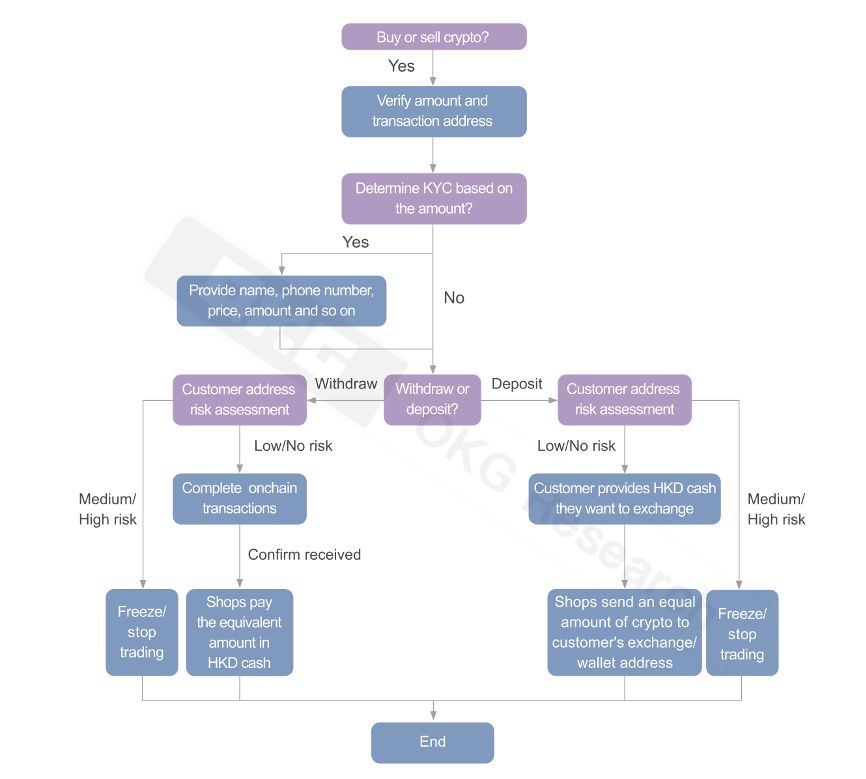
String (字符串)
虽然redis是用C语言编写,但是redis中的string是redis自己实现的字符串结构,叫Simple Dynamic String简称(SDS),因为redis做为中间件会接受不同语言编写的程序传过来的字符串,它们都可能和C语言中的字符串结构不一样,例如C语言中以’\0’表是字符串的结尾,当传过来的二进制数据转换成C语言中的字符串中间有’\0’那么C语言就会认为这个字符串已经结束了,则后面的数据就丢失了。redis中的string包含四部分:一个char类型的数组buff、一个len记录已经使用的长度、一个flags标识当前string的头信息以及一个alloc记录给当前string分配的大小。当客户端通过append或者setbit命令对string进行操作时,如果增加的字符串长度小于等于alloc-len则还是在当前string内存空间中直接添加即可,如果超出了string中剩余空间,则会重新分配一块内存,大小为新的字符串的长度*2(如果字符串的大小超过1mb则之后的扩容不会翻倍扩容而是每次增加1mb)。string最大的大小为512MB。
使用场景
- 计数器:Redis的原子递增操作可以用来实现Web应用中的各种计数功能,如页面访问计数、点赞数、评论数等。
- 分布式锁:在需要保证操作原子性的场景下,比如防止多个用户同时修改同一资源,可以使用Redis的String类型实现分布式锁。
- 会话共享:在多实例部署的Web应用中,可以使用Redis来存储用户的会话信息,实现会话共享,避免因会话问题导致的登录失效。
- 限流:通过设置特定的key来限制用户在一定时间内的请求次数,如短信验证码的发送频率控制,防止滥用。
- 全局序列号生成:在分布式系统中,可以使用Redis生成全局唯一的序列号,适用于订单号、票据号等。
- 消息队列:虽然不是String类型的直接应用,但可以通过List或Pub/Sub功能来实现消息队列,处理异步任务或事件通知。
- 存储JSON对象:将序列化后的JSON对象存储在Redis的String类型中,用于快速读取和修改,如用户配置、系统状态等,(如果对象中的某些字段经常修改时,建议用hash存储)。
- Webhook触发器:存储Webhook URL,当特定事件发生时,通过调用这些URL来触发外部服务。
- 分布式系统间的通信:在微服务架构中,Redis可以作为不同服务间的通信桥梁,传递轻量级的消息或数据。
- 缓存静态资源:将不经常变动的静态资源如图片、CSS和JavaScript文件缓存到Redis中,以减少数据库和文件系统的压力。
