Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
(ALBEF)在融合之前对齐:利用动量蒸馏进行视觉与语言表示学习
Paper: arxiv.org/pdf/2107.07651.pdf
Github: https://github.com/salesforce/ALBEF
本篇 Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
- 首先是对ALBEF文章的细节精简理解
- 然后附上原文精读
文章目录
- 1.背景动机
- 2.Model
- 2.1.模型架构
- 2.2.预训练目标
- 2.3.动量蒸馏
- 3.不同下游任务
- 4.原文阅读
- Abstract
- 1 Introduction
- 2 Related Work
- 2.1 Vision-Language Representation Learning
- 2.2 Knowledge Distillation
- 3 ALBEF Pre-training
- 3.1 Model Architecture
- 3.2 Pre-training Objectives
- 3.3 Momentum Distillation
- 3.4 Pre-training Datasets
- 3.5 Implementation Details
- 4 A Mutual Information Maximization Perspective(互信息最大化视角)
- 5 Downstream V+L Tasks
- 6 Experiments
- 6.1 Evaluation on the Proposed Methods
- 6.2 Evaluation on Image-Text Retrieval
- 6.3 Evaluation on VQA, NLVR, and VE
- 6.4 Weakly-supervised Visual Grounding
- 6.5 Ablation Study
- 7 Conclusion and Social Impacts
- A Downstream Task Details
1.背景动机
现有VLP模型的方法:
视觉语言预训练(VLP)旨在从大规模图像-文本对中学习多模态表征,从而改进下游的视觉语言(V+L)任务。
现有的大多数 VLP 方法都依赖于预训练的对象检测器来提取基于区域的图像特征,并采用多模态编码器将图像特征与文本融合。
现在VLP模型存在的三个问题:(1.特征没有对齐就融合;2.需要对象检测器和高分辨率图像;3.噪声数据对模型训练有干扰)
- 图像特征和单词标记嵌入在各自的空间中,多模态编码器在学习它们之间的交互时并没有提前对齐;
- 对象检测器既需要注释,又需要计算,因为它在预训练时需要边界框注释,在推理时需要高分辨率(如 600×1000)的图像;
- 使用的图像-文本数据集是从网络收集的,有噪音的,并且现有的预训练目标(MLM)会过度拟合噪音文本,从而降低模型的泛化性能。
针对上述问题,提出的ALBEF模型方法:(先对齐后融合,即使用ITC对齐后在加入多模态编码器建模)
对于ALBEF:
- 使用无检测器图像编码器和文本编码器对图像和文本进行独立编码;
- 使用图像-文本对比损失(ITC loss)对图文特征进行对齐;
- 使用多模态编码器通过跨模态注意将图像特征与文本特征融合。
图像-文本对比损失的作用:
- 使图像特征和文本特征一致,使多模态编码器更容易进行跨模态学习;
- 改进单模态编码器,使其更好地理解图像和文本的语义;
- 学习一个共同的低维空间来嵌入图像和文本,这使得图像-文本匹配目标对比正负样本挖掘能够找到更多信息丰富的样本。
为了防止网络数据中噪声干扰,ABLEF提出了动量蒸馏法:
动量蒸馏法(MoD):为了改善在噪声监督下的学习效果,使模型能够利用更大规模的非筛选网络数据集。
在训练过程中,通过获取模型参数的移动平均值来保留模型的动量版本,并使用动量模型生成伪目标作为额外的监督。有了 MoD,模型不会因为产生与网络注释不同的其他合理输出而受到惩罚。
对ALBEF理论的解释:(互信息最大化角度)
从互信息最大化的角度,ITC 和 MLM 最大化了图像-文本对的不同视图之间的互信息下限,其中视图是通过从每个视图对中获取部分信息生成的。从这个角度来看,动量蒸馏可以解释为利用语义相似的样本生成新的视图。因此,ALBEF 可学习不受语义保留变换影响的视觉语言表征。
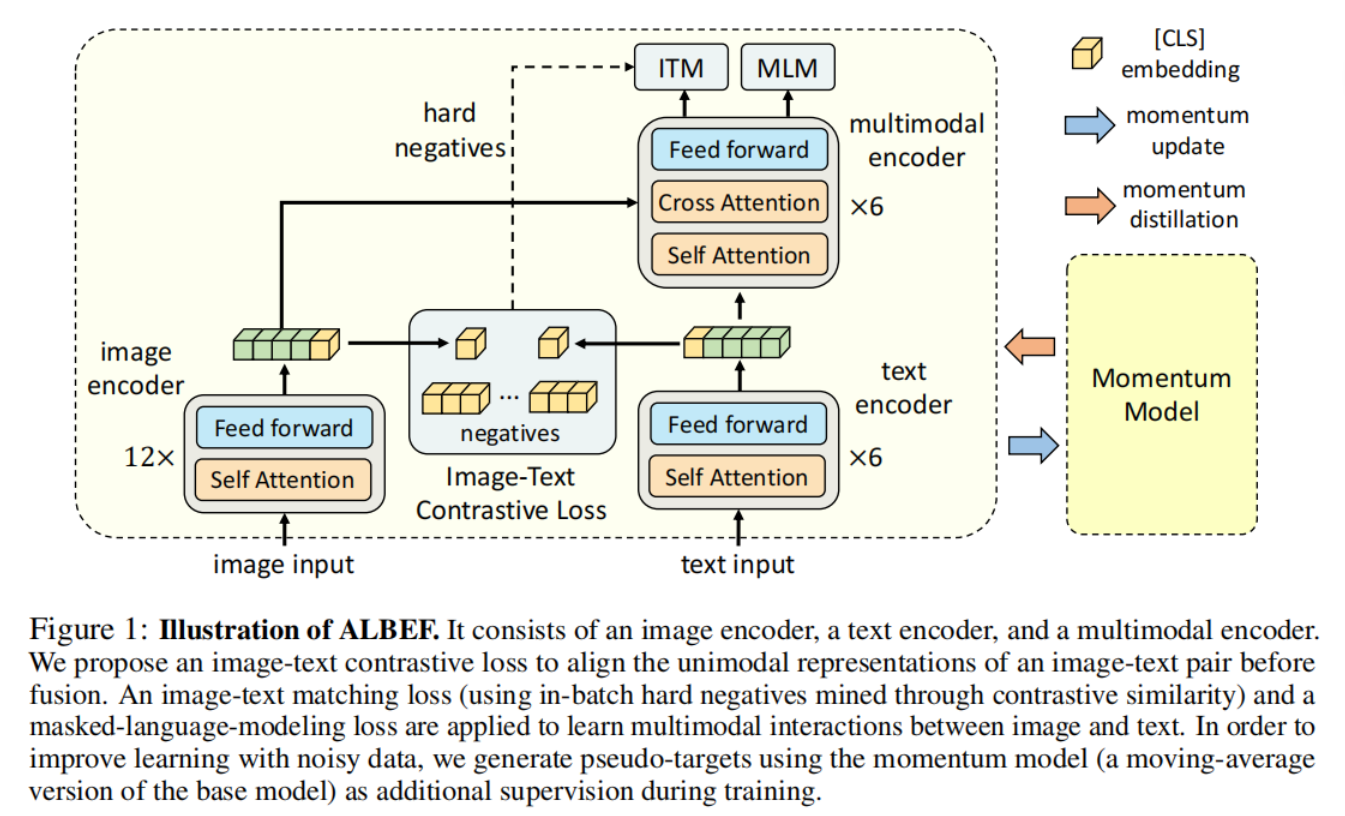
2.Model
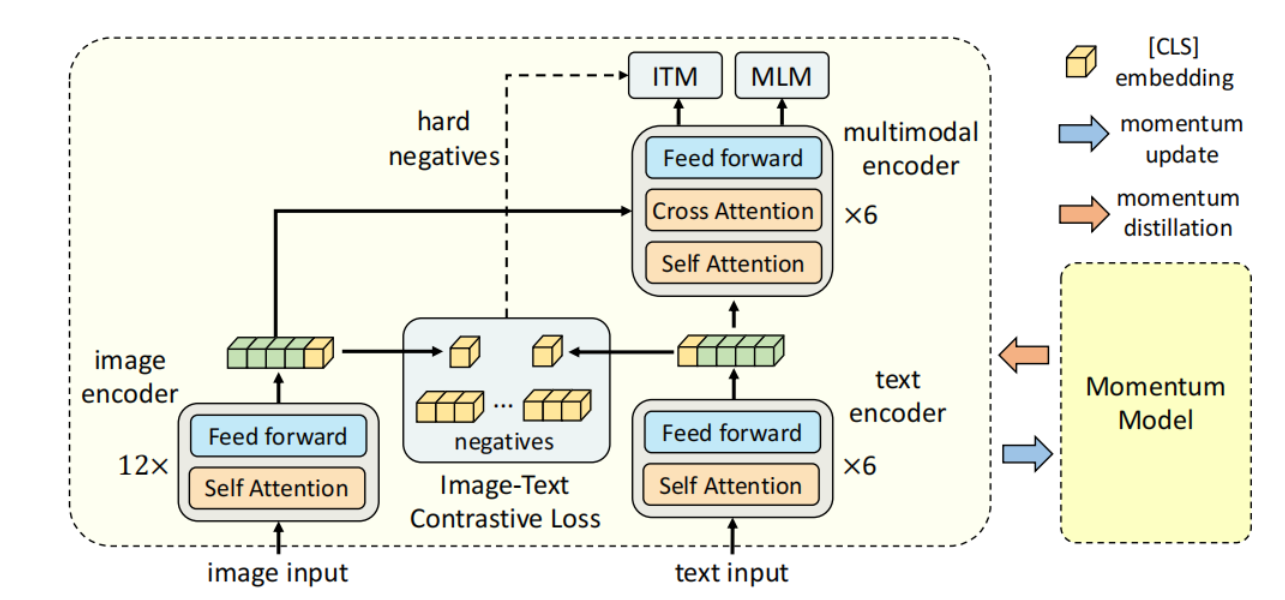
2.1.模型架构
ALBEF模型架构组成:
ALBEF 包含一个图像编码器、一个文本编码器和一个多模态编码器。
1.图像编码器:
使用12 层视觉变换器ViT-B/16作为图像编码器,并使用在ImageNet-1k上预先训练好的权重对其进行初始化。输入图像 I I I 被编码为一系列嵌入式数据: { v c l s , v 1 , . . . , v N } \{v_{cls}, v_1, ..., v_N\} {vcls,v1,...,vN},其中 v c l s v_{cls} vcls是 [CLS] 标记的嵌入。
2.文本编码器:
文本编码器使用 BERTbase模型的前 6 层进行初始化,。文本编码器将输入文本 T T T 转换为嵌入序列 { w c l s , w 1 , . . . , w N } \{w_{cls}, w_1, ..., w_N \} {wcls,w1,...,wN},并将其输入多模态编码器。
3.多模态编码器:
多模态编码器使用BERTbase 的后 6 层进行初始化,在多模态编码器的每一层,通过交叉关注将图像特征与文本特征融合
2.2.预训练目标
ALBEF使用三种预训练目标:
在单模态编码器上进行图像-文本对比学习(ITC),在多模态编码器上进行屏蔽语言建模(MLM)和图像-文本匹配(ITM)
1.图像-文本对比学习(ITC):
ITC目的是:在融合之前学习更好的单模态表征,即融合前先对齐。
它学习一个相似度函数 s = g v ( v c l s ) T g w ( w c l s ) s = g_v(v_{cls})^Tg_w(w_{cls}) s=gv(vcls)Tgw(wcls)。其中, g v g_v gv和 g w g_w gw是将[CLS]嵌入映射到归一化的低维(256维)表示的线性变换。
ALBEF采用MoCo的做法,即维护两个队列,用于存储来自动量单模态编码器的最近的M个图像-文本表示。动量编码器的归一化特征被表示为 g v ′ ( v c l s ′ ) g'_v(v'_{cls}) gv′(vcls′)和 g w ′ ( w c l s ′ ) g'_w(w'_{cls}) gw′(wcls′)。
将相似度分数定义为 s ( I , T ) = g v ( v c l s ) ⊤ g w ′ ( w c l s ′ ) s(I,T) = g_v(v_{cls})^\top g'_w(w'_{cls}) s(I,T)=gv(vcls)⊤gw′(wcls′) 和 s ( T , I ) = g w ( w c l s ) ⊤ g v ′ ( v c l s ′ ) s(T,I) = g_w(w_{cls})^\top g'_v(v'_{cls}) s(T,I)=gw(wcls)⊤gv′(vcls′)。
对于每幅图像和每段文字,计算图像到文字的 softmax 归一化相似度和文字到图像的 softmax 归一化相似度:
p m i 2 t ( I ) = exp ( s ( I , T m ) / τ ) ∑ m = 1 M exp ( s ( I , T m ) / τ ) p m t 2 i ( T ) = exp ( s ( T , I m ) / τ ) ∑ m = 1 M exp ( s ( T , I m ) / τ ) \begin{equation} \begin{split} p_m^\mathrm{i2t}(I) = \frac{\exp (s(I,T_m) / \tau)}{\sum_{m=1}^M \exp (s(I,T_m)/ \tau)} \\ p_m^\mathrm{t2i}(T) = \frac{\exp (s(T,I_m)/ \tau)}{\sum_{m=1}^M \exp (s(T,I_m)/ \tau)} \end{split} \end{equation} pmi2t(I)=∑m=1Mexp(s(I,Tm)/τ)exp(s(I,Tm)/τ)pmt2i(T)=∑m=1Mexp(s(T,Im)/τ)exp(s(T,Im)/τ)
