进位制与字符串专题
目录
- MT2179 01操作
- MT2182 新十六进制
- MT2172 萨卡兹人
- MT2173 回文串等级
- MT2175 五彩斑斓的串
MT2179 01操作
难度:黄金 时间限制:1秒 占用内存:128M
题目描述
刚学二进制的小码哥对加减乘除还不熟,他希望你帮他复习操作。
对于二进制数有如下几个操作:
- 整个二进制数加1;
- 整个二进制数减1;
- 整个二进制数乘2;
- 整个二进制数除2。
(本题不会导致最高位进退位,即若全是1,之后操作加1的情况不会出现)以上的操作是二进制数的对应操作,乘2或除2会导致进退位。
格式
输入格式:第一行两个正整数 n , m n,m n,m ,表示二进制数长度和操作数;
接下来一行一个二进制数;
第三行 m m m 个字符,+,-,*,/,对应操作1-4。
输出格式:一行字符表示操作后的二进制数。样例 1
输入:4 10
1101
*/-*-*-/*/输出:10110
备注
对于30%的数据, 1 ≤ n , m ≤ 1000 1≤n,m≤1000 1≤n,m≤1000;
对于60%的数据, 1 ≤ n , m ≤ 1 0 5 1≤n,m≤10^5 1≤n,m≤105;
对于100%的数据, 1 ≤ n , m ≤ 5 × 1 0 7 1≤n,m≤5×10^7 1≤n,m≤5×107。
相关知识点:
数学、进位制
题解
对二进制数进行简单运算,最简单的办法就是将输入的二进制数字串转换为二进制数,然后再按要求进行运算并输出。但注意到一点,题目给出的二进制数的长度非常大,因此这样的求解方法不一定可行。实际上,这道题考察的是对二进制数的加减乘除操作,因此求解的关键是理解这四则运算在二进制数中的法则。
- 加 1 运算。二进制数的加 1 运算在末尾位为0时直接将该位置为 1,否则就需要进位(同时将该位置为 0 )。这种情况可以推广至更高位。如,对二进制数 1011 执行加 1 运算时,由于末位为 1,则加 1 会使末位发生进位,此时末位将变为 0(即得到 101’0);进位后,由于较高位的数依然为 1,则在该位也会发生这种情况,即继续进位并置当前位为 0(即得到 10’00);再次进位后,较高位为 0,则直接置该位为1即可,即得到 1100。从该过程不难看出,二进制数的加 1 运算实际上就是从低位往高位不断扫描,直到遇到一个 “0” 时,将 “0” 换为 “1” 即可。在此过程中,只要遇到 “1” 就将 “1” 换为 “0”。
- 减 1 运算。二进制数的减 1 运算实际上和加 1 运算是互逆的。即若二进制数的末位已经为 1,则直接将该位置为 0,否则就需要借位(同时将该位置位 1)。这种情况可以推广至更高位。如,对二进制数 1100 执行减 1 运算时,由于末位为 0,则减 1 会使末位发生借位,此时末位将变为 1(即得到 110,1);借位后,由于较高位的数依然为 0,则在该位也会发生这种情况,即继续借位并置当前位为 1(即得到 11,11);再次借位后,较高位为 1,则直接置该位为0即可,即得到 1011。从该过程不难看出,二进制数的减 1运算实际上就是从低位往高位不断扫描,直到遇到一个 “1” 时,将 “1” 换为 “0” 即可。在此过程中,只要遇到 “0” 就将 “0” 换为 “1”。
- 乘 2 运算。二进制数的减 2 运算只需要在二进制数的末尾添加一个 0 即可(本质上是将原二进制数向左移1位)。如二进制数 101 对应的十进制数是 5,5×2=10,而 10 对应的二进制数是 1010。
- 除 2 运算。二进制数的除 2 运算与乘 2 运算互逆,即只需要将原二进制数向右移 1 位。
下面给出基于上述思路得到的完整代码(已 AC):
/*MT2179 01操作用 char * 才能获得满分
*/
#include<bits/stdc++.h>
using namespace std;const int MAX = 5e7+5;
char num[MAX];int main( )
{// 录入数据 int n,m,p; char opt;cin>>n>>m;cin>>num;// 执行 m 次操作while(m--){cin>>opt;switch(opt){// 加法操作 case '+':for(int i=n-1; i>=0;i--){if(num[i] == '0'){num[i] = '1';break;}else{num[i] = '0';}}break;// 减法操作 case '-':for(int i=n-1; i>=0; i--){if(num[i] == '1'){num[i] = '0';break;}else{num[i] = '1';}}break;// 乘法操作 case '*':num[n++] = '0';num[n] = '\0';break;// 除法操作 case '/':num[--n] = '\0';break;}}// 输出结果cout<<num; return 0;
