接下来是微软的Orca这篇论文,23年6月挂到了arxiv上。

目前利用大模型输出来训练小模型的研究都是在模仿,它们倾向于学习大模型的风格而不是它们的推理过程,这导致这些小模型的质量不高。Orca是一个有13B参数的小模型,它可以学习到LLM的推理过程。这篇论文中GPT-4作为教师模型,ChatGPT作为助教,使用渐进式学习来训练小模型。
下图展示了各模型相对于ChatGPT的性能得分,由GPT-4进行打分,这里Orca是领先于和它同等大小的模型,甚至比超大模型ChatGPT还要好。(不过Orca本来就是用了GPT-4的回答进行了训练,GPT-4更认可它的回答也是意料之中的)
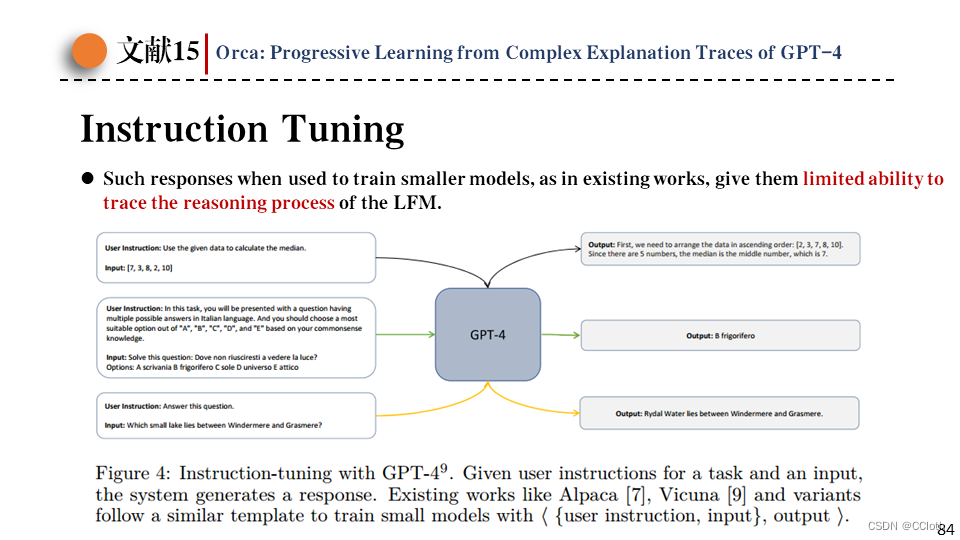
目前一些研究工作使用下图中的方式借助GPT-4来生成数据,然后用该数据对小模型进行指令微调。普通的指令微调通常只有简短的输入输出。当这些输入输出用于训练较小的模型时,就像现有的一些工作一样,它们追踪LLM推理过程的能力有限。
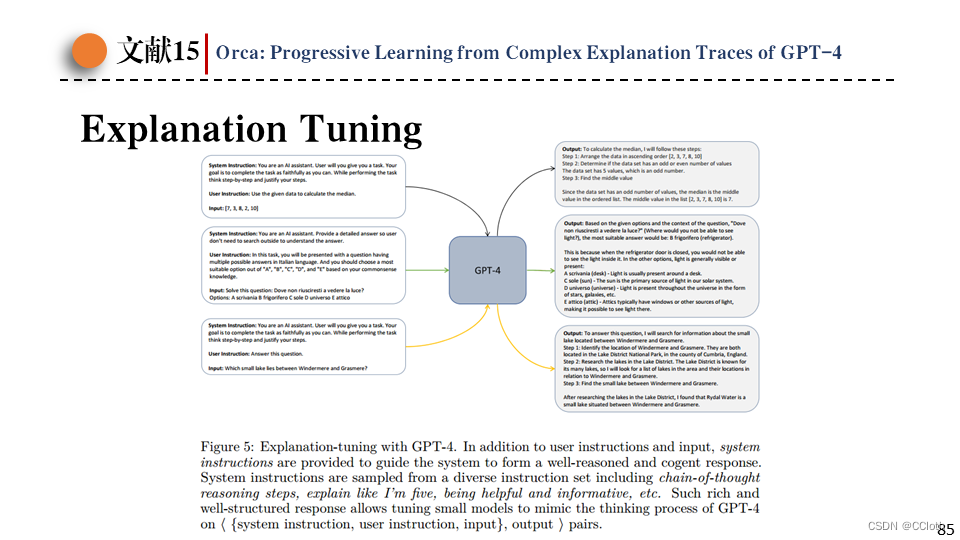
为了解决现有工作的不足,本文中提出了解释微调这一新型微调方法。如图中所示,将系统消息一起输入给GPT-4,系统消息可以要求LLM为回答生成解释信息或者逐步进行推理。

