提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、pandas的数据结构
- 1、一维数组pd.Series
- 1.1 pd.Series(data,index,dtype)
- 示例1:不定义index
- 示例2:自定义index
- 示例3:通过字典创建
- 1.2 属性与方法
- 1.3 访问数据
- 1.4 数据操作(切片、过滤(布尔访问)、运算)
- 1.4.1 切片
- 1.4.2 过滤(布尔访问)
- 1.4.3 排序
- 1.4.4 重置索引 .reset_index()
- 1.4.5 缺失值处理
- 1.5 高级用法(.apply(func))---- 元素级操作
- 1.6 空series及其判断
前言
本文主要介绍pandas的一些基本用法。
一、pandas的数据结构
1、一维数组pd.Series
1.1 pd.Series(data,index,dtype)
pd.Series 的主要参数有以下几个:
-
data:Series 的数据,可以是列表、数组、字典等。如果是字典,字典的键将成为 Series 的索引,字典的值将成为 Series 的数据。
-
index:用于指定 Series 的索引,可以是列表、数组、索引对象(如
pd.Index对象)、标量或者 None。如果不提供索引,将默认使用从 0 开始的整数索引。 -
dtype:指定 Series 的数据类型。如果不指定,将根据数据类型推断。
下面是一些示例:
示例1:不定义index
# 通过列表创建 Series,不定义index会自动生成0....index
data = [1, 2, 3, 4, 5]
s = pd.Series(data)
print(s)
输出:

示例2:自定义index
data = [1, 2, 3, 4, 5]
# 自定义索引
index = ['a', 'b', 'c', 'd', 'e']
s = pd.Series(data, index=index)
print(s)
输出:

示例3:通过字典创建
# 通过字典创建 Series
data = {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
s = pd.Series(data)
print(s)
输出:

1.2 属性与方法
# 属性(部分)
print(s.dtype) # 数据的类型
print(s.ndim) # 一维数组维数,永远是1
print(s.shape) # Series 的形状
print(s.size) # 元素的总数
# 方法(部分)
print(s.mean()) # 平均值
print(s.max()) # 最大值
print(s.min()) # 最小值
print(s.unique()) # 唯一值
1.3 访问数据
# 访问数据
print('自定义index访问单个元素:',s['a']) # 访问单个元素,返回的类型就是里面数据类型
print('位置索引访问单个元素:',s[1]) # 也可以通过位置索引访问,,返回的类型就是里面数据类型
print('索引列表访问多个元素1:\n',s[['a', 'b', 'c']]) # 通过索引列表访问多个元素,返回的数据类型(包括一条数据)都是pd.Series
# 注意:s[['0', '1']是不行的,索引列表只支持具体的index,不支持位置index
输出:

【注】:需要注意的就是仅取一个数据时的数据类型是什么;以及索引列表是不支持位置index的,只支持具体的index
1.4 数据操作(切片、过滤(布尔访问)、运算)
1.4.1 切片
# 切片至少会有两个数据吧,所以类型一定是pd.Series
print(s[1:3])
print(type(s[1:3]))
输出:

1.4.2 过滤(布尔访问)
# 过滤,返回的类型一定是pd.Series
print('s>2',s[s > 2])
print('s==2',s[s == 2])
输出:

1.4.3 排序
| func | 功能 |
|---|---|
| .sort_values() | 按值排序 |
| .sort_index() | 按索引排序 |
# 创建一个示例 Series
s = pd.Series([3, 1, 2, 4, 5], index=['a', 'b', 'c', 'd', 'e'])# 按值对 Series 进行排序
print("按值排序:")
print(s.sort_values()) # 按值排序,默认从小到大# 按索引对 Series 进行排序
print("\n按索引排序:")
print(s.sort_index()) # 按索引排序
输出:

运行这段代码,你将看到每个操作的输出结果,以及它们之间的区别:
- 按值排序:Series 中的值按照升序排列,索引随之重新排列。
- 按索引排序:Series 中的索引按照字母顺序进行排列,对应的值随之重新排列。
【注】:返回的还是pd.Series
【注】:排序方法应该还有参数可以自定义排序规则(用里面参数),要用到时问一下ChatGPT。
1.4.4 重置索引 .reset_index()
比较常用,有时通过布尔过滤选择数据返回的数据index是乱的,我们调用这个方法,index就会重新编号成0,1,2…
【注】:与Dataframe里调用稍微有点不一样,Series该方法不支持原地修改(不能用inplace),另外二者都需要传入drop=True表明丢弃原来的索引,反之效果看下面代码给演示一下吧,不是很好叙述。
# 创建一个示例 Series
s = pd.Series([3, 1, 2, 4, 5])
s = s[s >= 3]print(s)
# 重新设置索引,并丢弃原始索引
s_reset = s.reset_index(drop=True)print(s_reset)
输出:返回的结果类型还是Series

【注】:如果不设置drop=True就会将原来索引保持下来,并当成Dataframe的一列保存下来,因此会返回一个Dataframe,像下面这样:

【注】:Dataframe里面也要 .reset_index(drop=True,inplace=True)
1.4.5 缺失值处理
| func | 功能 |
|---|---|
| .isnull() | 检测缺失值 |
| .fillna() | 填充缺失值 |
| .dropna() | 删除缺失值所在的行 |
| 具体更详细用法建议问ChatGPT |
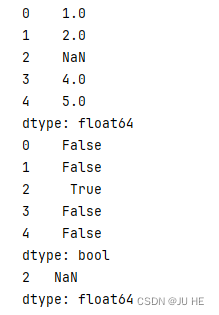
# 创建一个含有缺失值的 Series
s_with_nan = pd.Series([1, 2, None, 4, 5])
print(s_with_nan)# 检测缺失值,返回一个布尔series
print(s_with_nan.isnull())
# 结合布尔过滤就能返回缺失值的数据了
print(s_with_nan[s_with_nan.isnull()])print('-'*100)
# 填充缺失值
s_filled = s_with_nan.fillna(0)
print(s_filled)# 删除缺失值所在的行
s_dropped = s_with_nan.dropna()
print(s_dropped)
输出:

1.5 高级用法(.apply(func))---- 元素级操作
(.apply(func))---- 元素级操作:将指定函数应用于 Series 中的每个元素,并返回结果。
# 创建 Series
s = pd.Series([1, 2, 3, 4, 5])# 使用 apply 方法和 lambda 匿名函数,对每个元素进行平方操作
s_applied = s.apply(lambda x: x ** 2)
print(s_applied)
输出:

def f(x):return x**2
# 创建 Series
s = pd.Series([1, 2, 3, 4, 5])# 使用 apply 方法和 自定义的函数
s_applied = s.apply(f)
print(s_applied)