本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:Coggle 4月竞赛学习:多模态图文问答
Part1 内容介绍
在自然语言处理领域,大型语言模型(LLM)如GPT-3、BERT等已经取得了显著的进展,它们能够生成连贯、自然的文本,回答问题,并执行其他复杂的语言任务。但想要让大模型回答复杂问题,需要对原始内容进行深入的理解,比如对数据库进行解析、图像、语音等内容进行解析。
Part2 活动安排
-
免费学习活动,不会收取任何费用。
Part3 积分说明和奖励
为了激励各位同学完成的学习任务,在完成学习后(本次活动,截止5月1),将按照积分顺序进行评选 Top3 的学习者。如果打卡积分相同,则按照prompt质量和文本长度进行排序。
-
在线打卡地址:https://shimo.im/forms/8LCjpqgXm6YEx8ZD/fill
-
在线评分地址:https://competition.coggle.club/
Top1的学习者将获得以下奖励:
-
50元现金红包
-
Coggle 竞赛专访机会
Top2-3的学习者将获得以下奖励:
-
20元红包
-
Coggle 竞赛专访机会
历史活动打卡链接,可以参考如下格式:
-
https://blog.csdn.net/weixin_42551154/article/details/125474519
-
https://blog.csdn.net/weixin_42551154/article/details/125481695
欢迎大家将打卡内容,发在本论坛中,让大家一起学习进步,交流讨论。
Part4 多模态图文问答
背景介绍
图像作为一种媒介,在信息传递和沟通中扮演着至关重要的角色。它能够直观地展示复杂的概念、情感和场景,使得信息的传递更为高效和生动。然而,尽管图像在很多领域都发挥着重要作用,目前的问答系统在这方面还存在一定的局限性,尤其是在图文交互方面。本场比赛希望推动人工智能在理解和处理视觉与文本信息方面的研究和应用。要求参赛者设计和开发算法模型,能够准确地从图像和相关的文本描述中提取信息,并回答关于这些信息的问题。
打卡任务
| 任务名称 | 所需技能 |
|---|---|
| 任务1:读取数据集 | Python |
| 任务2:问答类型聚类 | sklearn、jieba |
| 任务3:CLIP介绍 | Pytorch |
| 任务4:CLIP图文检索与匹配 | Pytorch |
| 任务5:CLIP模型微调 | Pytorch |
| 任务6:AltCLIP加载与使用 | Pytorch |
| 任务7:BLIP多模态生成模型 | Pytorch |
| 任务8:VisualGLM-6B多模态问答 | Pytorch |
| 任务9:VisCPM 对话与图文生成 | Pytorch |
任务1:读取数据集
-
任务说明:读取比赛数据数据,了解问答数据集
-
任务要求:
-
了解数据集背景
-
读取比赛数据集
-
阅读问答技术背景
-
比赛数据集的设计是为了模拟真实的电商环境,让参赛者能够开发出能够理解和处理实际场景中图像与文本信息的算法模型。训练集包含了原始的图片和文本描述,用于参赛者训练他们的算法模型。通过训练集,模型可以学习如何从图像和文本中提取特征,并建立起图像内容与文本描述之间的关联。
测试集为模拟生成的用户提问,需要参赛选手结合提问(question)和提问图片(related_image)进行生成回答(answer),其中测试集的样例格式如下:
{"question": "请对给定的图片进行描述。","related_image": "vwsscflkvakdictzacfx.jpg","answer": ""
}
在提问中问题存在以下几种类型:
-
通过提问(
question)对提问图片(related_image)进行提问和描述 -
通过提问(
question)检索到最相关的图片(related_image)
多模态数据集是指包含多种不同类型数据的数据集合,在多模态数据集中,每种类型的数据都提供了关于数据集主题的不同视角和信息。这种数据集在现实世界的应用中非常广泛,因为现实世界的信息往往是以多种不同形式存在的。
多模态问答(Multimodal Question Answering, MQA)是一种人工智能任务,它结合了来自不同模态的信息,如文本、图像、音频和视频,以提供更准确和全面的答案。多模态问答系统通常具有交互性,允许用户通过不同的方式提问,例如使用自然语言、点击图片中的具体区域或提供音频输入。

图中是女款服装吗?图中服装是什么颜色?图中模特搭配了什么鞋子?
