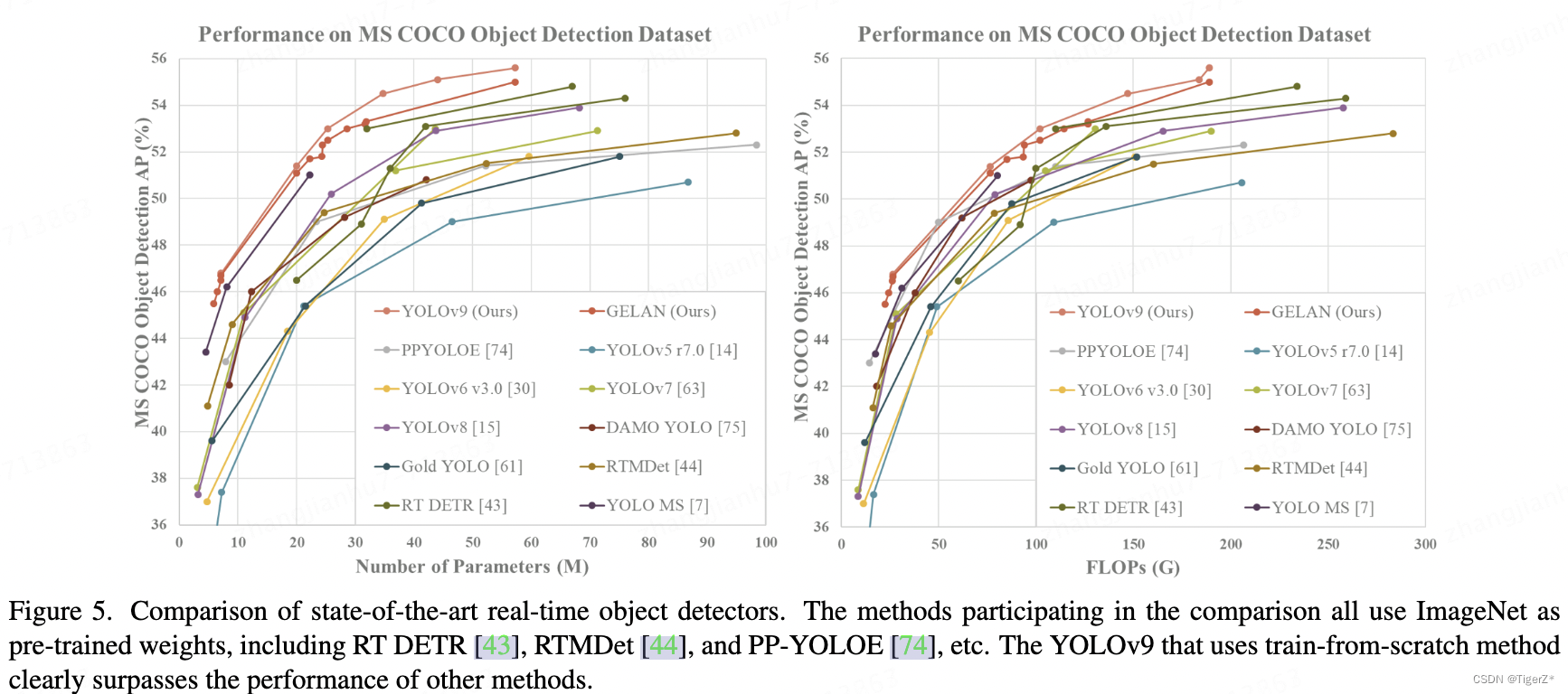
1、与sota比较
它比较好,也有网友做了性能和推理速度比较,目前看确实还是有优势的,所以后续持续关注。