}
MT2182 新十六进制
难度:钻石 时间限制:1秒 占用内存:128M
题目描述
小码哥基于之前的十六进制定义了一种新的进制,其仍然由十六个基数构成(即 0,1,2, …,9,A,B,C,D,E,F),并且大小关系保持不变(即 0<1<2<…<9<A<B<C<D<E<F),唯一不同的是数字只能按照大小关系升序排列(即 11,21 这样的数是不合法的,1F 的下一个数是 23),但前导 0 会被忽略(即 00012 等于 12,也同样合法)。
现在小码哥想为这种进制制作转换器,能够把这种进制下的数转换成十进制数,但小码哥不懂怎么下手,于是他来找你帮忙。
小码哥希望对于输入的数字能进行判断,如果这个数字不合法,转换器会报错,如果合法,转换器会输出对应的十进制数。格式
输入格式:一个字符串,为标准十六进制数。
输出格式:一个整数,表示转换成的十进制数,如果输入的十六进制数不合法输出error。样例 1
输入:12
输出:16
备注
字符串长度小于等于 20,可能出现负数,输出文件不存在 -0。
相关知识点:
数学、进位制
题解
首先对题目提出的新进制进行解读。我们来看原十六进制的前18个数:

根据题目的意思:“新十六进制下的数字只能按照大小关系升序排列”,因此上表中的十六进制数 “10”、“11” 是不合法的,于是在新十六进制下,数 “F” 的下一个数应该为 “12”,即新十六进制数的前 18 个数为:

这便是题目所说的新十六进制与十进制数的对应关系。
对于输入的任意新十六进制字符串,如果要找到其对应的十进制数,我们可以通过顺序查找的方式进行求解。即从 0 开始依次枚举该数对应的十六进制数,同时再定义一个计数器 cnt 来记录当前找到的合法的新十六进制数个数,当存在某个十进制数对应的十六进制数与输入的新十六进制数一致时,计数器 cnt 保存的值即为所求。根据这样的思路可写出以下代码:
/*MT2182 新十六进制数(Search) string.erase(string.begin())会将指定字符串的首位字符进行抹除
*/#include<bits/stdc++.h>
using namespace std;// 字符串处理:消除多余的前导0,同时反馈输入数据的正负性
int Formatting(string &str)
{int flag = 1;// 正负性判别 if(str[0] == '-'){flag = -1;str.erase(str.begin());}// 消除前导 0 while(str[0] == '0' && str.size()>1)str.erase(str.begin());return flag;
} // 字符串的合法性检测
bool isLegal(string str)
{int strlen = str.size();if(strlen==1) return true;for(int i=1; i<strlen; i++)if(str[i] - str[i-1] <= 0)return false;return true;
}// 根据新十六进制数的规则顺序枚举
int getDecOfNewHex(string str)
{int cnt = 0; string tmp;stringstream ss;for(int i=0; ; i++){// 将当前数字转换为 16 进制ss.clear();ss<<hex<<i;ss>>tmp;// 判断该十六进制数与输入字符是否一致 if(tmp == str) return cnt;// 若该十六进制数合法则向后计数 if(isLegal(tmp)) cnt++; }
}int main( )
{// 输入数据 string str;cin>>str;// 格式处理int flag = Formatting(str);// 合法性检测if(!isLegal(str)){cout<<"error"<<endl;return 0;}// 顺序查找该新十六进制字符串对应的十进制数 cout<<flag*getDecOfNewHex(str)<<endl;return 0;
}
这份代码出现了超时情况,只能得一半的分,原因很简单:每次枚举一个十进制数都涉及到进制转换以及合法性检测两个环节(特别是合法性检测),这肯定是有超时风险的。
