目录
1 疑问:Transformer的Decoder的输入输出都是什么
2 推理时Transformer的Decoder的输入输出
2.1 推理过程中的Decoder输入输出
2.2 整体右移一位
3 训练时Decoder的输入
参考文献:
1 疑问:Transformer的Decoder的输入输出都是什么
几乎所有介绍transformer的文章中都有下面这个图
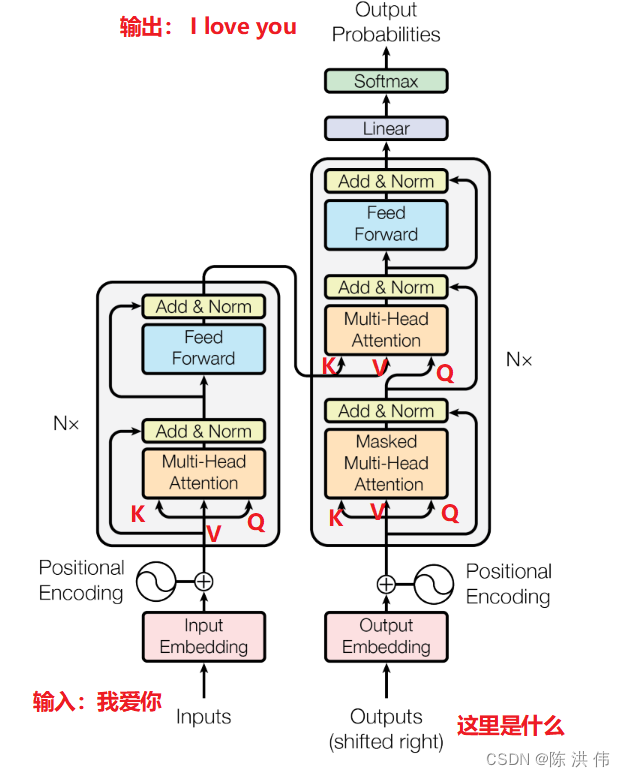
但是,右下角这里为什么把outputs给输入进去了,还有为什么有个shifted right,在网上看了下一些资料,简单整理一下,以后自己忘了就翻一下这篇博客笔记。
2 推理时Transformer的Decoder的输入输出
2.1 推理过程中的Decoder输入输出
假如是一个翻译过程,要将我爱你中国翻译成I love China.
- 输入:我爱中国
- 输出: I Love China
具体decoder的执行步骤是:
Time Step 1
-
- 初始输入: 起始符</s> + Positional Encoding(位置编码)
- 中间输入:(我爱中国)Encoder Embedding
- 最终输出:产生预测“I”
Time Step 2
-
- 初始输入:起始符</s> + “I”+ Positonal Encoding
- 中间输入:(我爱中国)Encoder Embedding
- 最终输出:产生预测“Love”
Time Step 3
-
- 初始输入:起始符</s> + “I”+ “Love”+ Positonal Encoding
- 中间输入:(我爱中国)Encoder Embedding
- 最终输出:产生预测“China”
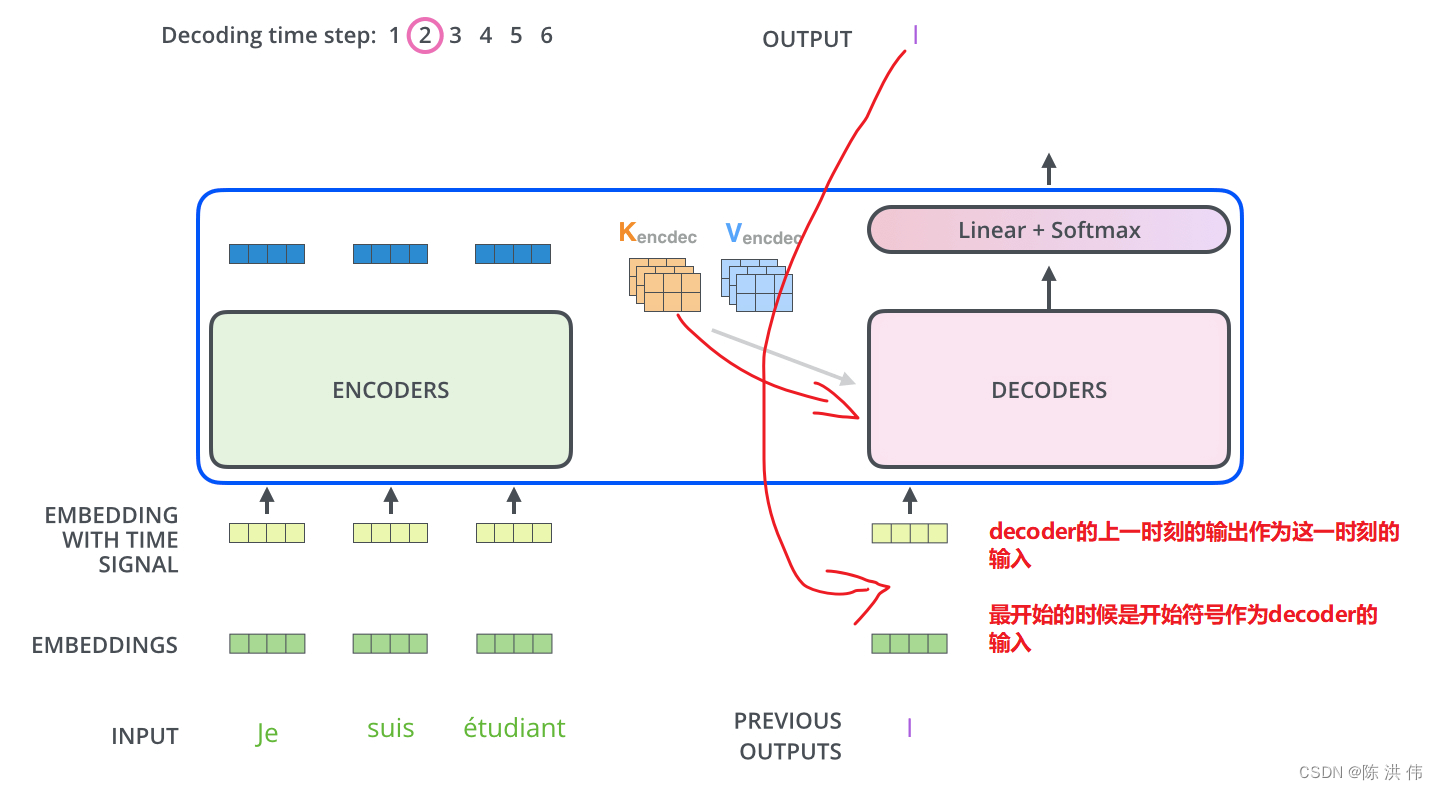
2.2 整体右移一位
在图片的右下角可以看到有个shitfed right,对Outputs有Shifted Right操作。
Shifted Right 实质上是给输出添加起始符/结束符,方便预测第一个Token/结束预测过程。
正常的输出序列位置关系如下:
- 0-"I"
- 1-"Love"
- 2-"China"
但在执行的过程中,我们在初始输出中添加了起始符</s>,相当于将输出整体右移一位(Shifted Right),所以输出序列变成如下情况:
- 0-</s>【起始符】
- 1-“I”
