MMU(Memory Manager Unit),是内存管理单元,负责将虚拟地址转换成物理地址。除此之外,MMU 实现了内存保护,进程无法直接访问物理内存,防止内存数据被随意篡改。
目录
一、内存管理体系结构
1、认识框架
2、虚拟地址到物理地址的转换流程
二、页命中
三、缺页
四、虚拟地址与物理地址的多级映射
1、第一级:PGD 页目录查询(VA => PTE)
2、第二级:PTE 页表查询(PTE => PA 高20位)
3、物理地址拼接(获得完整 PA)
一、内存管理体系结构
1、认识框架
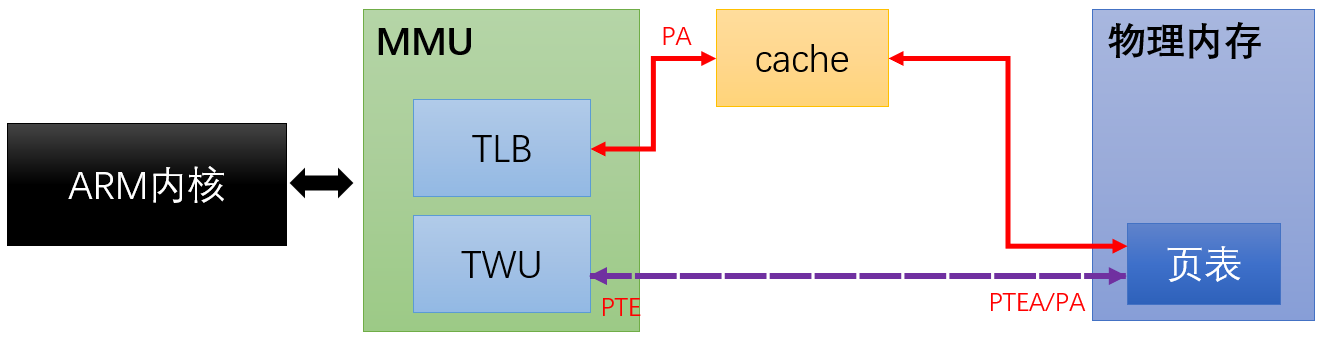
MMU:
- TLB模块:用于缓存从虚拟地址到物理地址的转换结果
- TWU模块:负责完成页表的查过程
Cache:
高速缓存。缓存某物理地址对应的内容
页表:
- 将虚拟地址转换为物理地址
- 管理CPU对物理页的访问(即检查是否具备读、写、可执行等权限)
- 隔离地址空间(隔离各个进程的地址空间,使其互不影响)
PTE: PTE 是一种数据结构,用于描述虚拟内存和物理内存之间的映射关系。通过使用PTE,CPU可以根据虚拟地址获取到物理内存地址,同时检查该地址的访问权限。
- 物理页地址:虚拟内存所映射的物理内存页的地址
- 访问权限:指示当前页面是否可读、可写、可执行等权限信息
- 脏位:标记页面是否被修改过,以支持页面置换
- 共享位:指示页面是否可以被共享
- 缓存位:用于控制页面的缓存策略,例如是否可以缓存到Cache