那要如何解决这个问题呢?其实上面的求解之所以会超时是因为我们枚举的目标集合是十进制数据集,而这个数据集中具有相当一部分数据在转换为十六进制数后为非新十六进制数,说简单点就是花了些时间枚举计算非合法的结果!这就是在做无用功。换个角度,我们可以枚举所有的新十六进制数,然后再按序为其编号不就能得到不同新十六进制数对应的十进制数了么?这里需要提一点,新十六进制数是存在最大值的(最大值显然为 123456789ABCDEF),也就是说新十六进制数是有限的,将其用树来表示得到的效果如下:

这为我们提供了枚举的可行性。
于是现在我们的问题是,如何枚举新十六进制数?一种简单直接的办法是用深度优先搜索算法:传递参数为上图所示根节点对应的数字,每次搜索时都从当前根节点的下一个数字进行递归搜索。这样,就能将所有合法十六进制数全部枚举出(具体代码如下)。
char chr[] = "0123456789ABCDEF";
int cnt = 1, flag = 1;
string tmp, str, s[100000]={"0"};
void dfs(int num){if(tmp.size()) s[cnt++] = tmp;for(int i=num+1; i<16; i++){tmp.push_back(chr[i]);dfs(i);tmp.pop_back();}
}
在得到了所有新十六进制字符串后,我们只需要再对这些字符串进行排序并为其标记顺序即可(这些顺序即指示了其对应的十进制数)。而对新十六进制的排序(即 0<1<2<…<9<A<B<C<D<E<F),恰好与各字符在 ASCII 码值上的大小关系一致。但考虑到数字越长表示的数越大(这点与依赖 ASCII 码值的字符串排序不同),因此需要单独写一个用于比较新十六进制数字符串大小关系的函数,如下:
bool cmp(string a, string b){if(a.size() == b.size()) return a<b;return a.size() < b.size();
}
最后只需要通过一重循环对得到的新十六进制数集合进行扫描便能查找到指定输入对应的十进制数,下面给出基于以上思路得到的完整代码(已 AC):
/*MT2182 新十六进制数
*/
#include<bits/stdc++.h>
using namespace std;const int MAX = 1e5+5;
char chr[] = "0123456789ABCDEF";
int cnt = 1;
string tmp, str, s[MAX]={"0"};// 利用深搜将所有的合法数字举例出来
void dfs(int num){if(tmp.size()) s[cnt++] = tmp;for(int i=num+1; i<16; i++){tmp.push_back(chr[i]);dfs(i);tmp.pop_back();}
}
// 字符串处理:消除多余的前导0,同时反馈输入数据的正负性
int Formatting(string &str)
{int flag = 1;// 正负性判别 if(str[0] == '-'){flag = -1;str.erase(str.begin());}// 消除前导 0 while(str[0] == '0' && str.size()>1)str.erase(str.begin());return flag;
}
// 自定义数字比较规则
bool cmp(string a, string b){if(a.size() == b.size()) return a<b;return a.size() < b.size();
}int main( )
{// 枚举所有的新十六进制数 dfs(0);// 获取输入 cin>>str;// 对输入字符串进行处理 int flag = Formatting(str);// 排序 sort(s,s+cnt,cmp);// 查找指定新十六进制数的位置 for(int i=0;i<cnt;i++)if(s[i] == str){cout<<i*flag;return 0;}cout<<"error";return 0;
}
MT2172 萨卡兹人
难度:黄金 时间限制:2.5秒 占用内存:128M
题目描述
很久很久以前,卡西米尔里住着萨卡兹人,他们彼此争斗不休。有一天,他们想要研究自己的 DNA 序列,来证明他们是一个种群。首先选取一个好长好长的序列(DNA 序列包含 26 个小写英文字母),然后每次选择两个区间,这两个区间代表两个萨卡兹人的 DNA 序列,这两个萨卡兹一模一样的唯一可能是他们的 DNA 序列一模一样。
格式
输入格式:第一行输入一个DNA字符串 S;
接下来一个数字 m m m ,表示 m m m 次询问;
接下来 m m m 行,每行四个数字 l 1 , r 1 , l 2 , r 2 l_1,r_1, l_2,r_2 l1,r1,l2,r2 分别表示此次询问的两个区间;