- 用户个性化设置:存储用户的个性化设置,如主题偏好、界面布局等,以便快速加载用户定制的界面。
常用命令
set key value//存储字符串键值对
mset key value [key value....]//批量存储字符串键值对
setnx key value//存入一个不存在的字符串键值对
get key//通过key获取value
mget key [key....]//批量获取value
del key [key....]//删除键值对
expire key seconds//设置过期时间
setex key seconds value//存储键值对并设置过期时间(秒)
psetex key milliseconds value//存储键值对并设置过期时间(毫秒)
append key value//key存在则追加字符串,不存在则设置
incr key//将key对应的数字值加一
decr key//将key对应的数字值减一
incrby key increment//将key对应的数字值加increment
decrby key increment//将key对应的数字值减increment
hash(散列)
redis的K-V键值对用的结构是dict,hash用的也是这个结构,类似于java中的hashtalbe,先有一个数组假设长度是4,当hset key field value时,将field通过hash算法如CRD16(field)计算得到一个0-65535之间的一个整数,再和数组长度取模得到这个field在数组中的位置,如果这个位置已经有了数据则将当前的value加入对应的链表中(当前的value为首节点)。
hash表中有一个重要的参数叫负载因子(负载因子 = used / size ; used 是哈希数组存储的元素个数,size 是哈希数组的长度)。当负载因子过大或过小,hash表会进行扩展或缩容,这两种都是通过渐进式rehash的方式完成的。
渐进式rehash:当哈希表中的元素过多时,如果一次性rehash到新的hashtable里,庞大的计算量,可能导致redis服务在一段时间不可用。为了避免rehash对服务器带来的影响,redis分多次、慢慢的将原本的哈希表中的键值对rehash到新的哈希表,这就是渐进式rehash
注:使用hash结构时,应避免单个hash结构过大,否则使用hgetall的操作时可能会导致线程阻塞,而且field是无法单独设置过期时间的
使用场景
类似于电商购物车这样的需要对对象中某一属性频繁修改的数据。
常用命令
HSET key field value//存储一个哈希表key的键值
HSETNX key field value//存储一个不存在的哈希表key的键值
