- 🍅 我是蚂蚁小兵,专注于车载诊断领域,尤其擅长于对CANoe工具的使用
- 🍅 寻找组织 ,答疑解惑,摸鱼聊天,博客源码,点击加入👉【相亲相爱一家人】
- 🍅 玩转CANoe,博客目录大全,点击跳转👉
📘前言
-
🍅 车载测试必不可少的是刷写,行业内有很多格式的刷写文件,
S19,HEX,BIN,还有一些主机厂自定义的比如Volvo/Geea的VBF,Chery的CBF等 -
🍅 本章节先了解
HEX文件
目录
- 📘前言
- 📙 HEX 文件的格式简介
- 🍅 实例说明
- 🍅 HEX View 神器
- 📙CAPL解析HEX文件源码
- 🌎总结
📙 HEX 文件的格式简介
Hex全称 (Intel HEX)文件是由一行行符合Intel HEX文件格式的文本所构成的ASCII文本文件。在Intel HEX文件中,每一行包含一个HEX记录。这些记录由对应机器语言码和/或常量数据的十六进制编码数字组成。Intel HEX文件通常用于传输将被存于ROM或者EPROM中的程序和数据。大多数EPROM编程器或模拟器使用Intel HEX文件
Intel Hex的格式这个record包含6部分内容,其格式是这样的:

:020000040100F9
:20000000709EE4057090C0007078052054640010707B0128546400105064000061F35464B8
:2000200000007060E0007060C0037C73FBA670FEE7FB50E7800070E0C80BE62F7168E00AEB
:200040007170C1007200E0007220E0007240E0007260E0007280E00072A0E00072C0E00020
| 格式说明 | |
|---|---|
| Start code | 数据每行都由冒号开头 |
| Byte count | 数据长度 1 Byte ,表示本行数据的长度,大值是255 (0xFF). 16 (0x10) 和32 (0x20)是最常用的。 |
| Address | 数据地址 2 Byte ,表示Memory数据开始16-bit地址偏移。物理地址通常是有这个偏移加上基地址 |
| Record type | 数据类型 1 Byte, 00 ~ 05, 表示不同数据段的含义 |
| Data | 具体数据 N Byte ,表示本行中数据字节的数量,它和A说明的数据长度一致 |
| Checksum | 比如:0300300002337A1E的计算方法: 数据和为:03 + 00 + 30 + 00 + 02 + 33 + 7A = E2,这个E2的补码是1E,即这个数据record的补码 |
| 数据类型详解 | |
|---|---|
| ‘00’ | 数据记录:用来记录数据,HEX文件的大部分记录都是数据记录 |
| ‘01’ | 文件结束记录:用来标识文件结束,放在文件的最后,标识HEX文件的结尾 |
| ‘02’ | 扩展段地址记录:用来标识扩展段地址的记录 |
| ‘03’ | 开始段地址记录:开始段地址记录 |
| ‘04’ | 扩展线性地址记录:用来标识扩展线性地址的记录 |
| ‘05’ | 开始线性地址记录:开始线性地址记录 |
一旦出现段地址或者线性地址,之后所有数据都要加偏移地址,直到出现一个新的段地址或者线性地址,再重新变更偏移地址。数据物理地址为:线性地址左移16位+段地址左移4位+偏移地址。

- 基地址:0108左移16位à0x01080000;
- 扩展段地址:12FF左移4位à0x00012FF0;
- 数据偏移地址:0x0100;
- 实际物理地址=基地址+扩展段地址+偏移地址=0x010930F0。
🍅 实例说明
- Notepad++ 打开选,自动识别,根据颜色可以看出HEX的记录格式
- 看到的是16进制显示的ASCII文本格式
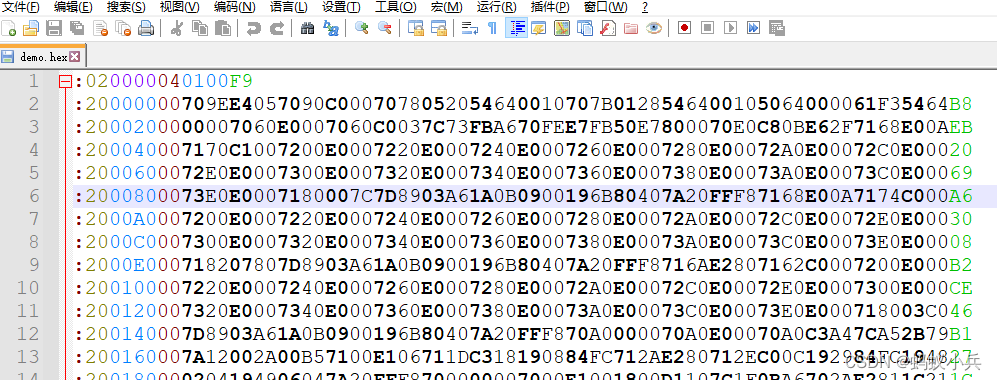
重点讲解下 Record type这个参数:
- 因为HEX的地址段只有两个字节表示,只能寻址到16位,显然是不够的,所以就有了拓展地址(
Record type =4),比如 头行数据:020000040100F9 ,02表示数据段的长度,2个字节;0000是默认填充的,04是Record type,表示后面的两个字节0x0100是拓展地址,也就是32位寻址的高16位,那么下面从第二行开始的地址段都会加上这个高地址段组成真正的刷写地址,比如刷写地址是0x01000000 - HEX文件大多数行的
Record type都是00 ,表示是数据段 - HEX文件最后一行的
Record type都是01 ,表示是结束
:20FFE00040F840F840F840F840F840F840F840F840F840F840F840F840F840F840F840F881
