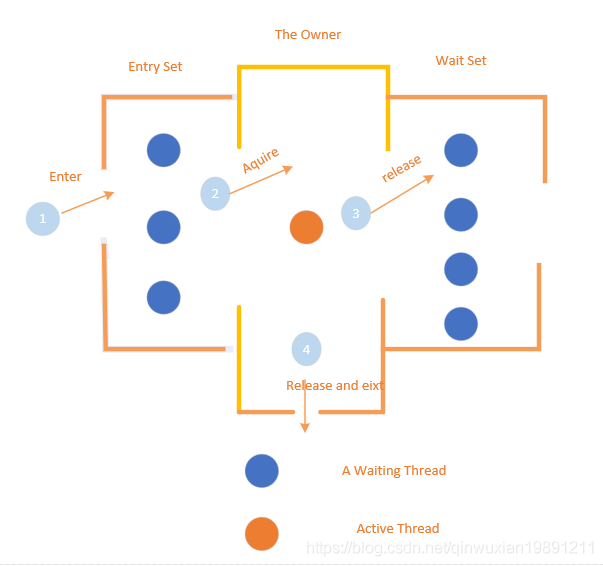
【前言】
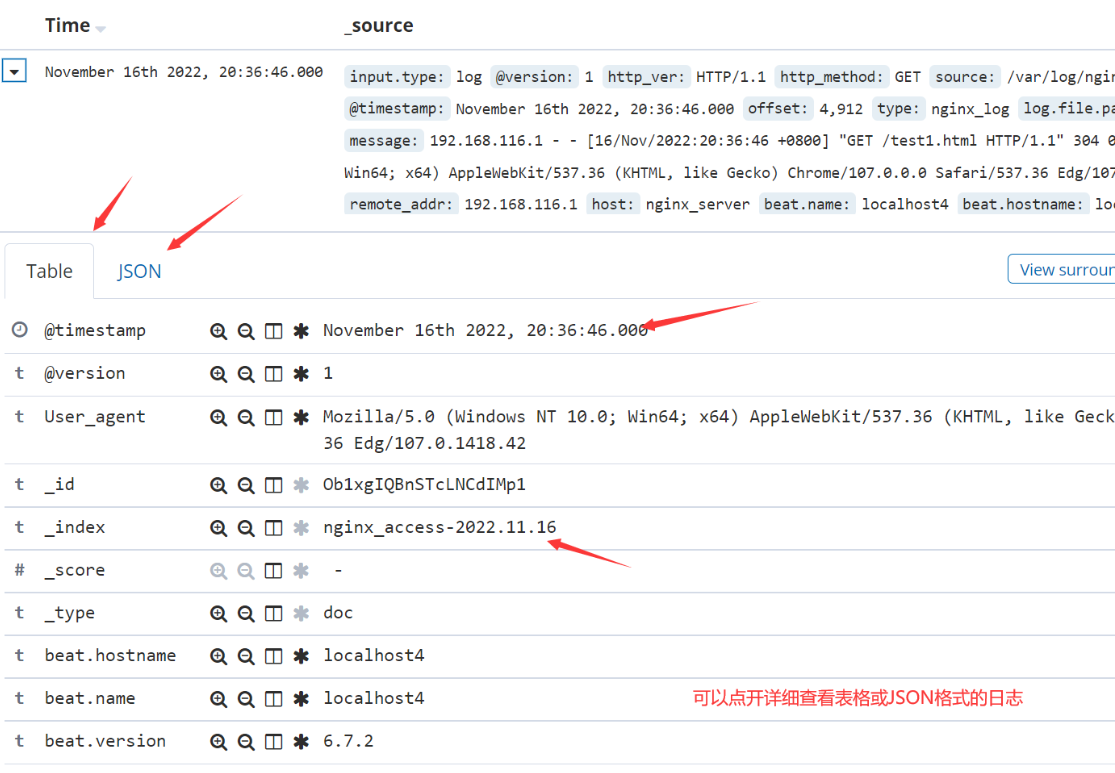
我们知道计算机上只会存储二进制的数据,无论文本、图片、音频、视频等,当我们将其保存在计算机上时,都会被转成二进制的。我们打开查看的时候,二进制数据又被转成我们看得懂的信息。如何将计算机上的二进制数据转为我们看得懂的文本、图片等,就涉及到编码规则,即二进制数据与我们看的懂的信息之间的映射关系。我们这里讨论的是文本编码规则,有ANSI、ASCII、UTF-8、Unicode等。
【ASCII】
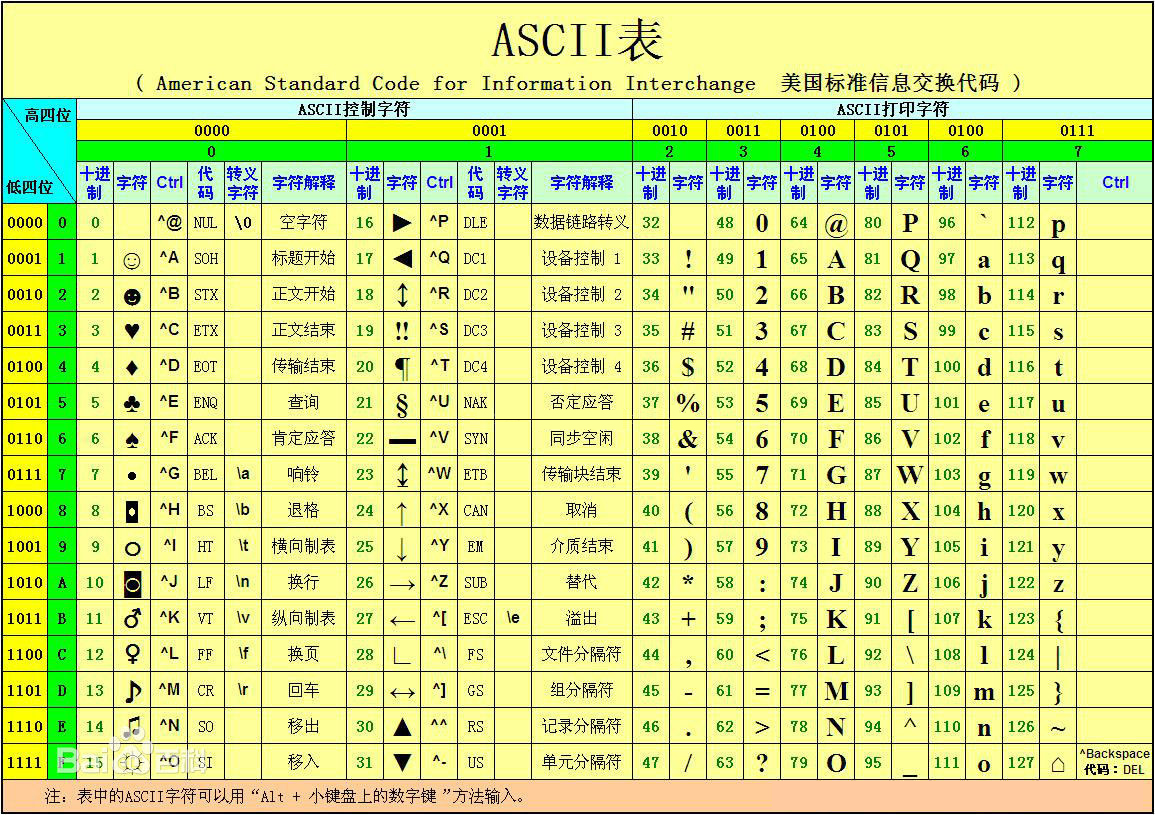
ASCII是编程首先会接触到的,其全名是American Standard Code for Information Interchange, 叫做“美国信息交换标准码”。现代计算机技术是从英文国家兴起的,最初的文本的内容只涉及26个英文、10个数字,一些行业常用字符等,加起来凑一凑到了128个。128个字符的集合就是ASCII字符集。128个在二进制中就需要7bit来区分。但计算机中最低要一个字节,即8bit。因此ASCII的最高位为0,空着不用。ASCII码中,一个英文字母占一个字节的空间。
【ANSI】
随着计算机发展到其他国家,各个国家也需要有各自的字符集,在创建自己国家语言的字符集时必须要兼容已有的ASCII字符集。
有些国家的语言字符很少,不到128个,例如拉丁文,就直接把ASCII编码中没用到的最高位用上。