HMSET key field value [field value ...]//在一个哈希表key中存储多个键值对
HGET key field//获取哈希表key对应的field键值
HMGET key field [field ...]//批量获取哈希表key中多个field键值
HDEL key field [field ...]//删除哈希表key中的field键值
HLEN key//返回哈希表key中field的数量
HGETALL ey//返回哈希表key中所有的键值
HINCRBY key field increment//为哈希表key中field键的值加上增量increment
list(列表)
一个有序的链表结构,使用quicklist和ziplist实现。
当List满足以下两个条件时,使用Ziplist编码:
- 列表中的元素数量小于或等于list-max-ziplist-entries配置(默认512个)。
- 列表中每个元素的长度小于或等于list-max-ziplist-value配置(默认64字节)
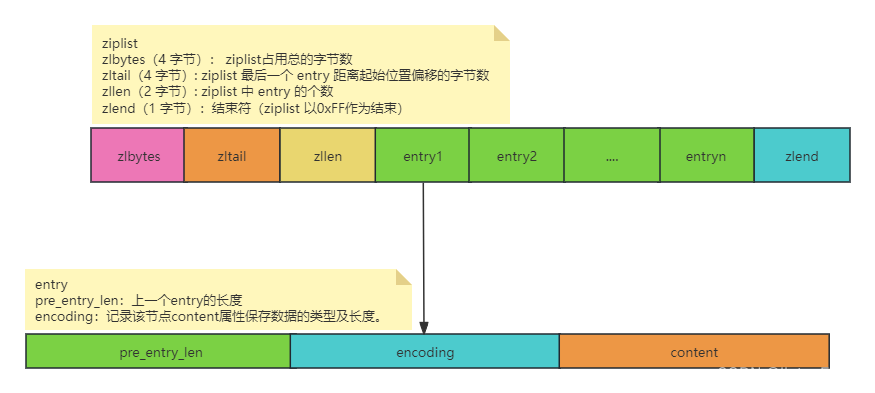
ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。所以我们必须限制ZipList的长度和entry大小。当list中的元素大小超过list-max-ziplist-value或者元素个数超过list-max-ziplist-entries,就会使用quciklist编码,将一个list拆分成多个小的ziplist,ziplist作为quicklist的节点,由quicklist来控制多个ziplist之间的联系。
配置参数:
- list-max-ziplist-size:控制着每个ziplist的最大长度,超过这个长度时,Redis会创建新的ziplist。
- list-compress-depth:控制着压缩的层数,即在进行列表操作时,Redis会从外到内压缩多少层ziplist。
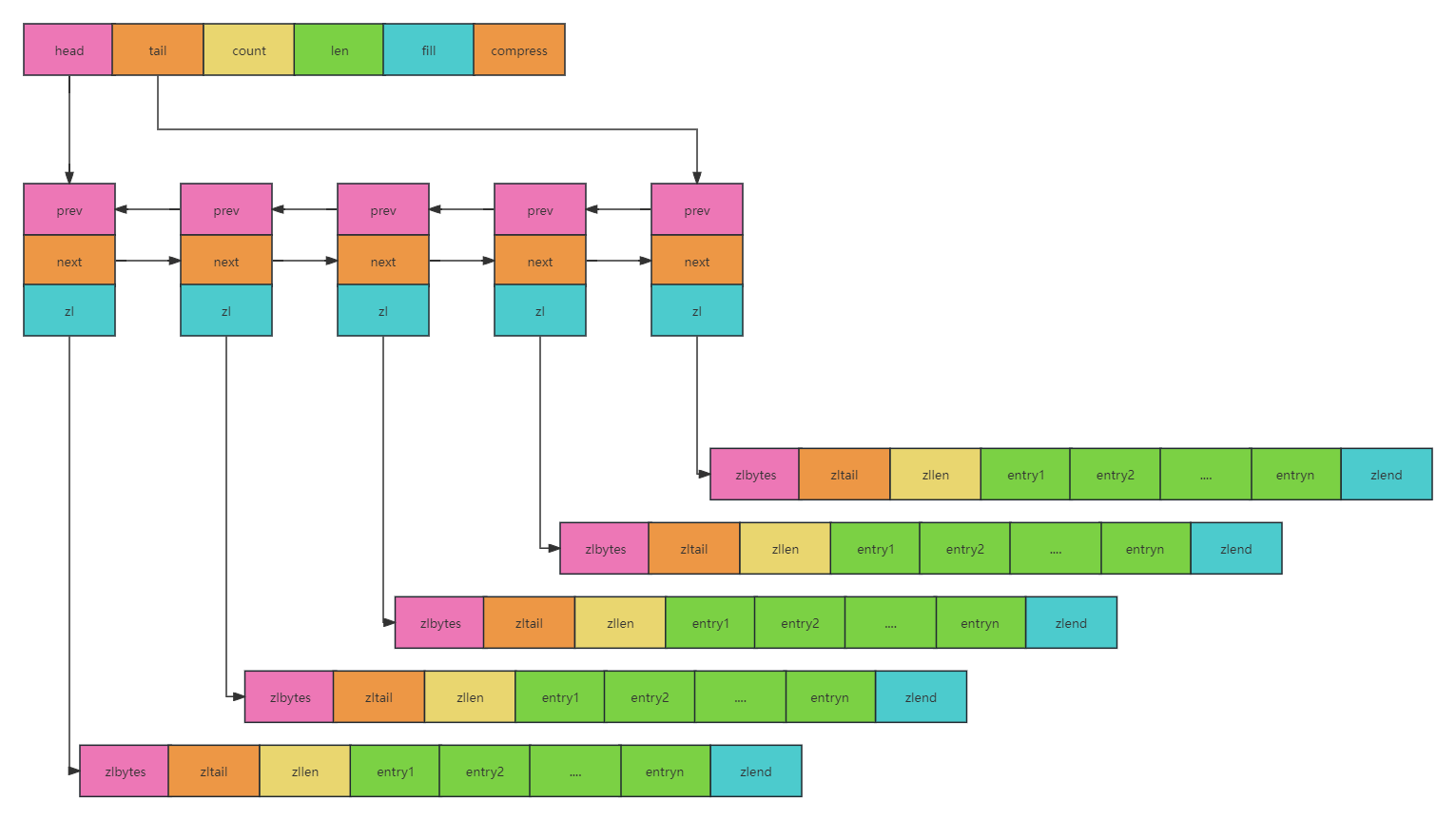
quickList结构如下:
- head:quickListNode头节点
- tail:quickListNode尾节点
- count:所有的ziplist中的entry总数量
- len:ziplist节点数量
- fill:ziplist中entry的上限,默认为-2
- compress:首尾节点不压缩的个数,若设置为1,则首尾节点各有一节点不压缩,中间节点压缩,中间节点压缩为0x4…等乱码,读的时候需要解压缩;写的时候需要重新压缩;设置为0,则代表所有节点不压缩