其中, τ \tau τ是一个可学习的温度参数。让 y i 2 t ( I ) {y}^\mathrm{i2t}(I) yi2t(I) 和 y t 2 i ( T ) {y}^\mathrm{t2i}(T) yt2i(T) 表示真实one-hot相似度。图像-文本对比度损失定义为 p 和 y 之间的交叉熵 H:
L i t c = 1 2 E ( I , T ) ∼ D [ H ( y i 2 t ( I ) , p i 2 t ( I ) ) + H ( y t 2 i ( T ) , p t 2 i ( T ) ) ] \begin{equation} \begin{split} \mathcal{L}_\mathrm{itc} = \frac{1}{2} \mathbb{E}_{(I,T)\sim D} \big[ \mathrm{H}({y}^\mathrm{i2t}(I),{p}^\mathrm{i2t}(I)) + \mathrm{H}({y}^\mathrm{t2i}(T),{p}^\mathrm{t2i}(T)) \big] \end{split} \end{equation} Litc=21E(I,T)∼D[H(yi2t(I),pi2t(I))+H(yt2i(T),pt2i(T))]
2.MASK语言建模(MLM):
MLM目的是:利用图像和上下文文本来预测屏蔽词。
以 15% 的概率随机Mask掉输入标记,并用特殊标记 [MASK]取而代之。让 T ^ \hat{T} T^ 表示Mask文本, p msk ( I , T ^ ) {p}^\textrm{msk}(I,\hat{T}) pmsk(I,T^)表示模型对Mask标记的预测概率。MLM 将交叉熵损失最小化:
L m l m = E ( I , T ^ ) ∼ D H ( y msk , p msk ( I , T ^ ) ) \begin{equation} \mathcal{L}_\mathrm{mlm} = \mathbb{E}_{(I,\hat{T})\sim D} \mathrm{H} ({y}^\textrm{msk}, {p}^\textrm{msk}(I,\hat{T})) \end{equation} Lmlm=E(I,T^)∼DH(ymsk,pmsk(I,T^))
3.图像-文本匹配(ITM):
ITM目的是:预测一对图像和文本是正样本(匹配)还是负样本(不匹配)。
将多模态编码器对 [CLS] 标记的输出嵌入后面附加一个全连接(FC)层,然后使用 softmax 预测两类概率 p i t m p^\mathrm{itm} pitm。ITM 损失为
L i t m = E ( I , T ) ∼ D H ( y itm , p itm ( I , T ) ) \begin{equation} \mathcal{L}_\mathrm{itm} = \mathbb{E}_{(I,T)\sim D} \mathrm{H} ({y}^\textrm{itm},{p}^\textrm{itm}(I,T)) \end{equation} Litm=E(I,T)∼DH(yitm,pitm(I,T))
ALBEF对ITM设计的训练策略:对比硬负例挖掘:
硬负例:如果一个负面的图像-文本对在语义上相似但在细节上有所不同,那么它就是一个硬负例。
ALBEF使用等式1中的对比相似度来找到一个Batch内的硬负例。对于每个小Batch中的图像,从同一Batch的文本中采样一个负面文本,遵循对比相似度的分布,其中与图像更相似的文本被采样的概率更高。同样地,我们也为每个文本采样一个硬负例图像。具体的流程:
- 计算图像与文本的相似度:对于每个图像,计算其与批次中所有文本的相似度
- 采样负面文本:对于每个图像,根据与文本的相似度分布,从批次中的文本中采样一个负面文本。采样概率与相似度呈正相关,即与图像更相似的文本被选中的概率更高。(我理解的是,抛开batch中的唯一正例,其余负例中选择相似度最高或最高的有最大的概率作为硬负例)
- 计算文本与图像的相似度:对于每个文本,计算其与批次中所有图像的相似度。
- 采样负面图像:对于每个文本,根据与图像的相似度分布,从批次中的图像中采样一个负面图像。同样地,采样概率与相似度呈正相关,即与文本更相似的图像被选中的概率更高。
- ALBEF最终的训练损失:
ALBEF 的全部预训练目标是:
L = L i t c + L m l m + L i t m \begin{equation} \mathcal{L} = \mathcal{L}_\mathrm{itc} + \mathcal{L}_\mathrm{mlm} + \mathcal{L}_\mathrm{itm} \end{equation} L=Litc+Lmlm+Litm
2.3.动量蒸馏
网络中的噪声数据对预训练任务带来的影响:
用于预训练的图像-文本配对大多是从网络上收集的,它们往往是有噪声的。
正图文对是弱相关的:文本可能包含与图像无关的词语,或者图像可能包含文本中没有描述的实体。
对于ITC影响:图像的负文本也可能与图像内容相匹配。
对于MLM影响:可能存在与注释不同的其他词语,它们对图像的描述更好。
但是,ITC 和 MLM 的单点标签会对所有负面预测进行惩罚,无论其正确与否。
为了解决噪声问题,提出的动量蒸馏训练策略:
动量模型是一个持续演化的教师,由单模态和多模态编码器的指数移动平均版本组成。
在训练过程中,对基础模型进行训练,使其预测结果与动量模型的预测结果相匹配。具体来说:
对于 ITC:首先使用动量单模态编码器的特征计算图像-文本相似度,即 s ′ ( I , T ) = g v ′ ( v c l s ′ ) ⊤ g w ′ ( w c l s ′ ) s'(I,T) = g'_v({v}'_{cls})^\top g'_w({w}'_{cls}) s′(I,T)=gv′(vcls′)⊤gw′(wcls′)和 s ′ ( T , I ) = g w ′ ( w c l s ) ⊤ g v ′ ( v c l s ′ ) s'(T,I) = g'_w({w}_{cls})^\top g'_v({v}'_{cls}) s′(T,I)=gw′(wcls)⊤gv′(vcls′)。然后,用等式 1 中的 s ′ s' s′ 代替 s s s ,计算软伪目标 q i 2 t {q}^{i2t} qi2t和 q t 2 i {q}^{t2i} qt2i。ITC M o D _\mathrm{MoD} MoD 损失定义如下
L i t c m o d = ( 1 − α ) L i t c + α 2 E ( I , T ) ∼ D [ K L ( q i 2 t ( I ) ∥ p i 2 t ( I ) ) + K L ( q t 2 i ( T ) ∥ p t 2 i ( T ) ) ] \begin{equation} \mathcal{L}_\mathrm{itc}^\mathrm{mod} = (1-\alpha) \mathcal{L}_\mathrm{itc} + \frac{\alpha }{2} \mathbb{E}_{(I,T)\sim D} \big[ \mathrm{KL}({q}^\mathrm{i2t}(I) \parallel {p}^\mathrm{i2t}(I)) + \mathrm{KL}({q}^\mathrm{t2i}(T)\parallel {p}^\mathrm{t2i}(T))\big] \end{equation} Litcmod=(1−α)Litc+2αE(I,T)∼D[KL(qi2t(I)∥pi2t(I))+KL(qt2i(T)∥pt2i(T))]
对于 MLM:让 q m s k ( I , T ^ ) {q}^{msk}(I,\hat{T}) qmsk(I,T^)表示动量模型对mask标记的预测概率,MLM M o D _\mathrm{MoD} MoD 损失为
