Huggingface与TurboMind介绍
Huggingface
HuggingFace是一个高速发展的社区,包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。可以认为是一个针对深度学习模型和数据集的在线托管社区,如果你有数据集或者模型想对外分享,网盘又不太方便,就不妨托管在HuggingFace。
托管在HuggingFace社区的模型通常采用HuggingFace格式存储,简写为HF格式。
但是HuggingFace社区的服务器在国外,国内访问不太方便。国内可以使用阿里巴巴的MindScope社区,或者上海AI Lab搭建的OpenXLab社区,上面托管的模型也通常采用HF格式。
TurboMind
TurboMind是LMDeploy团队开发的一款关于LLM推理的高效推理引擎,它的主要功能包括:LLaMa 结构模型的支持,continuous batch 推理模式和可扩展的 KV 缓存管理器。
TurboMind推理引擎仅支持推理TurboMind格式的模型。因此,TurboMind在推理HF格式的模型时,会首先自动将HF格式模型转换为TurboMind格式的模型。该过程在新版本的LMDeploy中是自动进行的,无需用户操作。
几个容易迷惑的点:
- TurboMind与LMDeploy的关系:LMDeploy是涵盖了LLM 任务全套轻量化、部署和服务解决方案的集成功能包,TurboMind是LMDeploy的一个推理引擎,是一个子模块。LMDeploy也可以使用pytorch作为推理引擎。
- TurboMind与TurboMind模型的关系:TurboMind是推理引擎的名字,TurboMind模型是一种模型存储格式,TurboMind引擎只能推理TurboMind格式的模型。
LMDeploy介绍
LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。 这个强大的工具箱提供以下核心功能:
- 高效的推理:LMDeploy 开发了 Persistent Batch(即 Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性。推理性能是 vLLM 的 1.8 倍
- 可靠的量化:LMDeploy 支持权重量化和 k/v 量化。4bit 模型推理效率是 FP16 下的 2.4 倍。量化模型的可靠性已通过 OpenCompass 评测得到充分验证。
- 便捷的服务:通过请求分发服务,LMDeploy 支持多模型在多机、多卡上的推理服务。
- 有状态推理:通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。
支持的模型
| Model | Size |
|---|---|
| Llama | 7B - 65B |
| Llama2 | 7B - 70B |
| InternLM | 7B - 20B |
| InternLM2 | 7B - 20B |
| InternLM-XComposer | 7B |
| QWen | 7B - 72B |
| QWen-VL | 7B |
| QWen1.5 | 0.5B - 72B |
| QWen1.5-MoE | A2.7B |
| Baichuan | 7B - 13B |
| Baichuan2 | 7B - 13B |
| Code Llama | 7B - 34B |
| ChatGLM2 | 6B |
| Falcon | 7B - 180B |
| YI | 6B - 34B |
| Mistral | 7B |
| DeepSeek-MoE | 16B |
| DeepSeek-VL | 7B |
| Mixtral | 8x7B |
| Gemma | 2B-7B |
| Dbrx | 132B |
LMDeploy 支持 2 种推理引擎: TurboMind 和 PyTorch,它们侧重不同。前者追求推理性能的极致优化,后者纯用python开发,着重降低开发者的门槛。
它们在支持的模型类别、计算精度方面有所差别。用户可参考这里, 查阅每个推理引擎的能力,并根据实际需求选择合适的。
实践部分
LMDeploy模型对话(chat)
InternStudio开发机创建conda环境
studio-conda -t lmdeploy -o pytorch-2.1.2激活环境
conda activate lmdeploy安装0.3.0版本的lmdeploy
pip install lmdeploy[all]==0.3.0下载模型
cd ~
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/运行模型
新建 pipeline_transformer.py
touch /root/pipeline_transformer.py 脚本内容:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("/root/internlm2-chat-1_8b", trust_remote_code=True)# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/internlm2-chat-1_8b", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()inp = "hello"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=[])
print("[OUTPUT]", response)inp = "please provide three suggestions about time management"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=history)
print("[OUTPUT]", response)运行脚本
python pipeline_transformer.py使用LMDeploy与模型对话
lmdeploy chat /root/internlm2-chat-1_8b对话结果

LMDeploy模型量化(lite)
计算密集与访存密集
- 计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速。
- 访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
常见的 LLM 模型由于 Decoder Only 架构的特性,实际推理时大多数的时间都消耗在了逐 Token 生成阶段(Decoding 阶段),是典型的访存密集型场景。
那么,如何优化 LLM 模型推理中的访存密集问题呢? 我们可以使用KV8量化和W4A16量化。KV8量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。W4A16 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
设置最大KV Cache缓存大小
KV Cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,KV Cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,KV Cache全部存储于显存,以加快访存速度。当显存空间不足时,也可以将KV Cache放在内存,通过缓存管理器控制将当前需要使用的数据放入显存。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置--cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。
保持不加该参数(默认0.8),运行1.8B模型
lmdeploy chat /root/internlm2-chat-1_8b显存使用(7816MB):
![]()
改变--cache-max-entry-count参数,设为0.5
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.5显存使用(6608MB):