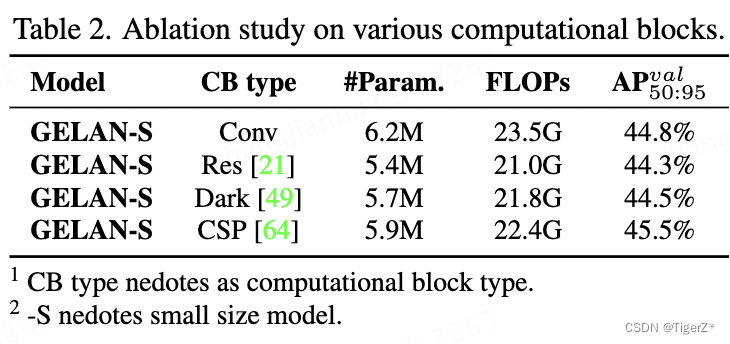
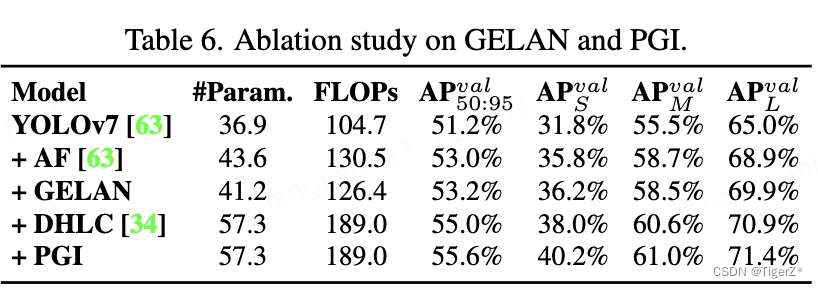
2、消融实验
GELAN

PGI
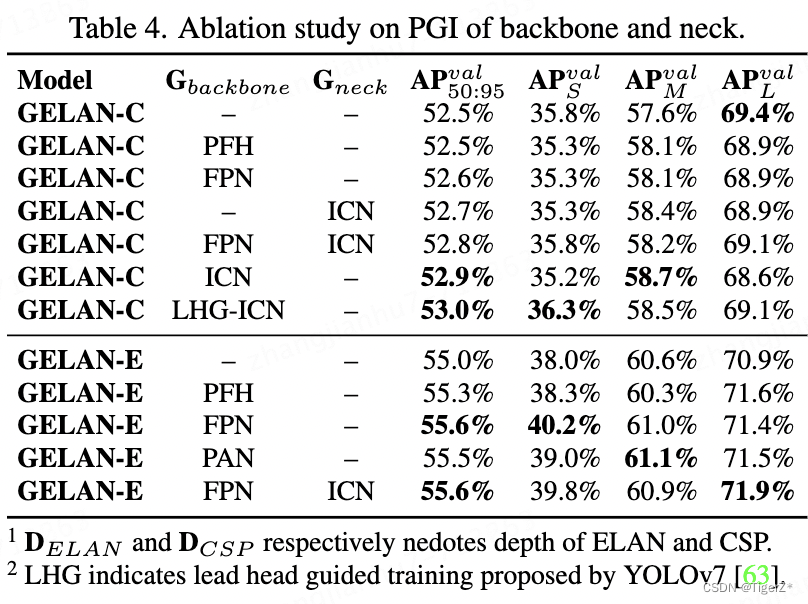

GELAN & PGI
可视化

参考链接
三个分支9个头的配置文件: How to use TripleDDetect? · Issue #226 · WongKinYiu/yolov9 · GitHub
结构图: Summary of YOLOv9 Architecture · Issue #355 · WongKinYiu/yolov9 · GitHub
推理速度对比: yolov5 yolov8 yolov9 speed test on T4 (tensorrt ) · Issue #178 · WongKinYiu/yolov9 · GitHub
训练速度对比: training speed is 3 times slower than yolov8 · Issue #173 · WongKinYiu/yolov9 · GitHub
去掉分支: GitHub - spacewalk01/TensorRT-YOLOv9: Cpp and python implementation of YOLOv9 using TensorRT API