2、虚拟地址到物理地址的转换流程
MMU 先检查 TLB 是否命中(即TLB 是否保存了该虚拟地址和物理地址的映射)
- 如果 TLB 命中了,继续查询该物理地址的内容是否存在于 cache 中。
- 若cache命中,直接取出内容返回给处理器
- 若cache没有命中,进一步访问物理内存获取相应的内容
- 如果 TLB 没有命中,MMU 通过 TWU 查询页表,翻译虚拟地址得到物理地址(具体过程请看下面“页命中”部分)
注意:这里存在一个特殊的过程“缺页”,放到后面介绍
二、页命中
页命中就是 MMU 成功将虚拟地址转换为物理地址,获取到物理地址对应内容的过程。(下图是将过程简化以后的结果,这里假设TLB没有命中)
ps:PTE 是一种数据结构,用于描述虚拟内存和物理内存之间的映射关系,包含的内容有物理内存页的地址、访问权限、臧伟
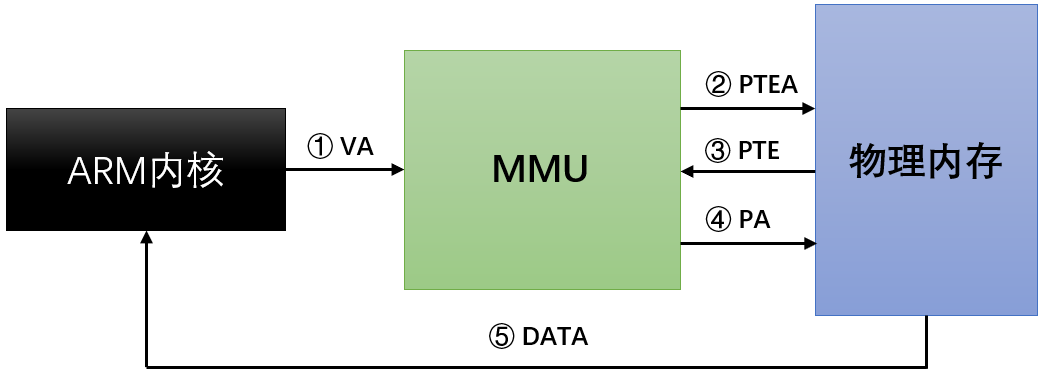
① 处理器对虚拟地址(VA) 进行访问
② MMU 通过TWU遍历物理内存页表中的 PTEA(PTE地址)
③ 物理内存返回 PTE(检查对应物理地址是否存在,或者是否具备访问权限)
④ MMU 通过PTE 映射物理地址,将其传给高速缓存或物理内存
⑤ 高速缓存或物理内存返回数据给处理器
三、缺页
与页命中相反,当MMU没有找到虚拟地址对应的物理地址时,这个时候为防止系统崩溃,需要采取补救措施。这种异常便是“缺页”(这里同样假设TLB没有命中)