L m l m m o d = ( 1 − α ) L m l m + α E ( I , T ^ ) ∼ D K L ( q msk ( I , T ^ ) ∥ p msk ( I , T ^ ) ) \begin{equation} \mathcal{L}_\mathrm{mlm}^\mathrm{mod} = (1-\alpha) \mathcal{L}_\mathrm{mlm} + \alpha \mathbb{E}_{(I,\hat{T})\sim D} \mathrm{KL} ({q}^\textrm{msk}(I,\hat{T})\parallel {p}^\textrm{msk}(I,\hat{T})) \end{equation} Lmlmmod=(1−α)Lmlm+αE(I,T^)∼DKL(qmsk(I,T^)∥pmsk(I,T^))
在图中,上面一行是 ITC 的前5名伪目标,下面一行是 MLM 的前5名伪目标。可以看到对于有的图,伪目标能概括出 GT 里面没有描述出来的物体。比如左下角的图,GT 说的是 “路上的车抛锚了”,但是 top-5 的伪标签不仅能够描述这个意思,还额外地描述了 “年轻女士” 这一信息。

动量蒸馏总结:
动量模型其实就是另一套参数的 ALBEF(教师模型)。个人理解:
- 先训练出一版ALBEF,然后将其平均版本作为动量模型(或不用训练出来,训练一部分就开始加入动量模型)
- 用动量模型输出的伪目标作为额外的监督标准,即在原始损失的基础上加入模型预测与伪目标之间的 KL-发散的加权组合。
- 动态的更新动量模型的参数权重
3.不同下游任务
ALBEF应用于不同的下游任务:
图像-文本检索:(Image-Text Retrieval)
图像-文本检索:图像-文本检索(TR)和文本-图像检索(IR)。
在微调过程中,ALBEF联合优化了 ITC 损失(公式 2)和 ITM 损失(公式 4)。ITC 基于单模态特征的相似性学习图像-文本评分函数,而 ITM 则对图像和文本之间的细粒度交互进行建模,以预测匹配得分。由于下游数据集包含每张图像的多个文本,ALBEF改变了 ITC 的真实标签,以考虑队列中的多个正例,其中每个正例的真实概率为 1/# 正例。
在推理过程中,ALBEF首先计算所有图像-文本对的特征相似度得分 sitc。然后,选取前k个候选者,计算其 ITM 分数 sitm 以进行排序。
视觉蕴含任务(Visual Entailment, SNLI-VE)
视觉蕴含(SNLI-VE5):用于预测图像和文本之间的关系是蕴含、中性还是矛盾。
ALBEF效仿 UNITER,将 VE视为一个三向分类问题,并在多模态编码器的[CLS]标记输出结果上使用多层感知器(MLP)预测类别概率。
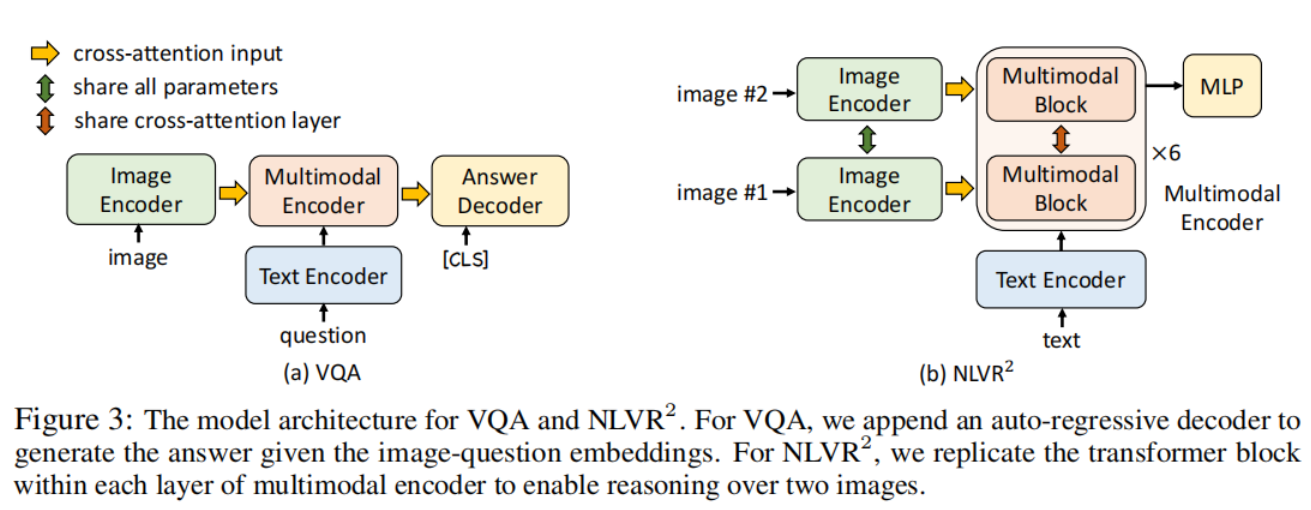
视觉问答任务 (Visual Question Answering, VQA)
视觉问题解答(VQA):要求模型在给出图像和问题的情况下预测答案。
ALBEF将 VQA 视为答案生成问题,具体来说:
使用 6 层transformer解码器来生成答案。如图 3a 所示,自动回归答案解码器通过交叉注意接收多模态嵌入,并将序列起始标记([CLS])作为解码器的初始输入标记。同样,解码器输出的末尾会添加一个序列结束标记([SEP]),表示生成完成。答案解码器使用来自多模态编码器的预训练权重进行初始化,并使用条件语言建模损失进行微调。ALBEF限制解码器在推理过程中只能从 3192 个候选答案中生成答案。
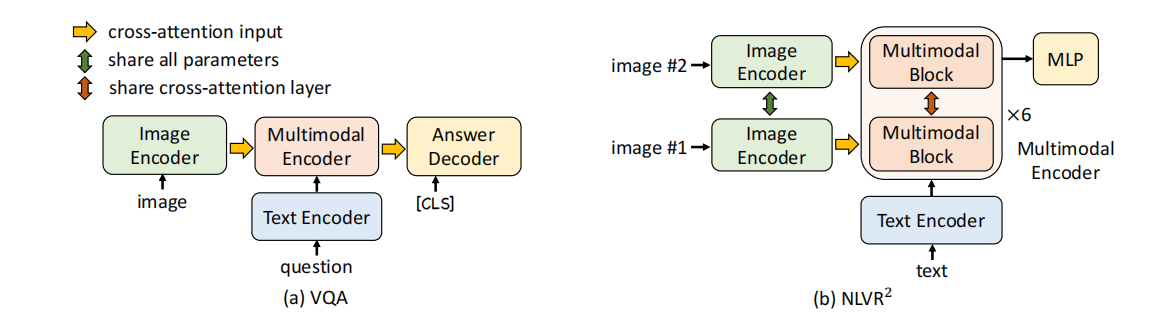
自然语言视觉推理任务 (Natural Language for Visual Reasoning, NLVR)
自然语言视觉推理(NLVR):预测文本是否描述了一对图像。
如图 3b 所示,多模态编码器的每一层都复制了两个连续的transformer块,其中每个块都包含一个自注意层、一个交叉注意层和一个前馈层。每一层中的两个区块使用相同的预训练权重进行初始化,两个交叉注意层共享相同的键和值线性投影权重。在训练过程中,这两个块接收两组图像对的图像嵌入。在多模态编码器的 [CLS] 表示上附加一个 MLP 分类器进行预测。
对于 NLVR,ALBEF执行了一个额外的预训练步骤:
ALBEF设计的文本分配(TA)任务如下:给定一对图像和一段文本,模型需要将文本分配给第一幅图像、第二幅图像或任何一幅图像。 ALBEF将其视为一个三向分类问题,并使用 [CLS] 表示上的 FC 层来预测分配。
视觉定位 (Visual Grounding)
视觉定位:旨在定位图像中与特定文字描述相对应的区域。
4.原文阅读
Abstract
现有的VLP存在的问题:(视觉与文本之前没有对齐就进行融合,即联合建模)
在各种视觉语言任务中,大规模视觉和语言表征学习都取得了可喜的进步。现有的大多数方法都采用基于transformer的多模态编码器,对视觉token(基于区域的图像特征)和文字token进行联合建模。由于视觉token和单词token是不对齐的,因此多模态编码器学习图像与文本之间的交互具有挑战性。
提出的ALBEF的优势:(在融合前,先对视觉与文本进行对齐)
在本文中,我们引入了一种对比损失,即通过跨模态注意力将图像和文本表征在融合前对齐(ALBEF),从而实现更扎实的视觉和语言表征学习。
与大多数现有方法不同,我们的方法既不需要边界框注释,也不需要高分辨率图像。为了提高从嘈杂网络数据中学习的效率,我们提出了动量蒸馏法,这是一种自我训练方法,可从动量模型生成的伪目标中学习。
Note: 动量蒸馏法解决的问题:降低网络采集的的图-文对中噪声所带来的影响
我们从互信息最大化的角度对 ALBEF 进行了理论分析,表明不同的训练任务可以解释为生成图像-文本对视图的不同方法。ALBEF 在多个下游视觉语言任务中都取得了一流的性能。在图像-文本检索方面,ALBEF 的表现优于在数量级更大的数据集上预训练过的方法。在 VQA 和 NLVR2 上,ALBEF 与最先进的方法相比,绝对性能分别提高了 2.37% 和 3.84%,同时推理速度更快。代码和模型见 https://github.com/salesforce/ALBEF。
1 Introduction
现有VLP构建的方式:(依赖于预训练的对象检测器来提取基于区域的图像特征)
视觉语言预训练(VLP)旨在从大规模图像-文本对中学习多模态表征,从而改进下游的视觉语言(V+L)任务。现有的大多数 VLP 方法(如 LXMERT、UNITER、OSCAR)都依赖于预训练的对象检测器来提取基于区域的图像特征,并采用多模态编码器将图像特征与单词标记融合在一起。训练多模态编码器是为了解决需要联合理解图像和文本的任务,如遮蔽语言建模(MLM)和图像文本匹配(ITM)。
现在VLP模型存在的三个问题:(1.特征没有对齐就融合;2.需要对象检测器和高分辨率图像;3.噪声数据对模型训练有干扰)
这个VLP框架虽然有效,但存在几个关键限制:
(1) 图像特征和单词标记嵌入在各自的空间中,这使得多模态编码器在学习模拟它们之间的交互时面临挑战;
(2) 对象检测器既需要注释,又需要计算,因为它在预训练时需要边界框注释,在推理时需要高分辨率(如 600×1000)的图像;
(3) 广泛使用的图像-文本数据集是从网络收集而来的,本质上是有噪音的,并且现有的预训练目标(如MLM)可能会过度拟合噪音文本,从而降低模型的泛化性能。
提出的ALBEF模型方式:(先对齐后融合,即使用ITC融合后在加入多模态编码器建模)
我们提出了ALign BEfore Fuse (ALBEF),一个新的 VLP 框架来解决这些局限性。我们首先使用无检测器图像编码器和文本编码器对图像和文本进行独立编码,然后使用多模态编码器通过跨模态注意将图像特征与文本特征融合在一起。我们在单模态编码器的表示上引入了一种中间的图像-文本对比损失(ITC loss),它具有三个作用:
(1)使图像特征和文本特征一致,从而使多模态编码器更容易进行跨模态学习;
(2)改进单模态编码器,使其更好地理解图像和文本的语义;
(3)学习一个共同的低维空间来嵌入图像和文本,这使得图像-文本匹配目标通过我们的对比正负样本挖掘能够找到更多信息丰富的样本。
