题目来源
招银网络-技术-1面
题目描述
- 缓存穿透是什么?
- 如何防止缓存穿透
- 布隆过滤器的原理是什么?
我的回答
- 缓存穿透是什么?
攻击者大量请求缓存和数据库中都不存在的key。 - 如何防止缓存穿透
可以使用布隆过滤器 - 布隆过滤器的原理是什么?
记不太清楚了
更好的答案
- 布隆过滤器的使用流程
使用bitmap来存储合法的的商品id。
当请求到达服务器之后,如果缓存中没有,则不直接访问数据库,而是先通过布隆过滤器进行筛选,如果通过了布隆过滤器的筛选,则可以去查询数据库了,查出来了之后,再放入缓存,并返回给客户端。 - 布隆过滤器的原理
在这个问题的场景下,我们是把布隆过滤器当做白名单来使用,只有布隆过滤器里面存在的商品id,才能通过过滤,然后去访问数据库。
要实现时间复杂度为1的过滤,只能使用哈希算法,但是哈希算法经常会产生碰撞,就会产生误判。
所以,布隆过滤器采用了多种哈希算法,当要查询一个商品id是否在白名单中时,布隆过滤器会计算hash_1(id), hash_2(id), hash_3(id)…hash_n(id),把所有计算出来的哈希值对bitmap的总位数取余,然后判断是否所有的取余之后的结果,都在bitmap中,如果都在,那该商品id通过过滤,如下所示,qqcr1为合法id,可以去请求数据库了。
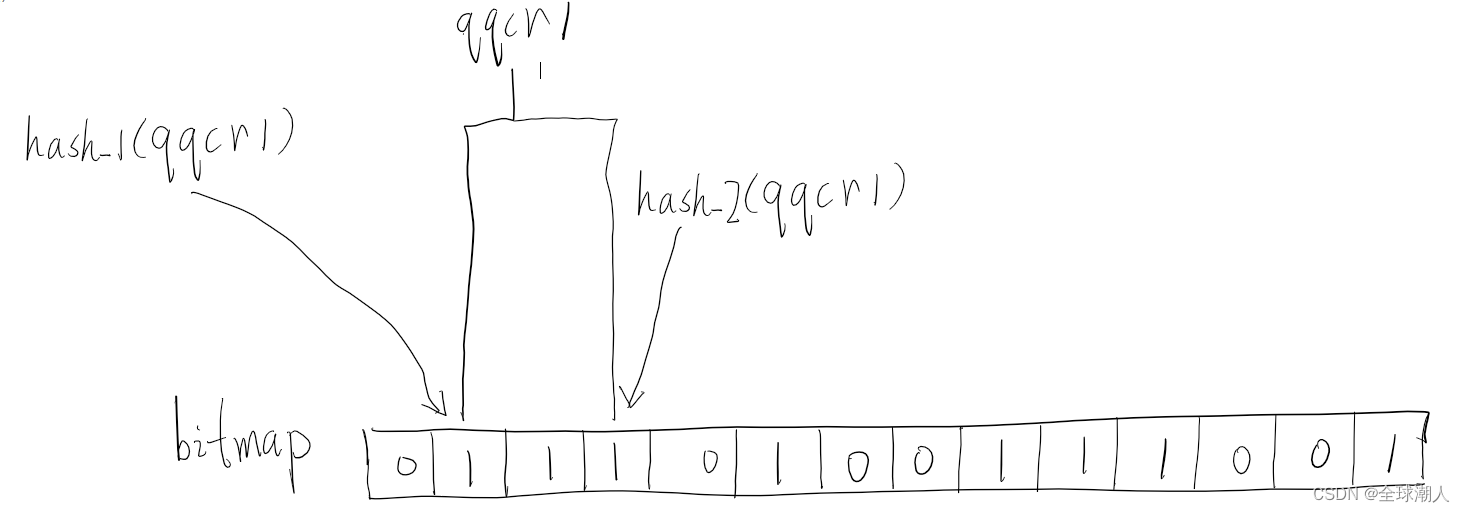