作者手动制作了16个不同的系统消息,如下图所示,这里展示了其中的8个系统消息。
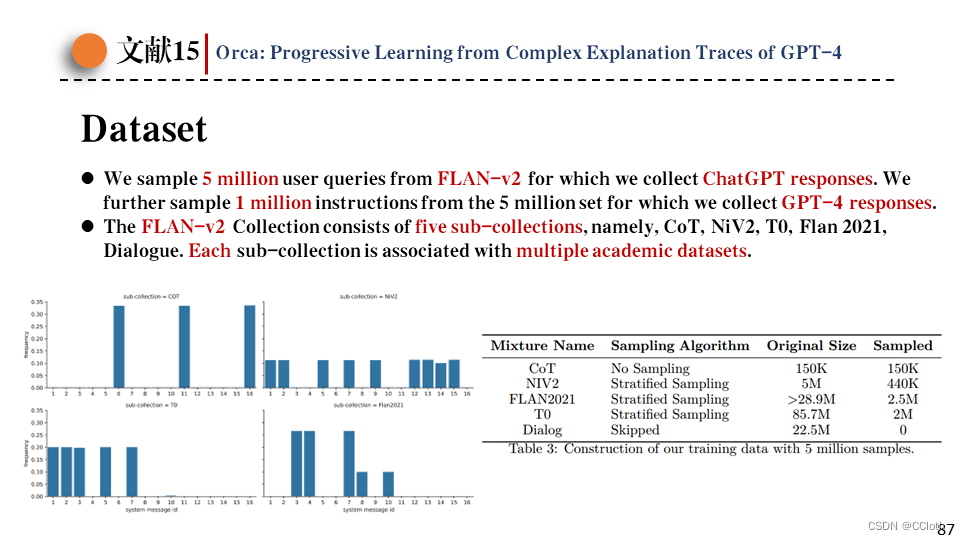
对于每一个数据集都有一组适合它的系统消息。这里就不得不提到模型训练用到的数据集了,训练集从FLAN-v2中采样,FLAN-v2又包括了5个子集,每个子集对应多个数据集。一共从FLAN-v2中采样了五百万条问题,下面右图显示了这些问题在各个子集中的占比。根据子集不同又有不同的系统消息,下面左图展示了不同子集中系统消息的频率分布。这五百万条问题输入ChatGPT获取回答,从中再抽一百万条输入GPT-4获取回答。这就构成了这篇论文使用的训练集了。

接下来要谈谈这篇论文使用的渐进式学习方法,所谓渐进式学习其实就是先用ChatGPT那五百万条数据训练,然后再用GPT-4那一百万条数据训练。
这里作者提到了为什么要用ChatGPT,主要有两个原因。第一个原因是模型的能力差距,Orca只有13B,相对GPT-4实在太弱了。有论文证明过,这时候引入一个能力差距比较小的中级教师作为过渡可以提升蒸馏效果。也就是渐进式学习的过程,学生首先从简单的例子中学习,然后再接触更难的例子,这时候从一个更优秀的老师那里得到改进过的推理步骤和逐步的解释。第二个原因就是GPT-4使用代价更高,如下面左图所示,GPT-4的价格更贵、每分钟允许请求数更少、每分钟可用token更少。基于这两个原因才引入了ChatGPT这个助教。下面右图显示了加入ChatGPT那五百万条数据后所带来的性能提升。
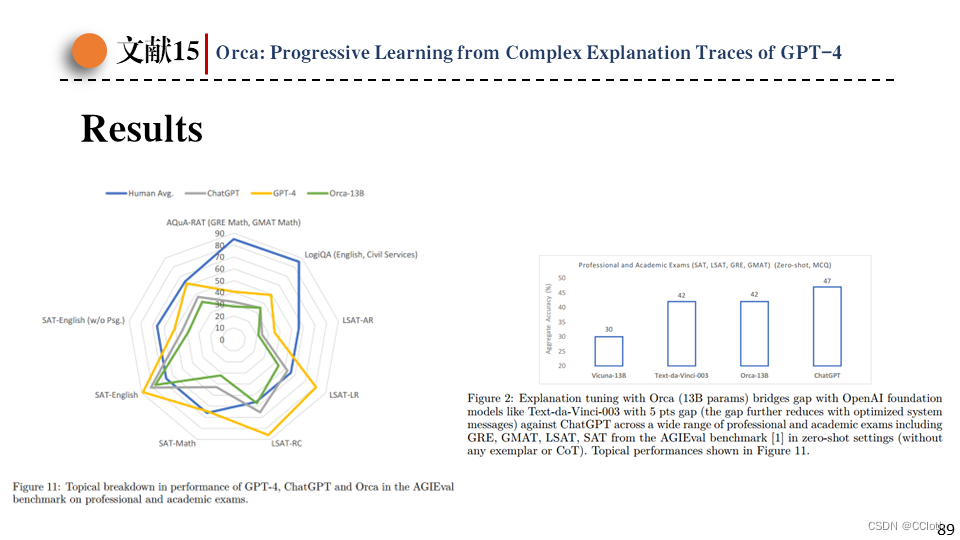
最后是模型的结果展示,左边是在某些考试上的得分,可以看到已经很接近ChatGPT了,右边是某些考试的平均得分,可以看到Orca明显优于同等规模的vicuna,同时表现接近了更大规模的模型。