quickListNode结构如下:
- prev: 前一个节点指针
- next:后一个节点指针
- zl: 当前节点ziplist指针
具体结构如图
使用场景
- Stack(栈) = LPUSH + LPOP
- Queue(队列)= LPUSH + RPOP
- Blocking MQ(阻塞队列)= LPUSH + BRPOP
常用命令
LPUSH key value [value ...]//将一个或多个值value插入到key列表的表头(最左边)
RPUSH key value [value ...]//将一个或多个值value插入到key列表的表尾(最右边)
LPOP key//移除并返回key列表的头元素
RPOP key//移除并返回key列表的尾元素
LRANGE key start stop//返回列表key中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key ...] timeout//从key列表表头弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
BRPOP key [key ...] timeout//从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
set (无序集合)
set是一个无序的、自动去重的集合数据类型,它的基本数据结构就是value为null的dict,当set中存储的元素都是整型,且set中元素的个数没有超过set-max-intset-entries(默认512,intset能存储的最大元素个数)的大小,则set集合编码为intset结构。
使用场景
- 抽奖
- 微信朋友圈点赞用户列表
- 微博我关注的人、共同关注、朋友推荐
常用命令
SADD key member [member ...]//往集合key中存入元素,元素存在则忽略,若key不存在则新建
SREM key member [member ...]//从集合key中删除元素
SMEMBERS key//获取集合key中所有元素 点赞用户列表
SCARD key//获取集合key的元素个数 点赞数量
SISMEMBER key member//判断member元素是否存在于集合key中 是否点赞
SRANDMEMBER key [count]//从集合key中选出count个元素,元素不从key中删除 单次抽奖
SPOP key [count]//从集合key中选出count个元素,元素从key中删除 一等奖 二等奖 三等奖 且不能重复获奖的情况
SINTER key [key ...]//交集运算 共同关注