:00000001FF
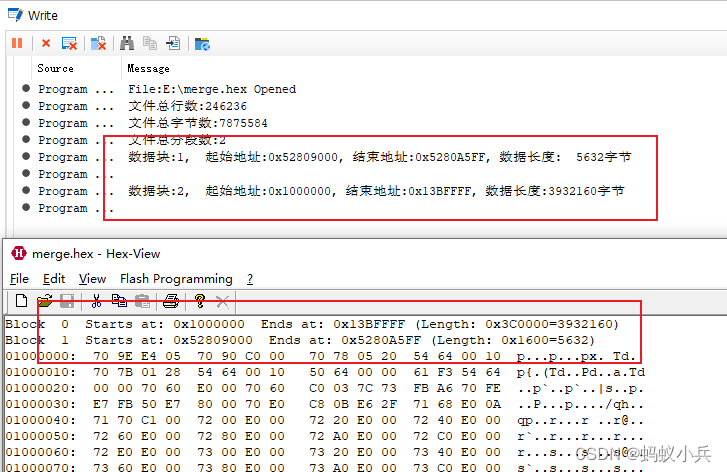
🍅 HEX View 神器
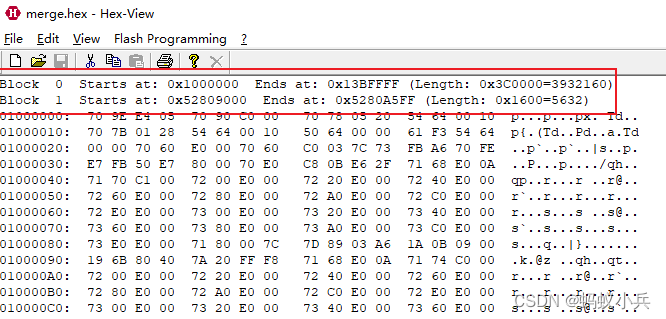
- HEX View 是一款专业的解析S19文件,HEX文件的工具,可以很方便的看出打开文件的Block块,起始地址和地址块的长度等信息
📙CAPL解析HEX文件源码
-
核心变量解释下:
-
F_SegmentInfor[10]:用来存放解析HEX文件的Block的信息,一般情况下,刷写文件的地址是不连续的,那么就会分成几个Block块,每个Block块我们要记录下该Block的起止地址,数据大小,因为这是我们UDS 34服务下载的必须数据,这里定义数组大小为10,足够大了,具体有多少个Block块,由变量SegCounter记录 -
FlsData_BufferArr[0x1FFFFFF]: 这个数组是记录是HEX文件的所有字节,数组大小可由刷写文件具体大小设置,因为这个数组存放的是所有Block块的数据,那么当我下载的时候我怎么区分,去取数据呢,那就是 上面说的结构体中的dword data_offset;这个变量来控制的, -
AllDataBytes:该文件所有的数据字节数。 -
我为什么没有这样定义 结构体呢?这样分段信息不是更加明确,刷写时取数据也更加方便直观吗?想一想为什么? struct FlsData_Segment
{
byte seg_index;
dword start_address;
dword data_size;
byte FlsData_BufferArr[0x1FFFFFF];
} F_SegmentInfor[10];//暂时定数组为10 -
Record type等于3/5的情况暂时没遇到,脚本没做处理。
/*@!Encoding:936*/variables
{ dword fileHandle;const dword text_module = 0;const dword binary_module = 1;enum File_Type { file_header, file_data,file_tail };struct FlsData_Segment {byte seg_index;dword start_address;dword data_size;dword data_offset; } F_SegmentInfor[10];//暂时定数组为10long SegCounter; //记录文件被分成多少个段long AllDataBytes; // 文件所有的数据字节数byte FlsData_BufferArr[0x1FFFFFF]; //文件中的所有字节被解析后放在该数组
}on key 'a'
{Flash_Parse_HEX("E:\\merge.hex");}long Flash_Parse_Hex(char f_path[])
{long fileHandle;char tmpBuffer[256]; //逐行读取,每行数据缓存dword i;dword tmpBufferByte; //单块数据块字节数qword OffsetAddress; //扩展线性地址 qword ReAddr; //上一数据行起始地址 dword Len; //HEX每行有效数据字节数dword ReLen; //HEX前一次数据长度dword Addr; //HEX每行起始地址dword Type; //HEX每行类型,有00,01,04四种类型long file_line_num; // 文件有多少行tmpBufferByte = 0;ReAddr = 0;ReLen = 0;SegCounter = 0;fileHandle = OpenFileRead(f_path,text_module);if (fileHandle == 0 ) {write("Failed to open File %s !",f_path);return 0 ;}write("File:%s Opened",f_path);while ( fileGetStringSZ(tmpBuffer,elcount(tmpBuffer),fileHandle)!