什么是 FastGPT ?
FastGPT是一个基于LLM大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过Flow可视化进行工作流编排,从而实现复杂的问答场景!
FastGPT 允许用户构建本地知识库,以提高 AI 的理解能力和应用场景的适应性。该系统的设计旨在让 AI 更好地理解用户需求并提供更准确的回答。
FastGPT 功能演示
本文假设你已经安装了 One API 和 M3E,如果还没有的话,建议你先阅读👇两篇
文章传送门:
- 大模型接口管理和分发系统One API
- 开源文本嵌入模型M3E
安装
在群晖上以 Docker 方式安装。
config.json
由于环境变量不利于配置复杂的内容,新版 FastGPT 采用了 ConfigMap 的形式挂载配置文件 config.json
这个配置文件中包含了系统参数和各个模型配置,使用时务必去掉注释!!!!!!!!!!!!!!
源文件的地址在这里👇:https://doc.fastai.site/docs/development/configuration/
老苏修改后的完整的config.json放在了这里👇:
https://raw.githubusercontent.com/wbsu2003/synology/main/FastGPT/config.json
llmModels
之前尝试过私有化部署的 LLM Models,在老苏的小机器上除了 Qwen:0.5b外,其他基本上都跑不动,所以这次尝试是用 Moonshot AI,其可用的模型包括 moonshot-v1-8k 、 moonshot-v1-32k 和 moonshot-v1-128k
vectorModels
FastGPT 默认使用了 openai 的 embedding 向量模型
"vectorModels": [{"model": "text-embedding-ada-002", // 模型名(与OneAPI对应)"name": "Embedding-2", // 模型展示名"avatar": "/imgs/model/openai.svg", // logo"charsPointsPrice": 0, // n积分/1k token"defaultToken": 700, // 默认文本分割时候的 token"maxToken": 3000, // 最大 token"weight": 100, // 优先训练权重"defaultConfig":{}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)"queryConfig": {} // 参训时的额外参数}],
老苏改用了 M3E 向量模型进行替换
"vectorModels": [{"model": "m3e","name": "M3E","price": 0.1,"defaultToken": 500,"maxToken": 1800}],
docker-compose.yml
下面的内容基于官方的 docker-compose.yml 修改而成,因为包含了中文注释,所以记得用 UTF-8 编码
源文件地址:https://github.com/labring/FastGPT/blob/main/files/deploy/fastgpt/docker-compose.yml
version: '3.3'services:pg:image: ankane/pgvector:v0.5.0 # git#image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.5.0 # 阿里云container_name: fastgpt-pgrestart: always#ports:# - 5432:5432volumes:- ./pdata:/var/lib/postgresql/dataenvironment:# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果- POSTGRES_USER=username- POSTGRES_PASSWORD=password- POSTGRES_DB=postgresmongo:image: mongo:5.0.18#image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18container_name: fastgpt-mongorestart: always#ports:# - 27017:27017volumes:- ./mdata:/data/dbenvironment:- MONGO_INITDB_ROOT_USERNAME=myusername- MONGO_INITDB_ROOT_PASSWORD=mypasswordcommand: mongod --keyFile /data/mongodb.key --replSet rs0entrypoint:- bash- -c- |openssl rand -base64 128 > /data/mongodb.keychmod 400 /data/mongodb.keychown 999:999 /data/mongodb.keyecho 'const isInited = rs.status().ok === 1if(!isInited){rs.initiate({_id: "rs0",members: [{ _id: 0, host: "mongo:27017" }]})}' > /data/initReplicaSet.js# 启动MongoDB服务exec docker-entrypoint.sh "$$@" &# 等待MongoDB服务启动until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; doecho "Waiting for MongoDB to start..."sleep 2done# 执行初始化副本集的脚本mongo -u myusername -p mypassword --authenticationDatabase admin /data/initReplicaSet.js# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程wait $$!fastgpt:image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.7 # git#image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.7 # 阿里云container_name: fastgpt-webrestart: alwaysdepends_on:- mongo- pgports:- 3155:3000volumes:- ./config.json:/app/data/config.json- ./tmp:/app/tmpenvironment:# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。- DEFAULT_ROOT_PSW=1234# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。- OPENAI_BASE_URL=http://192.168.0.197:3033/v1# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)- CHAT_API_KEY=sk-bn6M52bOfdxYB3n2Ee717eA2C66b45318f1c95E4D9553d94# 数据库最大连接数- DB_MAX_LINK=30# 登录凭证密钥- TOKEN_KEY=any# root的密钥,常用于升级时候的初始化请求- ROOT_KEY=root_key# 文件阅读加密- FILE_TOKEN_KEY=filetoken# MongoDB 连接参数. 用户名myusername,密码mypassword。- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin# pg 连接参数- PG_URL=postgresql://username:password@pg:5432/postgres
docker-compose.yml 可以在这里下载☞,https://raw.githubusercontent.com/wbsu2003/synology/main/FastGPT/docker-compose.yml
然后执行下面的命令
# 新建文件夹 fastgpt 和 子目录
mkdir -p /volume1/docker/fastgpt/{pg,mongo,tmp}# 进入 fastgpt 目录
cd /volume1/docker/fastgpt# 将 docker-compose.yml 放入当前目录# 一键启动
docker-compose up -d# 如果修改了 config.sys 文件,需要重启 FastGPT
docker-compose down
docker-compose up -d
运行
在浏览器中输入 http://群晖IP:3155 就能看到登录界面
如果你没有更改默认配置,那么用户名便是
root,密码为1234