多模态问答的挑战:
-
数据融合技术:如何有效地融合来自不同模态的数据是一个主要挑战。
-
特征提取:从多模态数据中提取相关特征需要特定的技术和方法。
-
语义理解:系统需要具备强大的语义理解能力,以便从文本、图像和其他模态中提取深层次的意义,并将其与问题相关联。
任务2:问题类型聚类
-
任务说明:分析问题类型,对提问进行聚类
-
任务要求:
-
通过文本聚类对提问进行分类
-
通过关键词对提问进行分类
-
通过大模型对提问进行分类
-
问题类型聚类是多模态问答系统中的一个关键步骤,它旨在将用户提出的问题根据其内容和性质进行分类。这个任务不仅有助于理解用户的查询意图,还能提高问答系统的效率和准确性。下面是数据集中提问的样例:
"question": "请匹配到与 2019秋冬新款百搭长裙女百褶裙显瘦金丝绒半身裙中长款高腰a字裙 最相关的图片。"
"question": "请对给定的图片进行描述。"
"question": "请匹配到与 罗拉家大码少女裙女装2019夏新品胖mm雪纺收腰方领爱心连衣裙3 最相关的图片。"
"question": "请对给定的图片进行描述。"
"question": "这是一款什么样的连衣裙?"
"question": "这款衬衫的面料是什么?"
...
首先我们需要对用户提出的问题进行深入分析,以确定其类型。这通常涉及到理解问题的语义内容、上下文信息以及与问题相关的图片信息。根据分析结果,将问题划分到不同的类别中。这些问题类别可以基于问题的意图、内容、复杂性或其他相关特征来定义。通过问题的划分,可以在后续对应执行不同的逻辑,以获得更好的问答体验。
在多模态问答系统中,问题可以根据其与图片和文本的关系进行分类。以下是一些可能的问题类型:
-
描述性问题:用户询问图片中的对象、场景或活动的描述,如“图片中的人在做什么?”
-
细节查询问题:用户对图片的特定细节感兴趣,如“这件衣服的颜色是什么?”
-
功能和用途问题:用户询问图片中产品的功能或用途,如“这款手机的摄像头像素是多少?”
-
比较问题:用户希望比较图片中的不同对象或产品,如“这两款相机哪个更适合旅行?”
-
推荐问题:用户寻求基于图片内容的推荐,如“根据这张室内装饰的图片,你能推荐一款相配的地毯吗?”
-
图文匹配问题:用户询问图片与特定文本描述的匹配程度,如“这张图片是否符合这个产品的描述?”
通过对问题进行有效的聚类和分类,多模态问答系统能够更好地理解用户的查询意图,并提供更加精准和相关的回答。以下是一些问题划分方法:
-
通过文本聚类对提问进行分类:
-
使用文本聚类技术,如K-means、层次聚类或基于密度的聚类方法,对问题文本进行分组。
-
聚类可以基于问题的语义相似性,将相似的问题归为一类。
-
可以通过词频、TF-IDF等文本特征提取方法来表示问题,然后使用这些特征进行聚类。
-
通过关键词对提问进行分类:
-
识别问题中的关键词和短语,这些关键词可以反映问题的主题和意图。
-
根据关键词的分布和频率,将问题分配到预定义的类别中。
-
可以结合自然语言处理技术,如命名实体识别(NER)和主题建模,来提取和分析关键词。
-
通过大模型对提问进行分类:
-
利用预训练的大型语言模型(如BERT、GPT等)来理解问题的上下文和语义。
-
这些模型可以捕捉到问题的深层语义特征,从而提高分类的准确性。
-
可以通过微调预训练模型,使其适应特定的问题类型和多模态数据集的特点。
任务3:CLIP介绍
-
任务说明:理解CLIP模型原理,并完成的CLIP的加载
-
任务要求:
-
理解CLIP模型的训练过程
-
理解CLIP模型的预测方法
-
CLIP(Contrastive Language-Image Pre-Training)模型是由OpenAI在2021年发布的一种多模态预训练神经网络。它通过从自然语言监督中学习,能够有效地理解和连接图像和文本信息。CLIP的核心思想是使用大量的图像和文本配对数据进行预训练,从而学习到图像和文本之间的对齐关系,使得模型能够理解图像内容并将其与文本描述相关联。
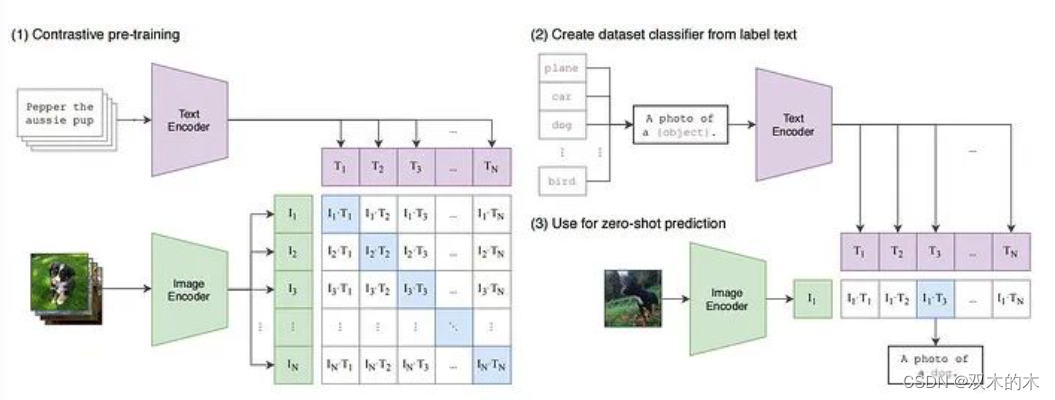
CLIP模型包含两个主要部分:图像编码器(Image Encoder)和文本编码器(Text Encoder)。
-
图像编码器(Image Encoder):
-
负责将输入的图像转换为低维向量表示(Embedding)。
-
可以使用不同的架构,如ResNet或Vision Transformer(ViT)。
-
在ViT架构中,图像首先被分割成多个小块(patches),然后加入位置信息,输入到Transformer模型中进行特征提取。
-
文本编码器(Text Encoder):
-
将文本转换为低维向量表示。
-
通常基于Transformer架构,执行对文本的小字节对编码(BPE)的表示。
-
文本序列用特定的起始和结束标记括起来,以形成有效的输入序列。