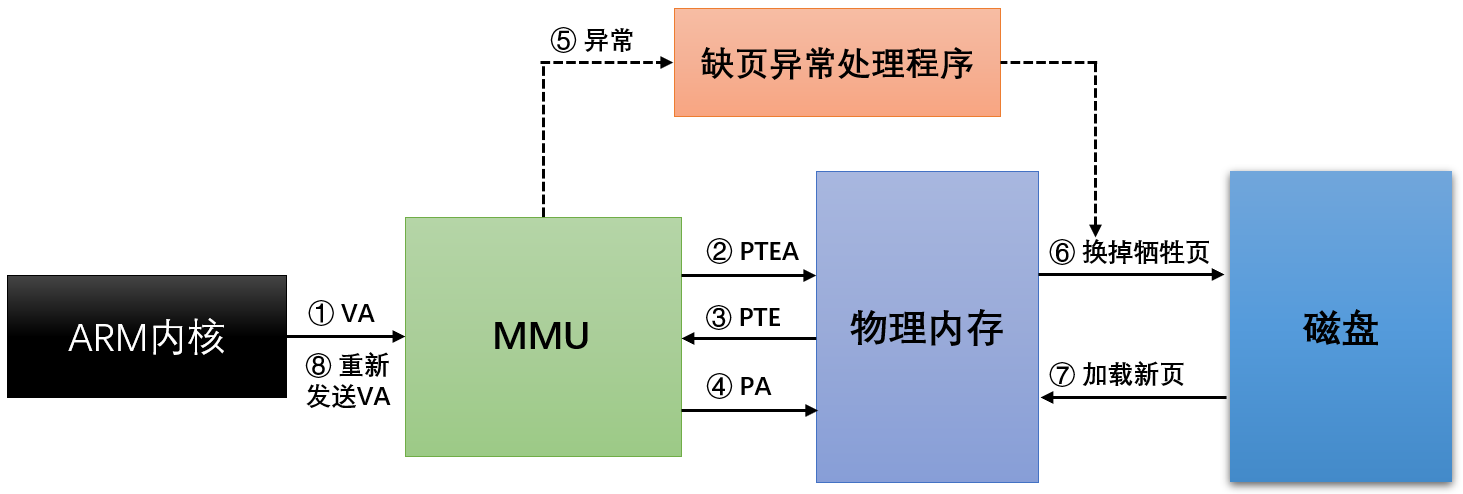
① 处理器对虚拟地址(VA) 进行访问
② MMU 通过TWU遍历物理内存页表中的 PTEA(PTE地址)
③ 物理内存返回 PTE(有效位为0,触发异常,CPU响应异常,运行相应的异常处理程序)
补救措施:
④ 选出物理内存中的牺牲页,如果该页被修改过,先保存到磁盘
⑤ 异常处理程序从磁盘中加载新的页面,并更新触发异常的PTE
⑥ 异常处理程序返回到原来的进程,重新发送一个VA 给MMU(接下来就是“命中页”的流程了)
(牺牲页可以选择长时间没被使用的页,因为后面要用新页内容覆盖该页,所以要检查有没有被修改过,如果被修改过,需要更新到磁盘)
四、虚拟地址与物理地址的多级映射
上面了解了虚拟地址到物理地址的大致转换过程,但是我们要MMU 是如何根据虚拟地址 VA 获得 PTE?又是如何根据 PTE 得到最终的物理地址 PA 的 ?
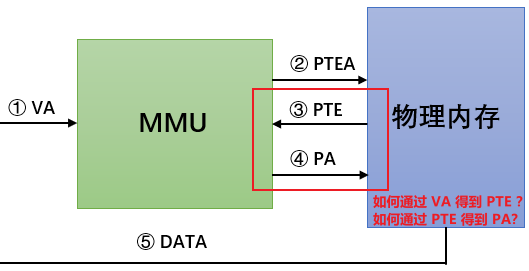
下面我们要了解便是 VA 到 PA 的具体转换过程。不同系统采取的映射策略会有所不同。(下面以ARM 32bit为例)
- Linux x86 :三级映射。PGD => PMD => PTE
- Linux x86_64:四级映射。PGD => PUD => PMD => PTE
- ARM 32bit : 两级映射。PGD => PTE
其中:
- PGD:Page Global Directory