ALBEF中的动态蒸馏法的解释:(生成伪目标作为额外监督,从而避免噪声的干预)
为了改善在噪声监督下的学习效果,我们提出了动量蒸馏法(MoD),这是一种简单的方法,使模型能够利用更大规模的非筛选网络数据集。在训练过程中,我们通过获取模型参数的移动平均值来保留模型的动量版本,并使用动量模型生成伪目标作为额外的监督。有了 MoD,模型不会因为产生与网络注释不同的其他合理输出而受到惩罚。我们的研究表明,MoD 不仅能改善预训练,还能改善下游任务中的干净注释。
对ALBEF理论的解释:(互信息最大化角度)
我们从互信息最大化的角度为 ALBEF 提供了理论依据。具体来说,我们表明,ITC 和 MLM 最大化了图像-文本对的不同视图之间的互信息下限,其中视图是通过从每个视图对中获取部分信息生成的。从这个角度来看,我们的动量蒸馏可以解释为利用语义相似的样本生成新的视图。因此,ALBEF 可学习不受语义保留变换影响的视觉语言表征。
ALBEF的性能优势:
我们展示了 ALBEF 在各种下游 V+L 任务中的有效性,包括图像-文本检索、视觉问题解答、视觉推理、视觉引申和弱监督视觉定位。与现有的先进方法相比,ALBEF 实现了大幅改进。在图像文本检索方面,ALBEF 优于在数量级更大的数据集上预先训练过的方法(CLIP和 ALIGN)。在 VQA 和 NLVR2 上,与最先进的方法 VILLA相比,它的绝对值分别提高了2.37% 和 3.84%,同时推理速度也快得多。我们还使用 Grad-CAM对 ALBEF 进行了定量和定性分析,结果表明 ALBEF 能够隐式地对对象、属性和关系进行准确的定位。
2 Related Work
2.1 Vision-Language Representation Learning
现有的视觉语言表征学习工作大多分为两类。
第一类VLP模型的方法:(直接使用多模态编码器执行图文交互)
第一类侧重于利用基于transformer的多模态编码器来模拟图像和文本特征之间的交互。这类方法在需要对图像和文本进行复杂推理的下游 V+L 任务中表现出色(如 NLVR2、VQA),但它们大多需要高分辨率输入图像和预训练的对象检测器。最近的一种方法通过移除对象检测器提高了推理速度,但性能较低。
第二类VLP模型的方法:(使用单模态编码器分别对图文进行编码)
第二类侧重于学习图像和文本的独立单模态编码器。最近的 CLIP和 ALIGN使用对比损失(表征学习中最有效的损失之一)对海量高噪声网络数据进行预训练。它们在图像-文本检索任务中取得了不俗的成绩,但在其他 V+L 任务中,它们缺乏为图像和文本之间更复杂的交互建模的能力。
ALBEF模型的方法:
ALBEF 将这两类方法统一起来,形成了强大的单模态和多模态表征,在检索和推理任务中均表现出色。此外,ALBEF 不需要对象检测器,而对象检测器是许多现有方法的主要计算瓶颈。
2.2 Knowledge Distillation
知识蒸馏法旨在通过从教师模型中提炼知识来提高学生模型的性能,通常是通过将学生的预测与教师的预测进行匹配。大多数方法侧重于从预先训练好的教师模型中提炼知识,而在线提炼则是同时训练多个模型,并将其集合作为教师模型。我们的动力蒸馏可以解释为一种在线自我蒸馏,即使用学生模型的时间集合作为教师。半监督学习、标签噪声学习以及最近的对比学习中也有类似的想法。 与现有研究不同,我们从理论和实验上证明,动量蒸馏是一种通用的学习算法,可以提高模型在许多 V+L 任务中的性能。
3 ALBEF Pre-training
在本节中,我们首先介绍了模型架构(第3.1节)。然后我们描述了预训练目标(第3.2节),接着是提出的动量蒸馏方法(第3.3节)。最后,我们描述了预训练数据集(第3.4节)和实现细节(第3.5节)。
3.1 Model Architecture
ALBEF模型架构组成:
如图 1 所示,ALBEF 包含一个图像编码器、一个文本编码器和一个多模态编码器。
我们使用12 层视觉变换器ViT-B/16作为图像编码器,并使用在ImageNet-1k上预先训练好的权重对其进行初始化。输入图像 I I I 被编码为一系列嵌入式数据: { v c l s , v 1 , . . . , v N } \{v_{cls}, v_1, ..., v_N\} {vcls,v1,...,vN},其中 v c l s v_{cls} vcls是 [CLS] 标记的嵌入。我们在文本编码器和多模态编码器中都使用了 6 层transformer。
文本编码器使用 BERTbase模型的前 6 层进行初始化,多模态编码器使用BERTbase 的后 6 层进行初始化。文本编码器将输入文本 T T T 转换为嵌入序列 { w c l s , w 1 , . . . , w N } \{w_{cls}, w_1, ..., w_N \} {wcls,w1,...,wN},并将其输入多模态编码器。在多模态编码器的每一层,通过交叉关注将图像特征与文本特征融合。
3.2 Pre-training Objectives
我们通过三个目标对ALBEF进行预训练:在单模态编码器上进行图像-文本对比学习(ITC),在多模态编码器上进行屏蔽语言建模(MLM)和图像-文本匹配(ITM)。我们通过在线对比正负挖掘改进了 ITM。
图像-文本对比学习(ITC)
图像-文本对比学习的目的是:在融合之前学习更好的单模态表征,即融合前先对齐。
它学习了一个相似度函数 s = g v ( v c l s ) T g w ( w c l s ) s = g_v(v_{cls})^Tg_w(w_{cls}) s=gv(vcls)Tgw(wcls),使得平行的图像-文本对具有更高的相似度分数。其中, g v g_v gv和 g w g_w gw是将[CLS]嵌入映射到归一化的低维(256维)表示的线性变换。受MoCo的启发,我们维护两个队列,用于存储来自动量单模态编码器的最近的M个图像-文本表示。动量编码器的归一化特征被表示为 g v ′ ( v c l s ′ ) g'_v(v'_{cls}) gv′(vcls′)和 g w ′ ( w c l s ′ ) g'_w(w'_{cls}) gw′(wcls′)。我们将相似度分数定义为 s ( I , T ) = g v ( v c l s ) ⊤ g w ′ ( w c l s ′ ) s(I,T) = g_v(v_{cls})^\top g'_w(w'_{cls}) s(I,T)=gv(vcls)⊤gw′(wcls′) 和 s ( T , I ) = g w ( w c l s ) ⊤ g v ′ ( v c l s ′ ) s(T,I) = g_w(w_{cls})^\top g'_v(v'_{cls}) s(T,I)=gw(wcls)⊤gv′(vcls′)。这种方法有助于跨模态对齐和匹配特征,促进更好的多模态学习。
对于每幅图像和每段文字,我们计算图像到文字的 softmax 归一化相似度和文字到图像的 softmax 归一化相似度:
p m i 2 t ( I ) = exp ( s ( I , T m ) / τ ) ∑ m = 1 M exp ( s ( I , T m ) / τ ) p m t 2 i ( T ) = exp ( s ( T , I m ) / τ ) ∑ m = 1 M exp ( s ( T , I m ) / τ ) \begin{equation} \begin{split} p_m^\mathrm{i2t}(I) = \frac{\exp (s(I,T_m) / \tau)}{\sum_{m=1}^M \exp (s(I,T_m)/ \tau)} \\ p_m^\mathrm{t2i}(T) = \frac{\exp (s(T,I_m)/ \tau)}{\sum_{m=1}^M \exp (s(T,I_m)/ \tau)} \end{split} \end{equation} pmi2t(I)=∑m=1Mexp(s(I,Tm)/τ)exp(s(I,Tm)/τ)pmt2i(T)=∑m=1Mexp(s(T,Im)/τ)exp(s(T,Im)/τ)
