文章目录
- Scrapy 官网
- Scrapy 文档
- Github
- Scrapy 简介
- 项目结构
- 爬虫实现
- XPath 教程
- 创建 Scrapy 项目
- 配置用户代理
- 网页 dom 元素
- IP 代理池
- IP代理池作用
- 配置IP代理池
- 申请IP代理池
Scrapy 官网
- https://scrapy.org/
Scrapy 文档
- https://docs.scrapy.org/en/latest/
Github
- https://github.com/scrapy/scrapy/
Scrapy 简介
Scrapy 是一个强大的 Python 网络爬虫框架,用于从网站上抓取数据并进行处理。它提供了一套高效的工具和机制,让开发者能够轻松地创建、管理和扩展爬虫程序。
-
基于异步的框架: Scrapy 使用 Twisted 库作为其底层网络引擎,利用异步的方式实现了高效的网络请求和数据处理,能够同时处理多个请求,提高了爬取效率。
-
选择器: Scrapy 提供了类似于 jQuery 的 CSS 选择器和 XPath 选择器,使得开发者能够方便地从 HTML 页面中提取所需的数据。
-
管道(Pipeline): Scrapy 的管道机制允许你定义一系列的操作来处理从网页中提取的数据,比如清洗、验证、存储到数据库等。
-
中间件(Middleware): 中间件可以在请求和响应的处理过程中进行拦截和处理,提供了灵活的扩展和定制能力。
-
扩展性: Scrapy 提供了丰富的扩展接口,可以方便地添加自定义的功能和插件,满足不同场景的需求。
-
自动限速: Scrapy 自带了自动限速功能,可以避免对目标网站造成过大的压力,遵守网站的爬取规则。
-
内置调度器和去重: Scrapy 内置了调度器和去重器,能够有效地管理爬取过程中的请求队列和已经爬取的页面,确保数据的完整性和避免重复爬取。
项目结构
-
scrapy.cfg: 这是 Scrapy 项目的配置文件,用于指定项目的设置和配置信息,比如项目名称、爬虫模块等。它是一个INI格式的文本文件。