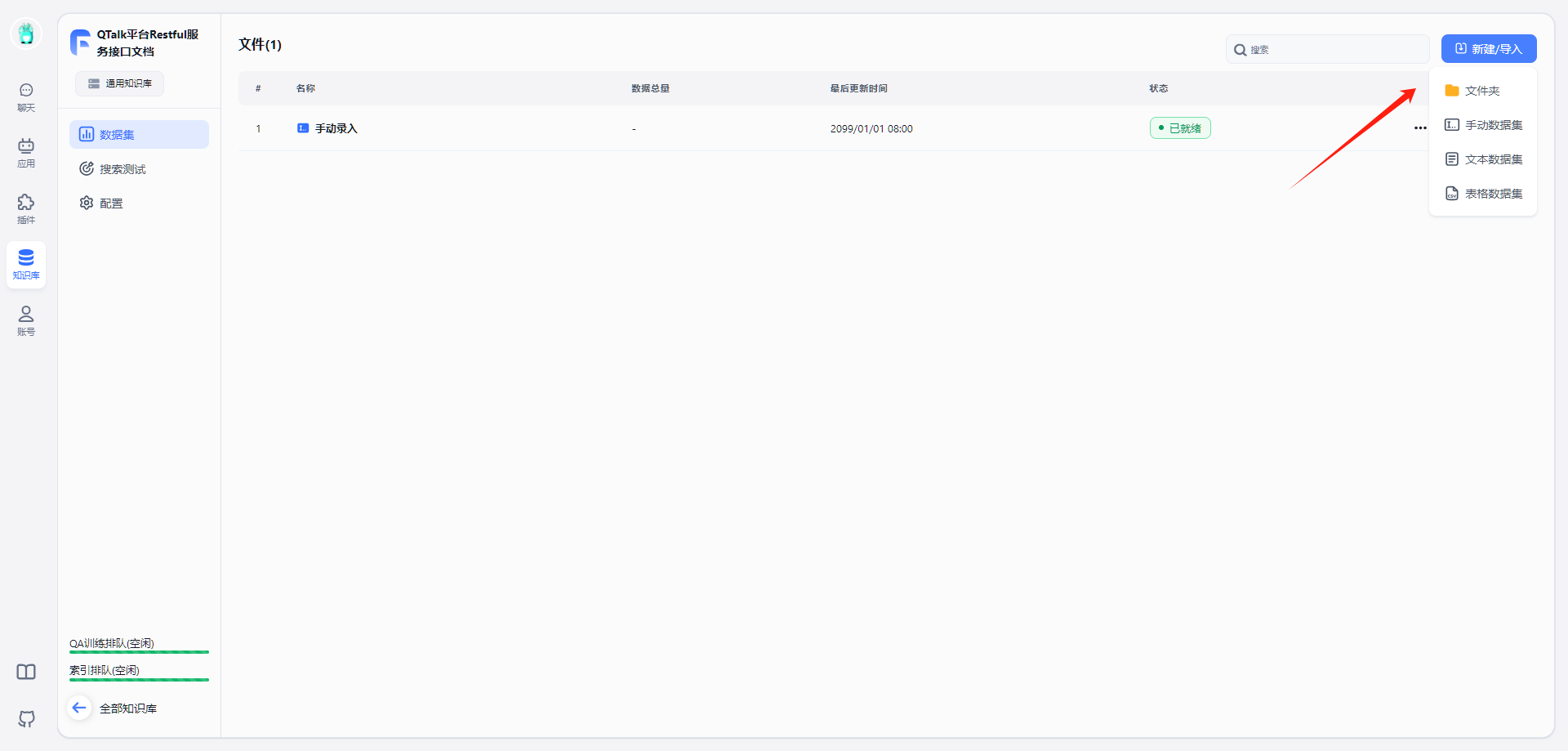
新建知识库
首先需要新建一个知识库

取个名字

选择 文本数据集
来源选择 本地文件
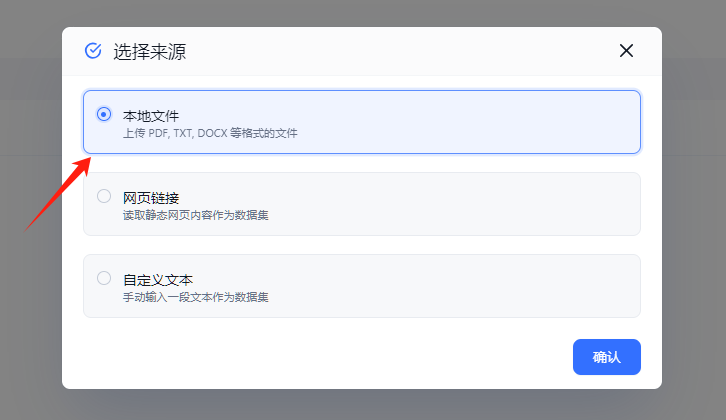
将文件拖入

上传了一个 pdf

直接用了默认设置

开始上传