注意:字符串的位置从1开始编号。
输出格式:对于每次询问,输出一行表示结果。如果两个萨卡兹完全相同输出Yes,否则输出No。样例1
输入:aabbaabb
3
1 3 5 7
1 3 6 8
1 2 1 2输出:Yes
No
Yes备注
其中: 1 ≤ l 1 ≤ r 1 ≤ l e n g t h ( S ) , 1 ≤ l 2 ≤ r 2 ≤ l e n g t h ( S ) 1≤ l_1≤r_1≤length(S),1≤ l_2≤ r_2≤length(S) 1≤l1≤r1≤length(S),1≤l2≤r2≤length(S);
1 ≤ l e n g t h ( S ) , m ≤ 1000000 1≤length(S),m≤1000000 1≤length(S),m≤1000000。
相关知识点:
字符串
题解
这道题考察了字符串的子串判等,比较简单,下面直接给出求解的完整代码(已 AC):
/*MT2172 萨卡兹人 */
#include<bits/stdc++.h>
using namespace std;int main( )
{// 输入数据string S;int m,l1,r1,l2,r2,p,len;cin>>S>>m;// 字符串移位(满足题目“字符串位置从1编号”的要求) S = "0"+S;// 执行询问while(m--) {cin>>l1>>r1>>l2>>r2;p=0, len = r1-l1;while(S[l1+p] == S[l2+p] && p<=len) p++;if(p > len) cout<<"Yes"<<endl;else cout<<"No"<<endl;}return 0;
}
MT2173 回文串等级
难度:黄金 时间限制:1秒 占用内存:128M
题目描述
所谓量变产生质变,就比如低级的材料攒多了可以合成更高级的玩意儿,高级的回文串也可以由低级的组成。任意一个字符串都可以是 0 级的回文串。而一个更高级的长为 n n n 的 i i i 级回文串则满足其长为 ⌊ 2 n ⌋ \lfloor \frac2n \rfloor ⌊n2⌋ (向下取整)的前后缀都为 i − 1 i-1 i−1 级回文串。现在给你一个字符串,问你其每个前缀的回文串等级。
格式
输入格式:一行一个字符串S。
输出格式:|S| 个数,表示其长为 1,2,3,…,|S| 的前缀的回文串等级。样例 1
输入:aaa
输出:1 2 2
备注
其中: 1 ≤ ∣ S ∣ ≤ 500000 1≤|S|≤500000 1≤∣S∣≤500000。
相关知识点:
字符串、字符串哈希
题解
首先需要弄清楚题中所说回文串等级。例如对字符串 “aba”:
- 当取前缀为 1 时(即 “a”),该字符串的长为 ⌊ 1 2 ⌋ = 0 \lfloor \frac12 \rfloor=0 ⌊21⌋=0 的前后缀不存在(即认为前后缀回文串等级为 0),且字符串 “a” 本身是一个回文串,因此认为 “a” 的回文串等级为 0+1=1(实际上,可以认为长度为 1 的字符的回文串等级就为 1);
- 当取前缀为 2 时(即 “ab”),该字符串的长为 ⌊ 2 2 ⌋ = 1 \lfloor \frac22 \rfloor=1 ⌊22⌋=1 的前后缀分别为 “a” 和 “b”(且各自的回文串等级均为 1),但字符串 “ab” 本身不是一个回文串,因此 “ab” 的回文串等级为 0;
- 当取前缀为 3 时(即 “aba”),该字符串的 ⌊ 3 2 ⌋ = 1 \lfloor \frac32 \rfloor=1 ⌊23⌋=1 的前后缀子串均为 “a”,都是 1 级回文串,因此 “aba” 的回文串等级为 1+1=2;
根据这样的思路,可写出以下代码:
// 输入数据(通过移位限定输入字符串的起始地址从1开始)
cin>>(s+1);
len = strlen(s+1);
// 初始化:第1个前缀的回文串等级必定是1
ans[1]=1;
cout<<1<<" ";
// 遍历原字符串的所有前缀,并求出各前缀的回文串等级
for(int i=2;i<=len;i++){if(isPlalindrome(s,1,i))ans[i] = ans[i>>1] + 1;cout<<ans[i]<<" ";
}
其中,函数 isPlalindrome(char *s, int start, int end) 用于判断字符串 s 从 start 到 end 的子串是否为回文。
该代码完整描述了求解本题的整体思路,但存在严重的超时风险。因为每次扫描指定字符串的所有前缀时,都需要单独判断此前缀串是否为回文,这在题目所给的数据范围内是必定超时的。因此,为了能完整通过全部测试数据,就必须想办法解决 “判断指定字符串的所有前缀串是否为回文” 这一难题。