=0 ){file_line_num++; //数据行计数器//write("file_line_num %d",file_line_num);//write("tmpBuffer %s",tmpBuffer);//判断首字符是否为:号if(tmpBuffer[0] == ':'){ Len = (char2byte(tmpBuffer[1])*0x10+char2byte(tmpBuffer[2])); // 数据长度Addr = char2byte(tmpBuffer[3])*0x1000+char2byte(tmpBuffer[4])*0x100+char2byte(tmpBuffer[5])*0x10+char2byte(tmpBuffer[6]);//偏移地址Addr = (OffsetAddress << 16) | Addr; //完整地址Type = char2byte(tmpBuffer[7])*0x10+char2byte(tmpBuffer[8]); //类型//以下为打印解析的过程,打印解析时候的变量// write("Addr %x",Addr);// write("tmpBufferByte %x",tmpBufferByte);switch(Type){case 0x00: //数据if (abs(Addr -ReAddr) > ReLen ) //判断为新数据块{ if(tmpBufferByte == 0) //是否为首行数据字节数{ F_SegmentInfor[SegCounter].data_offset = 0;F_SegmentInfor[SegCounter].start_address = Addr; //记录新数据块的起始地址}else //不是首行{F_SegmentInfor[SegCounter].data_size = tmpBufferByte; //数据长度 SegCounter++; tmpBufferByte = 0; //重新开始计数F_SegmentInfor[SegCounter].start_address = Addr; //记录新数据块的起始地址F_SegmentInfor[SegCounter].data_offset += tmpBufferByte; //相对数组FlsData_BufferArr的开始索引地址}}for(i = 0; i< Len ; i++){FlsData_BufferArr[AllDataBytes] = (char2byte(tmpBuffer[2*i+9])*0x10+char2byte(tmpBuffer[2*i+10]));AllDataBytes++; //全文件的字节计数器tmpBufferByte ++ ;//当前block的计数器} ReAddr = Addr; //保存当前地址,下一次使用 ReLen = Len; //保存当前长度,下一次使用 break;case 0x04: //扩展线性地址记录OffsetAddress = char2byte(tmpBuffer[9])*0x1000+char2byte(tmpBuffer[10])*0x100+char2byte(tmpBuffer[11])*0x10+char2byte(tmpBuffer[12]); //偏移地址 break;case 0x01: //地址,结束 F_SegmentInfor[SegCounter].data_size = tmpBufferByte; //数据长度F_SegmentInfor[SegCounter].data_offset = AllDataBytes - tmpBufferByte; //相对数组FlsData_BufferArr的开始索引地址 SegCounter++;break; } }}write("文件总行数:%d",file_line_num);write("文件总字节数:%d",AllDataBytes);write("文件总分段数:%d",SegCounter);for(i = 0; i < SegCounter; i++){write("数据块:%d, 起始地址:0x%X, 结束地址:0x%X, 数据长度:%6d字节\r\n", i+1, F_SegmentInfor[i].start_address, F_SegmentInfor[i].start_address + F_SegmentInfor[i].data_size - 1, F_SegmentInfor[i].data_size);}fileClose(fileHandle);return 1 ;
}byte char2byte(char ch)
{byte val;val = 0;if ( ch >= '0' && ch <= '9'){val = ch - '0'; }if ( ch >= 'a' && ch <= 'f'){val = (ch - 'a') + 10; }if ( ch >= 'A' && ch <= 'F'){val = (ch - 'A') + 10; }return val;
}- CAPL脚本跑出来的结果和HexView对比,结果一致,说明我们解析没问题

🌎总结

- 🚩要有最朴素的生活,最遥远的梦想,即使明天天寒地冻,路遥马亡!
- 🚩如果这篇博客对你有帮助,请 “点赞” “评论”“收藏”一键三连 哦!码字不易,大家的支持就是我坚持下去的动力。