CLIP模型的训练基于对比学习的原则,通过最大化正面图像-文本对的相似度并最小化负面对的相似度来进行。具体来说,模型被训练来预测哪些文本描述与给定的图像相匹配。在训练过程中,模型会接触到大量的图像和文本对,并学习将它们映射到共同的嵌入空间中,以便能够准确地进行匹配。
CLIP模型因其强大的多模态理解能力,在多个领域展现出了卓越的性能,包括但不限于:
-
图文匹配:确定给定的文本描述是否与图像内容相匹配。
-
图像检索:根据文本查询找到相关的图像。
-
零样本学习:在没有看过特定类别的样本的情况下,对图像进行分类。
英文CLIP模型 https://huggingface.co/openai/clip-vit-large-patch14
from PIL import Image
import requestsfrom transformers import CLIPProcessor, CLIPModelmodel = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
中文CLIP模型 https://huggingface.co/IDEA-CCNL/Taiyi-CLIP-Roberta-102M-Chinese
from PIL import Image
import requests
import clip
import torch
from transformers import BertForSequenceClassification, BertConfig, BertTokenizer
from transformers import CLIPProcessor, CLIPModel
import numpy as npquery_texts = ["一只猫", "一只狗",'两只猫', '两只老虎','一只老虎'] # 这里是输入文本的,可以随意替换。
# 加载Taiyi 中文 text encoder
text_tokenizer = BertTokenizer.from_pretrained("IDEA-CCNL/Taiyi-CLIP-Roberta-102M-Chinese")
text_encoder = BertForSequenceClassification.from_pretrained("IDEA-CCNL/Taiyi-CLIP-Roberta-102M-Chinese").eval()
text = text_tokenizer(query_texts, return_tensors='pt', padding=True)['input_ids']url = "http://images.cocodataset.org/val2017/000000039769.jpg" # 这里可以换成任意图片的url
# 加载CLIP的image encoder
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
image = processor(images=Image.open(requests.get(url, stream=True).raw), return_tensors="pt")with torch.no_grad():image_features = clip_model.get_image_features(**image)text_features = text_encoder(text).logits# 归一化image_features = image_features / image_features.norm(dim=1, keepdim=True)text_features = text_features / text_features.norm(dim=1, keepdim=True)# 计算余弦相似度 logit_scale是尺度系数logit_scale = clip_model.logit_scale.exp()logits_per_image = logit_scale * image_features @ text_features.t()logits_per_text = logits_per_image.t()probs = logits_per_image.softmax(dim=-1).cpu().numpy()print(np.around(probs, 3))
任务4:CLIP图文检索与匹配
-
任务说明:完成CLIP图文检索与匹配任务,完成图文问答任务
-
任务要求:
-
使用训练好的CLIP模型从图像中提取视觉特征。
-
使用相同的模型从文本中提取语义特征。
-
根据相似度得分对图文对进行排序,以确定最佳的匹配结果。
-
在图文问答任务中,有很多任务是如下类型。如用户询问图片中的对象、场景或活动的描述,如图片中的人在做什么?用户询问图片与特定文本描述的匹配程度,如“这张图片是否符合这个产品的描述?”