这便需要用到字符串哈希。我们知道,回文串是正着和倒着读结果都不变的字符串,基于这种性质,假设现在有一个长为 n n n 的回文字符串 S S S。如果我们随机取一个数 p p p,则总存在:
S 1 p n − 1 + S 2 p n − 2 + ⋯ + S n = S 1 + S 2 p + ⋯ + S n p n − 1 S_1 p^{n-1}+S_2 p^{n-2}+⋯+S_n=S_1+S_2 p+⋯+S_n p^{n-1} S1pn−1+S2pn−2+⋯+Sn=S1+S2p+⋯+Snpn−1
其中: S i S_i Si 表示字符串 S S S 中的第 i i i 个字符对应的 ASCII 值。例如,数字回文串 “11311” 始终满足:
1 p 4 + 1 p 3 + 3 p 2 + 1 p + 1 = 1 + 1 p + 3 p 2 + 1 p 3 + 1 p 4 1p^4+1p^3+3p^2+1p+1=1+1p+3p^2+1p^3+1p^4 1p4+1p3+3p2+1p+1=1+1p+3p2+1p3+1p4
根据该等式,我们可以通过计算一个字符串的前缀和与后缀和数组来快速地判断该字符串中任意前缀是否为一个回文串。例如,对于数字字符串 “112113”,我们可以维护以下两个数组(取 p = 5 p=5 p=5):

基于这两个数组,我们能在常数时间内判断出字符串 “112113” 的任意前缀子串是否为回文串:
- 长度为 1 的前缀 “1”:数组 H 1 H_1 H1 记录的该子串的前缀和为 H 1 [ 1 ] = 1 H_1 [1]=1 H1[1]=1,数组 H 2 H_2 H2 记录的该子串的前缀和为 H 2 [ 1 ] − H 2 [ 1 + 1 ] ∗ 5 = 1 H_2 [1]-H_2 [1+1]*5=1 H2[1]−H2[1+1]∗5=1,因此有 P r e H 1 = P r e H 2 PreH_1=PreH_2 PreH1=PreH2,所以前缀 “1” 是一个回文串;
- 长度为 2 的前缀 “11”:数组 H 1 H_1 H1 记录的该子串的前缀和为 H 1 [ 2 ] = 6 H_1 [2]=6 H1[2]=6,数组 H 2 H_2 H2 记录的该子串的前缀和为 H 2 [ 1 ] − H 2 [ 2 + 1 ] ∗ 5 2 = 6 H_2 [1]-H_2 [2+1]*5^2=6 H2[1]−H2[2+1]∗52=6,因此有 P r e H 1 = P r e H 2 PreH_1=PreH_2 PreH1=PreH2,所以前缀 “11” 是一个回文串;
- 长度为 3 的前缀 “112”:数组 H 1 H_1 H1 记录的该子串的前缀和为 H 1 [ 3 ] = 32 H_1 [3]=32 H1[3]=32,数组 H 2 H_2 H2 记录的该子串的前缀和为 H 2 [ 1 ] − H 2 [ 3 + 1 ] ∗ 5 3 = 56 H_2 [1]-H_2 [3+1]*5^3=56 H2[1]−H2[3+1]∗53=56,因此有 P r e H 1 ≠ P r e H 2 PreH_1\neq PreH_2 PreH1=PreH2,所以前缀 “112” 不是一个回文串;
- 长度为 4 的前缀 “1121”:数组 H 1 H_1 H1 记录的该子串的前缀和为 H 1 [ 4 ] = 161 H_1 [4]=161 H1[4]=161,数组 H 2 H_2 H2 记录的该子串的前缀和为 H 2 [ 1 ] − H 2 [ 4 + 1 ] ∗ 5 4 = 206 H_2 [1]-H_2 [4+1]*5^4=206 H2[1]−H2[4+1]∗54=206,因此有 P r e H 1 ≠ P r e H 2 PreH_1\neq PreH_2 PreH1=PreH2,所以前缀 “1121” 不是一个回文串;
- 长度为 5 的前缀 “11211”:数组 H 1 H_1 H1 记录的该子串的前缀和为 H 1 [ 5 ] = 1 × 5 4 + 1 × 5 3 + 2 × 5 2 + 1 × 5 + 1 × 1 H_1 [5]=1×5^4+1×5^3+2×5^2+1×5+1×1 H1[5]=1×54+1×53+2×52+1×5+1×1,数组 H 2 H_2 H2 记录的该子串的前缀和为 H 2 [ 1 ] − H 2 [ 5 + 1 ] ∗ 5 5 = 1 × 1 + 1 × 5 + 2 × 5 2 + 1 × 5 3 + 1 × 5 4 H_2 [1]-H_2 [5+1]*5^5=1×1+1×5+2×5^2+1×5^3+1×5^4 H2[1]−H2[5+1]∗55=1×1+1×5+2×52+1×53+1×54,显然 P r e H 1 = P r e H 2 PreH_1= PreH_2 PreH1=PreH2,所以前缀 “11211” 是一个回文串;