-
items.py: 这个文件定义了项目中用到的数据模型(Item)。数据模型用于定义要从网页中提取的字段,以及它们的类型和处理方式。它通常是一个类,继承自 Scrapy 的 Item 类。
-
middlewares.py: 这个文件定义了项目中使用的中间件。中间件是在 Scrapy 请求和响应处理过程中拦截和处理的组件,用于修改请求或响应,实现自定义的功能。例如,可以在中间件中添加代理、设置 User-Agent 等。
-
pipelines.py: 这个文件定义了项目中使用的管道(Pipeline)。管道用于处理从爬虫中提取的数据,可以执行一系列的操作,比如数据清洗、验证、存储到数据库等。它通常是一个类,继承自 Scrapy 的 Pipeline 类。
-
settings.py: 这个文件包含了项目的设置和配置信息,比如爬虫的 User-Agent、下载延迟、管道设置等。你可以在这里修改 Scrapy 的默认配置,以适应你的项目需求。
- USER_AGENT:设置用户代理字符串,用于模拟不同浏览器或设备发送请求。
- ROBOTSTXT_OBEY:设置是否遵守 robots.txt 规则。robots.txt 是一个文件,指示爬虫应该访问哪些页面。
- CONCURRENT_REQUESTS 和 CONCURRENT_REQUESTS_PER_DOMAIN:CONCURRENT_REQUESTS 设置同时发送的请求数量,而 CONCURRENT_REQUESTS_PER_DOMAIN 则限制对单个域名发送的并发请求数量。
- DOWNLOAD_DELAY:设置下载延迟,即发送两个请求之间的等待时间,以防止过于频繁地请求网站。
- COOKIES_ENABLED:设置是否启用 Cookies,用于保持登录状态或在网站间共享信息。
- ITEM_PIPELINES:设置数据管道的组件,用于处理爬取到的数据,如存储到数据库、写入文件等。
