概述:
什么是链表?
1、链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,有一系列结点(地址)组成,结点可动态的生成。
2、结点包括两个部分:
(1)存储数据元素的数据域(内存空间)。
(2)存储指向下一个结点地址的指针域。
(3) 相对于线性表顺序结构,操作复杂。
链表的分类:
链表的结构非常多样,以下的情况组合起来就有8种链表结构
(1)单向和双向。
(2)有头和无头。
(3)循环和不循环。
虽然说链表有这么多类型,但是掌握了其中一个,掌握链表的核心思路,其他的也就自然会了,我们这里列举的是单向链表。
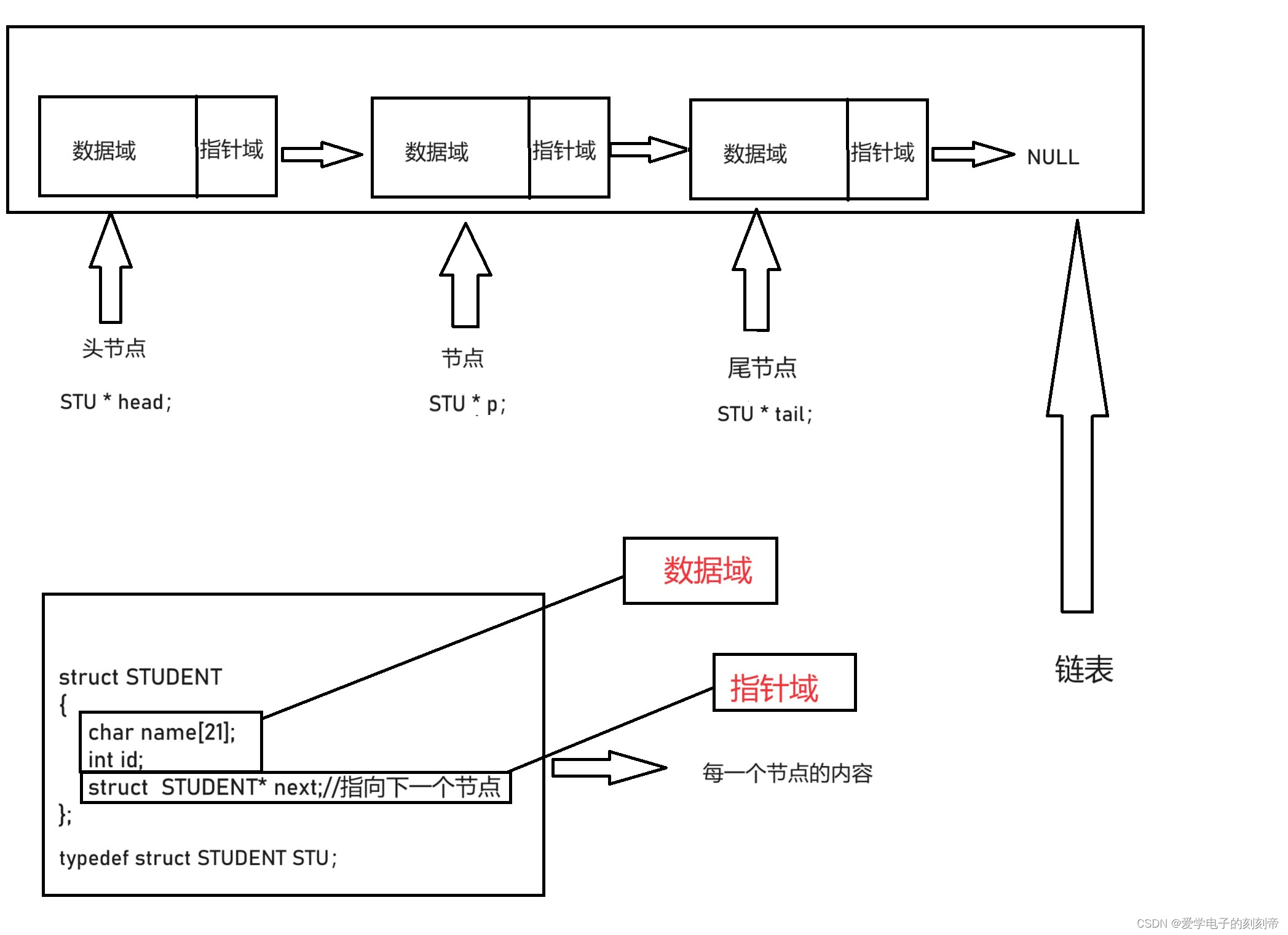
链表操作函数:
这里列举几个链表的操作函数:
我们先定义相应的结构体,用来表示链表里面的节点。
//定义结构体,结构体里面的内容相当于链表里面的节点
struct STUDENT
{char name[21];int id;struct STUDENT* next;//指向下一个节点
};typedef struct STUDENT STU;//方便以后定义结构体,直接用STU就可以代替struct STUDENTSTU* p, * head, * tail;//head:用于指向链表的头部,tai:用于指向链表的尾部,p:用来指向每次创建的新节点1、 链表里面加入新的节点:
/*链表里加入新的节点*/void add_new_joint(struct STUDENT ** p_head, struct STUDENT* p_new)//这里必须用二级指针
{//p_new指向需要加入的节点struct STUDENT* p_mov = *p_head;if (*p_head == NULL)//如果这个链表为空,加入的节点作为链表的头节点{*p_head = p_new;p_new->next = NULL;}else//链表不是空的,把他加在链表最后面{while (p_mov->next != NULL){p_mov = p_mov->next;//找到原有列表最后的一个节点}p_mov->next = p_new;p_new->next = NULL;//把他加入到链表的最后}
}2、链表的遍历:
void print_joints(struct STUDENT * head)//这里只需要用一级指针
{struct STUDENT* p_mov = head;//定义新的指针保存链表的首地址while (p_mov!= NULL)//遍历到最后一个节点{printf("name:%s id:%d\n",p_mov->name,p_mov->id);p_mov = p_mov->next;}
}3、链表的释放:
/*链表的释放*/
void link_free(struct STUDENT ** p_head)//把整个链表给释放
{struct STUDENT * p_mov=*p_head;if (*p_head == NULL)//如果这个链表本身为空,就不需要释放{printf("不是哥们,空的,释放什么啊\n");}while (*p_head!= NULL){p_mov = *p_head;//设置p_mov是为了删掉前面的节点,*p_head保存下一个节点的位置*p_head = (*p_head)->next;free(p_mov);//释放掉节点的内存p_mov = NULL;//实际上这句是无效的,只是为告诉你需要把头指针变回null,免得野指针}
}4、链表的查找,这里是找到对应的学生;
/*链表节点的查找,找人*/
struct STUDENT * link_search_student(struct STUDENT* head, char *name)
{struct STUDENT* p_mov = head;while (!strcmp(p_mov->name, name)&&(p_mov->next != NULL))//设置p_mov是为了去遍历整个链表,去找人{p_mov = p_mov->next;}if (strcmp(p_mov->name, name))//是找到人而退出循环{printf("这个人找到了,学号是:%d\n", p_mov->id);return p_mov;}else//找到底都找不到人而退出循环{printf("老弟,找不到这个人\n");return NULL;}