其中, τ \tau τ是一个可学习的温度参数。让 y i 2 t ( I ) {y}^\mathrm{i2t}(I) yi2t(I) 和 y t 2 i ( T ) {y}^\mathrm{t2i}(T) yt2i(T) 表示真实one-hot相似度,其中负值对的概率为 0,正值对的概率为 1。图像-文本对比度损失定义为 p 和 y 之间的交叉熵 H:
L i t c = 1 2 E ( I , T ) ∼ D [ H ( y i 2 t ( I ) , p i 2 t ( I ) ) + H ( y t 2 i ( T ) , p t 2 i ( T ) ) ] \begin{equation} \begin{split} \mathcal{L}_\mathrm{itc} = \frac{1}{2} \mathbb{E}_{(I,T)\sim D} \big[ \mathrm{H}({y}^\mathrm{i2t}(I),{p}^\mathrm{i2t}(I)) + \mathrm{H}({y}^\mathrm{t2i}(T),{p}^\mathrm{t2i}(T)) \big] \end{split} \end{equation} Litc=21E(I,T)∼D[H(yi2t(I),pi2t(I))+H(yt2i(T),pt2i(T))]
Mask语言任务 (MLM):
Mask语言建模利用图像和上下文文本来预测屏蔽词。我们以 15% 的概率随机Mask掉输入标记,并用特殊标记 [MASK]取而代之。让 T ^ \hat{T} T^ 表示Mask文本, p msk ( I , T ^ ) {p}^\textrm{msk}(I,\hat{T}) pmsk(I,T^)表示模型对Mask标记的预测概率。MLM 将交叉熵损失最小化:
L m l m = E ( I , T ^ ) ∼ D H ( y msk , p msk ( I , T ^ ) ) \begin{equation} \mathcal{L}_\mathrm{mlm} = \mathbb{E}_{(I,\hat{T})\sim D} \mathrm{H} ({y}^\textrm{msk}, {p}^\textrm{msk}(I,\hat{T})) \end{equation} Lmlm=E(I,T^)∼DH(ymsk,pmsk(I,T^))
其中, y msk {y}^\textrm{msk} ymsk 是one-hot词汇分布,真实标记的概率为 1。
图文匹配损失:(Image-Text Matching)
图像-文本匹配预测的是一对图像和文本是正样本(匹配)还是负样本(不匹配)。我们使用多模态编码器对 [CLS] 标记的输出嵌入作为图像-文本对的联合表示,并附加一个全连接(FC)层,然后使用 softmax 预测两类概率 p i t m p^\mathrm{itm} pitm。ITM 损失为
L i t m = E ( I , T ) ∼ D H ( y itm , p itm ( I , T ) ) \begin{equation} \mathcal{L}_\mathrm{itm} = \mathbb{E}_{(I,T)\sim D} \mathrm{H} ({y}^\textrm{itm},{p}^\textrm{itm}(I,T)) \end{equation} Litm=E(I,T)∼DH(yitm,pitm(I,T))
其中, y i t m {y}^{itm} yitm 是代表真实标签的二维one-hot向量。
ITM 采用对比硬负面挖掘:
我们提出了一种策略,用零计算开销来采样信息检索任务(ITM)中的硬负例。如果一个负面的图像-文本对在语义上相似但在细节上有所不同,那么它就是一个硬负例。我们使用等式1中的对比相似度来找到一个Batch内的硬负例。对于每个小Batch中的图像,我们从同一Batch的文本中采样一个负面文本,遵循对比相似度的分布,其中与图像更相似的文本被采样的概率更高。同样地,我们也为每个文本采样一个硬负例图像。采样的流程:
- 计算图像与文本的相似度:对于每个图像,计算其与批次中所有文本的相似度
- 采样负面文本:对于每个图像,根据与文本的相似度分布,从批次中的文本中采样一个负面文本。采样概率与相似度呈正相关,即与图像更相似的文本被选中的概率更高。(我理解的是,抛开batch中的唯一正例,其余负例中选择相似度最高或最高的有最大的概率作为硬负例)
- 计算文本与图像的相似度:对于每个文本,计算其与批次中所有图像的相似度。
- 采样负面图像:对于每个文本,根据与图像的相似度分布,从批次中的图像中采样一个负面图像。同样地,采样概率与相似度呈正相关,即与文本更相似的图像被选中的概率更高。
ALBEF 的全部预训练目标是:
L = L i t c + L m l m + L i t m \begin{equation} \mathcal{L} = \mathcal{L}_\mathrm{itc} + \mathcal{L}_\mathrm{mlm} + \mathcal{L}_\mathrm{itm} \end{equation} L=Litc+Lmlm+Litm
3.3 Momentum Distillation
网络噪声数据对预训练任务带来的影响:
用于预训练的图像-文本配对大多是从网络上收集的,它们往往是有噪声的。正文本对通常是弱相关的:文本可能包含与图像无关的词语,或者图像可能包含文本中没有描述的实体。对于 ITC 学习来说,图像的负文本也可能与图像内容相匹配。对于 MLM 来说,可能存在与注释不同的其他词语,它们对图像的描述同样出色(或更好)。但是,ITC 和 MLM 的单点标签会对所有负面预测进行惩罚,无论其正确与否。
提出的动量蒸馏解决噪声问题:
为了解决这个问题,我们提出通过动量模型生成的伪目标进行学习。动量模型是一个持续演化的教师,由单模态和多模态编码器的指数移动平均版本组成。在训练过程中,我们对基础模型进行训练,使其预测结果与动量模型的预测结果相匹配。具体来说,对于 ITC,我们首先使用动量单模态编码器的特征计算图像-文本相似度,即 s ′ ( I , T ) = g v ′ ( v c l s ′ ) ⊤ g w ′ ( w c l s ′ ) s'(I,T) = g'_v({v}'_{cls})^\top g'_w({w}'_{cls}) s′(I,T)=gv′(vcls′)⊤gw′(wcls′)和 s ′ ( T , I ) = g w ′ ( w c l s ) ⊤ g v ′ ( v c l s ′ ) s'(T,I) = g'_w({w}_{cls})^\top g'_v({v}'_{cls}) s′(T,I)=gw′(wcls)⊤gv′(vcls′)。然后,我们用等式 1 中的 s ′ s' s′ 代替 s s s ,计算软伪目标 q i 2 t {q}^{i2t} qi2t和 q t 2 i {q}^{t2i} qt2i。ITC M o D _\mathrm{MoD} MoD 损失定义如下
L i t c m o d = ( 1 − α ) L i t c + α 2 E ( I , T ) ∼ D [ K L ( q i 2 t ( I ) ∥ p i 2 t ( I ) ) + K L ( q t 2 i ( T ) ∥ p t 2 i ( T ) ) ] \begin{equation} \mathcal{L}_\mathrm{itc}^\mathrm{mod} = (1-\alpha) \mathcal{L}_\mathrm{itc} + \frac{\alpha }{2} \mathbb{E}_{(I,T)\sim D} \big[ \mathrm{KL}({q}^\mathrm{i2t}(I) \parallel {p}^\mathrm{i2t}(I)) + \mathrm{KL}({q}^\mathrm{t2i}(T)\parallel {p}^\mathrm{t2i}(T))\big] \end{equation} Litcmod=(1−α)Litc+2αE(I,T)∼D[KL(qi2t(I)∥pi2t(I))+KL(qt2i(T)∥pt2i(T))]
同样,对于 MLM,让 q m s k ( I , T ^ ) {q}^{msk}(I,\hat{T}) qmsk(I,T^)表示动量模型对mask标记的预测概率,MLM M o D _\mathrm{MoD} MoD 损失为