- AUTOTHROTTLE_ENABLED 和 AUTOTHROTTLE_START_DELAY:AUTOTHROTTLE_ENABLED 开启自动限速功能,AUTOTHROTTLE_START_DELAY 设置初始下载延迟。
-
spiders/: 这个目录包含了项目中的爬虫模块。每个爬虫通常是一个单独的 Python 文件,用于定义爬取规则、处理响应和提取数据。你可以在这里创建和管理多个爬虫。
-
init.py: 这个文件是 Python 包的初始化文件,用于标识该目录是一个 Python 包。
爬虫实现
免责声明: 本示例仅供技术交流学习,请遵守爬虫相关法律法规。
XPath 教程
- https://www.runoob.com/xpath/xpath-tutorial.html
XPath(XML Path Language)是一种用于在 XML 文档中定位节点的语言。它提供了一种简洁而强大的方式来选择 XML 文档中的特定部分,从而使得数据提取和文档导航变得更加容易和灵活。XPath 在 XML 文档中的应用非常广泛,同时也可以用于 HTML 文档的解析。
创建 Scrapy 项目
# 安装 Scrapy 库
pip3 install scrapy
# 创建 Scrapy 项目
scrapy startproject douban_top250
# 进入项目目录
cd douban_top250
# 创建 douban_movies.py 爬虫
scrapy genspider douban_movies movie.douban.com
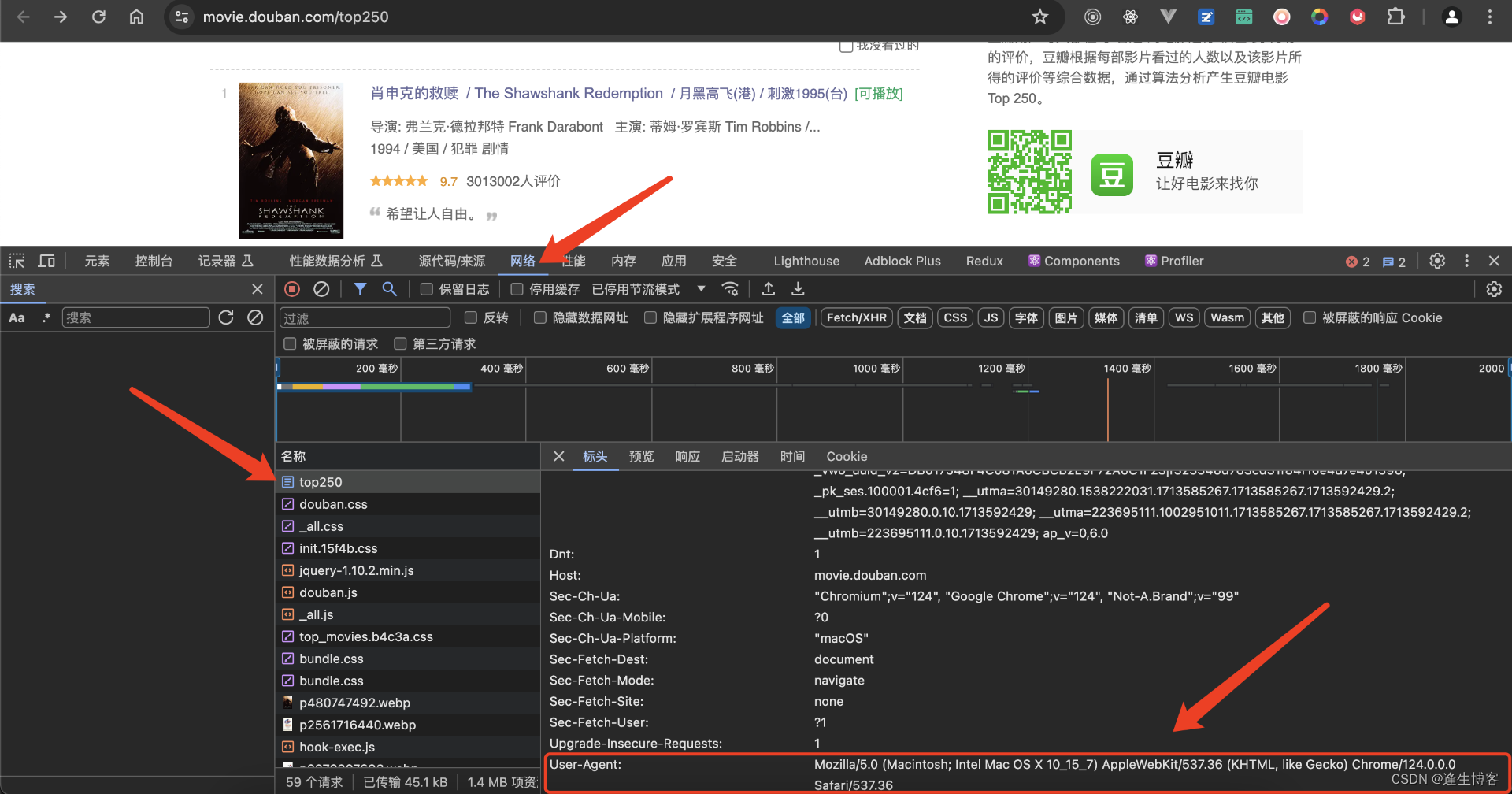
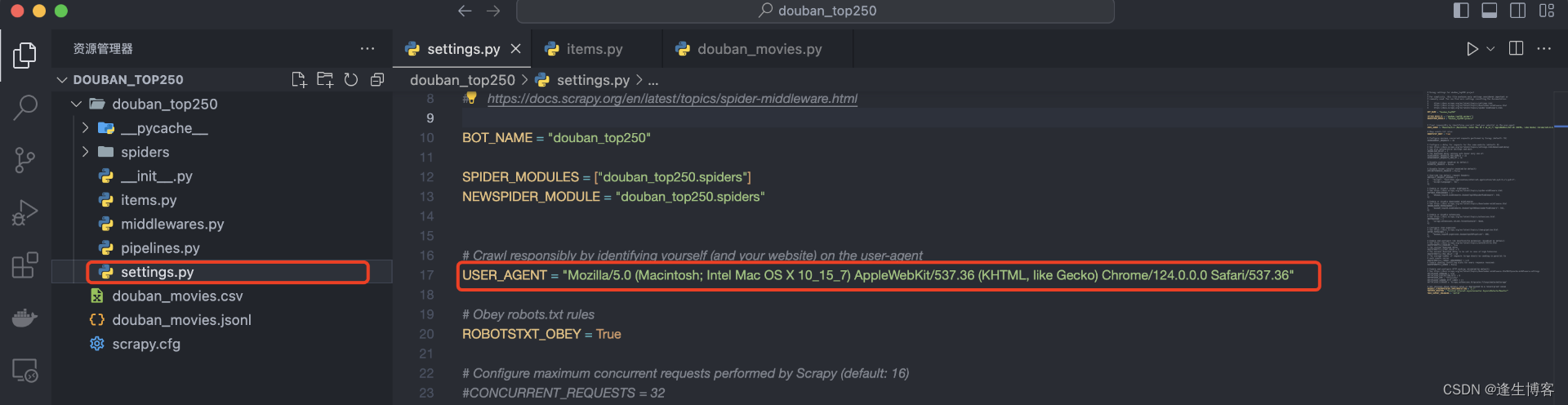
配置用户代理
- https://movie.douban.com/top250
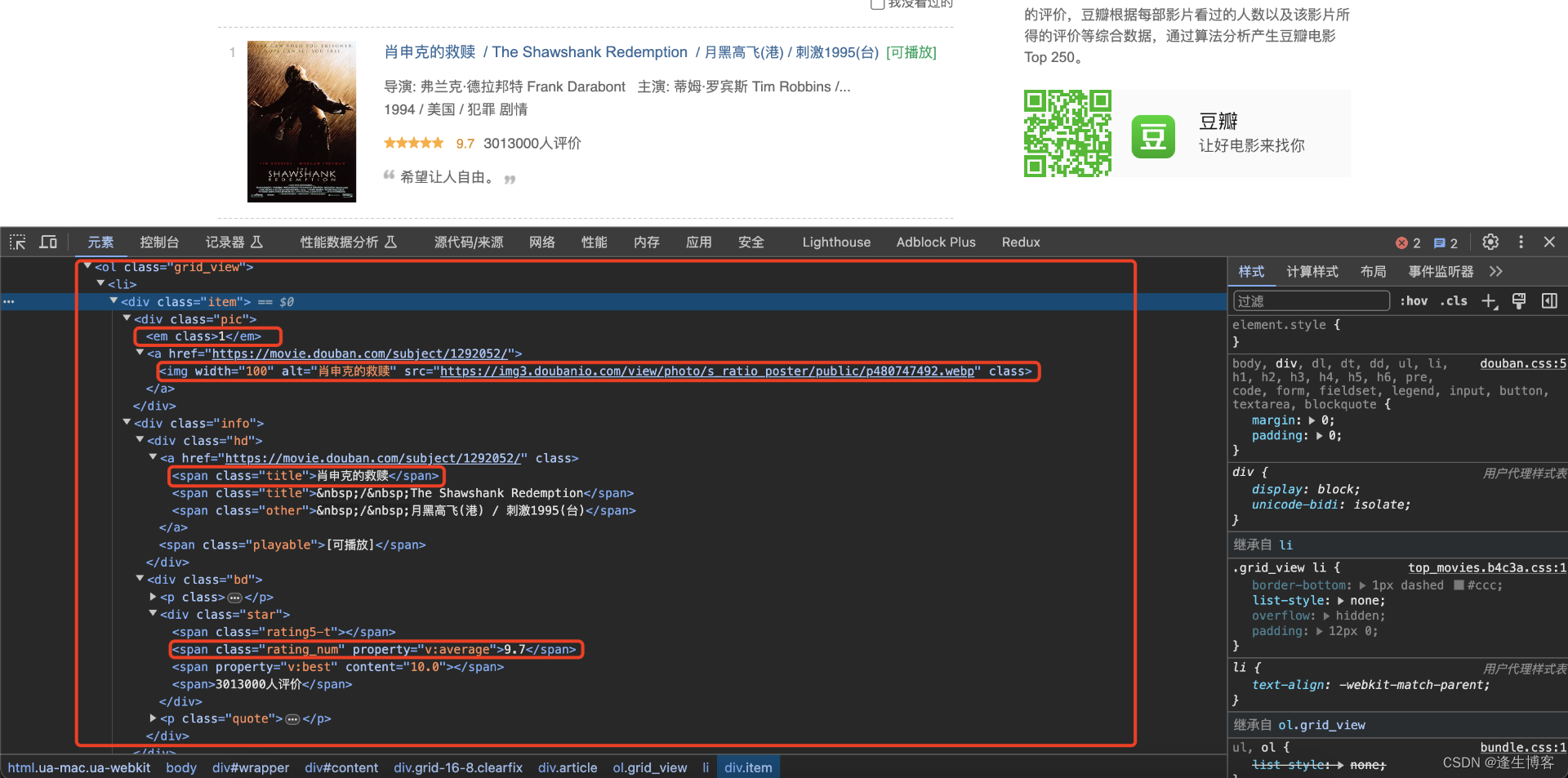
网页 dom 元素
- 编辑生成的 douban_top250/items.py