SINTERSTORE destination key [key ..]//将交集结果存入新集合destination中
SUNION key [key ..]//并集运算
SUNIONSTORE destination key [key ...]//将并集结果存入新集合destination中
SDIFF key [key ...]//差集运算 朋友推荐
SDIFFSTORE destination key [key ...]//将差集结果存入新集合destination中
Sort set (有序集合)
sortset是一个有序且去重的集合,当数据量较小时使用ziplist结构编码,当到达一定数量时使用dict+skiplist的结构去实现。
ziplist结构编码使用条件
- 元素数量小于zset_max_ziplist_entries,默认值128
- 每个元素都小于zset_max_ziplist_value,默认值64byte
ZipList本身没有排序功能,而且没有键值对的概念,因此存储sortset时score和element是紧挨在一起的两个entry,element在前,score在后,Score越小越接近队首,score越大越接近队尾,按照score值升序排列。
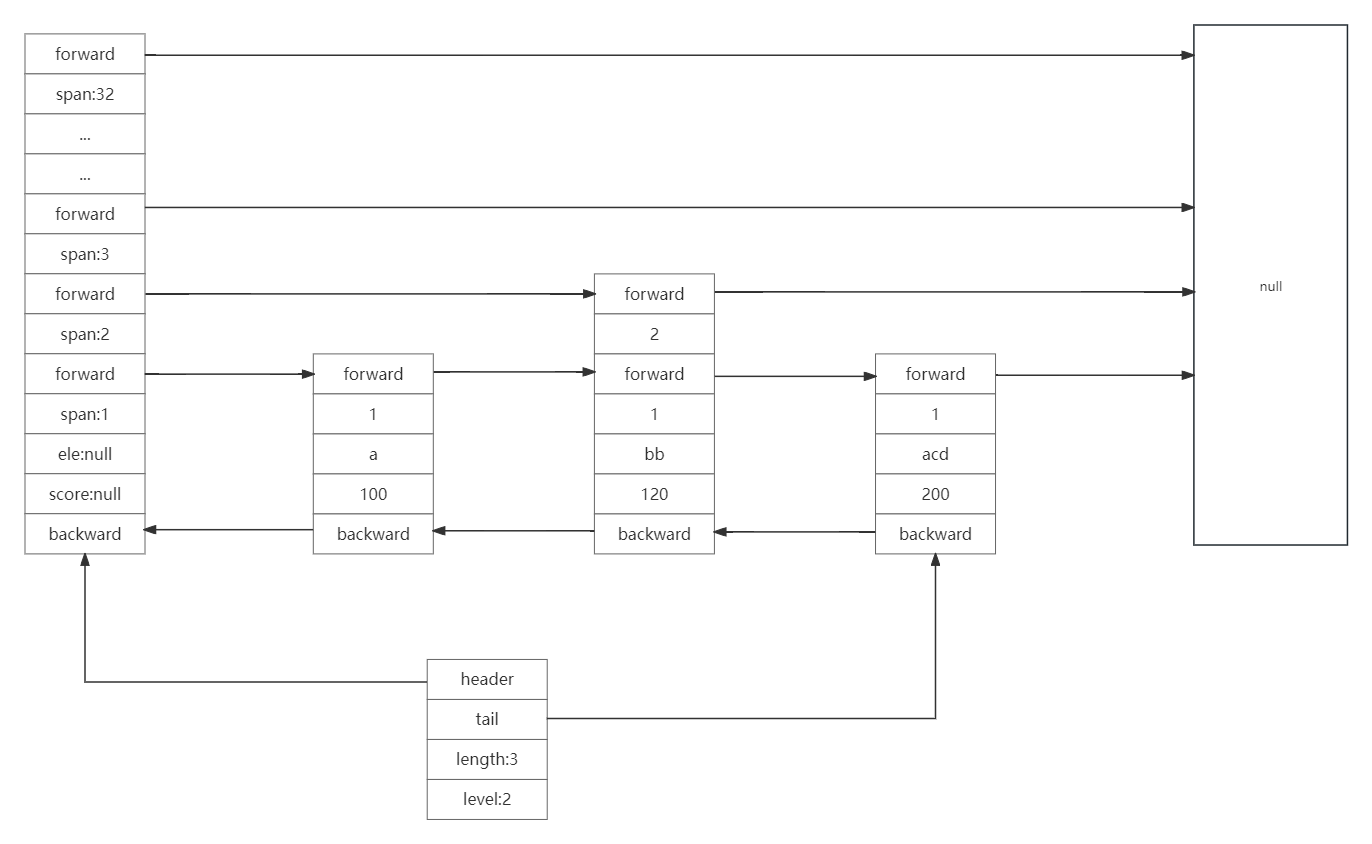
skiplist基于score进行排序,每个节点存有索引数组,所以有多个索引层级,优先从最高的层级查询,依次往下级索引查询,每个节点都有指针(每个指针的跨度可能不同)指向上一个和下一个节点,所以skiplist还是一个双向链表,具体结构如图:
- 逻辑图:
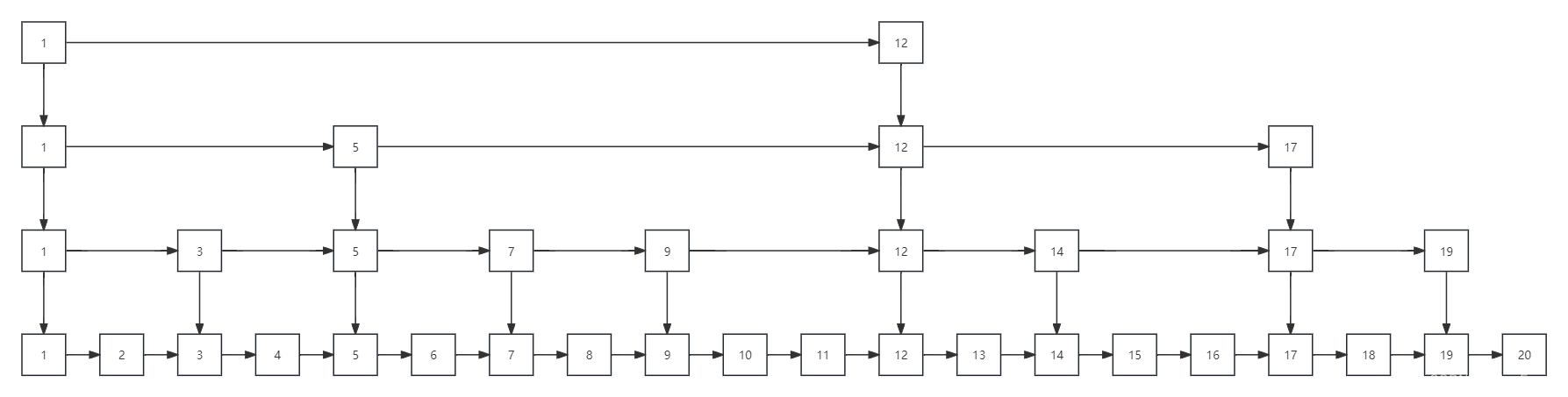
- 实际结构:
使用场景
- 排行榜,例如微博热搜top10
常用命令
ZADD key score member [[score member]…]//往有序集合key中加入带分值元素
ZREM key member [member …]//从有序集合key中删除元素
ZSCORE key member//返回有序集合key中元素member的分值
ZINCRBY key increment member//为有序集合key中元素member的分值加上increment
ZCARD key//返回有序集合key中元素个数
ZRANGE key start stop [WITHSCORES]//正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES]//倒序获取有序集合key从start下标到stop下标的元素
ZUNIONSTORE destkey numkeys key [key ...]//并集计算