L m l m m o d = ( 1 − α ) L m l m + α E ( I , T ^ ) ∼ D K L ( q msk ( I , T ^ ) ∥ p msk ( I , T ^ ) ) \begin{equation} \mathcal{L}_\mathrm{mlm}^\mathrm{mod} = (1-\alpha) \mathcal{L}_\mathrm{mlm} + \alpha \mathbb{E}_{(I,\hat{T})\sim D} \mathrm{KL} ({q}^\textrm{msk}(I,\hat{T})\parallel {p}^\textrm{msk}(I,\hat{T})) \end{equation} Lmlmmod=(1−α)Lmlm+αE(I,T^)∼DKL(qmsk(I,T^)∥pmsk(I,T^))
在图 2 中,我们展示了从伪目标中选出的前 5 个候选词的例子,这些候选词有效地捕捉到了图像的相关词语/文本。
图2中,上面一行是 ITC 的前5名伪目标,下面一行是 MLM 的前5名伪目标。可以看到对于有的图,伪目标甚至比 GT 概括得还像样,甚至是能概括出 GT 里面没有描述出来的物体。比如左下角的图,GT 说的是 “路上的车抛锚了”,但是 top-5 的伪标签不仅能够描述这个意思,还额外地描述了 “年轻女士” 这一信息。这说明一个问题,就是使用这些伪标签训练模型是很管用的。
我们还将 MoD 应用于下游任务。每个任务的最终损失是原始任务损失和模型预测与伪目标之间的 KL-发散的加权组合。 为简单起见,我们将所有预训练和下游任务的权重 α 设置为 0.4。

3.4 Pre-training Datasets
按照UNITER,我们使用两个网络数据集(Conceptual Caption、SBU Captions)和两个域内数据集(COCO和 Visual Genome)构建了预训练数据。 唯一图像的总数为 4.0M,图像-文本对的数量为 5.1M。为了证明我们的方法可以扩展到更大规模的网络数据,我们还加入了噪声更大的 Conceptual 12M 数据集,将图像总数增加到 1410 万。
3.5 Implementation Details
-
模型容量:我们的模型包括一个拥有 123.7M 参数的 BERTbase 和一个拥有 85.8M 参数的 ViT-B/16。
-
GPU/batch/epoch:我们在8个英伟达 A100 GPU 上使用512batch size对模型进行了30 个epoch的预训练。
-
优化器/LR: 我们使用权重衰减为0.02的 AdamW优化器。在前1000次迭代中,学习率预热至1e -4,然后按照余弦计划衰减至 1e -5。
-
预训练图像设置:在预训练期间,我们将分辨率为 256 × 256 的随机图像作物作为输入,并应用 RandAugment。
-
微调图像设置:在微调过程中,我们将图像分辨率提高到384 × 384,并按照文献对图像片段的位置编码进行插值。更新动量模型的动量参数设置为0.995,用于图像-文本对比学习的队列大小设置为65536。
-
蒸馏权重:我们在第一个 epoch内将蒸馏权重 α 从 0 线性提升到 0.4。
4 A Mutual Information Maximization Perspective(互信息最大化视角)
在本节中,我们将提供 ALBEF 的另一种视角,并证明它能最大化图像-文本对的不同 "视图 "之间的互信息(MI)下限。ITC、MLM 和 MoD 可以解释为生成视图的不同方法。
形式上,我们将两个随机变量 a 和 b 定义为一个数据点的两个不同视图。在自我监督学习中,a 和 b 是同一图像的两个增强变量。在视觉语言表征学习中,我们将 a 和 b 视为图像-文本对的不同变化,以捕捉其语义。我们的目标是学习不受视图变化影响的表征。这可以通过最大化 a 和 b 之间的 MI 来实现。在实践中,我们通过最小化 InfoNCE 损失来最大化 MI(a, b)的下限:
L N C E = − E p ( a , b ) [ log exp ( s ( a , b ) ) ∑ b ^ ∈ B ^ exp ( s ( a , b ^ ) ) ] \begin{equation} \mathcal{L}\mathrm{NCE} = -\mathbb{E}{p(a,b)}\left[ \log \frac{\exp (s(a,b))}{ \sum_{\hat{b}\in\hat{B}} \exp (s(a,\hat{b})) } \right] \end{equation} LNCE=−Ep(a,b)[log∑b^∈B^exp(s(a,b^))exp(s(a,b))]
其中,s(a,b) 是一个评分函数(例如,两个representations之间的点积),而 B ^ \hat{B} B^包含从建议分布中抽取的正样本b 和 ∣ B ^ ∣ − 1 \lvert \hat{B} \rvert-1 ∣B^∣−1 负样本。
我们的one-hot标签 ITC 损失(等式 2)可改写为
L i t c = − 1 2 E p ( I , T ) [ log exp ( s ( I , T ) / τ ) ∑ m = 1 M exp ( s ( I , T m ) / τ ) + log exp ( s ( T , I ) / τ ) ∑ m = 1 M exp ( s ( T , I m ) / τ ) ] \begin{equation} \mathcal{L}\mathrm{itc} = -\frac{1}{2} \mathbb{E}{p(I,T)} \big[\log \frac{\exp (s(I,T) / \tau)}{\sum{m=1}^M \exp (s(I,T_m)/ \tau)} + \log \frac{\exp (s(T,I) / \tau)}{\sum{m=1}^M \exp (s(T,I_m)/ \tau)}\big] \end{equation} Litc=−21Ep(I,T)[log∑m=1Mexp(s(I,Tm)/τ)exp(s(I,T)/τ)+log∑m=1Mexp(s(T,Im)/τ)exp(s(T,I)/τ)]
最小化\mathcal{L}_\mathrm{itc}可以看作是最大化 InfoNCE 的对称版本。因此,ITC 将两个单独的模态(即 I 和 T)视为图像-文本对的两个视图,并训练单模态编码器以最大化正对图像和文本视图之间的 MI。
如文献所示,我们也可以将 MLM 解释为最大化屏蔽词标记与其屏蔽上下文(即图像 + 屏蔽文本)之间的 MI。具体来说,我们可以将单热标签的 MLM 损失(等式 3)改写为
L m l m = − E p ( I , T ^ ) [ log exp ( ψ ( y ( m s k ) ) ⊤ f ( I , T ^ ) ) ∑ y ∈ V exp ( ψ ( y ) ⊤ f ( I , T ^ ) ) ] \begin{equation} \mathcal{L}\mathrm{mlm} = - \mathbb{E}{p(I,\hat{T})} \big[\log \frac{\exp (\psi(y (\mathrm{msk}))\top f(I,\hat{T}))} { \sum_{y \in \mathcal{V}} \exp (\psi(y)^\top f(I,\hat{T}))} \big] \end{equation} Lmlm=−Ep(I,T^)[log∑y∈Vexp(ψ(y)⊤f(I,T^))exp(ψ(y(msk))⊤f(I,T^))]
其中, ψ ( y ) : V → R d \psi(y): \mathcal{V} \rightarrow \mathbb{R}^d ψ(y):V→Rd是多模态编码器输出层中的一个查找函数,用于将单词标记 y 映射到一个向量中,V 是完整的词汇集, f ( I , T ^ ) f(I,\hat{T}) f(I,T^) 是一个函数,用于返回多模态编码器中与屏蔽上下文相对应的最终隐藏状态。因此,MLM 将图像-文本对的两个视图视为:(1) 随机选择的单词标记;(2) 屏蔽了该单词的图像 + 上下文文本。
