一、混淆矩阵
混淆矩阵就是统计分类模型的分类结果,即:统计归对类,归错类的样本的个数,然后把结果放在一个表里展示出来,这个表就是混淆矩阵。
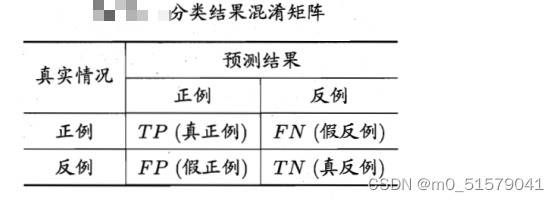
对于二分类问题,将类别1称为正例(Positive),类别2称为反例(Negative),分类器预测正确记作真(True),预测错误记作(False),由这4个基本术语相互组合,构成混淆矩阵的4个基础元素,为:
TP(True Positive):真正例,模型预测为正例,实际是正例
FP(False Positive):假正例,模型预测为正例,实际是反例
FN(False Negative):假反例,模型预测为反例,实际是正例
TN(True Negative):真反例,模型预测为反例,实际是反例
二、Pixel Accuracy (PA,像素精度)
(1)含义:分类正确的像素点数和所有的像素点数的比例
(2)计算公式:

图像中共有k+1类,Pii 表示将第i类分成第i类的像素数量(正确分类的像素数量),Pij表示将第i类分成第j类的像素数量(所有像素数量) 。因此该比值表示正确分类的像素数量占总像素数量的比例。
(3)根据混淆矩阵计算PA:
对角线元素之和 / 矩阵所有元素之和
PA = (TP + TN) / (TP + TN + FP + FN)
(4)优缺点
优点:简单
缺点:如果图像中大面积是背景,而目标较小,即使将整个图片预测为背景,也会有很高的PA得分,因此该指标不适用于评价以小目标为主的图像分割效果。
三、Mean Intersection over Union (MIoU)
(1)含义:MIoU就是该数据集中的每一个类的交并比的平均。
(2)计算公式如下:其中,Pij表示将i类别预测为j类别。
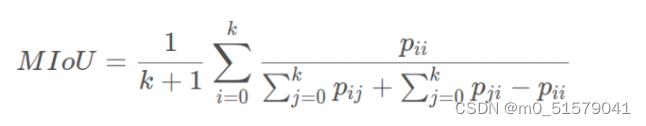
(3)根据混淆矩阵计算MIoU:
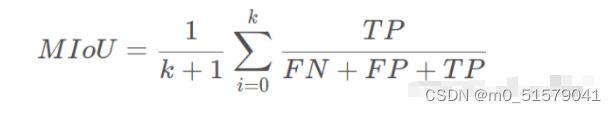
(4)一个有趣的图解:

在图上可以清晰的看到,prediction图被分成四个部分,其中大块的白色斜线标记的是true negative(TN,预测中真实的背景部分),红色线部分标记是false negative(FN,预测中被预测为背景,但实际上并不是背景的部分),蓝色的斜线是false positive(FP,预测中分割为某标签的部分,但是实际上并不是该标签所属的部分),中间荧光黄色块就是true positive(TP,预测的某标签部分,符合真值)。