但对汉字来说,常用汉字有六千多个,再加上中文相关的图形字符等,这就需要两个字节来表示。
两个字节最多可以存储的字符数目是2的16次方,即65536个字符,足够其他语言使用了。同样的,对于韩文、日文也需要两个字节表示。
对于ASCII字符集中的字符仍然用一个字节表示,对于其他语言的字符用两个字节表示。例如在中文的GB2312的表示中,如果一个字节的最高位为0,表示这个字节是ASCII编码,如果最高位为1,那么表示其是双字节编码的首字节,与后面的一个字节一块进行编码。这就是ANSI字符集,其是对ASCII字符集的拓展。
在中文操作系统下,ANSI字符集的编码规则是GB2312;在日文操作系统下,编码规则是JIS。
GB2312编码中只收集了常用的汉字,没有生僻字,后来的GBK和GB18030收集了更多的字符。
【Unicode】
Ansi字符集的问题是如果一个文本是GBK编码的,那么在日文操作系统上无法正确显示中文,看到的会是乱码。因此,需要一个包含所有国家所有字符的字符集,这个字符集就是Unicode字符集。
其目前已经包括了十多万个字符,还在不断增加中。此时用3个字节建立映射关系就够了,但是计算机中没有24位的数字类型,所有还是要用4个字节来表示。
在Unicode中所有字符都用4个字节表示,UTF-32编码刚好用4个字节表示。
UTF-16编码是变长编码,前65536个字符用两个字节表示,其他字符用四个字节表示。通过判断一个字节的前几位是否为“11011”来区分一个字符使用两个字节,还是四个字节表示。