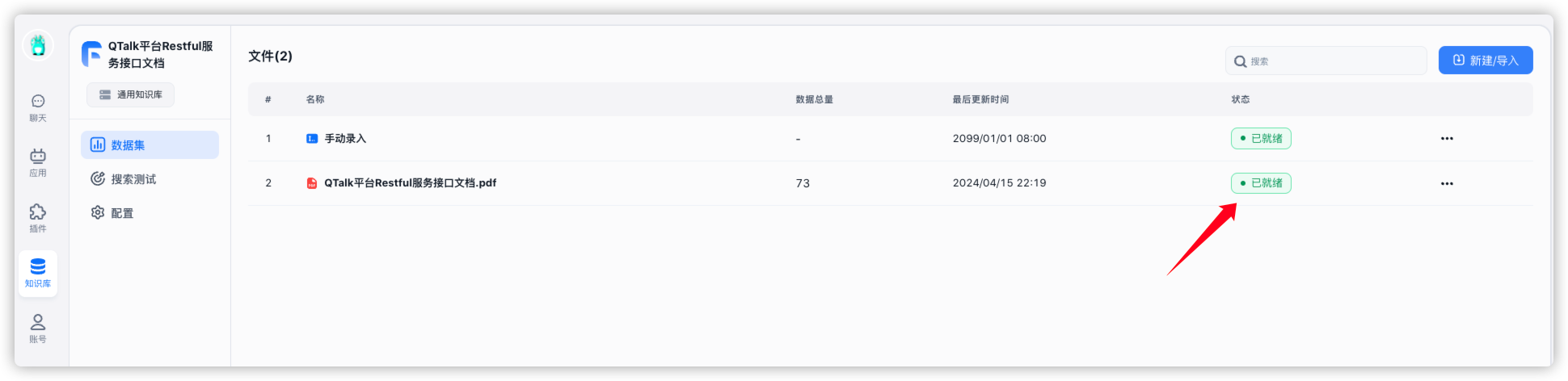
多了一个数据集

等状态变成 已就绪 就可以开始建应用了
当然这个过程也很消耗资源,小机器死机了一次,好在最后还是索引成功了
可以测试下搜索

新建应用
新建一个应用

模板选择了 知识库+对话引导
进入 简易配置,关联知识库

也可以进入 高级编排