把--cache-max-entry-count参数设置为0.01,约等于禁止KV Cache占用显存
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.01显存使用(4560MB):

使用W4A16量化
LMDeploy使用AWQ算法,实现模型4bit权重量化。推理引擎TurboMind提供了非常高效的4bit推理cuda kernel,性能是FP16的2.4倍以上。它支持以下NVIDIA显卡:
- 图灵架构(sm75):20系列、T4
- 安培架构(sm80,sm86):30系列、A10、A16、A30、A100
- Ada Lovelace架构(sm90):40 系列
安装依赖
pip install einops==0.7.0模型量化工作
lmdeploy lite auto_awq \/root/internlm2-chat-1_8b \--calib-dataset 'ptb' \--calib-samples 128 \--calib-seqlen 1024 \--w-bits 4 \--w-group-size 128 \--work-dir /root/internlm2-chat-1_8b-4bit开启模型对话
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq为了更加明显体会到W4A16的作用,我们将KV Cache比例再次调为0.01,查看显存占用情况。
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.01显存占用
![]()
对话结果

有关LMDeploy的lite功能的更多参数可通过-h命令查看。
lmdeploy lite -hLMDeploy服务(serve)
从架构上把整个服务流程分成下面几个模块。
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- API Server。中间协议层,把后端推理/服务通过HTTP,gRPC或其他形式的接口,供前端调用。
- Client。可以理解为前端,与用户交互的地方。通过通过网页端/命令行去调用API接口,获取模型推理/服务。
值得说明的是,以上的划分是一个相对完整的模型,但在实际中这并不是绝对的。比如可以把“模型推理”和“API Server”合并,有的甚至是三个流程打包在一起提供服务。
启动API服务器
lmdeploy serve api_server \/root/internlm2-chat-1_8b \--model-format hf \--quant-policy 0 \--server-name 0.0.0.0 \--server-port 23333 \--tp 1 \--cache-max-entry-count 0.4其中,model-format、quant-policy这些参数是与第三章中量化推理模型一致的;server-name和server-port表示API服务器的服务IP与服务端口;tp参数表示并行数量(GPU数量),cache-max-entry-count 代表我们将KV Cache比例设置为0.4
通过运行以上指令,我们成功启动了API服务器,请勿关闭该窗口,后面我们要新建客户端连接该服务。
可以通过运行一下指令,查看更多参数及使用方法:
lmdeploy serve api_server -h这一步由于Server在远程服务器上,所以本地需要做一下ssh转发才能直接访问。在你本地打开一个cmd窗口,输入命令如下:
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p <你的ssh端口号>命令行客户端连接API服务器
lmdeploy serve api_client http://localhost:23333网页客户端连接API服务器
lmdeploy serve gradio http://localhost:23333 \--server-name 0.0.0.0 \--server-port 6006Python代码集成
Python代码集成运行1.8B模型
新建Python源代码文件pipeline.py
touch /root/pipeline.py脚本内容
from lmdeploy import pipelinepipe = pipeline('/root/internlm2-chat-1_8b')
response = pipe(['Hi, pls intro yourself', '简单介绍一下上海'])
print(response) 执行
python /root/pipeline.py
向TurboMind后端传递参数
我们通过向lmdeploy传递附加参数,实现模型的量化推理,及设置KV Cache最大占用比例。在Python代码中,可以通过创建TurbomindEngineConfig,向lmdeploy传递参数。
原图:

以设置KV Cache占用比例为例,新建python文件pipeline_kv.py。
touch /root/pipeline_kv.py脚本内容
from lmdeploy import pipeline, TurbomindEngineConfig# 调低 k/v cache内存占比调整为总显存的 40%
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.4)pipe = pipeline('/root/internlm2-chat-1_8b',backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '简单介绍一下上海'])
print(response)运行
python /root/pipeline_kv.py
使用LMDeploy运行视觉多模态大模型llava
安装llava依赖库
pip install git+https://github.com/haotian-liu/LLaVA.git@4e2277a060da264c4f21b364c867cc622c945874新建一个python文件,比如pipeline_llava.py。
touch /root/pipeline_llava.py打开pipeline_llava.py,填入内容如下:
from lmdeploy import pipeline
from lmdeploy.vl import load_image# pipe = pipeline('liuhaotian/llava-v1.6-vicuna-7b') 非开发机运行此命令
pipe = pipeline('/share/new_models/liuhaotian/llava-v1.6-vicuna-7b')image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
response = pipe(('describe this image', image))
print(response)保存后运行pipeline。
python /root/pipeline_llava.py
通过Gradio来运行llava模型。新建python文件gradio_llava.py。
touch /root/gradio_llava.py打开文件,填入以下内容:
import gradio as gr
from lmdeploy import pipeline# pipe = pipeline('liuhaotian/llava-v1.6-vicuna-7b') 非开发机运行此命令
pipe = pipeline('/share/new_models/liuhaotian/llava-v1.6-vicuna-7b')def model(image, text):if image is None:return [(text, "请上传一张图片。")]else:response = pipe((text, image)).textreturn [(text, response)]demo = gr.Interface(fn=model, inputs=[gr.Image(type="pil"), gr.Textbox()], outputs=gr.Chatbot())
demo.launch()运行python程序。
python /root/gradio_llava.py通过ssh转发一下7860端口。
ssh -CNg -L 7860:127.0.0.1:7860 root@ssh.intern-ai.org.cn -p <你的ssh端口>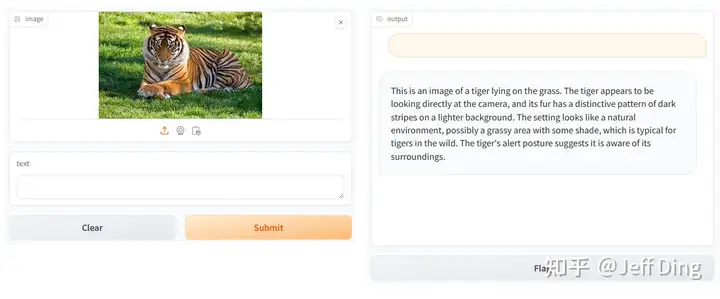
使用LMDeploy运行第三方大模型
LMDeploy不仅支持运行InternLM系列大模型,还支持其他第三方大模型。支持的模型列表如下:
| Model | Size |
|---|---|
| Llama | 7B - 65B |
| Llama2 | 7B - 70B |
| InternLM | 7B - 20B |
| InternLM2 | 7B - 20B |
| InternLM-XComposer | 7B |
| QWen | 7B - 72B |
| QWen-VL | 7B |
| QWen1.5 | 0.5B - 72B |
| QWen1.5-MoE | A2.7B |
| Baichuan | 7B - 13B |
| Baichuan2 | 7B - 13B |
| Code Llama | 7B - 34B |
| ChatGLM2 | 6B |
| Falcon | 7B - 180B |
| YI | 6B - 34B |
| Mistral | 7B |
| DeepSeek-MoE | 16B |
| DeepSeek-VL | 7B |
| Mixtral | 8x7B |
| Gemma | 2B-7B |
| Dbrx | 132B |
可以从Modelscope,OpenXLab下载相应的HF模型,下载好HF模型,下面的步骤就和使用LMDeploy运行InternLM2一样
定量比较LMDeploy与Transformer库的推理速度差异
先来测试一波Transformer库推理Internlm2-chat-1.8b的速度,新建python文件,命名为benchmark_transformer.py,填入以下内容:
import torch
import datetime
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("/root/internlm2-chat-1_8b", trust_remote_code=True)# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/internlm2-chat-1_8b", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()# warmup
inp = "hello"
for i in range(5):print("Warm up...[{}/5]".format(i+1))response, history = model.chat(tokenizer, inp, history=[])# test speed
inp = "请介绍一下你自己。"
times = 10
total_words = 0
start_time = datetime.datetime.now()
for i in range(times):response, history = model.chat(tokenizer, inp, history=history)total_words += len(response)
end_time = datetime.datetime.now()delta_time = end_time - start_time
delta_time = delta_time.seconds + delta_time.microseconds / 1000000.0
speed = total_words / delta_time
print("Speed: {:.3f} words/s".format(speed))运行python脚本:
python benchmark_transformer.py速度结果:
Speed: 77.712 words/s
下面来测试一下LMDeploy的推理速度,新建python文件benchmark_lmdeploy.py,填入以下内容:
import datetime
from lmdeploy import pipelinepipe = pipeline('/root/internlm2-chat-1_8b')# warmup
inp = "hello"
for i in range(5):print("Warm up...[{}/5]".format(i+1))response = pipe([inp])# test speed
inp = "请介绍一下你自己。"
times = 10
total_words = 0
start_time = datetime.datetime.now()
for i in range(times):response = pipe([inp])total_words += len(response[0].text)
end_time = datetime.datetime.now()delta_time = end_time - start_time
delta_time = delta_time.seconds + delta_time.microseconds / 1000000.0
speed = total_words / delta_time
print("Speed: {:.3f} words/s".format(speed))运行脚本:
python benchmark_lmdeploy.py速度结果:
Speed: 464.752 words/s