ITC 和 MLM 都是通过模态分离或单词mask,从图像-文本对中获取部分信息来生成视图的。我们的动量蒸馏可视为从整个提案分布中生成备选视图。以等式 6 中的 I T C M o D ITC_\mathrm{MoD} ITCMoD为例,最小化 K L ( p i 2 t ( I ) , q i 2 t ( I ) ) \mathrm{KL}({p}^\mathrm{i2t}(I),{q}^\mathrm{i2t}(I)) KL(pi2t(I),qi2t(I))等同于最小化以下目标:
− ∑ m q m i 2 t ( I ) log p m i 2 t ( I ) = − ∑ m exp ( s ′ ( I , T m ) / τ ) ∑ m = 1 M exp ( s ′ ( I , T m ) / τ ) log exp ( s ( I , T m ) / τ ) ∑ m = 1 M exp ( s ( I , T m ) / τ ) \begin{equation} -\sum_m {q}m^\mathrm{i2t}(I) \log {p}m^\mathrm{i2t}(I) = -\sum_m \frac{\exp (s'(I,T_m) / \tau)}{\sum{m=1}^M \exp (s'(I,T_m)/ \tau)} \log \frac{\exp (s(I,T_m) / \tau)}{\sum{m=1}^M \exp (s(I,T_m)/ \tau)} \end{equation} −m∑qmi2t(I)logpmi2t(I)=−m∑∑m=1Mexp(s′(I,Tm)/τ)exp(s′(I,Tm)/τ)log∑m=1Mexp(s(I,Tm)/τ)exp(s(I,Tm)/τ)
对于与图像 I 有相似语义的文本,它能最大化 ( I , T m ) (I,T_m) (I,Tm),因为这些文本的 q m i 2 t ( I ) {q}_m^\mathrm{i2t}(I) qmi2t(I)更大。同样,对于与 T 相似的图像, I T C M o D ITC_\mathrm{MoD} ITCMoD 也能最大化 M I ( I m , T ) MI(I_m,T) MI(Im,T)。我们可以用同样的方法证明, M L M M o D MLM_\mathrm{MoD} MLMMoD 会为屏蔽词 y m s k y^\mathrm{msk} ymsk生成替代视图 y ′ ∈ V y'\in \mathcal{V} y′∈V并最大化 y ′ y' y′ 与 ( I , T ^ ) (I,\hat{T}) (I,T^)之间的 MI。因此,我们的动量蒸馏可视为对原始视图进行数据增强。动量模型会生成原始图像-文本对中不存在的各种视图,并鼓励基础模型学习捕捉与视图无关的语义信息的表征。
5 Downstream V+L Tasks
我们将预先训练好的模型适用于五个下游 V+L 任务。下面我们将介绍每个任务和微调策略。
图像-文本检索:(Image-Text Retrieval)
图像-文本检索包含两个子任务:图像-文本检索(TR)和文本-图像检索(IR)。我们在 Flickr30K和 COCO 基准上对 ALBEF 进行了评估,并使用每个数据集的训练样本对预训练模型进行了微调。对于Flickr30K上的zero-shot检索,我们使用在 COCO 上微调过的模型进行评估。在微调过程中,我们联合优化了 ITC 损失(公式 2)和 ITM 损失(公式 4)。ITC 基于单模态特征的相似性学习图像-文本评分函数,而 ITM 则对图像和文本之间的细粒度交互进行建模,以预测匹配得分。由于下游数据集包含每张图像的多个文本,我们改变了 ITC 的真实实况标签,以考虑队列中的多个阳性,其中每个阳性的真实实况概率为 1/#阳性。在推理过程中,我们首先计算所有图像-文本对的特征相似度得分 sitc。然后,我们选取前k个候选者,计算其 ITM 分数 sitm 以进行排序。由于 k 可以设置得非常小,因此我们的推理速度要比需要计算所有图像-文本对的 ITM 分数的方法快得多。
视觉蕴含任务(Visual Entailment, SNLI-VE)
视觉蕴含(SNLI-VE5)是一项细粒度视觉推理任务,用于预测图像和文本之间的关系是蕴含、中性还是矛盾。我们效仿 UNITER,将 VE视为一个三向分类问题,并在多模态编码器的[CLS]标记输出结果上使用多层感知器(MLP)预测类别概率。
视觉问答任务 (Visual Question Answering, VQA)
视觉问题解答(VQA)要求模型在给出图像和问题的情况下预测答案。与将 VQA 视为多答案分类问题的现有方法不同 [53, 2],我们将 VQA 视为答案生成问题,具体来说,我们使用 6 层transformer解码器来生成答案。如图 3a 所示,自动回归答案解码器通过交叉注意接收多模态嵌入,并将序列起始标记([CLS])作为解码器的初始输入标记。同样,解码器输出的末尾会添加一个序列结束标记([SEP]),表示生成完成。答案解码器使用来自多模态编码器的预训练权重进行初始化,并使用条件语言建模损失进行微调。为了与现有方法进行公平比较,我们限制解码器在推理过程中只能从 3192 个候选答案中生成答案。
自然语言视觉推理任务 (Natural Language for Visual Reasoning, NLVR)
自然语言视觉推理(NLVR)要求模型预测文本是否描述了一对图像。我们对多模态编码器进行了扩展,以实现对两幅图像的推理。 如图 3b 所示,多模态编码器的每一层都复制了两个连续的transformer块,其中每个块都包含一个自注意层、一个交叉注意层和一个前馈层(见图 1)。每一层中的两个区块使用相同的预训练权重进行初始化,两个交叉注意层共享相同的键和值线性投影权重。在训练过程中,这两个块接收两组图像对的图像嵌入。我们在多模态编码器的 [CLS] 表示上附加一个 MLP 分类器进行预测。
对于 NLVR,我们执行了一个额外的预训练步骤,为新的多模态编码器编码图像对做好准备:
我们设计的文本分配(TA)任务如下:给定一对图像和一段文本,模型需要将文本分配给第一幅图像、第二幅图像或任何一幅图像。 我们将其视为一个三向分类问题,并使用 [CLS] 表示上的 FC 层来预测分配。我们只使用 4M 幅图像对 TA 进行 1 个 epoch 的预训练(第 3.4 节)。
视觉定位 (Visual Grounding)
视觉定位旨在定位图像中与特定文字描述相对应的区域。我们研究了弱监督设置,在这种设置中,没有边界框注释可用。我们在RefCOCO+数据集上进行实验,并仅使用图像-文本监督对模型进行微调,遵循与图像-文本检索相同的策略。在推理过程中,我们扩展了Grad-CAM以获取热图,并使用它们对提供的检测建议进行排序。
6 Experiments

6.1 Evaluation on the Proposed Methods
首先,我们评估了提出的方法(即图像-文本对比学习、对比硬负面挖掘和动量提炼)的有效性。表 1 显示了我们的方法的不同变体在下游任务中的表现。
ITC的添加提升ALBEF性能:
与基线预训练任务(MLM+ITM)相比,添加 ITC 大幅提高了预训练模型在所有任务中的性能。
hard negative mining改进ITM:
所提出的硬负挖掘能找到更多信息丰富的训练样本,从而改进 ITM。
动量蒸馏的添加提升ALBEF性能:
此外,添加动量蒸馏功能可提高 ITC、MLM以及所有下游任务的学习效果。
最后,我们展示了 ALBEF 可以有效地利用噪声更大的网络数据来提高预训练性能。
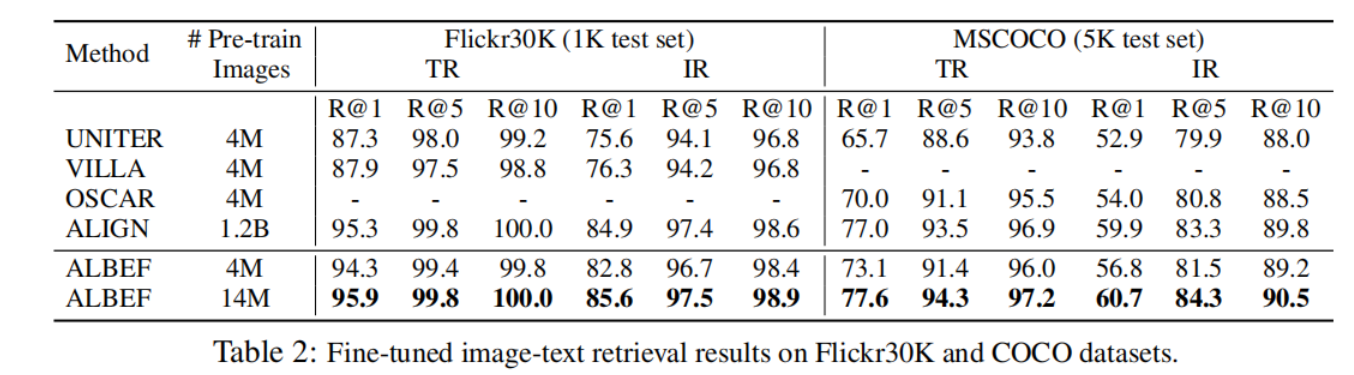
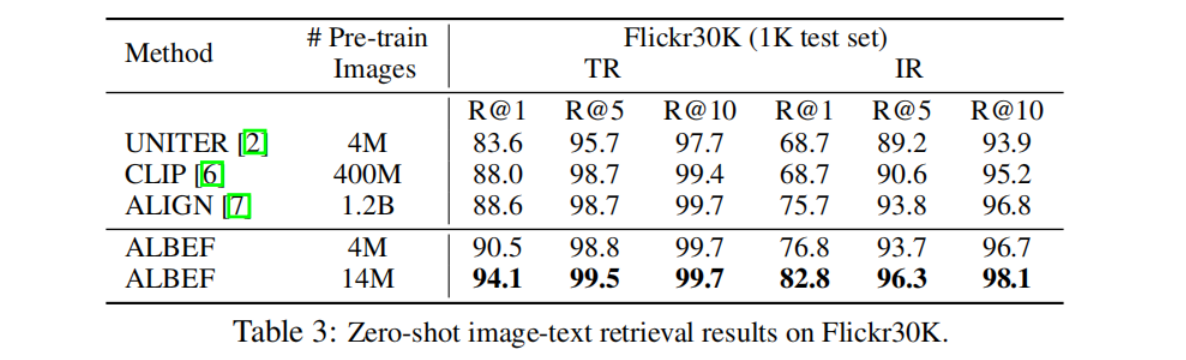
6.2 Evaluation on Image-Text Retrieval
ALBEF在图像文本检索中与其他VLP相比的结果:
表 2 和表 3 分别报告了微调图像文本检索和zero-shot图像文本检索的结果。我们的 ALBEF 达到了最先进的性能,超过了 CLIP和 ALIGN,它们是在数量级更大的数据集上训练的。当训练图像的数量从 400 万增加到 1400 万时,ALBEF 的性能有了相当大的提高,因此我们推测,通过在更大规模的网络图像-文本对上进行训练,ALBEF 的性能有可能进一步提高。
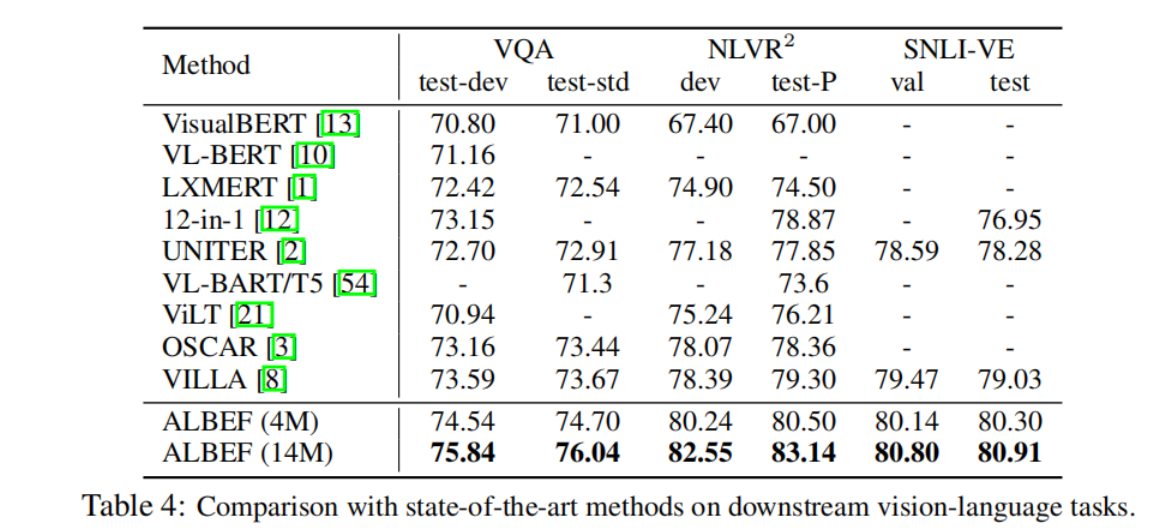