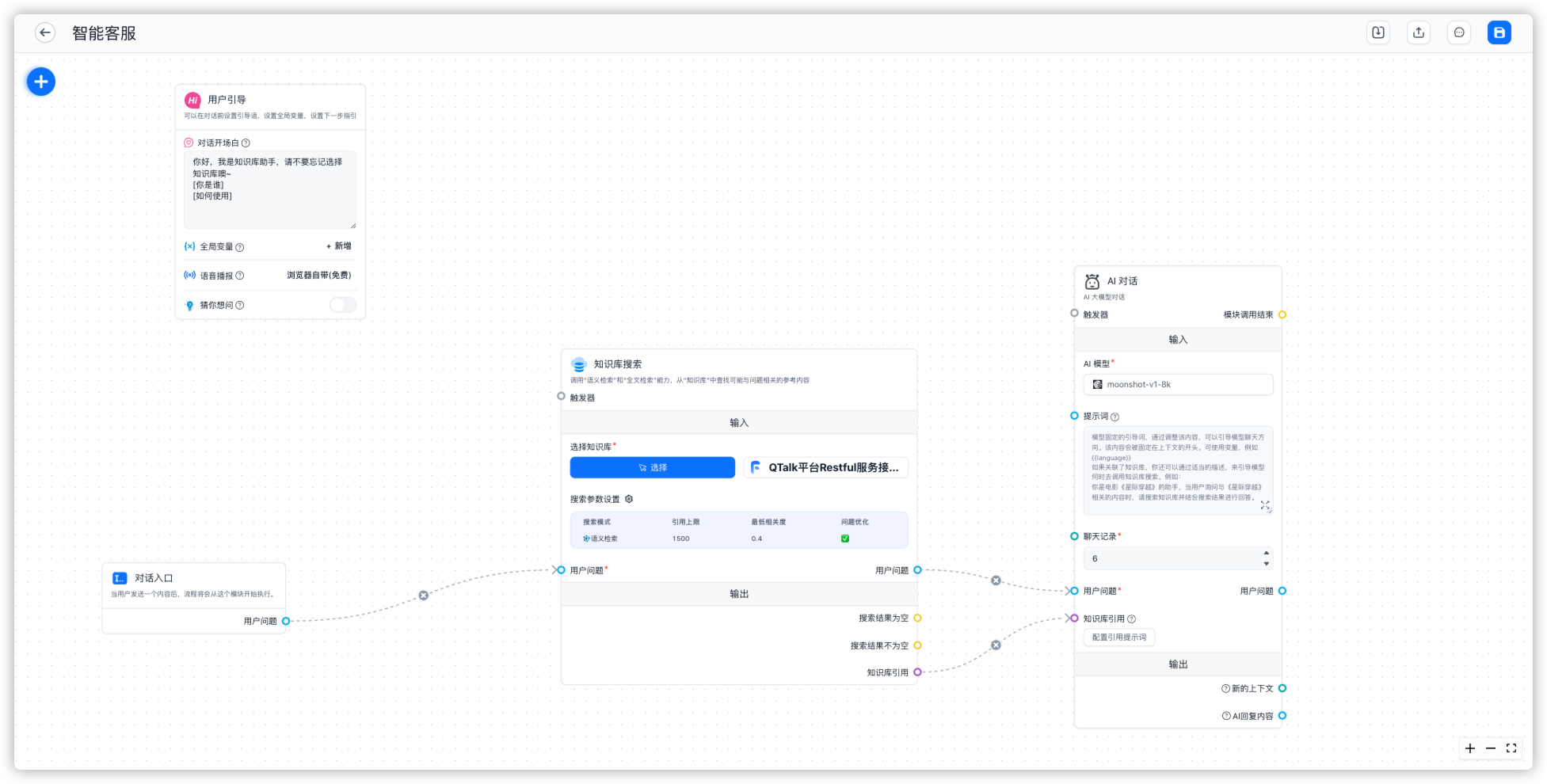
这里已经可以开始调试了

再来一条

没问题的话就可以保存、发布了
开始聊天
进入 聊天

相关接口的开发问题随便问,这给客服工作省了多大的事啊

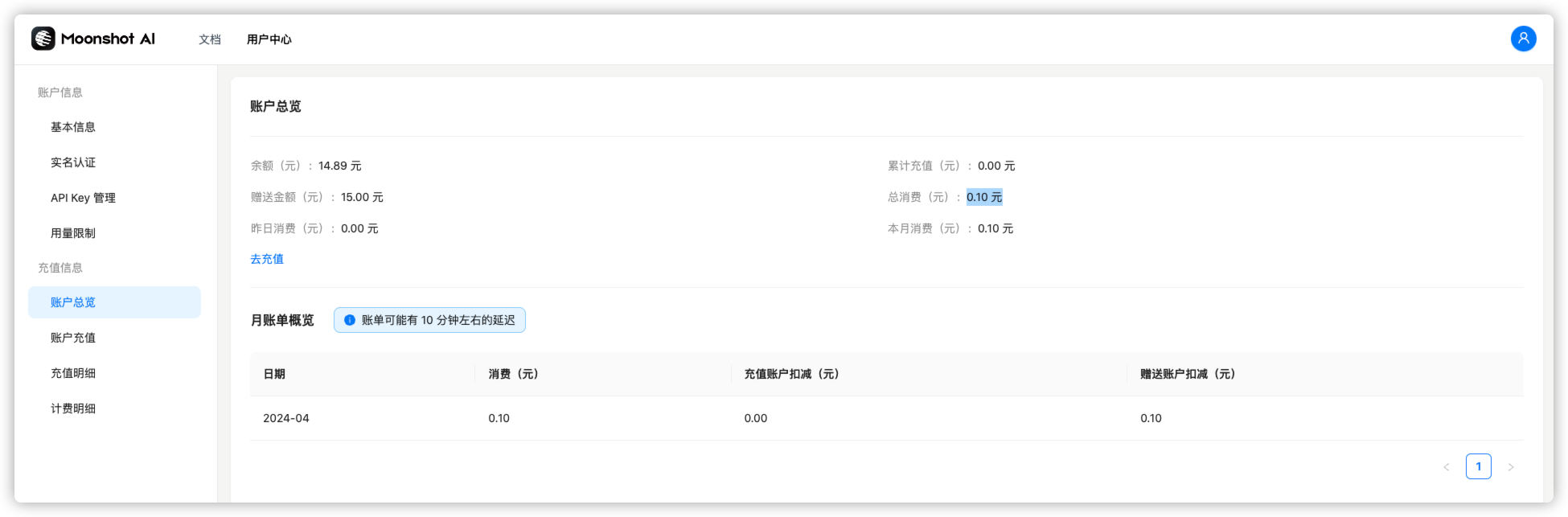
看看 Moonshot AI 赠送的 15块 还剩下多少?