布隆过滤器是如何初始化的呢?答案是将所有的合法的商品id经过布隆过滤器定义的哈希函数计算之后,对bitmap的位数取余,然后将该bit位设置为1,如下图所示
如果有任何一个hash算法的结果取余之后不在bit毛中,则该商品id一定是攻击者伪造的,就不能去请求数据库,如下所以,qqcr2为非法id。
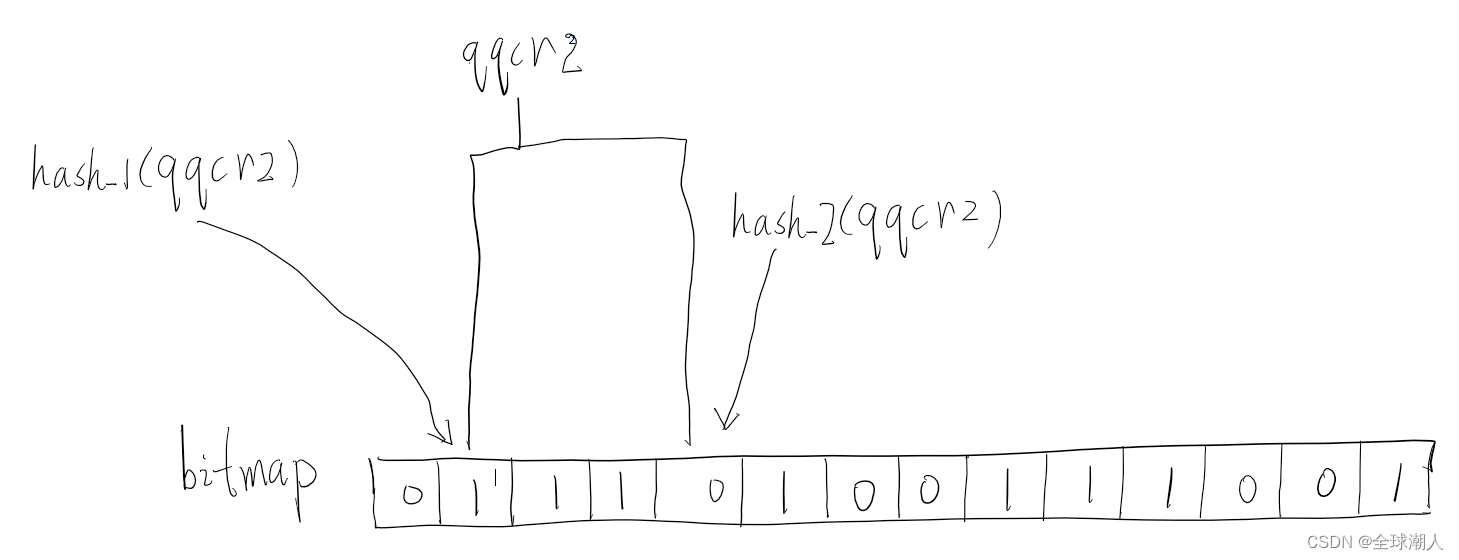
-
布隆过滤器的优点
使用bitmap来存储白名单,节省空间,并且计算哈希的时间复杂度是1,在判断商品是否存在时,可以使用如下方法:
获取哈希函数值,对bitmap总位数取余,假如结果为3和1,然后利用位运算,将一个int类型或者long类型的字面量1左移两位和1位,就可以得到100,010,将100和010做位运算或运算,就可以得到110,然后将110与bitmap做位运算与操作,如果结果大于0,则通过布隆过滤器的过滤,就可以去数据库查询了。当然,上述过滤操作是我自己猜想的,真正的布隆过滤器,肯定不止有int的32位或者long的64位,具体的需要去查找怎么做的布隆过滤器。 -
布隆过滤器的缺点
– 缺点1:可能会发生误判的情况
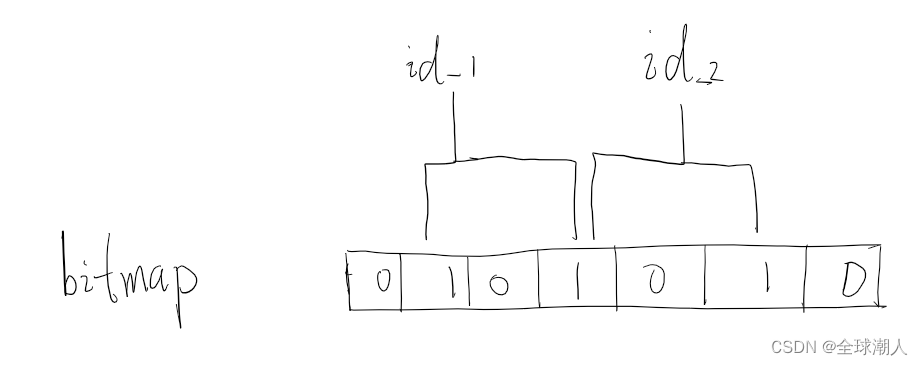
现在有两个合法商品id,id_1和id_2,一个不合法的商品id为id_3,有两个hash函数,计算出来的bitmap如下