对于英文字母来说,其由最初的一个字节变成了UTF-32编码的4个字节和UTF-16编码的两个字节,还是存在空间浪费,采用UTF-8编码可以有效节省空间,其也是变长编码。
如果读取的一个字节的首位为0,表示这个字节有个对应的字符;如果读取的一个字节的首位为1,接着判断下一个bit,依次判断得到的结果为110,那么表示这个字节和解析来的字节一起有个对应的字符。依次类推,首个字节中前几位为1110,表示3个字节对应一个字符,11110表示4个字节对应一个字符,如下图所示。

【其他】
一般来说UTF-8应用是最广泛的。在C#中,文本默认是UTF-16编码,一个字符对应两个字节。(一个字符对应四个字节的情况在中英文语况很少遇到)。而在C++中默认是ANSI编码的。
从C++传递字符串给C#,如果字符串全是英文,可以直接传给C#,因为UTF-16兼容ANSI中的英文编码。如果是字符串中包含有中文,则在C#端就无法正确识别。需要先将字符串转成字节序列(即字节数组),再将ANSI字节序列转成Unicode字节序列,再将Unicode字节序列转成UTF-16或UTF-8编码的字符串。
注意,代码文件也是文本文件,也会有编码格式的问题,在VS中选择文件->高级保存选项可以修改代码文件的编码格式。
【参考】
ASCII码和ANSI码的区别_ansi ascii_斑驳的岁月的博客-CSDN博客
程序员必备:彻底弄懂常见的7种中文字符编码 - 知乎 (zhihu.com)
Unicode 编码及 UTF-32, UTF-16 和 UTF-8 - 知乎