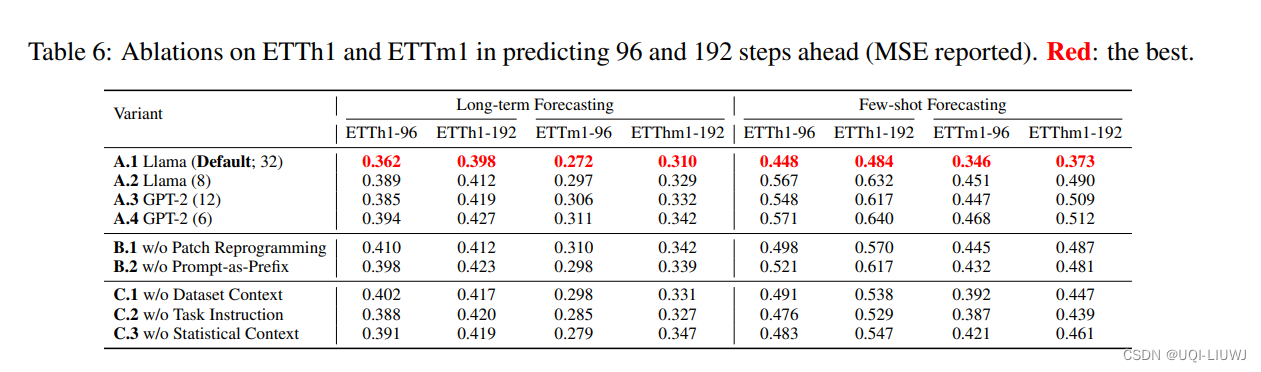
在深度学习模型的训练中,权重的初始值极为重要。一个好的初始值,会使模型收敛速度提高,使模型准确率更精确。一般情况下,我们不使用全0初始值训练网络。为了利于训练和减少收敛时间,我们需要对模型进行合理的初始化。
一、初始化方式
在常见的CNN深度学习模型中,最常出现的是Conv卷积和BatchNorm算子。
(1)对于Conv卷积,权重初始化的方式有‘normal’,‘xavier’,‘kaiming’,‘orthogonal’
- 以
‘normal’方式为例:对Conv卷积的weight通常是以均值为0,标准差为0.02的正态分布进行参数初始化
(2)对于BatchNorm算子,通常是使用‘normal’方式进行初始化
- 对
weight通常是以均值为1,标准差为0.02的正态分布进行参数初始化 - 对
bias通常是以方差为0的正态分布进行参数初始化
二、代码
def weights_init(net, init_type='normal', init_gain = 0.02):def init_func(m):classname = m.__class__.__name__if hasattr(m, 'weight') and classname.find('Conv') != -1:if init_type == 'normal':# ---------------------------------------------## Conv weight:均值为0,标准差为0.02的正态分布# ---------------------------------------------#torch.nn.init.normal_(m.weight.data, 0.0, init_gain)elif init_type == 'xavier':torch.nn.init.xavier_normal_(m.weight.data, gain=init_gain)elif init_type == 'kaiming':torch.nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')elif init_type == 'orthogonal':torch.nn.init.orthogonal_(m.weight.data, gain=init_gain)else:raise NotImplementedError('initialization method [%s] is not implemented' % init_type)elif classname.find('BatchNorm2d') != -1:# ---------------------------## BN weight:均值为1,标准差为0.02的正态分布# ---------------------------#torch.nn.init.normal_(m.weight.data, 1.0, 0.02)# ---------------------------## BN bias:方差为0的正态分布# ---------------------------#torch.nn.init.constant_(m.bias.data, 0.0)print('initialize network with %s type' % init_type)net.apply(init_func)
debug查看
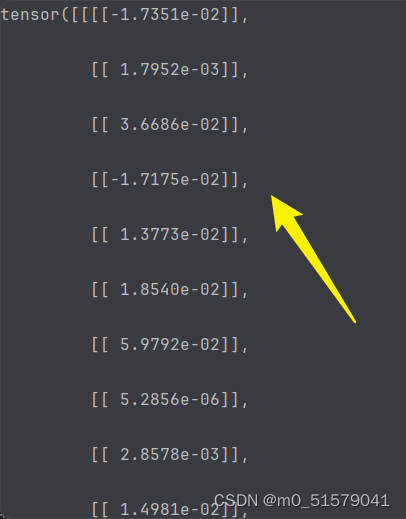
在执行weights_init函数之前,model.Dethead.obj_preds.weight的数值为
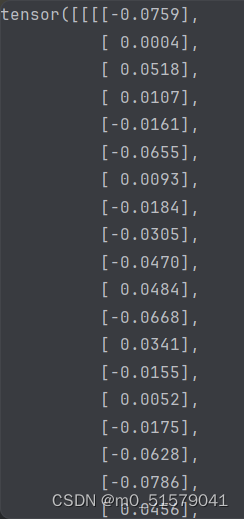
在执行weights_init函数之后,model.Dethead.obj_preds.weight的数值为