GPT 浅析
文章目录
- GPT 浅析
- GPT 1
- 无监督预训练
- 有监督微调
- 任务相关的输入变换
- GPT2
- GPT3
GPT 1
在模型架构上,GPT-1基于Transformer构造,这是因为与其他卷积神经网 络或者循环神经网络相比,Transformer提供了效率更高的方法来处理文本 中的长期依赖关系。
预训练技术:GPT-1使用了一种称为“生成式预训练”(Generative Pre-Training,GPT)的技术。预训练分为两个阶段:预训练和微调(fine-tuning)。
在预训练阶段,GPT-1使用了大量的无标注文本数据集,例如维基百科和网页文本等。通过最大化预训练数据集上的对数极大似然概率来训练模型参数。在微调阶段,GPT-1将预训练模型的参数用于特定的自然语言处理任务,如文本分类和问答系统等。
多层模型:GPT-1模型由多个堆叠的Transformer编码器组成,每个编码器包含多个注意力头和前向神经网络。这使得模型可以从多个抽象层次对文本进行建模,从而更好地捕捉文本的语义信息。
无监督预训练
给定一个无监督的语料数据集 U = { u 1 , u 2 , . . . , u n } \mathbf{U}=\{\boldsymbol{u}_1,\boldsymbol{u}_2,...,\boldsymbol{u}_n\} U={u1,u2,...,un}, GPT-1使用标准的语言模型进行训练,也就是最大化如下似然估计:
L 1 ( U ) = ∑ i l o g P ( u i ∣ u i − k , . . . , u i − 1 ; θ ) L_1(\mathbf{U})=\sum_ilogP(\boldsymbol{u}_i|\boldsymbol{u}_{i-k},...,\boldsymbol{u}_{i-1};\boldsymbol{\theta}) L1(U)=i∑logP(ui∣ui−k,...,ui−1;θ)
其中, k k k 表示上下文窗口的大小,P表示条件概率, θ \theta θ是网络的参数,采用梯度下降法进行训练。
GPT-1使用一个多层Transformer解码器进行语言建模,该模型对输入上 下文使用多头自注意力机制,然后使用前馈神经网络预测目标单词的概 率分布,建模过程如下:
h 0 = U W e + W p h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) P ( U ) = s o f t m a x ( h n W e T ) \begin{aligned} \boldsymbol{h}_0&=\boldsymbol{UW}_e+\boldsymbol{W}_p\\ \boldsymbol{h}_l&=transformer\_block(\boldsymbol{h}_{l-1})\\ P(\boldsymbol{U})&=softmax(\boldsymbol{h}_n\boldsymbol{W}_e^T) \end{aligned} h0hlP(U)=UWe+Wp=transformer_block(hl−1)=softmax(hnWeT)
其中, W e W_e We是一个单词向量矩阵, W p W_p Wp是位置向量矩阵, U U U 表示输入文本的上下文向量, n n n是网络层数。
有监督微调
在使用上述方法进行预训练之后,GPT-1采用有监督微调方法将参数调整到更适合下游任务的状态
假设现在有某个有标记的样本集 C C C,其中每个样本由一系列的输入单词 { x 1 , x 2 , . . . , x m } \{x^1,x^2,...,x^m\} {x1,x2,...,xm}和一个标签 y y y组成,那么输入单词序列首先被送入在前一个阶段预训练好的模型中得到一个状态向量 h l m h_l^m hlm,接着被送入一个线性层进行结果预测:
P ( y ∣ x 1 , x 2 , . . . , x m ) = s o f t m a x ( h l m W y ) P(y|x^1,x^2,...,x^m)=softmax(h_l^mW_y) P(y∣x1,x2,...,xm)=softmax(hlmWy)
基于此,有监督微调阶段的目标函数就是:
L 2 ( C ) = ∑ ( x , y ) l o g P ( y ∣ x 1 , x 2 , . . . , x m ) L_2(\mathbf{C})=\sum_{(x,y)}logP(\mathbf{y}|\mathbf{x}^1,\mathbf{x}^2,...,\mathbf{x}^m) L2(C)=(x,y)∑logP(y∣x1,x2,...,xm)
与此同时,GPT-1的设计人员发现,在有监督微调阶段将语言模型作为微调的辅助目标能够进一步提升模型的泛化能力,并且可以加速收敛帮助学习。最终,在有监督微调阶段,模型的训练目标变为:
L 3 ( C ) = L 2 ( C ) + λ × L 1 ( C ) \begin{aligned}L_3(\mathbf{C})=L_2(\mathbf{C})+\lambda\times L_1(\mathbf{C})\end{aligned} L3(C)=L2(C)+λ×L1(C)
其中 λ \lambda λ是权重系数。
任务相关的输入变换
对于像文本分类一样的任务,可以按照上述有监督微调阶段所提到的方法进行微调,但是像问答、文本蕴含等自然语言理解任务,则需要在输 入阶段进行相应的设计和修改,才可以将GPT模型进行应用。
在微调阶段,所有任务的输入都增加了特殊的Token作为输入的开始 [start]和结束[extract]。
-
对于文本分类任务,将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布
-
对于文本蕴含任务,设计者将前提和假设进行拼接,然后在二者之间增 加了一个特殊标记“Delim” 。
-
对于文本相似度计算任务,由于被计算相似度的两个句子之间没有前后顺序关系,所以对同一对数据进行了不同顺序的拼接,最后使用线性化得到相似度得分。特别地,输入时两个句子之间增加了特殊标记 “Delim” ,用来区分前后两个句子。
-
对于多项选择的问答任务,将每个候选答案与问题和原文片段进行拼接, 得到相应的向量表示,最后使用Softmax函数在候选答案范围中进行结 果概率预测。

在模型实现细节上,GPT-1很大程度上遵循了原始的Transformer工作模式, 训练了一个具有掩码自注意力机制的12层仅包含解码器的Transformer。对 于前馈神经网络,使用了3072维的内部状态,使用最大学习率为2.5×10-4 的Adam优化方案。
GPT2
GPT-2提供了一种更为灵活和通用的形式来指定任务、输入和输出,避免了算法级别的任务定制。如在机器翻译任务中,模型的输入可以被设定为 “请翻译为法语、英语原文内容、对应法语内容”;在机器阅读理解任务 中,训练样本可以被写成“问题的答案、问题、原文、答案” 。
GPT-2的思想本质上就是早期的指令微调(Prompt Finetuning)方法,这种做法可以使得模型学习在遇到类似的提示语之后,应该输出什么样的内 容。
在模型实现上,GPT-2仍然使用Transformer作为主干模型,与GPT-1的整体架构类似,只进行了少量修改,包括层归一化被移到每个块的输入部分, 起到类似预激活的作用,在最终的自注意力块之后又增加了额外的层归一化,同时Transformer的Decoder层数从GPT-1的12层增加到了24层、36 层和48层。
GPT3
GPT-3的主要目标是使用更少的领域数据,且不经过微调去解决问题。它沿用GPT-2的模型和训练方法,将模型参数大小从GPT-2的15亿个升级到1750亿。
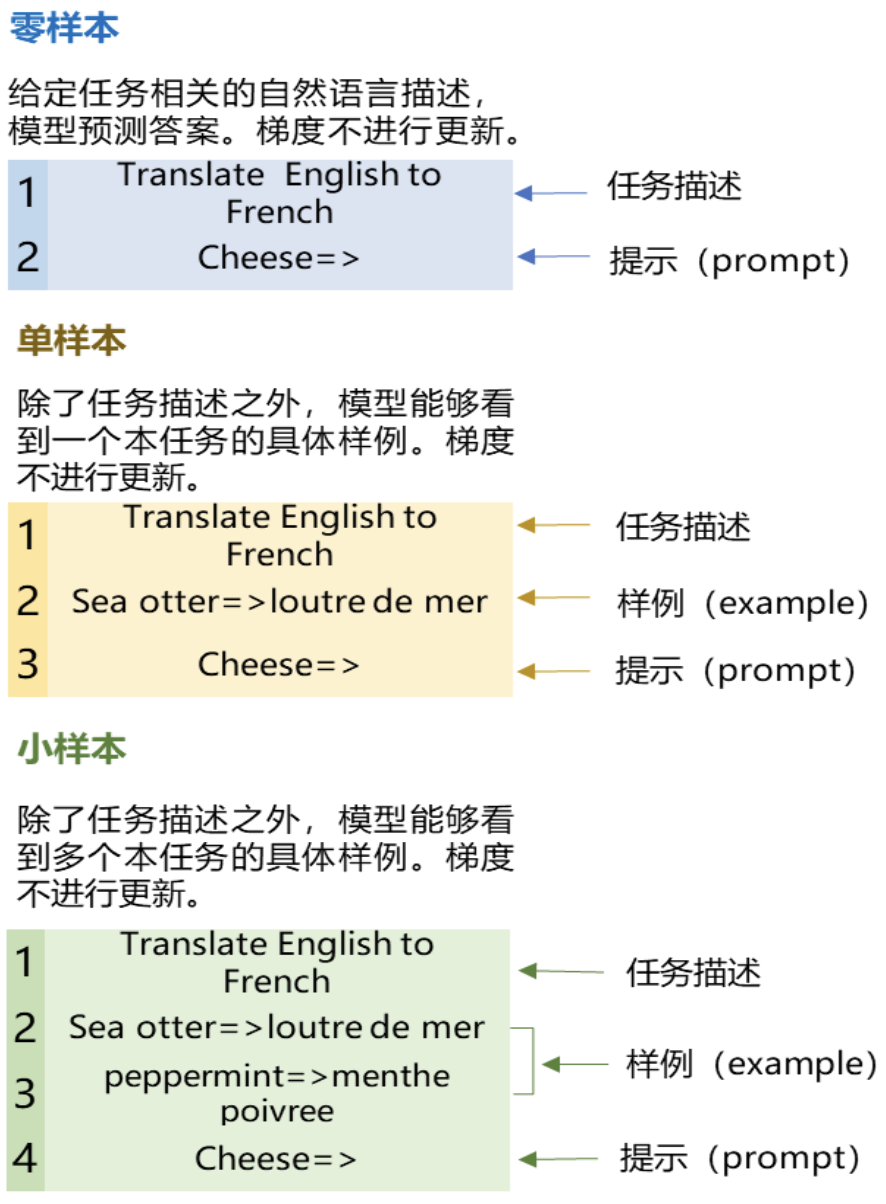
在几十个自然语言处理数据集上对GPT-3进行了评估,包括三种设置:
- 零样本学习(Zero-shot Learning):不允许展示具体的任务样本,只告知模型自然语言表示的指令;
- 单样本学习(One-shot Learning): 只允许向模型展示一个样本;
- 小样本学习(Few-shot Learning): 允许尽可能多的向模型展示样本(大概在10-100个之间)。
在开发GPT-3的过程中,研究人员发现,模型增大之后,引入一些质量较差的数据带来的负面影响变小了,因此与GPT-1和GPT-2相比,GPT-3开始使用Common Crawl数据集进行训练。