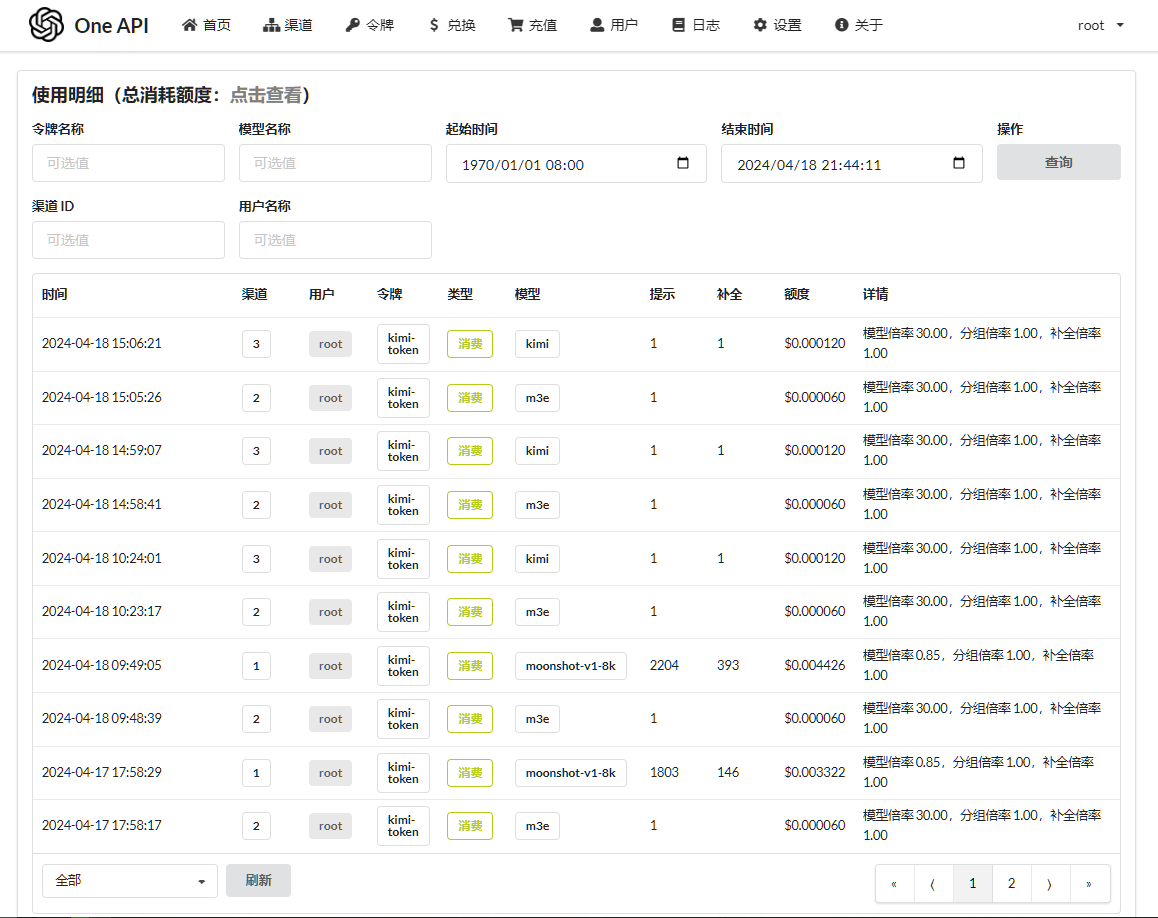
所有的请求,在 One API 的日志中都有记录
FastGPT 是支持纯本地私有化部署的,但老苏考虑了自己小机器的性能,采用了混合部署的方式,其中向量模型采用了本地私有化部署,而 LLM 模型则使用了云服务
流程跑通了,接下来就是优化了,比如 标记预期答案 等