- 长度为 6 的前缀 “112113”:数组 H 1 H_1 H1 记录的该子串的前缀和为 H 1 [ 6 ] = 1 × 5 5 + 1 × 5 4 + 2 × 5 3 + 1 × 5 2 + 1 × 5 + 3 × 1 H_1 [6]=1×5^5+1×5^4+2×5^3+1×5^2+1×5+3×1 H1[6]=1×55+1×54+2×53+1×52+1×5+3×1,数组 $H_2 $ 记录的该子串的前缀和为 H 2 [ 1 ] = 1 × 1 + 1 × 5 + 2 × 5 2 + 1 × 5 3 + 1 × 5 4 + 3 × 5 5 H_2 [1]=1×1+1×5+2×5^2+1×5^3+1×5^4+3×5^5 H2[1]=1×1+1×5+2×52+1×53+1×54+3×55,显然 P r e H 1 ≠ P r e H 2 PreH_1\neq PreH_2 PreH1=PreH2,所以前缀 “112113” 不是一个回文串。
这便是利用字符串哈希判断任意字符串的所有前缀子串是否为回文的方法。下面给出基于该思路的完整代码(已 AC):
/*MT2173 回文串等级 哈希求解
*/
#include<bits/stdc++.h>
using namespace std;// 定义一个较大的质数
const int Z = 111;
const int MAX = 5e5+7;
unsigned long long p[MAX], h1[MAX], h2[MAX];
char s[MAX];
int len, ans[MAX];// 预处理哈希函数的前缀和
void init(int n){p[0]=1;for(int i=1; i<=n; i++){p[i] = p[i-1]*Z;h1[i] = h1[i-1]*Z + s[i];h2[n-i+1] = h2[n-i+2]*Z + s[n-i+1];}
}int main( )
{// 输入数据(通过移位限定输入字符串的起始地址从1开始)cin>>s+1; len = strlen(s+1);init(len);// 初始化:第1个前缀的回文串等级必定是1ans[1]=1;cout<<1<<" ";// 遍历原字符串的所有前缀,并求出各前缀的回文串等级for(int i=2;i<=len;i++){// 判断当前的前缀子串是否是回文串if(h1[i] == h2[1]-h2[i+1]*p[i])ans[i] = ans[i>>1] + 1;cout<<ans[i]<<" ";}return 0;
}
MT2175 五彩斑斓的串
难度:钻石 时间限制:1秒 占用内存:128M
题目描述
小码哥是一个喜欢字符串的男孩子。
小码哥在研究字典序的性质。他发现他可以通过改变字母表的顺序来改变两个字符串的大小关系。
例如,通过将现有的字母表顺序 “abcdefghijklmnopqrstuvwxyz” 改为 “abcdefghijklonmpqrstuvwxyz”,字符串 “omm” 会小于 “mom”。
现在小码哥有 n n n 个字符串,对于其中的一个字符串,如果存在某种字母表顺序,使得它在这 n n n 个字符串中字典序最小,那这个字符串就是一个五彩斑斓的串。
现在小码哥想找出所有五彩斑斓的串,由于小码哥忙于他的研究,找出所有五彩斑斓的串的重任被交到了你的身上。格式
输入格式:第一行一个正整数 n n n,表示字符串的个数;
接下来 n n n 行,每行一个字符串。
输出格式:输出第一行为一个正整数,为五彩斑斓的串的个数;
接下来对于每个五彩斑斓的串输出一行。
注意:输出的串的顺序应该和输入一致!样例 1
输入:4
omm
moo
mom
ommnom输出:2
omm
mom备注
测试数据保证 1 ≤ n ≤ 3 × 1 0 4 1≤n≤3×10^4 1≤n≤3×104 ,所有字符串的总长不超过 3 × 1 0 5 3×10^5 3×105,且字符集为小写英文字母。
相关知识点:
字符串、字典树
题解
题目的意思是对输入的一系列字符串,判断其中的每个字符串是否存在一种字典序使得其在这些字符串集中最小。例如,对于题目给出的字符串集 {omm, moo, mom, ommnom}:
- 字符串 “omm” 在给定满足 “o<m” 的字典序中总存在:omm < ommnom < moo < mom,此时字符串 “omm” 是最小的。于是称字符串 “omm” 是五彩斑斓的串;
- 字符串 “moo” 无论是在给定满足 “o<m” 的字典序(此时有omm < ommnom < moo < mom)中,还是在给定满足 “m<o” 的字典序(此时有 mom < moo < omm < ommnom)中,字符串 “omm” 均不是最小的。于是认为字符串 “moo” 不是五彩斑斓的串;