6.3 Evaluation on VQA, NLVR, and VE
ALBEF在其他 V+L 理解任务中与其他VLP相比的结果:
表 4 报告了在其他 V+L 理解任务中与现有方法的比较。在使用 400 万张预训练图像的情况下,ALBEF 已经达到了最先进的性能。在使用 1400 万张预训练图像的情况下,ALBEF 的性能大大优于现有方法,包括额外使用对象标记或对抗数据增强的方法。与 VILLA相比,ALBEF 在 VQA test-std、NLVR tetst-P 和 on SNLI-VE-test中的绝对值分别提高了 2.37%、3.84% 和 1.88%。由于 ALBEF 无需检测器,对图像的分辨率要求较低,因此推理速度也比大多数现有方法快得多(在 NLVR 上比 VILLA 快 10 倍以上)。
6.4 Weakly-supervised Visual Grounding
ALBEF在视觉定位中与其他VLP相比的结果:
表 5 显示了在 RefCOCO+上的结果,ALBEF 的性能大大优于现有方法(这些方法使用的文本嵌入较弱)。ALBEFitc 变体在图像编码器最后一层的自我注意图上计算 Grad-CAM 可视化,梯度是通过最大化图像-文本相似度 sitc 获得的。ALBEFitm 变体在多模态编码器第三层(专门用于定位的一层)的交叉注意图上计算 Grad-CAM,梯度是通过最大化图像-文本匹配分数 sitm 获得的。 图 4 提供了一些可视化效果。


我们在图 5 中提供了 VQA 的 Grad-CAM 可视化效果。ALBEF 的 Grad-CAM 可视化效果与人类在做出决策时的视线高度相关。在图 6 中,我们展示了 COCO 的单词可视化效果。请注意,我们的模型不仅为对象提供了依据,还为其属性和关系提供了依据。
6.5 Ablation Study
表 6 研究了各种设计方案对图像-文本检索的影响。由于我们在推理过程中使用 s i t c s_{itc} sitc 过滤前 k 候选者,因此我们改变 k 并报告其效果。一般来说, s i t c s_{itc} sitc 得出的排名结果对 k 的变化并不敏感。我们还在最后一列验证了硬负挖掘的效果。
表 7 研究了文本分配(TA)预训练和参数共享对 NLVR的影响。我们研究了三种策略:(1) 两个多模态区块共享所有参数,(2) 仅共享交叉注意层 (CA),(3) 不共享。
在不共享 TA 的情况下,共享整个区块的性能更好。通过 TA 对图像对模型进行预训练,共享 CA 可获得最佳性能。
7 Conclusion and Social Impacts
本文提出了一种新的视觉语言表征学习框架-ALBEF。ALBEF首先对齐单模态图像表征和文本表征,然后将它们与多模态编码器融合。我们从理论和实验上验证了所提出的图像-文本对比学习和动量蒸馏的有效性。与现有方法相比,ALBEF 在多个下游 V+L 任务上具有更好的性能和更快的推理速度。
虽然我们的论文在视觉语言表征学习方面取得了可喜的成果,但在实际应用之前,有必要对数据和模型进行更多分析,因为网络数据可能包含非预期的私人信息、不合适的图像或有害文本,仅优化准确性可能会产生不必要的社会影响。
A Downstream Task Details
ALBEF在各种微调下游任务的实现细节:
下面我们将介绍微调预训练模型的实施细节。在所有下游任务中,我们使用与预训练相同的 RandAugment、AdamW 优化器、余弦学习率衰减、权重衰减和蒸馏权重。所有下游任务都接收分辨率为 384 × 384 的输入图像。在推理过程中,我们会调整图像大小,但不会进行任何裁剪。
图像-文本检索:(Image-Text Retrieval)
图像-文本检索,在这项任务中,我们考虑了两个数据集:COCO 和 Flickr30K。我们对这两个数据集采用了广泛使用的Karpathy 分割法。COCO 包含 113/5k/5k 张图片,用于训练/验证/测试;Flickr30K 包含 29k/1k/1k 张图片,用于训练/验证/测试。我们对 10 个epoch进行微调。批次大小为 256,初始学习率为 1e -5 。
视觉蕴含任务(Visual Entailment, SNLI-VE)
视觉蕴含任务,我们在 SNLI-VE 数据集上进行评估,该数据集由斯坦福自然语言推理(SNLI)和 Flickr30K 数据集构建而成。我们按照原始数据集的拆分方法,将 29.8k 张图片用于训练,1k 张用于评估,1k 张用于测试。我们对预训练模型进行了 5 次微调,批量大小为 256,初始学习率为 2e -5 。
视觉问答任务 (Visual Question Answering, VQA)
VQA,我们在 VQA2.0 数据集上进行了实验,该数据集使用 COCO 的图像构建。该数据集包含 8.3 万张训练图像、4.1 万张验证图像和 8.1 万张测试图像。我们报告的是 test-dev 和 test-std 两部分的性能。按照大多数现有研究成果,我们使用训练集和验证集进行训练,并包括来自 Visual Genome 的额外问题-答案对。由于 VQA 数据集中的许多问题都包含多个答案,因此我们根据每个答案在所有答案中出现的百分比对其损失进行加权。我们使用 256 个batch size和 2e -5 的初始学习率对模型进行了 8 个epoch的微调。
自然语言视觉推理任务 (Natural Language for Visual Reasoning, NLVR)
NLVR,我们按照中最初的训练/评估/测试模式进行实验。我们使用 128个批次和 2e -5 的初始学习率对模型进行了 10 个 epoch 的微调。由于 NLVR 接收两张输入图像,因此我们使用文本分配(TA)执行额外的预训练步骤,为模型推理两张图像做好准备。TA 预训练使用大小为 256 × 256 的图像。 我们在 4M 数据集上预训练了 1 个 epoch,使用的批次大小为 256,学习率为 2e-5。
视觉定位 (Visual Grounding)
2e -5 的初始学习率对模型进行了 8 个epoch的微调。
自然语言视觉推理任务 (Natural Language for Visual Reasoning, NLVR)
NLVR,我们按照中最初的训练/评估/测试模式进行实验。我们使用 128个批次和 2e -5 的初始学习率对模型进行了 10 个 epoch 的微调。由于 NLVR 接收两张输入图像,因此我们使用文本分配(TA)执行额外的预训练步骤,为模型推理两张图像做好准备。TA 预训练使用大小为 256 × 256 的图像。 我们在 4M 数据集上预训练了 1 个 epoch,使用的批次大小为 256,学习率为 2e-5。
视觉定位 (Visual Grounding)
视觉定位,我们在 RefCOCO+ 数据集进行了实验,该数据集是通过双人 ReferitGame收集的。该数据集包含 COCO 训练集中 19,992 幅图像的 141,564 个表达式。严格来说,我们的模型不允许看到 RefCOCO+ 中的 Val/test 图像,但在预训练期间,它已经接触过这些图像。我们假定这不会产生什么影响,因为这些图像只占整个 1400 万张预训练图像中很小的一部分,并将其作为今后消除数据污染的工作。在弱监督微调过程中,我们采用与图像文本检索相同的策略,但不进行随机裁剪,并对模型进行 5 次epoch训练。在推理过程中,我们使用 sitc 或 sitm 计算每个 16 × 16 图像片段的重要性得分。对于 ITC,我们在视觉编码器最后一层的[CLS]标记的自我注意图上计算 Grad-CAM 可视化,并对所有注意头的热图进行平均。对于 ITM,我们在多模态编码器第 3 层的交叉注意图上计算 Grad-CAM,并对所有注意头和所有输入文本标记进行平均。 ITC 和 ITM 的定量比较见表 5。图 7 显示了定性比较。由于多模态编码器能更好地模拟图像与文本之间的交互,因此能生成更好的热图,捕捉到更精细的细节。在图 8 中,我们报告了每个交叉注意力层和表现最佳层中每个单独注意力头的定位精度。
![[svelte]属性和逻辑块](https://img-blog.csdnimg.cn/direct/a3e97acb936a4b5c8f1e05dcb610cc87.png)