描述性问题要求模型能够理解图片内容并用文本形式进行描述,图文匹配问题要求模型判断给定的文本描述与图像内容的匹配程度。都可以使用如下的流程来解决:
-
图像和文本特征提取:同时使用CLIP模型的图像编码器和文本编码器提取图像的视觉特征和文本的语义特征。
-
相似度计算:通过计算图像特征和文本特征之间的相似度(如余弦相似度)来判断它们的匹配程度。
-
匹配验证:根据相似度得分,确定文本描述是否符合图像内容。得分越高,表示匹配程度越高。
任务5:CLIP模型微调
-
任务说明:使用训练集中的图文对CLIP进行微调
-
任务要求:
-
确定微调的模型架构,选择合适的图像编码器和文本编码器。
-
设定微调的学习率、批次大小、训练周期等超参数。
-
决定是否冻结预训练模型的部分层。
-
任务6:AltCLIP加载与使用
-
任务说明:使用AltCLIP进行图文匹配
-
任务要求:
-
使用训练好的AltCLIP模型从图像中提取视觉特征。
-
使用相同的模型从文本中提取语义特征。
-
根据相似度得分对图文对进行排序,以确定最佳的匹配结果。
-
https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP
import torch
from PIL import Image
from flagai.auto_model.auto_loader import AutoLoaderdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")loader = AutoLoader(task_name="txt_img_matching",model_name="AltCLIP-XLMR-L", # Load the checkpoints from Modelhub(model.baai.ac.cn/models)model_dir="./checkpoints"
)model = loader.get_model()
tokenizer = loader.get_tokenizer()
transform = loader.get_transform()model.eval()
model.to(device)
tokenizer = loader.get_tokenizer()def inference():image = Image.open("./dog.jpeg")image = transform(image)image = torch.tensor(image["pixel_values"]).to(device)tokenizer_out = tokenizer(["a rat", "a dog", "a cat"], padding=True,truncation=True,max_length=77,return_tensors='pt')text = tokenizer_out["input_ids"].to(device)attention_mask = tokenizer_out["attention_mask"].to(device)with torch.no_grad():image_features = model.get_image_features(image)text_features = model.get_text_features(text, attention_mask=attention_mask)text_probs = (image_features @ text_features.T).softmax(dim=-1)print(text_probs.cpu().numpy()[0].tolist())if __name__=="__main__":inference()
任务7:BLIP多模态生成模型
-
任务说明:使用BLIP进行图文问答
-
任务要求:
-
理解BLIP模型的训练过程
-
理解BLIP模型的预测方法
-
任务8:VisualGLM-6B多模态问答
-
任务说明:使用VisualGLM-6B进行图文问答
-
任务要求:
-
理解VisualGLM-6B模型的训练过程
-
理解VisualGLM-6B模型的预测方法
-
任务9:VisCPM 对话与图文生成
-
任务说明:使用VisCPM进行图文问答
-
任务要求:
-
理解VisCPM模型的训练过程
-
理解VisCPM模型的预测方法
-
THE END!
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

![[python数据处理系列]详解独热编码与标签编码的区别及在Pandas中的实现](https://img-blog.csdnimg.cn/direct/50230b56e8654a4aa5a027d1357a0946.png)