- 字符串 “mom” 在给定满足 “m<o” 的字典序中总存在:mom <moo < omm < ommnom,此时字符串 “mom” 是最小的。于是称字符串 “mom” 是五彩斑斓的串;
- 字符串 “ommnom” 在给定的字符串集中,存在它的前缀字符串 “omm”,因此无论在怎样的字典序下,字符串 “ommnom” 总是比 “omm” 大,因此字符串 “ommnom” 不可能是五彩斑斓的串。
为了判断一个字符串是否为 “五彩斑斓的串”,最直接的办法就是枚举全部的字典序,并求出在各字典序下的最小的字符串。但这样的求解在极端情况下(即给定的字符串集中含有全 26 个字符),将存在 26! 个字典序,这肯定超时无疑!此时要如何求解这个问题呢?这便需要用到字典树。
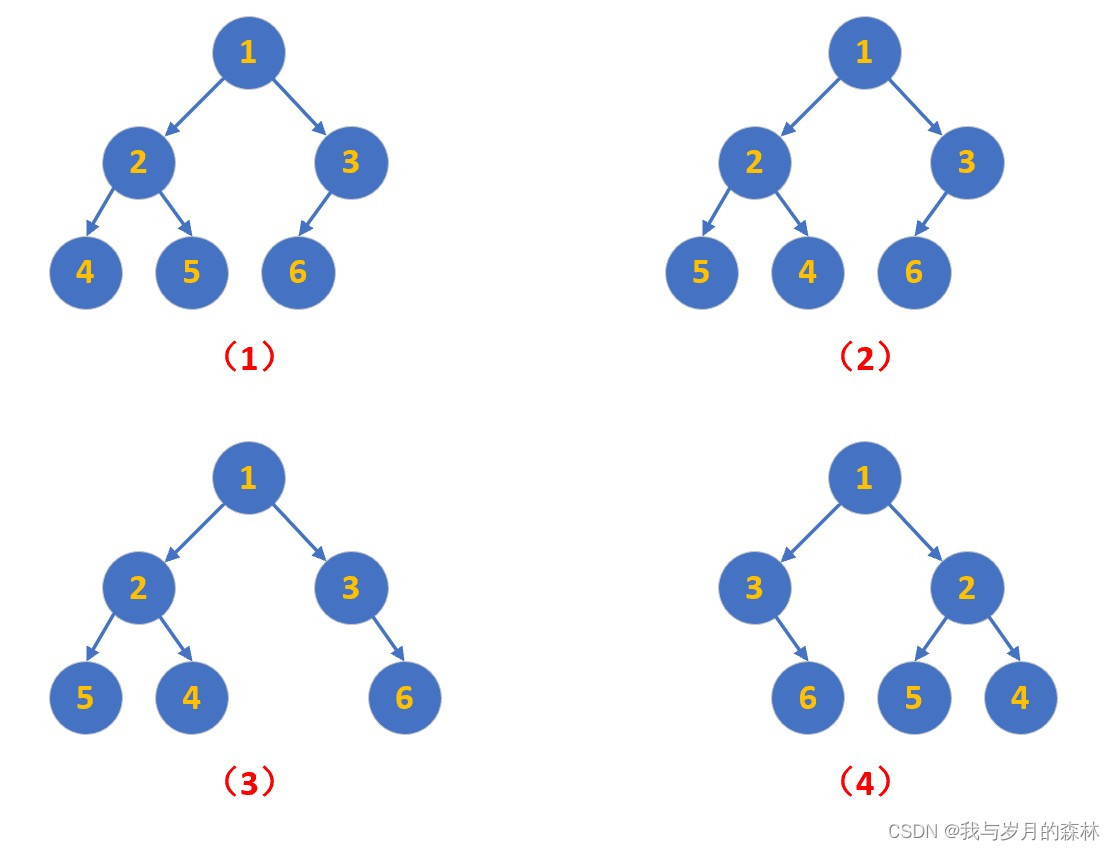
字典树是一种可高效地存储和检索字符串的树形数据结构,例如,对于题目给出的字符串集 {omm, moo, mom, ommnom},可构建如下字典树:

需要说明的是,字典树并没有严格的字母表顺序,他只是一种存储结构。所以,在上面的字典树中,各分支之间的位置关系并不代表这些字符之间的顺序,他们彼此之间的地位对等。
为了找到本题所说的 “五彩斑斓的串”,我们必须单独构建一个字母之间大小关系的表。为此,定义一个规格为 26×26 的矩阵 m,它的含义如下:
- m [ i ] [ j ] = 1 m[i][j] = 1 m[i][j]=1:表示字符 i i i 的字典序大于字符 j j j;
- m [ i ] [ j ] = − 1 m[i][j] = -1 m[i][j]=−1:表示字符 i i i 的字典序小于字符 j j j。
根据这个矩阵,以及字典树,我们便能快速的判断出一个字符是否能成为一个 “五彩斑斓的串”。以题目给出的字符串集为例,下面阐述其具体的判别过程:
- 字符串 “omm”:首先初始化矩阵 m 中的各取值为 0。接下来来到字典树的第一层,该层有两个分支,且对应节点中存放的字符分别为 “o” 和 “m”。为了使得字符串 “omm” 最小,就必须要求字母 “o” 的字典序小于 “m”,于是置 m[o][m] = -1, m[m][o] = 1。接下来沿着字符串 “omm” 的分支继续往下,来到第二层,该层仅有一个分支,因此无需添加字典序规则。继续往下,来到第三层,该层依然只有一个分支,因此无需添加字典序规则。字符串 “omm” 扫描结束,从矩阵 m 中的结果可知,要使字符串 “omm” 成为 “五彩斑斓的串” 的字典序为 “o<m”。
- 字符串 “moo”:首先初始化矩阵 m 中的各取值为 0。接下来来到字典树的第一层,该层有两个分支,且对应节点中存放的字符分别为 “o” 和 “m”。为了使得字符串 “moo” 最小,就必须要求字母 “m” 的字典序小于 “o”,于是置 m[m][o] = -1, m[o][m] = 1。接下来沿着字符串 “moo” 的分支继续往下,来到第二层,该层仅有一个分支,因此无需添加字典序规则。继续往下,来到第三层,该层有两个分支,且对应节点中存放的字符分别为 “o” 和 “m”。为了使得字符串 “moo” 最小,就必须要求字母 “o” 的字典序小于 “m”,但是现存 m 矩阵中,已经存在 m[m][o] = -1, m[o][m] = 1。这与现在的要求相矛盾,因此认为字符串 “moo” 不可能成为 “五彩斑斓的串”。
- 字符串 “mom”:首先初始化矩阵 m 中的各取值为 0。接下来来到字典树的第一层,该层有两个分支,且对应节点中存放的字符分别为 “o” 和 “m”。为了使得字符串 “mom” 最小,就必须要求字母 “m” 的字典序小于 “o”,于是置 m[m][o] = -1, m[o][m] = 1。接下来沿着字符串 “omm” 的分支继续往下,来到第二层,该层仅有一个分支,因此无需添加字典序规则。继续往下,来到第三层,该层有两个分支,且对应节点中存放的字符分别为 “o” 和 “m”。为了使得字符串 “mom” 最小,就必须要求字母 “m” 的字典序小于 “o”,这与现存 m 矩阵中的规则一致,故无需更新。字符串 “mom” 扫描结束,从矩阵 m 中的结果可知,要使字符串 “mom” 成为 “五彩斑斓的串” 的字典序为 “m<o”。
- 字符串 “ommnom”:在给定的字符串集中,存在它的前缀字符串 “omm”,因此对 m 矩阵进行更新时,其前半段的更新与对字符串 “omm” 的更新一致。接下来当程序继续往下扫描时,它将读取到一个字符结束标记,即系统将识别到字符串 “ommnom” 在给定字符串集中存在前缀,因此直接退出程序,并反馈字符串 “ommnom” 不可能是五彩斑斓的串。