当然,你还可以将 FastGPT 通过 OpenAPI 接口,被第三方应用调用,可以是全局 API key(可操作 FastGPT 上的相关服务和资源,无法直接调用应用对话)
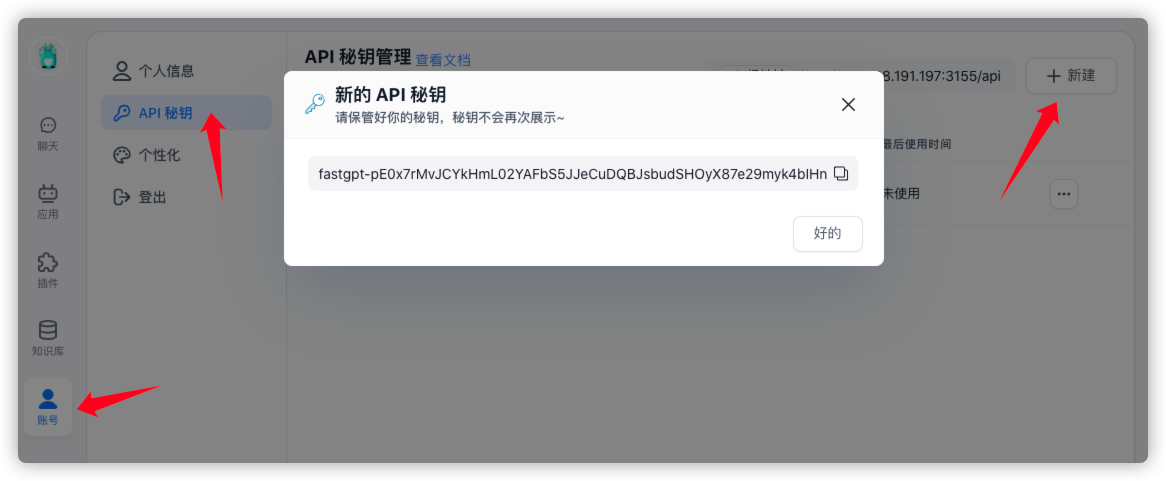
也可以是应用 API key(可直接调用应用对话)

参考文档
labring/FastGPT: FastGPT is a knowledge-based platform built on the LLM, offers out-of-the-box data processing and model invocation capabilities, allows for workflow orchestration through Flow visualization!
地址:https://github.com/labring/FastGPT
FastGPT
地址:https://fastgpt.in/
快速了解 FastGPT | FastGPT
地址:https://doc.fastai.site/docs/intro/