- PUD:Page Upper Directory
- PMD:Page Middle Directory
- PTE:Page Table Entry
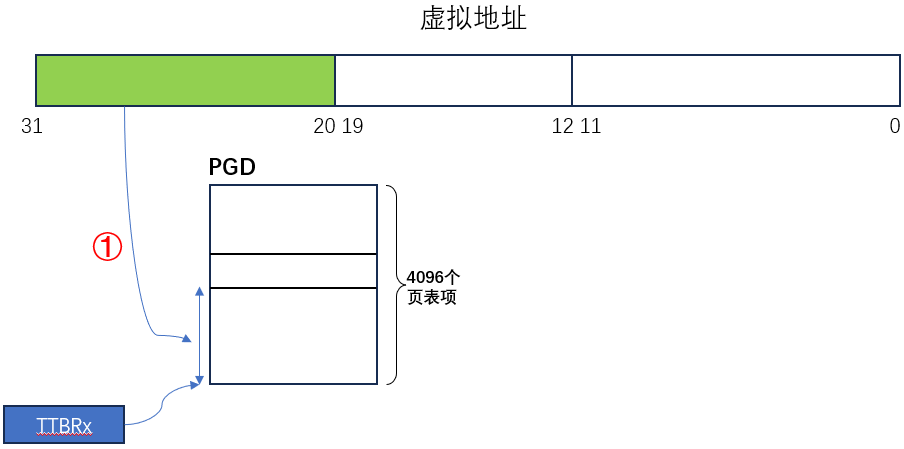
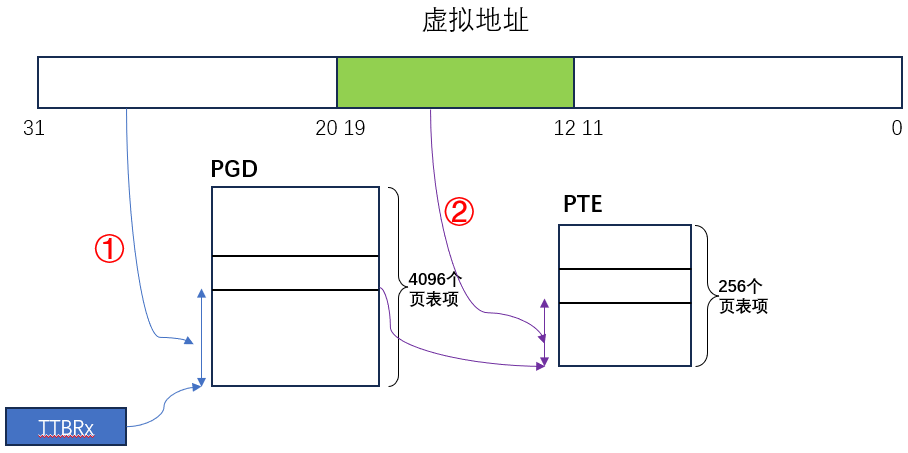
1、第一级:PGD 页目录查询(VA => PTE)
虚拟地址 VA 的高 12 位(bit[31:20])可作为访问一级页表的索引值,基地址保存在 TTBRx 寄存器中。从PGD 中获取到的是二级页表 PTE 的基地址(起始地址)
2、第二级:PTE 页表查询(PTE => PA 高20位)
虚拟地址 VA 的 bit[19:12] 可作为访问二级页表的索引值,基地址来自 PGD 获得的页表项。从PTE 中获取到的是物理地址PA的高20位。
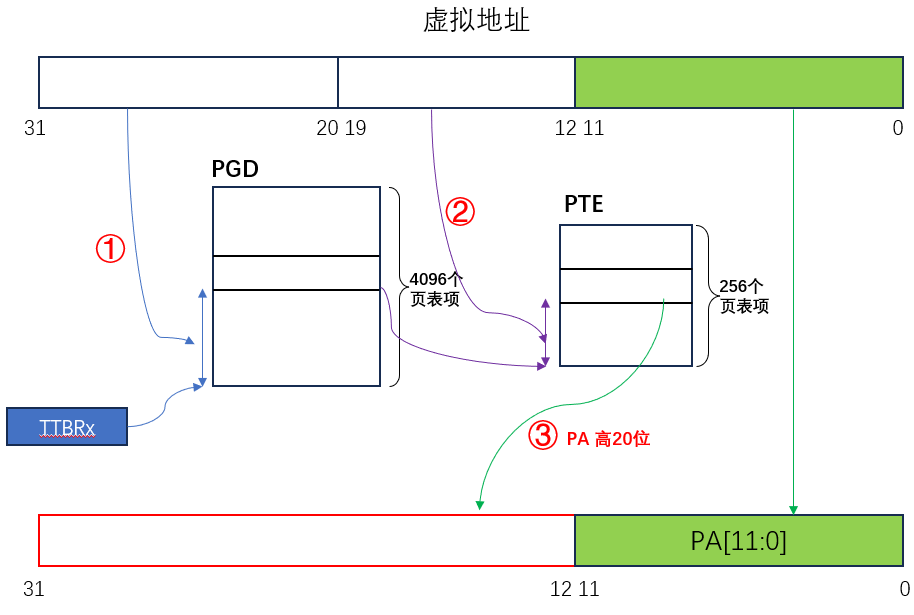
3、物理地址拼接(获得完整 PA)
完整的物理地址 PA = 从PTE获得 PA 高 20 位 + 虚拟地址 VA 的bit[11:0]
参考文章:
一文搞懂MMU工作原理 - 知乎 (zhihu.com)
linux中的pte是什么_linux中的pte是什么意思-PHP博客-李雷博客 (mdaima.com)
ARM32 页表映射过程 - DF11G - 博客园 (cnblogs.com)
MMU内存管理单元的工作原理和作用-电子发烧友网 (elecfans.com)