import scrapyclass DoubanTop250Item(scrapy.Item):rank = scrapy.Field()pic = scrapy.Field()title = scrapy.Field()rating = scrapy.Field()link = scrapy.Field()
- 编辑生成的 douban_top250/spiders/douban_movies.py
import scrapyfrom ..items import DoubanTop250Itemclass DoubanMoviesSpider(scrapy.Spider):name = "douban_movies"allowed_domains = ["movie.douban.com"]start_urls = ["https://movie.douban.com/top250"]def parse(self, response):# 解析电影列表movies = response.xpath('//ol[@class="grid_view"]/li')for movie in movies:item = DoubanTop250Item()item['rank'] = movie.xpath('.//div[@class="pic"]/em/text()').get()item['pic'] = movie.xpath('.//div[@class="pic"]/a/img/@src').get()item['title'] = movie.xpath('.//div[@class="hd"]/a/span/text()').get()item['rating'] = movie.xpath('.//div[@class="star"]/span[2]/text()').get()item['link'] = movie.xpath('.//div[@class="hd"]/a/@href').get()yield item# 获取下一页的链接next_url = response.xpath('//span[@class="next"]/a/@href').extract()if next_url:next_url = 'https://movie.douban.com/top250' + next_url[0]yield scrapy.Request(next_url)
- 运行爬虫并将结果保存到文件
# 输出到 douban_movies.csv 文件
scrapy crawl douban_movies -o douban_movies.csv
# 输出到 douban_movies.csv 文件,日志输出到 douban_movies.log 文件
scrapy crawl douban_movies -o douban_movies.csv -s LOG_FILE=douban_movies.log
# 输出到 douban_movies.jsonl 文件
scrapy crawl douban_movies -o douban_movies.jsonl
- douban_movies.csv
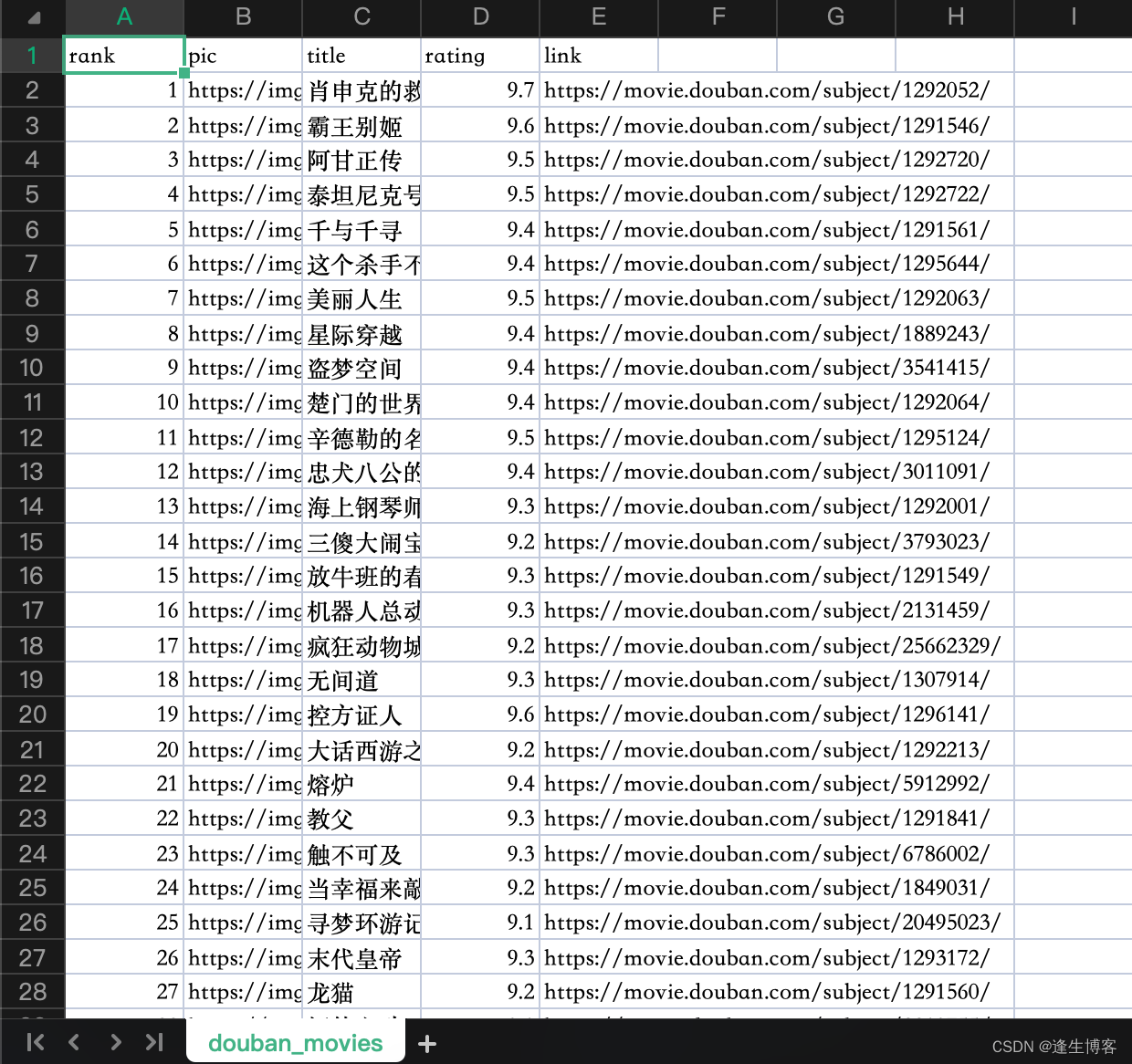
注意: 为了避免被封禁或者影响网站性能,建议设置合理的下载延迟和 User-Agent,并遵守网站的爬取规则。
IP 代理池
IP代理池作用
-
隐私保护:代理IP池可以隐藏用户的真实IP地址,确保用户在互联网上的匿名性。这对于一些需要保护个人隐私的用户或组织来说尤为重要。
-
访问限制:代理IP池可以模拟不同的IP地址,使用户可以绕过一些地理位置或访问限制。例如,在某些地区限制访问的情况下,通过代理IP池可以实现对被封锁内容的访问。
-
反爬虫:代理IP池可以防止网站对爬虫的屏蔽和限制。通过轮换使用不同的代理IP,可以规避被识别为爬虫的风险,确保爬取数据的稳定性和持续性。
配置IP代理池
- 编辑生成的 douban_top250/settings.py
# 暂时不使用IP代理池,请将值设置为 False
PROXY_ENABLED = True# 设置代理 IP 池
PROXIES = ['http://19.89.12.8','http://19.89.12.9',# 添加更多代理 IP
]# 启用随机代理IP中间件
DOWNLOADER_MIDDLEWARES = {"douban_top250.middlewares.DoubanTop250DownloaderMiddleware": 543,
}
- 编辑生成的 douban_top250/middlewares.py
import random
from scrapy.exceptions import NotConfigured
import logginglogger = logging.getLogger(__name__)class DoubanTop250DownloaderMiddleware(object):"""随机选择代理 IP 并将其添加到请求的 meta 中"""def __init__(self, proxies):self.proxies = proxies@classmethoddef from_crawler(cls, crawler):if not crawler.settings.getbool('PROXY_ENABLED'):raise NotConfiguredproxies = crawler.settings.getlist('PROXIES')logger.info("proxys: %s", proxies)return cls(proxies)def process_request(self, request, spider):# 从代理 IP 池中随机选择一个代理 IP 并添加到请求的 meta 中proxie = random.choice(self.proxies)logger.info("proxy: %s", proxie)request.meta['proxy'] = proxie
申请IP代理池