}
5、链表节点的删除,这里是找到对应的学生删除:
/*链表节点的删除*/
void link_delete_student(struct STUDENT** p_head, char* name)
{struct STUDENT* pb = *p_head;//用来遍历整个链表struct STUDENT* pf = *p_head;//用来报保存上一个节点if (*p_head == NULL){printf("空的,不用删\n");}while ((pb->next != NULL) && (!strcmp(pb->name, name))){pf = pb;pb = pb->next;}if (strcmp(pb->name, name))//是因为找到而退出循环{if (pb == *p_head)//如果删的是头部{//(*p_head)->next = *p_head;一样的效果*p_head = pb->next;}else//删的不是头部{//因为删除节点,只要把上一个节点的next指向需要删除节点的后一个节点,所以要多去创建一个pf指向前一个节点pf->next = pb->next;}free(pb);//释放掉需要删除的节点pb = NULL;//实质上是无效的,只是为告诉你需要把删除节点的指针变回null,免得野指针}else{printf("没有您要删除的节点\n");}
}
6、链表中插入一个节点,这里是插入学号,从小到大排序:
/*链表中插入一个节点*/
void link_insert_num(struct STUDENT** p_head, struct STUDENT* p_new)//插入学号为4的同学,按学号顺序插入,0 1 2 3 5 -> 0 1 2 3 4 5
{struct STUDENT* pb=*p_head;//pb用来遍历链表,指向插入节点的下一个节点struct STUDENT* pf = *p_head;//存放目标节点的上一个节点if (*p_head == NULL)// 链表为空链表{*p_head = p_new;p_new->next = NULL;return;}while ((pb->next != NULL) && (pb->id > p_new->id))//插入成功退出或者插入到底都插入不进去{pf = pb;pb = pb->next;}if (pb->id > p_new->id)//成功插入{if (pb=*p_head)//插入的是头节点,他变成头节点{p_new->next = *p_head;*p_head = p_new;}else//插入的不是头节点{//插入就是把需要插入的节点的next指向后一个节点,上一个节点的next指向当前插入的节点//pb插入节点的下一个节点//所以需要上一个节点pfpf->next = p_new;p_new->next = pb;}}else//插入失败,只能给她丢在后面了{pb->next = p_new;p_new->next = NULL;}
}
调用函数:
在创建以上几个链表的操作函数,就可以把他们调用到main函数里面了。这里只举一个例子,其他读者可以自己去尝试。
创建一个节点,输入内容,把节点放在链表里面,然后遍历链表,把他们在全部输出出来。
int main()
{int i;for (i = 0; i < 2; i++){p = (struct STUDENT*)malloc(sizeof(struct STUDENT));printf("请输入名字和学号\n"); scanf("%s %d",&p->name,&p->id);add_new_joint(&head,p); //将新节点加入链表}joints_print(head);return 0;
}到这里链表基础知识就讲完了,这只是基础,只有掌握基础之后,读者才能继续深入学习,切记,代码不是拿来看的,要去自己敲出来,画图理解,才能熟练掌握,包括我自己也是,我还需要后续去进行学习,做到真正掌握链表。