近日,中国信通院联合上海人工智能实验室成立的大模型测试验证与协同创新中心牵头,首次面向全国范围征集全行业优秀应用实践,并形成《2023大模型落地应用案例集》(以下简称“《案例集》”)。

《案例集》一共119页pdf,作为首部聚焦落地应用的权威研究成果,全面展示了大模型前沿技术和发展成果,推动了大模型为代表的人工智能技术赋能社会经济高质量发展。经专家组的多轮评审,共52个各自领域的典型大模型技术落地应用成功入选。


2022年底ChatGPT的横空出世,引爆了国内外大模型的热情,各行各业的创业者已经集结在十字路口蓄势待发。从国内市场来看,目前人工智能(AI)大模型已经在各行各业“落子不断”。据公开资料不完全统计显示,国内大模型的发展路径是“通用+垂直”两条腿走路,其中垂类大模型落地速度最快。《案例集》显示,有近65%+的AI大模型是垂直大模型。
趋势已然,大模型技术突破代表了AI发展的一个重要里程碑,下面笔者将梳理中国从业者构建的“底层原创技术-中层基础模型-上层行业应用”的大模型图鉴。

如何获取本案例集的PDF?
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

PART 1 大模型领域中国学者的技术贡献
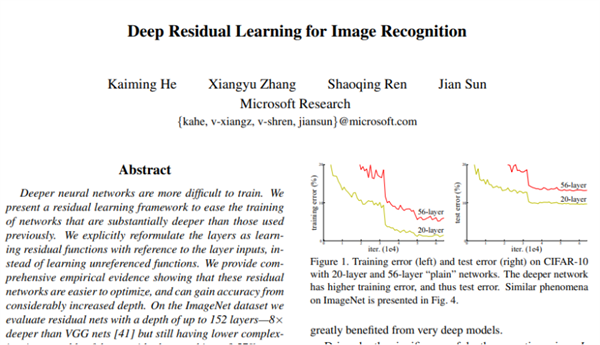 图注:ResNet的四位作者分别是:何恺明、张祥雨、任少卿、孙剑。
图注:ResNet的四位作者分别是:何恺明、张祥雨、任少卿、孙剑。
2016年,来自微软亚洲研究院的四位学者提出深度残差学习(ResNet),解决了深度网络的梯度传递问题。
要知道,2015年之前深度学习最多只能训练20层,ResNet之后,就可以有效地训练超过百层的深度神经网络。

2017年Google发布Transformer,它的出现打稳了AI大模型的“地基”,不仅“颠覆”了自然语言处理(NLP)中的机器翻译任务,而且还提供了一种新的思路来处理图像数据。
中国学者也围绕Transformer做了许多改进和完善,例如微软亚洲研究院联合西安交通大学推出LONGNET,将Transformer的序列长度扩展10亿+;京东探索研究院联合武汉大学提出全球首个面向遥感任务设计的亿级视觉Transformer大模型;阿里达摩院提出新的Transformer结构FMViT,大幅度提升AI模型精度与速度。
在大模型领域细数中国学者贡献,许多原创性贡献来自本土。已故的商汤科技创始人汤晓鸥(缅怀)在2023世界人工智能大会上,发表演讲时表示:在深度学习的大门上,我们按了18次门铃,取得了许多跨时代的突破。
其中汤晓鸥提到了上海人工智能实验室领军科学家林达华,他当时设计的计算机视觉开源算法体系OpenMMLab,目前已经成为国际上最具影响力的视觉算法开源体系。值得一提的是,林达华也是书生大模型体系的重要贡献者。
京东探索研究院早在2021年年初就展开了大模型体系(超级深度学习)的建设和基础研究,领导京东建设了中国第一个NVIDIA DGX Superpod天琴alpha-α超算集群。
在此基础上,京东探索研究院的织女模型vega v2在2022年登顶SuperGLUE榜首,一举超越同场竞技的谷歌、微软、Meta等业界顶尖企业;
2021年研究院开发的大规模视觉模型ViTAE,在ImageNet Real的目标识别和MS COCO的人体姿态估计等权威榜单上均获得世界第一。
PART 2 大模型应用拐点已至
图灵奖获得者Yann LeCun说过:AI大模型的技术都是公开的,算不上底层技术上的创新,如果你愿意一探究竟的话,可以发现它背后没有任何秘密可言。但借着这些“过时”的技术,在中国拥有庞大的人才基数和数据集的情况下,可以发展出更适合本土环境和语境的大模型。
那么如何形象理解大模型?前科技部长王志刚从高维度表示,大模型,就是大数据、大算力、强算法。形象一些:大模型事实上就是算法、数据、算力上的有效结合。传统巨头在大模型领域的技术投入普遍都是在积极防御,而中国企业在非常积极地推动向应用中的落地。
目前,业界除了把AI大模型商业落地模式统分为toB和toC之外,在市场划分上则遵循通用与垂直两大路径,两者在参数级别、应用场景等方面差异正在显性化。通用大模型往往是指具备处理多种不同类型任务的AI模型,这些模型通常是通过大规模的数据训练而成,能够在多个领域和应用中表现出良好的效能。大家耳熟能详的几个通用大模型均来自财力雄厚的企业。
PART 3: 抢滩大模型未来:构建生态
对于AI大模型这种划时代的超级机遇而言,胜负不在于做出一个爆款应用,赚到几亿盈利,而在于是否抓到了大时代的方向。换句话说,当下的大模型竞争早已超过了技术的范畴,更多是一种生态层面的比拼,具体表现在有多少应用、有多少插件、有多少开发者以及用户等。谁能够率先围绕大模型构建生态,或者说谁率先融入生态,谁就能成为领先者。大模型要想像电力一样输送给千行百业和千家万户,必然需要一个体系化的产业生态,构建这个生态需要一系列相互关联的因素,包括技术发展、应用场景、数据管理、伦理与法律问题、以及社会影响等。
在生态建构的路径上,目前企业可分为两派。一派将大模型接入原有的产品线,做升级和优化;另一派试图以大模型产品为中心,建构新一代的“超级应用”。
而有些企业试图跳过这两种路径,多方面融入AI大模型生态。从《案例集》公布的大模型服务类案例,我们可以看到有些中国企业做了以下尝试:例如蚂蚁集团实现了一个大模型数据高效高质量供给平台,不仅可降低数据获取和使用成本,且保证来源合规,并能够有效提升数据质量、过滤风险数据保障训练安全;优刻得开发的AGI云上模型服务平台,能提供数据标准化整合、安全合规、提供算力等服务;上海道客研发的云原生大模型知识库平台能够帮助解决信息孤岛,以及定制个性化的私人语料库;泡泡玛特的AI整合平台集成多个知名AI大模型,为用户提供一站式AI服务。这些大模型服务工具,在一定程度上能有效地解决“幻觉”、“道德”、“性能”、“数据合规”等当前AI大模型遇到的问题。更重要的是借助这些服务,可以建设规范可控的自主工具链,帮助AI企业探索“大而强”的通用模型,助力公司研发“小而美”的垂直行业模型,从而构建基础大模型和专业小模型交互共生、迭代进化的良好生态。
如何获取本案例集的PDF?
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓




![[Diffusion Model笔记] DDPM数学推导版 2024.04.23](https://img-blog.csdnimg.cn/direct/98e2bd2cc76b4d6bb5c3ddafc7eb96d3.png)