ZINTERSTORE destkey numkeys key [key …]//交集计算
bitmap(位图)
基于string类型实现,相当于是对一个二进制的字符串进行操作,每个位都表示一个数据,0和1表示不同的两种状态。
使用场景
- 布隆过滤器:将数据经过哈希算法和取模,最终数据可以落在bitmap的某一个位上,将这个位设为1,查询时如果存在,可能因为哈希冲突的问题不能确认当前记录是否存在,但是如果获取不到则一定不存在,可用于缓存穿透问题中对大部分系统内没有的数据进行过滤
- 用户登录:一个string最大长度是512MB,则一个bitmap最大可以记录一天内51210241024*8 = 4294967296个用户的登录情况
常用命令
setbit key offset value//对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。位的设置或清除取决于 value 参数,可以是 0 也可以是 1 。当 key 不存在时,自动生成一个新的字符串值。未设置的位置以 0 填充。
getbit key offset //对 key 所储存的字符串值,获取指定偏移量上的位(bit)。当 offset 比字符串值的长度大,或者 key 不存在时,返回 0
bitop operation destkey key [key ...]//对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上。operation 可以是 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种
bitop and destkey key [key ...]//获取指定的天数都有登录的用户
bitop or destkey key [key ...]//指定天数中登录过的用户
bitcount key [start] [end]//计算给定字符串中,被设置为 1 的比特位的数量。
HyperLogLog(超日志)
HyperLogLog(HLL)是一种概率数据结构,用于估计集合中唯一元素的数量,而不需要存储这些元素本身。
使用场景
- 可用于统计大数据量且不重复的数据,例如一个页面的用户访问量,用户需要去重的情况
常用命令
PFADD key elemet [elemet...]# 添加元素到HyperLogLog
PFCOUNT key#获取HyperLogLog的基数估计值
PFMERGE destkey key[key...]# 合并多个HyperLogLog
Geospatial(地理空间)
