- 概
- Motivation
- ZeRO
- ZeRO-Offload
- ZeRO-Infinite
- ZeRO++
- 代码
Rajbhandari S., Rasley J., Ruwase O. and He Y. ZeRO: Memory optimizations toward training trillion parameter models. InSC, 2020.
Ren J., Rajbhandari S., Aminabadi R. Y., Ruwase O., Yang S., Zhang M., Li D., He Y. ZeRO-Offload: Democratizing billion-scale model training. USENIX ATC, 2021.
Rajbhandari S., Ruwase O., Rasley J., Smith S. and He Y. ZeRO-Infinity: Breaking the gpu memory wall for extreme scale deep learning. InSC, 2021.
Wang G., Qin H., Jacobs S. A., Holmes C., Rajbhandari S., Ruwase O., Yan F., Yang L., He Y. ZeRO++: Extremely efficient collective communication for giant model training. ICLR, 2024.
概
整理一下 DeepSpeed 的 ZeRO 系列.
Motivation
- 虽然这些方法各有不同, 但是 motivation 都是尽可能降低训练模型的显存开销, 同时尽可能保持运算效率.
ZeRO
-
对于一个 1.5 B 的 GPT2, 采用 FP-16 的混合精度训练, 需要:
- 本身的 32-bit weights 需要 6 GB 的显存;
- 16-bit 的模型需要 3 GB 的显存;
- 16-bit 的梯度需要 3 GB 的显存;
- 32-bit 的 Adam 需要 12 GB 的显存.
-
故, 不考虑中间的激活值, 就需要 24 GB 的显存, 考虑到额外的激活值, 就需要更多.
-
ZeRO-1: 同时, 我们也注意到, 优化器 Adam 的状态缓存的消耗是非常惊人的, 所以 ZeRO-1 的策略是把 Adam 的优化器缓存均分到 GPUs 上.
-
ZeRO-2: 除了优化器的缓存, 把梯度也均分到 GPUs;
-
ZeRO-3: 则是进一步将模型参数也均分到 GPUs 上.
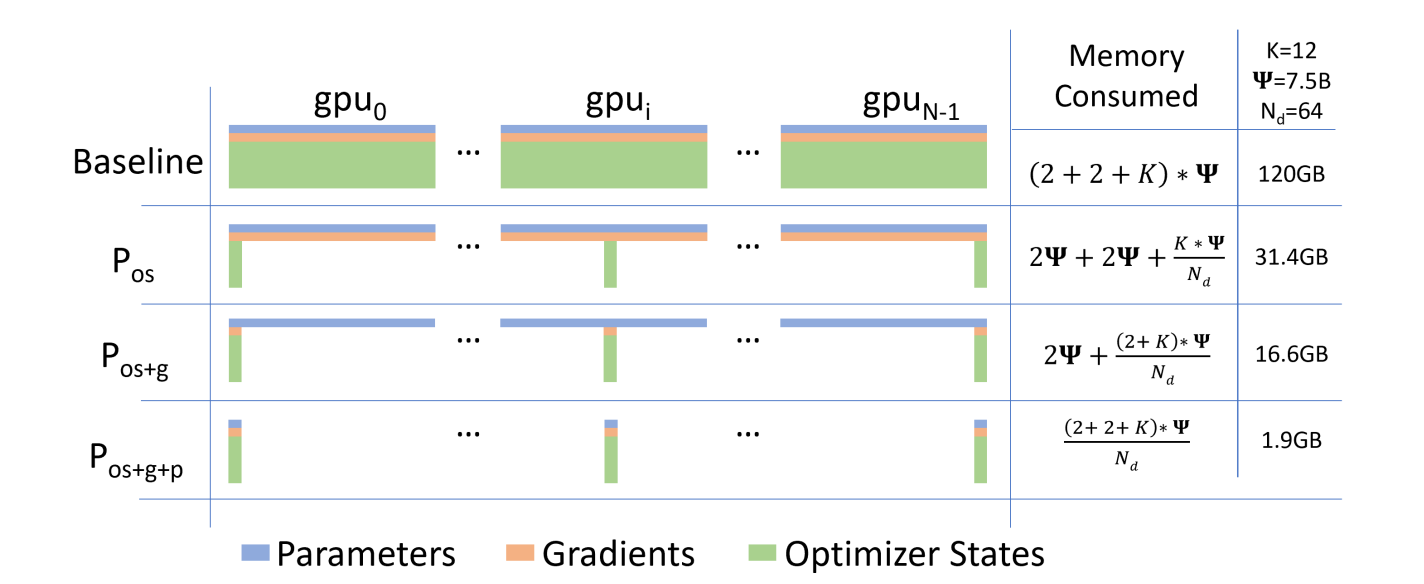
- 当然了, 上面的处理会带来不菲的 communication 的消耗.
ZeRO-Offload
-
ZeRO-1/2/3 的显存消耗降低非常依赖较多的 GPUs, 所以对于只有较少的 GPUs (比如 single GPU) 的情形效果就不是那么好了.
-
ZeRO-Offload 主要就是为了解决这个问题, 他主要是讲优化器的缓存 offload 到 CPU 中. 但是, CPU-GPU 的 communication 代价是不容忽视的, 所以和一般的 CPU-offload 不同的是, 模型的更新是在 CPU 中进行, 依赖一个优化过的 CPU-Adam 优化器:

-
此外, delayed parameter update 可以用来进一步降低 communication 代价: 它的核心是在 forward/backward 期间, 在 CPU 中更新一份模型参数, 然后新的梯度来后, 把新的模型参数复制到 GPU 中. 所以模型更新的时间可以被 overlap 掉. 不过, 容易发现, 这个时候, 其实我们不是实时更新模型, 还是延迟了一步.
-
为了降低延迟更新的影响, 作者会在一开始的 iterations 保持正常, 后续才延迟更新.

ZeRO-Infinite
-
ZeRO-Offload 沟通了 GPU, CPU (内存), ZeRO-Infinite 更进一步, 把 NVMe 也加了进来, 所以理论上可以训练任意大的模型.
-
显然, 此时的 communication 消耗就更大了 (多了 GPU-CPU-NVMe).
-
作者分析了论证了各个带宽的瓶颈所在, 并提出了一些分割手段.

ZeRO++
- 意识到之前方法所存在的 communication 消耗的问题, ZeRO++ 主要是通过一些量化方法, 在数据迁移前后进行量化和反量化, 以降低通信开销.
代码
[DeepSpeed]