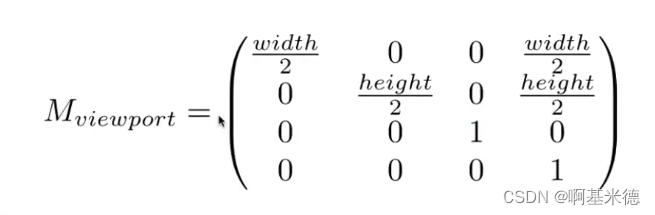系列文章链接
论文一:2020 Informer:长时序数据预测
论文二:2021 Autoformer:长序列数据预测
论文三:2022 FEDformer:长序列数据预测
论文四:2022 Non-Stationary Transformers:非平稳性时序预测
论文五:2022 Pyraformer:基于金字塔图结构的时序预测
论文六:2023 Crossformer:多变量时序预测
论文七:2023 LSFT-Linear:质疑transformer能力的线性预测模型
论文链接:https://arxiv.org/abs/2106.13008
github链接:https://github.com/thuml/Autoformer
解读参考:https://zhuanlan.zhihu.com/p/386955393
视频解读:https://www.bilibili.com/video/BV1kb4y1s7iA/?spm_id_from=333.337.search-card.all.click&vd_source=c912801c215d811162cae4db751b0768
清华大学吴海旭的论文(时间序列领域前沿论文制造机,实验室公众号搜索:THUML),考虑到的背景问题有以下几点:
- 原始时序数据中的依赖关系难以提取;
- 对于长时序数据而言,transformer计算的二次计算复杂度过高;
- 前人提出的Informer模型虽然降低了复杂度,但是存在原始信息的丢失;
基于对时序数据分解和序列周期性分布特性的理解,本文主要有以下几个创新点:

- 序列分解模块(Series Decomposition Block):传统的时间序列分解可以获取时序数据的季节性(seasonal)、趋势(trend)等分布特性,这种对于时序数据而言其实是十分重要的特性;因此本文基于此思想,提出了一种时间序列分解的思想,具体计算如下: X t = A v g P o o l ( P a d d i n g ( X ) ) X_t=AvgPool(Padding(X)) Xt=AvgPool(Padding(X)) X s = X − X t X_s=X-X_t Xs=X−Xt其中采用Padding来保证序列的维度一致性,然后通过平均池化可以得到时序数据的趋势分布向量 X t X_t Xt,用原向量 X X X减去趋势向量可以得到具有季节性分布特性的向量 X s X_s Xs;
- 自相关机制(Auto Correlation Mechanism):采用自相关系数计算找到与当前子序列关联性更大的序列用于指导预测数据生成;当序列的相似性越高时,滞后相乘的自相关系数就会越大,计算如下: R x x ( T ) = l i m L − > ∞ 1 L ∑ L X X T i = 1 R_{xx}(T)=\underset {L->\infty}{lim}\frac{1}{L}\underset{i=1}{\sum^LXX_T} Rxx(T)=L−>∞limL1i=1∑LXXT其中T表示滞后间隔的设定, X X X表示原始时序数据, X T X_T XT表示滞后时时序数据。

基于这种思想,就可以针对时序数据计算在不同步长的情况下,对应的自相关系数,得到一个自相关系数向量(选取TopK个自相关很强的自相关序列),再通过softmax函数将向量转换成对应的概率分布向量,作为权重分布;本文用Auto-Correlation替代transformer中的self-attention的计算过程;为了加速计算,采用快速傅立叶FFT运算去找到最合理的滞后步长选择,能够快速得到合理的TopK自相关向量的计算;
在本文的Encoder中,更注重关注时序数据的季节性特性,因此保留的数据都是经分解后的季节性数据;在Decoder中,会将分解后的季节性、趋势性时序都作为输入,并且将原始序列的部分数据拼接在初始位置,用于指导后续序列的预测,网络具体运算细节可以参考原文;