此外,需要注意一点,字母之间的大小关系是可传递的。例如,假设现在得到了字母顺序 “a<b<c”。接下来,当我们得到一个新的顺序 “c<d” 时,除了要更新 m[c][d] 和 m[d][c],还需要将所有原先就比 “c” 小的字母统一规定小于 “d”,即需要更新 m[a][d]、m[d][a]、m[b][d] 和 m[d][b];所有原先就比 “d” 大的字母统一规定大于 “c”。即,要充分考虑 m 矩阵中的所有现存规则,并实时地动态更新。
下面给出基于以上思路写出的完整代码(已 AC):
/*MT2175 五彩斑斓的串
*/
#include<bits/stdc++.h>
using namespace std;const int N = 3e5+5;
int n, ans[N], cnt;
string s[N];
char tmp[N];struct Trie{// m 矩阵指示了各字符的大小关系(从而形成一个字典序) // m[i][j] = 1:表示字符 i 的字典序大于字符 j // m[i][j] = -1:表示字符 i 的字典序小于字符 j // A 数组存放所有比指定字符小的字符;B 数组存放所有比指定字符大的字符 int id, nex[N][26], m[26][26], A[30], B[30];// 字符串的结束标记 bool end[N];// 插入字符串 void insert(string s){int p = 0, l=s.size(), c;// 构建字符串中各字符在字典树中的位置关系 for(int i=0; i<l; i++){c = s[i] - 'a';if(!nex[p][c]) nex[p][c] = ++id;p = nex[p][c];}end[p]=1; }// 判断给定字符串是否存在一个能使其最小的字典序 bool check(string s){// 每次执行判断时必须重置字符的大小关系矩阵 memset(m, 0, sizeof(m));int p=0, l = s.size();for(int i=0; i<l; i++){int c = s[i] - 'a';// 1. 查看是否有已知的更短的前缀字符串 if(end[p]) return false;// 2. 查看是否有兄弟之间的关系 for(int j=0; j<26; j++)if(nex[p][j] && m[c][j]>0 && j!=c)return false;// 3. 更新前后序的节点组合A[0] = B[0] = 0;for(int j=0; j<26; j++) {// 如果存在兄弟节点,要使当前字符串为“五彩斑斓的串”(即当前字符在字典序里最小) // 就必须使得字符 c 小于 字符 j,即 m[c][j] = -1 if(nex[p][j] && j!=c){m[c][j] = -1;m[j][c] = 1;// 接下来必须将字符 c 的大小关系传递至整个已有的字典序 m 中 for(int k=0; k<26; k++){// 维护前序字符集的规则:所有本来就比 c 小的字符也应该小于 j if(m[c][k] == 1){// 将所有比字符 c 小的字符记录进入 A 数组,为了节省计数变量,这里就用 A[0] A[++A[0]] = k;m[j][k] = 1;m[k][j] = -1;}// 维护后序字符集的规则:所有本来就比 j 大的字符也应该大于 c if(m[j][k] == -1){// 将所有比字符 c 大的字符记录进入 B 数组,为了节省计数变量,这里就用 B[0] B[++B[0]] = k;m[c][k] = -1;m[k][c] = 1;}}}}// 建立字典关系:A 数组中的所有字符自然是小于 B 数组中的所有字符 for(int j=1; j<=A[0]; j++)for(int k=1; k<=B[0]; k++){m[A[j]][B[k]] = -1;m[B[k]][A[j]] = 1;}p = nex[p][c];}return true;}
};
Trie trie;int main( )
{// 获取输入cin>>n;// 插入所有的字符串,构建字典树for(int i=1; i<=n; i++){cin>>s[i];trie.insert(s[i]);}// 依次扫描每个字符串,检测其是否能成为“五彩斑斓的串”for(int i=1; i<=n; i++){if(trie.check(s[i]))ans[++cnt] = i;}// 输出cout<<cnt<<endl;for(int i=1; i<=cnt; i++)cout<<s[ans[i]]<<endl;return 0;
}