地图经纬度信息,基于Sort set实现,存入时会将经纬度通过GeoHash算法转换为整数作为score存入sort set
使用场景
- 计算两点之间的距离
- 附件的人
常用命令
GEOADD key longitude latitude member [longitude latitude member ...]//将一个或多个指定的地理位置(经度和纬度)添加到给定的键(key)中。
GEOPOS key member [member ...]//返回一个或多个在键(key)中已存储的地理位置的坐标(经度和纬度)。
GEODIST key member1 member2 [m|km|mi|ft]//计算两个地理位置之间的距离。
GEORADIUS key longitude latitude radius m|km|mi|ft [WITHCOORD] [WITHDIST]//返回给定中心坐标和半径内的所有地理位置。
GEORADIUSBYMEMBER key member radius m|km|mi|ft [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]//返回与给定位置名称为中心的指定半径内的所有地理位置。
GEOHASH key member [member ...]//返回一个或多个位置对象的Geohash表示。
Stream (流)
- redis最早可以使用list来实现消息队列,但是list只能由一个消费者消费,不能广播。
- 之后redis引入了发布/订阅模式,l引入一个概念叫channel,生产者通过publish接口投递消息时会指定channel,消费者通过subscribe接口订阅它关心的channel,调用subscribe后这条连接会进入一个特殊的状态,通常不能在发送其他请求,当有消息投递到这个channel时Redis服务端会立刻通过该连接将消息推送到消费者。这里一个channel可以被多个应用订阅,消息会同时投递到每个订阅者,做到了消息的广播。另一方面,消费者也可以订阅一批channel。这解决了List结构单播的局限,允许一个消息被多个客户端接收。但是pub/sub模式中,是不管消费者是否接受到消息的,发完广播消息就删掉了,所以容易出现消息丢失的问题。
- redis在5.0之后引入了stream,提供了消息持久化,消费者群组,消费者待确认消息列表以及消费者确认消息的功能





![[阅读笔记20][BTX]Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM](https://img-blog.csdnimg.cn/direct/8751e7253f134d69b3387fceb546fff5.png)