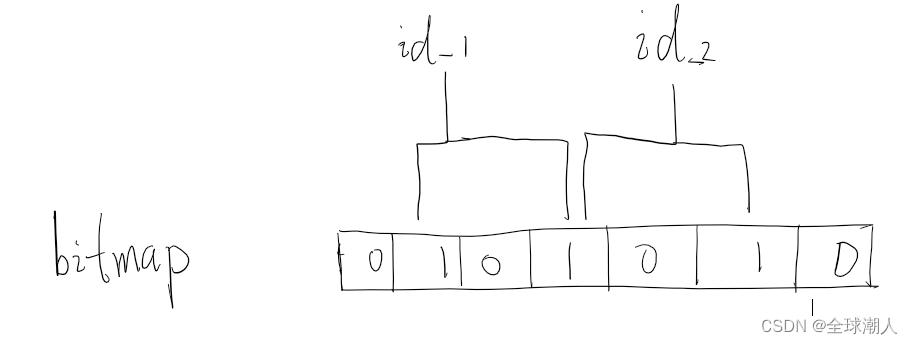
id_3计算出来的bit位如下,可以看到id_3计算的bit位跟id_1和id_2的bit位产生了碰撞,则id_3可以通过布隆过滤器的过滤,产生误判。
有没有什么办法可以解决这个误判的问题呢?
如果只使用一个布隆过滤器来存储商品白名单,则不行,因为哈希碰撞肯定会存在。有另一个思路,我们可以通过增加bitmap的长度与增加哈希函数的个数,缓解哈希碰撞,从而缓解误判的概率。但是,需要注意的是,增加bitmap会占用更多的存储空间,增加哈希函数,需要进行更多次的计算,会占用更多的CPU时间片。

– 缺点2:删除数据困难,假如bitmap已经初始化好了,如果后台管理员删除了某几个商品,则布隆过滤器不能直接将该商品对应的bit位设置为0,因为其他商品计算出来的bit位可能跟被删除的商品一致。所以我们可以采取定期重新初始化布隆过滤器的策略,在某些商品被删除到重新初始化期间,可能会出现误判。
遗留问题
怎么初始化布隆过滤器,布隆过滤器在代码中怎么使用?
布隆过滤器这个数据结构,是存在redis当中?还是存在我们写得Java服务当中?
参考
bilibili视频-徐庶老师-面试官:说说布隆过滤器怎么解决缓存穿透的?
小林coding:什么是缓存雪崩、击穿、穿透?