- 2-“Love”
- 3-“China”
这样我们就可以通过起始符</s>预测“I”,也就是通过起始符预测实际的第一个输出。
3 训练时Decoder的输入
训练时由于知道所有的输出,所以不需要等t-1个单词预测完了之后才去预测t个单词,训练时候是并行的,
训练时,decoder的并行计算是指 翻译第i+1个单词无需等待第i个单词的输出,因为训练时知道所有训练数输入数据的真实标签值,无需等待,可并行运算。
比如,翻译: 我有一只猫 ==> I have a cat
decoder input: Encoder input(我有一只猫) + start [---I have a cat /end--- masked]
output ==> I
decoder input: Encoder input(我有一只猫) + start I [---have a cat /end--- masked]
output ==> have
decoder input: Encoder input(我有一只猫) + start I have[---a cat /end--- masked]
output ==> a
decoder input: Encoder input(我有一只猫) + start I have a[---cat /end--- masked]
output ==> cat
decoder input: Encoder input(我有一只猫) + start I have a cat[---/end--- masked]
output ==> end
上述训练数据的decoder过程 可并行计算
参考文献:
哪位大神讲解一下Transformer的Decoder的输入输出都是什么?能解释一下每个部分都是什么? - 知乎
NLP Transformer的Decoder的输入输出都是什么?每个部分都是什么? NLP中的encoder和decoder的输入是什么?_transformer decoder的输入-CSDN博客
自然语言处理Transformer模型最详细讲解(图解版)-阿里云开发者社区
简单之美 | Transformer 模型架构详解
GPT中的Transformer架构以及Transformer 中的注意力机制-CSDN博客
The Illustrated Transformer【译】-CSDN博客
Transformer模型详解(图解最完整版) - 知乎