原文:
zh.annas-archive.org/md5/98cfb0b9095f1cf64732abfaa40d7b3a译者:飞龙
协议:CC BY-NC-SA 4.0
第八章:深度学习与电脑游戏
上一章关注的是解决棋盘游戏问题。在本章中,我们将研究更复杂的问题,即训练人工智能玩电脑游戏。与棋盘游戏不同,游戏规则事先是不知道的。人工智能不能预测它采取行动会发生什么。它不能模拟一系列按钮按下对游戏状态的影响,以查看哪些获得最高分。它必须纯粹通过观察、玩耍和实验来学习游戏的规则和约束。
在本章中,我们将涵盖以下主题:
-
Q 学习
-
经验重演
-
演员-评论家
-
基于模型的方法
游戏的监督学习方法
强化学习中的挑战在于找到我们网络的良好目标。我们在上一章中就一种方法,策略梯度。如果我们能够将强化学习任务转化为监督任务问题,那么问题就会变得容易得多。因此,如果我们的目标是构建一个玩电脑游戏的人工智能代理,我们可能会尝试观察人类的游戏方式,并让我们的代理从他们那里学习。我们可以录制一个专家玩家玩游戏的视频,同时跟踪屏幕图像和玩家按下的按钮。
正如我们在计算机视觉章节中所看到的,深度神经网络可以从图像中识别模式,因此我们可以训练一个以屏幕为输入,以每一帧中用户按下的按钮为目标的网络。这类似于上一章中 AlphaGo 的预训练。这种方法在一系列复杂的 3D 游戏上进行了尝试,例如《超级大乱斗》和《马里奥网球》。卷积网络用于其图像识别质量,而 LTSM 用于处理帧之间的长期依赖关系。使用这种方法,一个针对《超级大乱斗》训练过的网络可以在最困难的难度设置下击败游戏内 AI:

从人类身上学习是一个很好的起点,但我们进行强化学习的目标应该是实现超越人类的表现。此外,用这种方式训练的智能体将永远受到其能力的限制,而我们真正想要的是能够真正自我学习的智能体。在本章的其余部分,我们将介绍一些旨在超越人类水平的方法。
应用遗传算法玩游戏
长期以来,AI 在视频游戏环境中的最佳结果和大部分研究都围绕着遗传算法展开。这种方法涉及创建一组模块,这些模块接受参数以控制 AI 的行为。参数值的范围由一组基因的选择来确定。然后将创建一组代理,使用这些基因的不同组合,然后在游戏上运行。最成功的一组代理基因将被选择,然后将使用成功代理的基因的组合创建一个新的代理一代。这些代理再次在游戏上运行,直到达到停止条件,通常是达到最大迭代次数或游戏中的性能水平。偶尔,在创建新一代时,一些基因可以发生突变以创建新基因。一个很好的例子是 MarI/O,这是一个使用神经网络遗传演化学习玩经典的 SNES 游戏 超级马里奥世界 的 AI:

图 1:使用遗传算法学习马里奥(https://www.youtube.com/watch?v=qv6UVOQ0F44)
这些方法的一个很大的缺点是,它们需要大量的时间和计算能力来模拟所有参数的变化。每一代的每个成员都必须运行整个游戏直到终止点。该技术也没有利用游戏中人类可以使用的丰富信息。每当收到奖励或惩罚时,都会有关于状态和采取的行动的上下文信息,但遗传算法只使用运行的最终结果来确定适应度。它们不是那么多的学习而是试错。近年来,已经找到了更好的技术,利用反向传播来允许代理在玩耍时真正学习。与上一章一样,这一章也非常依赖代码;如果您不想花时间从页面上复制文本,您可以在 GitHub 仓库中找到所有代码:github.com/DanielSlater/PythonDeepLearningSamples。
Q 学习
想象一下,我们有一个代理将在一个迷宫环境中移动,其中某处有一个奖励。我们的任务是尽快找到到达奖励的最佳路径。为了帮助我们思考这个问题,让我们从一个非常简单的迷宫环境开始:
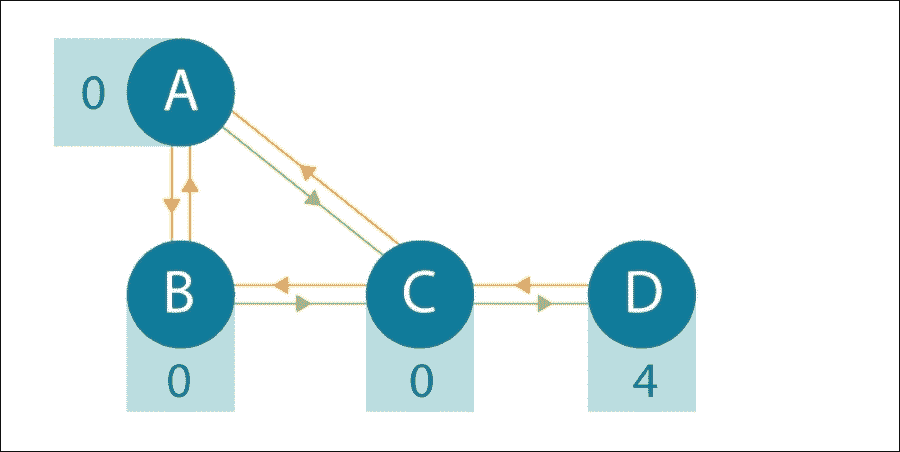
图 2:一个简单的迷宫,代理可以沿着线移动从一个状态到另一个状态。如果代理到达状态 D,将获得奖励 4。
在所示的迷宫中,代理可以在任何节点之间来回移动,通过沿着线移动。代理所在的节点是它的状态;沿着线移动到不同的节点是一种行动。如果代理达到状态D的目标,就会得到4的奖励。我们希望从任何起始节点找到迷宫的最佳路径。
让我们思考一下这个问题。如果沿着一条直线移动将我们置于状态D,那么这将永远是我们想要采取的路径,因为这将在下一个时间步给我们4的奖励。然后退回一步,我们知道如果我们到达状态C,它直接通往D,我们可以获得那个 4 的奖励。
要选择最佳行动,我们需要一个能够为行动让我们置于的状态提供预期奖励的函数。在强化学习中,这个函数的名称是 Q 函数:
state, action => expected reward
如前所述,到达状态D的奖励是4。那么到达状态C的奖励应该是多少呢?从状态C,可以采取一个行动转移到状态D并获得4的奖励,所以也许我们可以将C的奖励设为4。但是如果我们在所示的迷宫中采取一系列随机行动,我们最终总是会到达状态D,这意味着每个行动都会获得相同的奖励,因为从任何状态,我们最终都会到达状态D的4奖励。
我们希望我们的预期奖励考虑到获得未来奖励需要的行动数。我们希望这种期望能够产生这样的效果,即当处于状态A时,我们直接转移到状态C而不是通过状态B,这将导致到达D需要更长的时间。所需的是一个考虑到未来奖励的方程,但与更早获得的奖励相比打折。
另一种思考这个问题的方式是考虑人们对待金钱的行为,这是对人们对待奖励的行为的良好代理。如果在一周后和十周后选择收到 1 美元的选择,人们通常会选择尽快收到 1 美元。生活在不确定的环境中,我们对以较少不确定性获得的奖励更加重视。我们推迟获得奖励的每一刻都是世界不确定性可能消除我们奖励的更多时间。
为了将这个应用于我们的代理,我们将使用用于评估奖励的时间差方程;它如下所示:

在这个方程中,V 是采取一系列动作的奖励,r [t] 是在这个序列中在时间 t 收到的奖励,g 是一个常数,其中 0 < g < 1,这意味着将来的奖励不如更早获得的奖励有价值;这通常被称为折扣因子。如果我们回到我们的迷宫,这个函数将为在一个动作中到达奖励的动作提供更好的奖励,而不是在两个或更多动作中到达奖励的动作。如果将 g 的值设为 1,方程简化为随时间的奖励总和。这在 Q 学习中很少使用;它可能导致代理不收敛。
Q 函数
现在我们可以评估代理在迷宫中移动的路径,那么如何找到最优策略呢?对于我们的迷宫问题,简单的答案是,在面临动作选择时,我们希望选择导致最大奖励的动作;这不仅适用于当前动作,还适用于当前动作后我们将进入的状态的最大动作。
这个函数的名称是 Q 函数。如果我们有完美的信息,这个函数将给出我们在任何状态下的最优动作;它看起来如下:
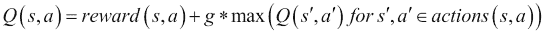
在这里,s 是一个状态,a 是在该状态下可以采取的动作,而 0 < g < 1 是折扣因子。rewards 是一个函数,它返回在某个状态下采取某个动作的奖励。actions 是一个函数,它返回在状态 s 中采取动作 a 后转移到的状态 s’ 以及在该状态下所有可用的动作 a’。
让我们看看如果我们将 Q 函数应用于折扣因子为 g=0.5 的迷宫会是什么样子:

图 3:简单迷宫,现在带有 Q 值。箭头显示了在每个末端两个状态之间移动的预期奖励
您会注意到所示的 Q 函数是无限递归的。这是一个假设的完美 Q 函数,所以不是我们可以在代码中应用的东西。为了在代码中使用它,一个方法是简单地预先设定一个最大的动作数;那么它可能是这样的:
def q(state, action, reward_func, apply_action_func, actions_for_state_func, max_actions_look_ahead, discount_factor=0.9):new_state = apply_action_func(state, action)if max_actions_look_ahead > 0:return reward_func(new_state) + discount_factor \ * max(q(new_state, new_action, reward_func, apply_action_func, actions_for_state_func, max_actions_look_ahead-1)
for new_action in actions_for_state_func(new_state))else:return reward_func(new_state)
在这里,state 是定义环境状态的某个对象。action 是定义在状态中可以采取的有效动作的某个对象。reward_func 是一个函数,它返回给定状态的浮点值奖励。apply_action_func 返回将给定动作应用于给定状态后的新状态。actions_for_state_func 是一个函数,它返回给定状态的所有有效动作。
如果我们不必担心未来的奖励并且我们的状态空间很小,上述方法将获得良好的结果。它还要求我们能够准确地从当前状态模拟到未来状态,就像我们可以为棋盘游戏做的那样。但是,如果我们想要训练一个代理来玩动态电脑游戏,那么这些约束都不成立。当被提供来自电脑游戏的图像时,我们不知道在按下给定按钮后图像将会变成什么,或者我们将获得什么奖励,直到我们尝试为止。
Q 学习的实践
一个游戏可能每秒有 16-60 帧,并且经常会根据许多秒前所采取的动作来获得奖励。此外,状态空间是广阔的。在电脑游戏中,状态包含作为游戏输入的屏幕上的所有像素。如果我们想象一个屏幕被降低到 80 x 80 像素,所有像素都是单色和二进制,黑色或白色,那仍然是 2⁶⁴⁰⁰ 个状态。这使得状态到奖励的直接映射变得不切实际。
我们需要做的是学习 Q 函数的近似值。这就是神经网络可以应用其通用函数近似能力的地方。为了训练我们的 Q 函数近似值,我们将存储游戏状态、奖励和我们的代理在游戏中采取的行动。我们网络的损失函数将是其对前一状态的奖励的近似值与其在当前状态获得的实际奖励之间的差的平方,加上其对游戏中达到的当前状态的奖励的近似值乘以折扣因子的差的平方:

s 是先前的状态,a 是在该状态下采取的动作,而 0 < g < 1 是折扣因子。rewards 是返回在状态中采取行动的奖励的函数。actions 是返回在状态 s 中采取行动后你过渡到的 s’ 状态和该状态中所有可用的动作 a’。Q 是先前介绍的 Q 函数。
通过以这种方式训练连续的迭代,我们的 Q 函数逼近器将慢慢收敛到真实的 Q 函数。
让我们先为世界上最简单的游戏训练 Q 函数。环境是一个一维状态地图。一个假设的代理必须通过向左或向右移动来最大化其奖励来导航迷宫。我们将为每个状态设置奖励如下:
rewards = [0, 0, 0, 0, 1, 0, 0, 0, 0]
如果我们要可视化它,它可能会看起来像这样:

图 4:简单的迷宫游戏,代理可以在相连节点之间移动,并可以在顶部节点获得奖励 1。
如果我们把我们的代理放到这个“迷宫”中的第一个位置,他可以选择移动到 0 或 2 的位置。我们想要构建一个学习每个状态的价值的网络,并通过此可推断出采取移动到该状态的动作的价值。网络的第一次训练将仅学习每个状态的内在奖励。但在第二次训练中,它将利用从第一次训练中获得的信息来改进奖励的估计。在训练结束时,我们预期看到一个金字塔形状,在 1 个奖励空间中具有最大的价值,然后在离中心更远的空间上递减价值,因为您必须更进一步旅行,从而应用更多的未来折扣以获得奖励。以下是代码中的示例(完整示例在 Git 存储库中的q_learning_1d.py中):
import tensorflow as tf
import numpy as npstates = [0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0]
NUM_STATES = len(states)
我们创建一个states列表;列表中每个项的值是代理移动到该位置时获得的奖励。在这个示例中,它获得到第 5 个位置的奖励:
NUM_ACTIONS = 2
DISCOUNT_FACTOR = 0.5def one_hot_state(index):array = np.zeros(NUM_STATES)array[index] = 1.return array
这个方法将使用一个数字,并将其转换为我们状态空间的独热编码,例如,3 变为[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]:
session = tf.Session()
state = tf.placeholder("float", [None, NUM_STATES])
targets = tf.placeholder("float", [None, NUM_ACTIONS])
我们创建了一个 TensorFlow session和用于输入和目标的占位符;数组中的None用于小批量维度:
weights = tf.Variable(tf.constant(0., shape=[NUM_STATES, NUM_ACTIONS]))
output = tf.matmul(state, weights)
对于这个简单的例子,我们可以使用状态和动作奖励之间的线性关系来准确地评估一切,所以我们只需要创建一个output层,它是weights的矩阵乘法。不需要隐藏层或任何非线性函数:
loss = tf.reduce_mean(tf.square(output - targets))
train_operation = tf.train.GradientDescentOptimizer(0.05).minimize(loss)
session.run(tf.initialize_all_variables())
我们使用均方误差(MSE)作为损失函数和标准梯度下降训练。这就是我们最终将用作目标值的 Q-learning 的一部分:
for _ in range(1000):state_batch = []rewards_batch = []for state_index in range(NUM_STATES):state_batch.append(one_hot_state(state_index))
我们创建一个state_batch,其中的每个项目都是游戏中的每个状态,以独热编码形式表示。例如,[1, 0, 0, 0, 0, 0, 0, 0, 0],[0, 1, 0, 0, 0, 0, 0, 0, 0],以此类推。然后,我们将训练网络来逼近每个状态的值:
minus_action_index = (state_index - 1) % NUM_STATESplus_action_index = (state_index + 1) % NUM_STATES
对于每个状态,我们现在获取如果我们从该状态采取每个可能动作后所在的位置。注意,在这个示例中,状态会循环,所以从位置 0 向-1 移动会使您处于位置 8:
minus_action_state_reward = session.run(output, feed_dict={state: [one_hot_state(minus_action_index)]})plus_action_state_reward = session.run(output, feed_dict={state: [one_hot_state(plus_action_index)]})
我们使用我们的网络,即我们的 q 函数近似器,来获取它认为如果我们采取每个动作(minus_action_index和plus_action_index),我们将获得的奖励,即网络认为我们在它将我们放入的状态中能够获得的奖励:
minus_action_q_value = states[minus_action_index] + DISCOUNT_FACTOR * np.max(minus_action_state_reward)plus_action_q_value = states[plus_action_index] + DISCOUNT_FACTOR * np.max(plus_action_state_reward)]
在这里,我们有了现在常见的 Q 函数方程的 Python 版本。我们将移动到一个状态的初始奖励与DISCOUNT_FACTOR乘以我们在该状态下采取的动作所能获得的最大奖励相加:
action_rewards = [minus_action_q_value, plus_action_q_value]
rewards_batch.append(action_rewards)
我们将这些添加到rewards_batch中,它将用作训练操作的目标值:
session.run(train_operation, feed_dict={state: state_batch,targets: rewards_batch})print([states[x] + np.max(session.run(output, feed_dict={state: [one_hot_state(x)]}))for x in range(NUM_STATES)])
一旦我们获得了每个状态的完整奖励集,我们就会运行实际的训练步骤。如果我们运行此脚本并查看输出,我们可以感受到算法是如何迭代更新的。在第一次训练运行之后,我们看到了这个:
[0.0, 0.0, 0.0, 0.05, 1.0, 0.05, 0.0, 0.0, 0.0, 0.0]一切都是 0,除了奖励状态两边的项目。现在这两个状态基于你可以从它们移动到奖励方块上获得奖励。再向前走几步,你会发现奖励开始在状态之间传播:
[0.0, 0.0, 0.013, 0.172, 1.013, 0.172, 0.013, 0.0, 0.0, 0.0]此程序的最终输出将类似于这样:
[0.053, 0.131, 0.295, 0.628, 1.295, 0.628, 0.295, 0.131, 0.053, 0.02]正如你所看到的,数组中最高的奖励位于第五个位置,我们最初设置为有奖励的位置。但是我们给出的奖励只有 1;那么为什么这里的奖励比这个要高呢?这是因为 1.295 是在当前空间获得的奖励与我们可以在未来从这个空间移开并反复返回时获得的奖励的总和,这些未来的奖励通过我们的折扣因子 0.5 减少。
学习这种未来的无限奖励是好的,但是奖励通常是在执行具有固定结束的任务过程中学到的。例如,任务可能是在架子上堆放物体,当堆栈倒塌或所有物体都堆放完毕时结束。要将这个概念添加到我们的简单 1-D 游戏中,我们需要添加终端状态。这些将是达到后,任务就结束的状态;所以与其他任何状态相比,在评估其 Q 函数时,我们不会通过添加未来奖励来训练。要进行此更改,首先我们需要一个数组来定义哪些状态是终止状态:
terminal = [False, False, False, False, True, False, False, False, False, False]
这将设置为第五个状态,我们从中获得奖励的状态为终止状态。然后,我们只需要修改我们的训练代码以考虑这个终止状态:
if terminal[minus_action_index]:minus_action_q_value = DISCOUNT_FACTOR * states[minus_action_index]else:minus_action_state_reward = session.run(output, feed_dict={state: [one_hot_state(minus_action_index)]})minus_action_q_value = DISCOUNT_FACTOR *(states[minus_action_index] + np.max(minus_action_state_reward))if terminal[plus_action_index]:plus_action_q_value = DISCOUNT_FACTOR * states[plus_action_index]else:plus_action_state_reward = session.run(output,feed_dict={state: [one_hot_state(plus_action_index)]})plus_action_q_value = DISCOUNT_FACTOR * (states[plus_action_index] + np.max(plus_action_state_reward))
如果我们现在再次运行代码,输出将稳定为这样:
[0.049, 0.111, 0.242, 0.497, 1.0, 0.497, 0.242, 0.111, 0.0469, 0.018]动态游戏
现在我们已经学习了世界上最简单的游戏,让我们尝试学习一些更加动态的内容。Cart pole 任务是一个经典的强化学习问题。代理必须控制一个小车,上面平衡着一个杆,通过一个关节连接到小车上。在每一步,代理可以选择将小车向左或向右移动,并且每一步平衡杆的时候都会获得奖励 1。如果杆与竖直方向偏差超过 15 度,游戏就结束:

图 5:Cart pole 任务
要运行 Cart pole 任务,我们将使用 OpenAIGym,这是一个于 2015 年创建的开源项目,它以一致的方式提供了一种运行强化学习代理与一系列环境进行交互的方法。在撰写本文时,OpenAIGym 支持运行一系列 Atari 游戏,甚至还支持一些更复杂的游戏,如 doom,而且设置最少。可以通过运行以下命令来安装它:
pip install gym[all]在 Python 中运行 Cart pole 可以通过以下方式实现:
import gymenv = gym.make('CartPole-v0')
current_state = env.reset()gym.make方法创建了我们的代理将在其中运行的环境。传入"CartPole-v0"字符串告诉 OpenAIGym 我们希望这是车杆任务。返回的env对象用于与车杆游戏进行交互。env.reset()方法将环境置于其初始状态,并返回描述它的数组。调用env.render()将以可视方式显示当前状态,并对env.step(action)的后续调用允许我们与环境进行交互,以响应我们调用它的动作返回新的状态。
我们需要如何修改我们简单的一维游戏代码以学习车杆挑战?我们不再有一个明确定义的位置;相反,车杆环境将一个描述车和杆位置和角度的四个浮点值的数组作为输入给我们。这些将成为我们的神经网络的输入,它将由一个具有 20 个节点和一个tanh激活函数的隐藏层组成,导致一个具有两个节点的输出层。一个输出节点将学习当前状态向左移动的预期奖励,另一个输出节点将学习当前状态向右移动的预期奖励。以下是代码示例(完整的代码示例在 git repo 的deep_q_cart_pole.py中):
feed_forward_weights_1 = tf.Variable(tf.truncated_normal([4,20], stddev=0.01))
feed_forward_bias_1 = tf.Variable(tf.constant(0.0, shape=[20]))feed_forward_weights_2 = tf.Variable(tf.truncated_normal([20,2], stddev=0.01))
feed_forward_bias_2 = tf.Variable(tf.constant(0.0, shape=[2]))input_placeholder = tf.placeholder("float", [None, 4])
hidden_layer = tf.nn.tanh(tf.matmul(input_placeholder, feed_forward_weights_1) + feed_forward_bias_1)
output_layer = tf.matmul(hidden_layer, feed_forward_weights_2) + feed_forward_bias_2
为什么使用一个具有 20 个节点的隐藏层?为什么使用tanh激活函数?挑选超参数是一门黑暗的艺术;我能给出的最好答案是,当尝试时,这些值表现良好。但是知道它们在实践中表现良好,以及知道一些关于解决车杆问题需要什么样的复杂程度的信息,我们可以猜测为什么这可能指导我们选择其他网络和任务的超参数。
一个关于在监督学习中隐藏节点数量的经验法则是,它应该在输入节点数量和输出节点数量之间。通常,输入数量的三分之二是一个不错的区域。然而,在这里,我们选择了 20,是输入节点数量的五倍。一般来说,偏爱更少的隐藏节点有两个原因:第一个是计算时间,更少的单元意味着我们的网络运行和训练速度更快。第二个是减少过拟合并提高泛化能力。你已经从前面的章节中了解到了过拟合以及过于复杂模型的风险,即它完全学习了训练数据,但没有能力泛化到新数据点。
在强化学习中,这些问题都不那么重要。虽然我们关心计算时间,但通常瓶颈大部分时间花在运行游戏上;因此,额外的几个节点不太重要。对于第二个问题,在泛化方面,我们没有测试集和训练集的划分,我们只有一个环境,一个代理人在其中获得奖励。因此,过度拟合不是我们必须担心的事情(直到我们开始训练能够跨多个环境运行的代理人)。这也是为什么你经常看不到强化学习代理人使用正则化器的原因。这个警告是,随着训练过程的进行,我们的训练集的分布可能会因为我们的代理人在训练过程中的变化而发生显著变化。存在的风险是代理人可能会对我们从环境中获得的早期样本过度拟合,并导致学习在后来变得更加困难。
鉴于这些问题,选择隐藏层中的任意大数量节点是有意义的,以便给予最大可能性学习输入之间的复杂交互。但是唯一真正的方法是测试。图 6显示了运行具有三个隐藏节点的神经网络与小车杆任务的结果。正如您所看到的,尽管它最终能够学会,但其表现远不及具有 20 个隐藏节点的情况,如图 7所示:
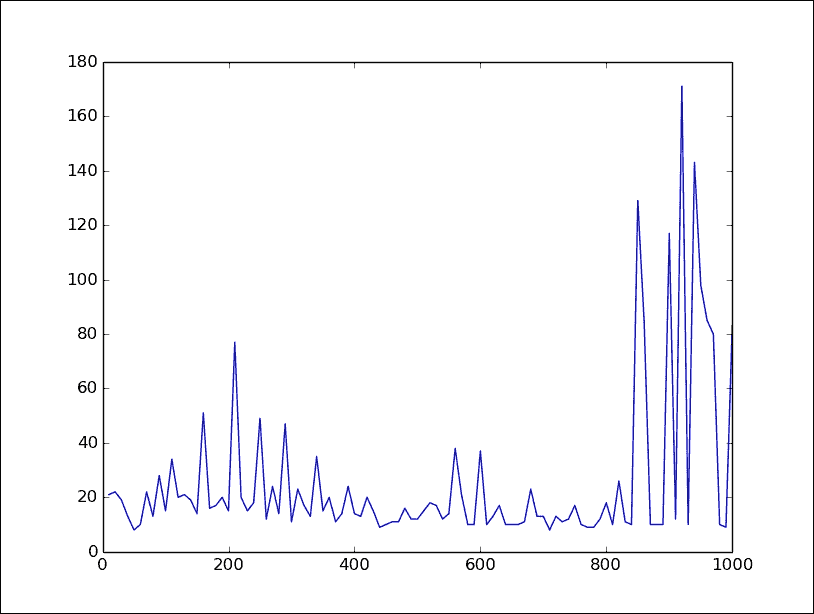
图 6:具有三个隐藏节点的小车杆,y = 最近 10 场比赛的平均奖励,x = 已玩的比赛
为什么只有一个隐藏层?任务的复杂性可以帮助我们估计这一点。如果我们考虑小车杆任务,我们知道我们关心输入参数的相互关系。杆的位置可能好也可能不好,这取决于小车的位置。这种交互水平意味着仅仅是权重的纯线性组合可能不够。通过快速运行,这个猜测可以得到确认,它将显示出尽管没有隐藏层的网络可以比随机更好地学习这个任务,但它的表现远不如单隐藏层网络。
更深的网络会更好吗?也许,但是对于只有这种轻微复杂性的任务来说,更多的层次往往不会改善事情。运行网络将确认额外的隐藏层似乎几乎没有什么影响。一个隐藏层为我们提供了我们在这个任务中所需要的容量。
至于选择tanh,有几个因素需要考虑。relu 激活函数之所以在深度网络中流行,是因为饱和。当运行一个具有激活函数范围受限的多层网络时,例如 logistic 函数的 0 到 1,许多节点会学会在接近 1 的最大值处激活。它们在 1 处饱和。但我们经常希望在输入更极端时信号更明显。这就是为什么 relu 如此流行的原因——它给一个层增加了非线性,同时不限制其最大激活。这在许多层网络中尤为重要,因为早期层可能会获得极端的激活,这对于向未来层发出信号是有用的。
只有一个层时,这不是一个问题,所以 sigmoid 函数是合理的。输出层将能够学习将来自我们隐藏层的值缩放到它们需要的值。有没有理由更喜欢 tanh 而不是 logistic 函数呢?我们知道我们的目标有时会是负数,并且对于一些参数组合,这可能是好的或坏的,具体取决于它们的相对值。这表明,提供由 tanh 函数提供的 -1 到 1 的范围可能比 logistic 函数更可取,其中要判断负相关性,首先必须学习偏差。这是事后的大量推测和推理;最好的答案最终是这种组合在这个任务中非常有效,但希望它能够在面对其他类似问题时给出一些最佳超参数的开始猜测的感觉。
要回到代码,我们的损失和训练函数在我们的推车杆任务中将是这样的:
action_placeholder = tf.placeholder("float", [None, 2])
target_placeholder = tf.placeholder("float", [None])q_value_for_state_action = tf.reduce_sum(tf.mul(output_layer, action_placeholder),reduction_indices=1)
q_value_for_state_action 变量将是网络为给定状态和动作预测的 q-value。将 output_layer 乘以 action_placeholder 向量,除了我们采取的动作外,其他所有值都将为 0,然后对其求和,这意味着我们的输出将是我们的神经网络对于仅仅那个动作的预期值的近似:
cost = tf.reduce_mean(tf.square(target_placeholder – q_value_for_state_action))
train_operation = tf.train.RMSPropOptimizer(0.001).minimize(cost)
我们的成本是我们认为的状态和动作的预期回报与由 target_placeholder 定义的应该是的回报之间的差异。
描述在第七章棋盘游戏的深度学习中的策略梯度方法的一个缺点是,所有训练都必须针对环境进行。一组策略参数只能通过观察其对环境奖励的影响来评估。而在 Q 学习中,我们试图学习如何评估一个状态和动作的价值。随着我们对特定状态价值的理解能力提高,我们可以利用这些新信息更好地评估我们曾经经历过的先前状态。因此,与其总是在当前经历的状态上进行训练,我们可以让我们的网络存储一系列状态,并针对这些状态进行训练。这被称为经验回放。
经验回放
每次我们采取一个动作并进入一个新状态时,我们都会存储一个元组previous_state, action_taken, next_reward, next_state和next_terminal。这五个信息片段就足以运行一个 Q 学习训练步骤。当我们玩游戏时,我们将把这些信息存储为一系列观察。
另一个经验回放有助于解决的困难是,在强化学习中,训练很难收敛。部分原因是我们训练的数据之间存在非常强的相关性。学习代理人经历的一系列状态将密切相关;如果一系列状态和行动的时间序列一起训练,会对网络的权重产生很大影响,并可能撤销大部分之前的训练。神经网络的一个假设是训练样本都是来自某个分布的独立样本。经验回放有助于解决这个问题,因为我们可以让训练的小批量样本从内存中随机抽样,这样样本之间就不太可能相关。
从记忆中学习的学习算法称为离线学习算法。另一种方法是在线学习,其中我们只能根据直接玩游戏来调整参数。策略梯度、遗传算法和交叉熵方法都是其示例。
运行带有经验回放的车杆的代码如下:
from collections import deque
observations = deque(maxlen=20000)
last_action = np.zeros(2)
last_action[0] = 1
last_state = env.reset()
我们从我们的observations集合开始。在 Python 中,一个 deque 是一个队列,一旦达到容量就会开始从队列开头删除项目。在这里创建 deque 时,其 maxlen 为 20,000,这意味着我们只会存储最近的 20,000 个观察。我们还创建了最后一个动作,np.array,它将存储我们从上一个主循环中决定的动作。它将是一个独热向量:
while True:env.render()last_action = choose_next_action(last_state)current_state, reward, terminal, _ = env.step(np.argmax(last_action))
这是主循环。我们首先渲染环境,然后根据我们所处的last_state决定采取什么动作,然后采取该动作以获得下一个状态:
if terminal:reward = -1
OpenAIGym 中的小车杆任务始终在每个时间步长给出奖励 1。当我们达到终止状态时,我们将强制给予负奖励,以便代理有信号学习避免它:
observations.append((last_state, last_action, reward, current_state, terminal))if len(observations) > 10000:train()
我们将此转换的信息存储在我们的观察数组中。如果我们有足够的观察结果存储,我们也可以开始训练。只有在我们有足够多的样本时才开始训练非常重要,否则少量早期观察结果可能会严重偏倚训练:
if terminal:last_state = env.reset()else:last_state = current_state
如果我们处于终止状态,我们需要重置我们的env以便给我们一个新的游戏状态。否则,我们可以将last_state设置为下一个训练循环的current_state。我们现在还需要根据状态决定采取什么行动。然后是实际的train方法,使用与我们之前的 1-D 示例相同的步骤,但改为使用来自我们观察的样本:
def _train():mini_batch = random.sample(observations, 100)
从我们的观察中随机取 100 个项目;这些将是要进行训练的mini_batch:
previous_states = [d[0] for d in mini_batch]actions = [d[1] for d in mini_batch]rewards = [d[2] for d in mini_batch]current_states = [d[3] for d in mini_batch]
将mini_batch元组解包为每种类型数据的单独列表。这是我们需要馈入神经网络的格式:
agents_reward_per_action = session.run(_output_layer, feed_dict={input_layer: current_states})
获取由我们的神经网络预测的每个current_state的奖励。这里的输出将是一个大小为mini_batch的数组,其中每个项目都是一个包含两个元素的数组,即采取左移动作的 Q 值估计和采取右移动作的 Q 值估计。我们取其中的最大值以获取状态的估计 Q 值。连续的训练循环将改进此估计值以接近真实的 Q 值:
agents_expected_reward = []for i in range(len(mini_batch)):if mini_batch[i][4]:# this was a terminal frame so there is no future reward...agents_expected_reward.append(rewards[i])else:agents_expected_reward.append(rewards[i] + FUTURE_REWARD_DISCOUNT * np.max(agents_reward_per_action[i]))
如果是非终止状态,将我们实际获得的奖励与我们的网络预测的奖励相结合:
session.run(_train_operation, feed_dict={input_layer: previous_states,action: actions,target: agents_expected_reward})
最后,对网络运行训练操作。
Epsilon 贪心
Q 学习的另一个问题是,最初,网络会非常糟糕地估计动作的奖励。但是这些糟糕的动作估计决定了我们进入的状态。我们早期的估计可能非常糟糕,以至于我们可能永远无法从中学习到奖励的状态。想象一下,在小车杆中,网络权重被初始化,使代理始终选择向左移动,因此在几个时间步长后失败。因为我们只有向左移动的样本,所以我们永远不会开始调整我们的权重以向右移动,因此永远无法找到具有更好奖励的状态。
对此有几种不同的解决方案,例如为网络提供进入新颖情境的奖励,称为新颖性搜索,或者使用某种修改来寻找具有最大不确定性的动作。
最简单的解决方案,也是被证明效果良好的解决方案之一,是从随机选择动作开始,以便探索空间,然后随着网络估计变得越来越好,将这些随机选择替换为网络选择的动作。这被称为 epsilon 贪心策略,它可以作为一种轻松实现一系列算法的探索方法。这里的 epsilon 是指用于选择是否使用随机动作的变量,贪心是指如果不是随机行动,则采取最大行动。在单车杆示例中,我们将这个 epsilon 变量称为probability_of_random_action。它将从 1 开始,表示 0 的随机动作几率,然后在每个训练步骤中,我们将其减小一些小量,直到它为 0 为止:
if probability_of_random_action > 0.and len(_observations) > OBSERVATION_STEPS:probability_of_random_action -= 1\. / 10000
在最后一步,我们需要的是将我们的神经网络输出转换为智能体动作的方法:
def choose_next_action():if random.random() <= probability_of_random_action:action_index = random.randrange(2)
如果随机值小于probability_of_random_action,则随机选择一个动作;否则选择我们神经网络的最大输出:
else:readout_t = session.run(output_layer, feed_dict={input_layer: [last_state]})[0]action_index = np.argmax(readout_t)new_action = np.zeros([2])
new_action[action_index] = 1
return new_action
这是训练进度与单车杆任务的图表:

图 7:单车杆任务,y = 过去 10 次游戏的平均长度 x = 所玩游戏的数量
看起来很不错。单车杆任务的成功定义为能够持续超过 200 轮。在 400 次游戏后,我们轻松击败了这个标准,平均每局游戏持续时间远远超过 300 轮。因为我们使用 OpenAIGym 设置了这个学习任务,现在可以轻松地设置到其他游戏中。我们只需要将gym.make行更改为以新输入游戏字符串为输入,然后调整我们网络的输入和输出数量以适应该游戏。在 OpenAIGym 中还有一些其他有趣的控制任务,例如摆锤和杂技,q-learning 在这些任务上也应该表现良好,但作为挑战,让我们来玩一些 Atari 游戏。
Atari Breakout
Breakout 是一款经典的 Atari 游戏,最初于 1976 年发布。玩家控制一个挡板,必须用它将球弹到屏幕顶部的彩色方块上。每次命中一个方块都会得分。如果球下落到屏幕底部超出挡板范围,玩家将失去一条生命。游戏在所有方块被销毁或玩家失去最初的三条生命后结束:

图 8:Atari Breakout
想想学习像 Breakout 这样的游戏比我们刚刚看过的单车杆任务要难多少。对于单车杆来说,如果做出了导致杆倾斜的错误动作,我们通常会在几个动作内收到反馈。在 Breakout 中,这样的反馈要少得多。如果我们将挡板定位不正确,可能是因为进行了 20 多次移动才导致的。
Atari Breakout 随机基准测试
在我们进一步探讨之前,让我们创建一个通过随机选择移动来玩 Breakout 的代理程序。这样,我们将有一个基准来评价我们的新代理程序:
from collections import dequeimport random
import gym
import numpy as npenv = gym.make("Breakout-v0")
observation = env.reset()
reward_per_game = 0
scores = dequeu(maxlen=1000)while True:env.render()next_action = random.randint(1, 3)observation, reward, terminal, info = env.step(next_action)reward_per_game += reward
我们随机选择我们的移动方向;在 Breakout 中,移动的方式如下:
-
1:向左移动
-
2:保持静止
-
3:向右移动
if terminal:scores.append(reward_per_game)reward_per_game = 0print(np.mean(scores))env.reset()如果我们已经玩了很多游戏,那么我们将存储并打印我们的分数,然后调用env.reset()继续玩。通过让这个运行一段时间,我们可以看到随机 Breakout 倾向于每场比赛得分约为 1.4 分。让我们看看我们能用 Q-learning 做得更好多少。
我们必须处理的第一个问题是从我们的车杆任务中进行调整的状态空间要大得多。对于车杆输入,是 210 x 160 像素的完整屏幕,每个像素包含三个浮点数,分别是每种颜色的值。要理解游戏,这些像素必须与方块、球拍和球相关联,然后这些物体之间的交互必须在某种程度上被计算。更让事情变得更加困难的是,单个屏幕图像不足以理解游戏正在发生什么。球随时间以某种速度移动;要理解最佳移动,你不能仅仅依赖于当前屏幕图像。
处理这个问题有三种方法:一种是使用循环神经网络,它将根据先前的输出来判断当前状态。这种方法可以奏效,但训练难度较大。另一种方法是将屏幕输入作为当前帧和上一帧之间的增量。在图 9中,你会看到一个例子。由于在 Pong 中颜色并没有提供信息,因此两个帧都已经被转换为灰度。上一帧的图像已从当前帧的图像中减去。这可以让你看到球的路径和两个球拍移动的方向:

图 9:Pong 游戏的增量图像
这种方法对于只由移动元素组成的游戏(如 Pong)效果很好,但对于像 Breakout 这样的游戏,其中方块的位置是固定的,我们将丢失有关游戏状态的重要信息。事实上,我们只能在方块被击中时看到它的一瞬间,而我们尚未击中的方块将保持不可见。
对于 Breakout,我们将采取的第三种方法是将当前状态设置为游戏最近 n 个状态的图像,其中 n 为 2 或更多。这允许神经网络拥有做出对游戏状态的良好判断所需的所有信息。对于大多数游戏来说,默认值 n 为 4 是很好的选择;但对于 Breakout,已经发现 n 为 2 就足够了。尽可能使用较低的 n 值是很好的,因为这会减少我们的网络所需的参数数量。
屏幕预处理
全部代码在 Git 存储库中的deep_q_breakout.py中。但我们将在此处逐个讨论与杆平衡示例的一些重要修改。首先是神经网络的类型。对于杆平衡,一个具有单个隐藏层的网络就足够了。但这涉及到将四个值映射到只有两个动作。现在,我们要处理screen_width * screen_height * color_channels * number_of_frames_of_state = 201600被映射到三个动作,这是一个更高级别的复杂度。
我们可以做的第一件事是将屏幕调整大小,以便为自己省点力。经过实验,我们发现可以将屏幕缩小后仍可玩 Breakout。缩小两倍仍可看到球,球拍和所有方块。而且,图像空间中大部分都不是对代理有用的信息,顶部的得分、侧面和顶部的灰色区域,以及底部的黑色空间都可以从图像中裁剪掉。这使我们能够将 210 * 160 的屏幕缩减为更容易管理的 72 * 84,将参数数量减少了四分之三以上。
在 Breakout 游戏中,像素的颜色不包含任何有用的信息,所以我们可以用单一颜色代替三种颜色,这只有黑色或白色,将输入的数量再次减少到三分之一。现在我们只剩下 72 * 84 = 6048 个位,需要两帧的游戏才能学习。我们现在来写一个方法来处理 Breakout 的屏幕:
def pre_process(screen_image):
screen_image参数将是我们从 OpenAIGym 的env.reset或env.next_step操作中获得的 Numpy 数组。它的形状为 210 * 160 * 3,每个项都是表示该颜色值的 0 到 255 之间的整数:
screen_image = screen_image[32:-10, 8:-8]
对 Numpy 数组的这个操作裁剪了图像,因此我们去掉了顶部的分数,底部的黑色空间和两侧的灰色区域:
screen_image = screen_image[::2, ::2, 0]
Python 数组的::2参数意味着我们取每隔一个项目,幸运的是 Numpy 也支持这种操作。末尾的 0 表示我们只取红色通道,这很好,因为我们马上就要把它变成只有黑白两种颜色。screen_image现在将被处理成 72 * 84 * 1 的大小:
screen_image[screen_image != 0] = 1
这将图像中不是完全黑色的一切设为 1。这在一些需要精确对比度的游戏中可能行不通,但对于 Breakout 游戏来说就有效了:
return screen_image.astype(np.float)
最后,这个方法返回的screen_image确保类型转换成浮点数。这会在以后将值放入 TensorFlow 时节省时间。图 10展示了处理前后屏幕的样子。经过处理后,尽管不太美观,图像仍然包含你玩游戏所需的所有元素:

图 10:处理前后的 Breakout 样子
这使我们的状态为 72842 = 12800 位,意味着我们需要将我们的三个动作映射到 2^(12800) 种可能的状态。这听起来很多,但问题变得更简单了,因为尽管这是打砖块游戏中可能的所有状态的完整范围,但只有一组相当小且可预测的状态会发生。挡板在固定区域水平移动;一个像素将激活球,一些方块将存在于中央区域。可以很容易地想象从图像中提取出一些特征,这些特征可能更好地与我们想要采取的动作相关联 —— 例如,我们的挡板与球的相对位置、球的速度等 —— 这是深度神经网络可以捕捉到的特征。
创建一个深度卷积网络
接下来,让我们用一个深度卷积网络来替换小车摆动示例中的单隐藏层网络。卷积网络首次出现在 第四章,“无监督特征学习”。卷积网络是有意义的,因为我们处理的是图像数据。我们创建的网络将有三个卷积层,导致一个单一的平坦层,导致我们的输出。使用四个隐藏层有一定的直观意义,因为我们知道我们将需要从像素中检测非常抽象的不变表示,但也已经被证明对于一系列架构是成功的。因为这是一个深度网络,relu 激活函数是有意义的。图 11 显示了网络的样子:

图 11:我们的网络架构,将学习玩打砖块游戏。
这是创建我们的深度卷积网络的代码:
SCREEN_HEIGHT = 84
SCREEN_WIDTH = 74
STATE_FRAMES = 2CONVOLUTIONS_LAYER_1 = 32
CONVOLUTIONS_LAYER_2 = 64
CONVOLUTIONS_LAYER_3 = 64
FLAT_HIDDEN_NODES = 512
这些常量将在我们的 create_network 方法中使用:
def create_network():input_layer = tf.placeholder("float", [None, SCREEN_HEIGHT, SCREEN_WIDTH, STATE_FRAMES])
我们将我们的输入定义为高度、宽度和状态帧的乘积;none 维度将用于状态批次:
convolution_weights_1 = tf.Variable(tf.truncated_normal([8, 8, STATE_FRAMES, CONVOLUTIONS_LAYER_1], stddev=0.01))convolution_bias_1 = tf.Variable(tf.constant(0.01, shape=[CONVOLUTIONS_LAYER_1]))
第一个卷积层将是一个 8x8 的窗口,跨越宽度和高度,同时接收状态帧。因此,它将获得关于当前图像的 8x8 部分和上一帧中该 8x8 补丁是什么样子的数据。每个补丁将映射到 32 个卷积,将成为下一层的输入。我们给偏置一个非常轻微的正值;这对于具有 relu 激活的层来说可能是有好处的,以减少 relu 函数造成的死神经元数量:
hidden_convolutional_layer_1 = tf.nn.relu(tf.nn.conv2d(input_layer, convolution_weights_1, strides=[1, 4, 4, 1], padding="SAME") + convolution_bias_1)
我们将权重和偏置变量放入卷积层中。这是通过 tf.nn.conv2d 方法创建的。设置 strides=[1, 4, 4, 1] 意味着 8x8 的卷积窗口将在图像的宽度和高度上每四个像素应用一次。所有的卷积层都将通过 relu 激活函数:
convolution_weights_2 = tf.Variable(tf.truncated_normal([4, 4, CONVOLUTIONS_LAYER_1, CONVOLUTIONS_LAYER_2], stddev=0.01))convolution_bias_2 = tf.Variable(tf.constant(0.01, shape=[CONVOLUTIONS_LAYER_2]))hidden_convolutional_layer_2 = tf.nn.relu(tf.nn.conv2d(hidden_convolutional_layer_1, convolution_weights_2, strides=[1, 2, 2, 1], padding="SAME") + convolution_bias_2)convolution_weights_3 = tf.Variable(tf.truncated_normal([3, 3, CONVOLUTIONS_LAYER_2, CONVOLUTIONS_LAYER_3], stddev=0.01))convolution_bias_3 = tf.Variable(tf.constant(0.01, shape=[CONVOLUTIONS_LAYER_2]))hidden_convolutional_layer_3 = tf.nn.relu(tf.nn.conv2d(hidden_convolutional_layer_2, convolution_weights_3, strides=[1, 1, 1, 1], padding="SAME") + convolution_bias_3)
创建接下来的两个卷积层的步骤与之前相同。我们的最后一个卷积层hidden_convolutional_layer_3现在必须连接到一个扁平层:
hidden_convolutional_layer_3_flat = tf.reshape(hidden_convolutional_layer_3, [-1, 9*11*CONVOLUTIONAL_LAYER_3])
这将把我们的卷积层重新整形为单个扁平层,其维度为 none,9,11,64:
feed_forward_weights_1 = tf.Variable(tf.truncated_normal([FLAT_SIZE, FLAT_HIDDEN_NODES], stddev=0.01))feed_forward_bias_1 = tf.Variable(tf.constant(0.01, shape=[FLAT_HIDDEN_NODES]))final_hidden_activations = tf.nn.relu(tf.matmul(hidden_convolutional_layer_3_flat, feed_forward_weights_1) + feed_forward_bias_1)feed_forward_weights_2 = tf.Variable(tf.truncated_normal([FLAT_HIDDEN_NODES, ACTIONS_COUNT], stddev=0.01))feed_forward_bias_2 = tf.Variable(tf.constant(0.01, shape=[ACTIONS_COUNT]))output_layer = tf.matmul(final_hidden_activations, feed_forward_weights_2) + feed_forward_bias_2return input_layer, output_layer
我们接着按照标准方式创建最后两个扁平层。请注意,最后一层没有激活函数,因为我们在这里学习的是给定状态下动作的价值,它具有无界范围。
现在我们的主循环需要添加以下代码,以便当前状态是多个帧的组合,在打砖块游戏中,STATE_FRAMES设置为2,但较高的数字也会起效:
screen_binary = preprocess(observation)if last_state is None:
last_state = np.stack(tuple(screen_binary for _ in range(STATE_FRAMES)), axis=2)
如果我们没有last_state,那么我们就构造一个新的 Numpy 数组,它只是当前的screen_binary堆叠了我们想要的STATE_FRAMES次:
else:screen_binary = np.reshape(screen_binary, (SCREEN_HEIGHT, SCREEN_WIDTH, 1))current_state = np.append(last_state[:, :, 1:], screen_binary, axis=2)
否则,我们将新的screen_binary添加到我们的last_state的第一个位置以创建新的current_state。然后我们只需要记住在主循环结束时将我们的last_state重新分配为等于我们的当前状态:
last_state = current_state
现在可能遇到的一个问题是,我们的状态空间现在是一个大小为 84742 的数组,并且我们想要以 100 万个这样的数组的顺序作为过去观察的列表,用于训练。除非您的计算机非常强大,否则可能会遇到内存问题。幸运的是,这些数组中很多将是非常稀疏的,并且只包含两种状态,因此可以使用内存压缩来解决这个问题。这将牺牲一些 CPU 时间来节省内存;因此在使用之前,请考虑哪个对您更重要。在 Python 中实现它只需要几行代码:
import zlib
import pickleobservations.append(zlib.compress(
pickle.dumps((last_state, last_action, reward, current_state, terminal), 2), 2))
在这里,我们压缩数据然后将其添加到我们的观察列表中:
mini_batch_compressed = random.sample(_observations, MINI_BATCH_SIZE)
mini_batch = [pickle.loads(zlib.decompress(comp_item)) for comp_item in mini_batch_compressed]
当从列表中取样时,我们只在使用时解压我们的小批量样本。
我们可能遇到的另一个问题是,尽管推车杆可能只需要几分钟就能训练好,但打砖块的训练时间可能会以天计算。为了防止出现意外情况,比如断电关机,我们希望在训练过程中随时保存我们的网络权重。在 Tensorflow 中,这只需要几行代码:
CHECKPOINT_PATH = "breakout"saver = tf.train.Saver()if not os.path.exists(CHECKPOINT_PATH):os.mkdir(CHECKPOINT_PATH)checkpoint = tf.train.get_checkpoint_state(CHECKPOINT_PATH)
if checkpoint:saver.restore(session, checkpoint.model_checkpoint_path)
这可以放在文件的开头,就在session.run(tf.initialize_all_variables())这一行上面。然后我们只需执行以下命令:
saver.save(_session, CHECKPOINT_PATH + '/network')
这意味着每隔几千次训练迭代都要创建我们网络的定期备份。现在让我们看一下训练的效果如何:

我们可以看到,在 170 万次迭代后,我们玩的水平远远超出了随机水平。这种相同的 Q 学习算法已经尝试过多种 Atari 游戏,并且通过良好的超参数调整,在 Pong、Space Invaders 和 Q*bert 等游戏中能够达到人类水平或更高的表现。
Q 学习中的收敛问题
但是,并不是一帆风顺的。让我们看看在前面序列结束后代理的训练如何继续:

如您所见,在某个时刻,代理的能力出现了巨大且持续的下降,然后回到了类似的水平。这种情况的可能原因(尽管我们很难确切知道原因)之一是 Q 学习的问题之一。
Q 学习是针对其自身对状态动作对的表现期望进行训练的。这是一个移动的目标,因为每次运行训练步骤时,目标都会发生变化。我们希望它们朝着对奖励更准确的估计值的方向移动。但随着它们朝着那里前进,参数的小变化可能会导致相当极端的振荡。
一旦我们陷入了比先前的能力评估更差的状态,每个状态动作评估都必须调整到这个新现实。如果我们每场比赛平均得分为 30 分,而通过我们的新策略,我们只能得到 20 分,整个网络都必须调整到这个情况。
目标网络冻结(Minh 等人 2015 年,《通过深度强化学习实现人类水平控制》- 自然)可以帮助减少这种情况。第二个神经网络,称为目标网络,被创建为主训练网络的副本。在训练期间,我们使用目标网络生成用于训练主神经网络的目标值。通过这种方式,主网络正在学习针对更固定的点。目标网络的权重被冻结,但一旦过了一定数量的迭代次数或达到收敛标准,目标网络就会更新为来自主网络的值。已经证明,这个过程可以显著加快训练速度。
很多强化学习可能遇到的另一个问题与具有相当极端奖励的游戏相关。例如,吃下力量丸然后吃掉鬼魂给予了非常高的奖励。这些接收到的极端奖励可能会导致梯度问题,并导致次优学习。修复这个问题的非常简单但不够令人满意的方法叫做奖励剪切,它只是将从环境中接收到的奖励剪切在某个范围内(-1 和 +1 常用)。这种方法花费很少的精力,但它的问题在于代理已经丢失了关于这些更大奖励的信息。
另一种方法是所谓的归一化深度 Q 网络(Hasselt 等人——跨多个数量级学习价值,2016)。这涉及将神经网络设置为在 -1 到 1 范围内输出状态和动作的预期奖励。将输出放入此范围后,它通过以下方程进行处理:

这里,U(s, a) 是神经网络的输出。参数 σ 和 µ 可以通过确保目标网络和主网络之间的缩放输出保持恒定来计算出,如目标网络冻结中所述:

使用这种方法,神经网络梯度将更多地指向学习状态和动作的相对值,而不是简单地消耗精力学习 Q 值的规模。
策略梯度与 Q 学习
虽然我们举了一个例子,使用策略梯度来学习棋盘游戏,使用 Q 学习来学习计算机游戏,但这两种技术并不局限于此类型。最初,Q 学习被认为是更好的技术,但随着时间的推移和更好的超参数调整,策略梯度常常表现更好。1991 年利用神经网络和 Q 学习在博弈中取得了世界最佳表现,最新研究表明策略梯度对大多数雅达利游戏效果最佳。那么何时应该使用策略梯度而不是 Q 学习呢?
一个限制是,Q 学习只适用于离散动作任务,而策略梯度可以学习连续动作任务。此外,Q 学习是确定性算法,对于某些任务,最佳行为涉及一定程度的随机性。例如,石头、剪刀、布,任何偏离纯随机性的行为都可能被对手利用。
也存在在线学习与离线学习的方面。对于许多任务,特别是机器人控制任务,在线学习可能非常昂贵。需要从记忆中学习的能力,因此 Q 学习是最佳选择。不幸的是,无论是 Q 学习还是策略梯度的成功都会受到任务和超参数选择的影响很大;因此,在确定新任务的最佳学习方法时,实验似乎是最好的方法。
策略梯度也更容易陷入局部最小值。Q 学习更有可能找到全局最优解,但这样做的成本是未经证实的收敛,性能可能在达到全局最优解的过程中发生剧烈波动或完全失败。
但也有另一种方法,它兼具两者的优点,这就是演员-评论员方法。
演员-评论员方法
强化学习方法可以分为三大类:
-
基于价值的学习:这个方法试图学习处于某个状态的预期奖励/价值。然后可以根据其相对值来评估进入不同状态的可取性。Q 学习就是基于价值的学习的例子。
-
基于策略的学习:在这种方法中,不尝试评估状态,而是尝试不同的控制策略,并根据环境的实际奖励进行评估。策略梯度就是例子。
-
基于模型的学习:在这种方法中,代理试图对环境的行为进行建模,并选择基于模型模拟其可能采取的行动结果来评估其模型的行为。
演员评论方法都围绕着使用两个神经网络进行训练的想法。第一个,评论者,使用基于价值的学习来学习给定状态的值函数,即代理人实现的预期奖励。然后,演员网络使用基于策略的学习来最大化评论者的值函数。演员正在使用策略梯度进行学习,但现在其目标已经改变。不再是通过游戏获得的实际奖励,而是使用评论者对该奖励的估计。
Q 学习的一个重大问题是,在复杂情况下,算法很难收敛。由于 Q 函数的重新评估改变了选择的动作,实际的价值奖励可能会有很大的变化。例如,想象一个简单的走迷宫机器人。在迷宫中遇到的第一个 T 形交叉口,它最初向左移动。 Q 学习的连续迭代最终导致它确定右移是更可取的方式。但现在,因为其路径完全不同,现在必须重新计算每个其他状态评估; 先前学到的知识现在价值很低。 Q 学习由于策略的微小变化可能对奖励产生巨大影响而受到高方差的影响。
在演员评论中,评论者所做的事情与 Q 学习非常相似,但存在一个关键区别:不是学习给定状态的假设最佳动作,而是学习基于演员当前遵循的最可能的次优策略的预期奖励。
相反,策略梯度存在相反的高方差问题。由于策略梯度是随机地探索迷宫,某些移动可能被选择,实际上相当不错,但由于在同一次试验中选择了其他不良移动而被评估为不良。这是因为尽管策略更稳定,但与评估策略相关的方差很高。
这就是演员评论的目标,旨在共同解决这两个问题。基于价值的学习现在方差较低,因为策略现在更加稳定和可预测,而基于策略梯度的学习也更加稳定,因为现在它具有一个从中获取梯度的方差值函数。
方差减少的基线
演员评论方法有几种不同的变体:我们将首先看一下基线演员评论。在这里,评论者试图学习代理人从给定位置的平均表现,因此其损失函数将是这样的:

这里, 是评论者网络在时间步t的状态的输出,r[t]是从时间步t开始的累积折现奖励。然后可以使用目标训练演员:
是评论者网络在时间步t的状态的输出,r[t]是从时间步t开始的累积折现奖励。然后可以使用目标训练演员:

因为基线是从这个状态的平均表现中得出的,这样做的效果是大幅降低训练的方差。如果我们使用策略梯度一次运行小车杆任务,再使用基线一次,其中我们不使用批量规范化,我们可以看到基线表现更好。但如果我们加入批量规范化,结果并没有太大不同。对于比小车杆更复杂的任务,奖励可能随状态变化而变化很多,基线方法可能会更大程度地改善事物。这方面的一个例子可以在actor_critic_baseline_cart_pole.py中找到。
广义优势估计器
基线方法在减少方差方面做得很好,但它不是真正的演员评论家方法,因为演员不是在学习评论者的梯度,而只是使用它来规范化奖励。广义优势估计器进一步前进,并将评论者的梯度纳入演员的目标中。
为了做到这一点,我们需要学习的不仅仅是代理处于的状态的价值,还有它采取的状态动作对的价值。如果V(s[t])是状态的价值,Q(s[t], a[t]*)*是状态动作对的价值,我们可以这样定义一个优势函数:

这将给我们带来动作a[t]在状态s[t]中的表现与代理在这个位置上平均动作之间的差异。向着这个函数的梯度移动应该会使我们最大化我们的奖励。而且,我们不需要另一个网络来估计Q(s[t], a[t]),因为我们可以利用我们在s[t+1]达到的状态的价值函数,而 Q 函数的定义如下:

在这里,r t 现在是该时间步的奖励,而不是基线方程中的累积奖励, 是未来奖励的折扣因子。我们现在可以将其代入,纯粹地给出我们的优势函数中的V项:
是未来奖励的折扣因子。我们现在可以将其代入,纯粹地给出我们的优势函数中的V项:

同样,这给我们提供了一个度量标准,用来判断评论者是否认为给定的动作改善了还是损害了位置的价值。我们将我们的演员损失函数中的累积奖励替换为优势函数的结果。这方面的完整代码在actor_critic_advantage_cart_pole.py中。这种方法用于小车杆挑战可以完成,但可能比仅使用批量规范化的策略梯度花费更长的时间。但对于像学习电脑游戏这样更复杂的任务,优势演员-评论家可能表现最好。
异步方法
在本章中我们看到了许多有趣的方法,但它们都受到训练速度非常慢的限制。当我们在基本控制问题上运行时,例如推车和杆子任务,这并不是什么问题。但是对于学习 Atari 游戏或者未来可能想要学习的更复杂的人类任务来说,数天到数周的训练时间就太长了。
对于策略梯度和演员-评论家来说,时间限制的一个重要部分是,在在线学习时,我们只能同时评估一个策略。我们可以通过使用更强大的 GPU 和更大的处理器获得显著的速度提升;在线评估策略的速度将始终作为性能的硬性限制。
这就是异步方法旨在解决的问题。其想法是在多个线程上训练相同的神经网络的多个副本。每个神经网络在线针对其线程上运行的环境的一个单独实例进行训练。不同于对每个训练步骤更新每个神经网络,更新跨多个训练步骤存储。每x个训练步骤,来自每个线程的累积批量更新被汇总在一起,并应用于所有网络。这意味着网络权重将根据所有网络更新中参数值的平均变化进行更新。
这种方法已经被证明适用于策略梯度、演员-评论家和 Q 学习。它极大地改善了训练时间,甚至提高了性能。在异步方法的最佳版本中,被认为是最成功的广义游戏学习算法的异步优势演员-评论家方法,在撰写本文时,被认为是最成功的广义游戏学习算法。
基于模型的方法
到目前为止,我们已经展示的方法可以很好地学习各种任务,但是通过这些方法训练出来的智能体仍然可能遭受重大限制:
-
它训练速度非常慢;一个人可以通过几次游玩学会像乒乓球一样的游戏,而对于 Q 学习,可能需要数百万次游玩才能达到类似的水平。
-
针对需要长期规划的游戏,所有技术表现都非常糟糕。想象一个平台游戏,玩家必须从房间的一侧取回一把钥匙,以打开另一侧的门。游戏中很少会发生这种情况,即使发生了,学习到这个钥匙是导致门获得额外奖励的机会也微乎其微。
-
它无法制定策略或以任何方式适应新颖的对手。它可能可以在与训练对手对战时表现良好,但在面对游戏玩法上有新颖性的对手时,学会适应将需要很长时间。
-
如果在环境中给出一个新的目标,就需要重新训练。如果我们正在训练打乒乓球作为左挡板,然后我们改为右挡板,我们将很难重新利用先前学到的信息。一个人可以毫不费力地做到这一点。
所有这些观点都可以说与一个中心问题相关。Q 学习和策略梯度在游戏中为奖励优化参数非常成功,但它们并没有学习如何理解游戏。人类学习在许多方面与 Q 学习有所不同,但一个显著的不同是,当人类学习一个环境时,他们在某种程度上正在学习这个环境的模型。然后他们可以使用该模型进行预测或者想象在环境中采取不同行动会发生什么事情。
想象一个玩家学习下棋的情景:他可以思考如果他进行某个特定的移动会发生什么。他可以想象在这一步之后棋盘会呈现什么样子,在那个新的位置他将会有哪些选择。他甚至可以将对手考虑进他的模型中,这个玩家是什么性格,倾向于采取什么样的走法,他的心情如何。
这就是基于模型的强化学习方法的目标。基于模型的 Pong 方法旨在建立一个模拟,模拟出它可能采取的不同行动的结果,并努力使该模拟尽可能接近现实。一旦建立起一个良好的环境模型,学习最佳行动就变得简单得多,因为代理可以将当前状态视为马尔可夫链的根,并利用一些来自第七章, 棋盘游戏的深度学习的技术,比如 MCTS-UCT,从其模型中抽样以查看哪些行动有最佳结果。它甚至可以更进一步,使用在自身模型上训练的 Q 学习或策略梯度,而不是在环境上训练。
基于模型的方法还有一个优势,那就是它们可能使人工智能更容易适应变化。如果我们已经学会了一个环境模型,但想要在其中改变我们的目标,我们可以重复使用同一个模型,只需简单地调整模型内的策略。如果我们讨论的是机器人或者在物理世界中运作的其他人工智能,通过玩数百万次的情节来学习策略梯度是完全不切实际的,特别是考虑到现实世界中的每次实验都会耗费时间、能量,并且存在着由于意外事件而带来的风险。基于模型的方法可以缓解许多这些问题。
构建模型引发种种问题。如果你正在构建一个基于模型的代理来学习 Pong,你知道它发生在一个二维环境中,有两个球拍和一个球,并且基本的物理规则。你需要这些元素都在你的模型中才能成功。但如果你手工制作这些,那么学习就不会那么多,并且你的代理远离了泛化学习算法。对于模型来说,什么是正确的先验?我们如何构建一个足够灵活,可以学习世界中遇到的复杂事物,同时仍能成功学习特定内容的模型?
更正式地说,学习模型可以看作是学习一个函数,它给出下一个状态在给定当前状态和动作对的情况下:

如果环境是随机的,此函数甚至可能返回可能的下一状态的概率分布。一个深度神经网络自然是该函数的一个很好的选择,然后学习将采取以下步骤:
-
构建一个输入为当前状态,输出为下一个状态和奖励的动作网络。
-
从环境中遵循一种探索性策略,收集一系列状态动作转换。简单地随机行动可能是一个很好的初始选择。
-
使用状态动作转换的集合以监督的方式训练网络,以下一状态和状态奖励作为目标。
-
使用训练好的网络转换来确定使用 MCTS、策略梯度或 Q-learning 的最佳移动。
如果我们以倒立摆任务为例,并以 MSE 作为损失函数,我们可以发现训练深度神经网络准确预测该环境的所有状态转换很容易,包括新状态何时终止。这个示例代码在 Git 仓库中。
甚至可以使用卷积和循环层来学习更复杂的 Atari 游戏模型。这是网络架构的一个例子:

来源:http://cs231n.stanford.edu/reports2016/116_Report.pdf
一个这样的网络使用了两个卷积/反卷积层和 128 个节点的 RNN 来学习预测 Pong 游戏中的下一帧。它能够成功地预测模糊版本的下一帧,但发现该模型不够稳健,无法运行 MCTS 来预测未来一两帧的事件。
这种方法的修改版本效果好得多。在这种方法中,网络不再尝试进行反卷积来预测下一帧图像,而是仅仅尝试预测 RNN 输入在下一帧中将是什么,从而消除了反卷积的需要。该网络可以学会以足够高的水平玩乒乓球,以击败游戏内的人工智能,训练后平均每场比赛赢得 2.9 分。这离完全训练的深度 Q 网络可以达到的 20.0 分还有很长的路要走,但对于一种非常新的方法来说,这仍然是一个有希望的结果。类似的结果也在 Breakout 游戏中实现了。
摘要
在本章中,我们研究了使用强化学习构建计算机游戏代理的方法。我们介绍了三种主要方法:策略梯度、Q 学习和基于模型的学习,并展示了如何将深度学习与这些方法结合使用以实现人类或更高水平的表现。我们希望读者能够从本章中获得足够的知识,以便能够将这些技术应用到他们可能想要解决的其他游戏或问题中。强化学习是当前非常令人兴奋的研究领域。谷歌、Deepmind、OpenAI 和微软等公司都在大力投资以解锁这一未来。
在下一章中,我们将探讨异常检测以及如何应用深度学习方法来检测金融交易数据中的欺诈实例。
第九章:异常检测
在第四章中,我们看到了特征学习的机制,特别是自动编码器作为监督学习任务的无监督预训练步骤的使用。
在本章中,我们将应用类似的概念,但用于不同的用例,即异常检测。
出色的异常检测器之一是找到智能数据表示,可以轻易表现出与正态分布的偏差。深度自动编码器在学习基础数据的高级抽象和非线性关系方面表现非常好。我们将展示深度学习如何非常适合异常检测。
在本章中,我们将首先解释离群点检测和异常检测概念之间的差异和共同之处。读者将通过一个想象的欺诈案例研究,随后通过示例,展示在现实世界应用中存在异常的危险以及自动和快速检测系统的重要性。
在进入深度学习实现之前,我们将介绍一些广泛应用于传统机器学习的技术家族及其当前局限性。
我们将应用在第四章中看到的深度自动编码器的架构,但用于一种特定的半监督学习,也称为新颖性检测。我们将提出两种强大的方法:一种基于重建错误,另一种基于低维特征压缩。
我们将介绍 H2O,这是一个最受欢迎的用于构建简单但可扩展的前馈多层神经网络的开源框架之一。
最后,我们将使用 H2O 自动编码器模型的 Python API 编写一些异常检测示例。
第一个例子将重用你在第三章中看到的 MNIST 数字数据集,深度学习基础和第四章中看到的无监督特征学习,但用于检测书写不良的数字。第二个例子将展示如何检测心电图时间序列中的异常脉动。
总结一下,本章将涵盖以下主题:
-
什么是异常和离群点检测?
-
异常检测的实际应用
-
流行的浅层机器学习技术
-
使用深度自动编码器进行异常检测
-
H2O 概述
-
代码示例:
-
MNIST 数字异常识别
-
心电图脉动检测
-
什么是异常和离群点检测?
异常检测通常与离群值检测和新奇检测相关,它是识别在同质数据集中偏离预期模式的项目、事件或观察结果。
异常检测是关于预测未知的。
每当我们在数据中发现一个不一致的观察结果,我们可以称之为异常或离群值。尽管这两个词经常可以互换使用,但实际上它们指的是两个不同的概念,正如 Ravi Parikh 在他的一篇博客文章中描述的那样(https://blog.heapanalytics.com/garbage-in-garbage-out-how-anomalies-can-wreck-your-data/):
“异常值是一个远离分布均值或中位数的合法数据点。它可能是不寻常的,比如 9.6 秒的 100 米赛跑,但仍在现实范围内。异常是由与其余数据生成过程不同的过程生成的非法数据点。”
让我们尝试用一个简单的欺诈检测示例来解释两者的区别。
在一份交易日志中,我们观察到一个特定客户每个工作日的午餐平均花费 10 美元。突然间,有一天他们花了 120 美元。这当然是一个离群值,但也许那天他们决定用信用卡支付整笔账单。如果这些交易中有几笔远高于预期金额的订单,那么我们可以识别出异常。异常是指当单一的罕见事件理由不再成立时,例如,连续三个订单的交易金额超过 120 美元。在这种情况下,我们谈论的是异常,因为已经从一个不同的过程生成了重复和相关的离群值模式,可能是信用卡欺诈,与通常的行为相比。
当阈值规则可以解决许多检测问题时,发现复杂的异常需要更高级的技术。
如果一个克隆的信用卡进行了大量金额为 10 美元的微支付,基于规则的检测器可能会失败。
通过简单地查看每个维度上的度量值,异常生成过程仍然可能隐藏在平均分布内。单一维度信号不会触发任何警报。让我们看看如果我们在信用卡欺诈示例中添加一些额外维度会发生什么:地理位置、当地时区的时间以及一周中的日期。
让我们更详细地分析同一个欺诈示例。我们的客户是一名全职员工,居住在罗马,但在米兰工作。每个周一早上,他乘火车去上班,然后在周六早上回罗马看朋友和家人。他喜欢在家做饭;他一周只出去吃几次晚餐。在罗马,他住在他的亲戚附近,所以他周末从不必准备午餐,但他经常喜欢和朋友出去过夜。预期行为的分布如下:
-
金额:介于 5 到 40 美元之间
-
位置:米兰 70%和罗马 30%
-
一天中的时间:70%在中午到下午 2 点之间,30%在晚上 9 点到 11 点之间。
-
一周中的日期:一周内均匀分布
有一天,他的信用卡被克隆了。欺诈者住在他的工作地附近,为了不被抓住,他们每天晚上约 10 点在一家同伙的小店里系统地进行 25 美元的小额支付。
如果我们只看单个维度,欺诈交易将只是略微偏离预期分布,但仍然可接受。金额和一周中的日期的分布效果将保持更多或更少相同,而位置和一天中的时间将稍微增加到米兰的晚上时间。
即使是系统地重复,他生活方式的微小变化也是一个合理的解释。欺诈行为很快就会变成新的预期行为,即正常状态。
让我们考虑联合分布:
-
约 70%的金额在米兰午餐时间约 10 美元左右,只在工作日
-
约 30%的金额在周末晚餐时间在罗马约 30 美元左右
在这种情况下,欺诈行为在第一次发生时会立即被标记为异常值,因为米兰夜间超过 20 美元的交易非常罕见。
给出前面的例子,我们可能会认为考虑更多维度可以使我们的异常检测更智能。就像任何其他机器学习算法一样,你需要在复杂性和泛化之间找到一个权衡。
如果维度过多,所有观察结果都会投射到一个空间中,其中所有观察结果彼此等距离。因此,一切都将成为“异常值”,按照我们定义异常值的方式,这本质上使整个数据集“正常”。换句话说,如果每个点看起来都一样,那么你就无法区分这两种情况。如果维度太少,模型将无法从草堆中发现异常值,可能会让它在大量分布中隐藏更长时间,甚至永远。
然而,仅识别异常值是不够的。异常值可能是由于罕见事件、数据收集中的错误或噪音引起的。数据总是肮脏的,充满了不一致性。第一条规则是“永远不要假设你的数据是干净和正确的”。找到异常值只是一个标准例程。更令人惊讶的是发现偶发且无法解释的重复行为:
“数据科学家意识到,他们最好的日子与发现数据中真正奇怪的特征的日子重合。”
《草堆与针》:异常检测,作者:Gerhard Pilcher & Kenny Darrell,数据挖掘分析师,Elder Research, Inc.
特定异常模式的持续存在是我们正在监控的系统中发生了变化的信号。真正的异常检测发生在观察到基础数据生成过程中的系统偏差时。
这也影响到数据预处理步骤。与许多机器学习问题相反,在异常检测中,你不能只过滤掉所有的异常值!尽管如此,你应该仔细区分它们的性质。你确实想要过滤掉错误的数据条目,删除噪声,并对剩余的数据进行归一化。最终,你想要在清理后的数据集中检测到新颖性。
异常检测的现实应用
异常情况可能发生在任何系统中。从技术上讲,你总是可以找到一个在系统历史数据中找不到的从未见过的事件。在某些情况下检测到这些观察结果的影响可能会产生巨大的影响(积极和消极)。
在执法领域,异常检测可以用于揭示犯罪活动(假设你在一个平均人足够诚实以便识别突出分布之外的罪犯的地区)。
在网络系统中,异常检测可以帮助发现外部入侵或用户的可疑活动,例如,一个意外或故意向公司内部网络以外泄露大量数据的员工。或者可能是黑客在非常用端口和/或协议上打开连接。在互联网安全的特定案例中,异常检测可以用于通过简单地观察非受信任域名上的访客激增来阻止新的恶意软件传播。即使网络安全不是你的核心业务,你也应该通过数据驱动的解决方案来保护你的网络,以便在出现未识别的活动时监控并提醒你。
另一个类似的例子是许多主要社交网络的身份验证系统。专门的安全团队已经开发出可以衡量每个单独活动或活动序列以及它们与其他用户的中位行为有多远的解决方案。每当算法标记一项活动为可疑时,系统将提示你进行额外的验证。这些技术可以大大减少身份盗窃,并提供更大的隐私保护。同样,相同的概念也可以应用于金融欺诈,正如我们在前面的例子中看到的那样。
由人类行为产生的异常是最受欢迎的应用之一,但也是最棘手的。这就像一场国际象棋比赛。一方面,你有专业领域的专家、数据科学家和工程师开发先进的检测系统。另一方面,你有黑客,他们了解这场比赛,研究对手的走法。这就是为什么这种系统需要大量的领域知识,并且应该设计成具有反应性和动态性的。
并非所有的异常都来自“坏人”。在营销中,异常可以代表孤立的,但高利润的客户,可以用定制的报价来定位他们。他们不同和特殊的兴趣和/或有利可图的个人资料可用于检测离群客户。例如,在经济衰退期间,找到一些潜在客户,尽管大趋势,他们的利润增长,这可能是适应你的产品和重新设计业务策略的一个想法。
其他应用包括医学诊断、硬件故障检测、预测性维护等。这些应用也需要灵活性。
商机,就像新的恶意软件一样,每天都可能出现,它们的生命周期可能非常短,从几小时到几周。如果你的系统反应慢,你可能会太晚,永远追不上你的竞争对手。
人工检测系统不能扩展,通常也遭受泛化的困扰。正常行为的偏差并不总是显而易见,分析师可能难以记住整个历史以进行比对,这是异常检测的核心要求。如果异常模式隐藏在数据中实体的抽象和非线性关系中,情况会变得复杂。需要智能和完全自动化的系统,能够学习复杂的互动关系,提供实时和准确的监控,是该领域创新的下一个前沿。
流行的浅层机器学习技术
异常检测并不新鲜,许多技术已经被广泛研究。建模可以分为两个阶段:数据建模和检测建模。
数据建模
数据建模通常包括将可用数据分组成我们希望检测的观察的粒度,以包含检测模型需要考虑的所有必要信息。
我们可以确定三种主要类型的数据建模技术:
点异常:这类似于单个异常值检测。我们数据集中的每一行对应一个独立的观察。目标是将每个观察分类为“正常”或“异常”,或者更好地提供一个数字异常得分。
上下文异常:每个点都附加有额外的上下文信息。一个典型的例子是在时间序列中查找异常,其中时间本身就代表了上下文。一月份冰淇淋销售的激增和七月份是不同的。上下文必须封装到额外的特征中。时间上下文可以是代表月份、季度、日期、星期几的分类日历变量,或布尔标志如是否 是 公共假期?
集体异常:代表潜在异常原因的观测模式。集体指标应该被智能地聚合成新的特征。一个例子是之前描述的欺诈检测示例。交易应该被分组到会话或间隔中,并且应该从序列中提取统计数据,比如付款金额的标准偏差、频率、两次连续交易之间的平均间隔、消费趋势等。
同样的问题可以用多种混合方法来解决,定义不同粒度的数据点。例如,可以独立地最初检测出个别异常交易,然后在时间上进行链接,封装时间上下文,并在分组序列上重复检测。
检测建模
无论数据类型如何,检测模型的通用输入由多维空间中的点(特征空间)组成。因此,通过一些特征工程,我们可以将任何异常表示转换为单个特征向量。
出于这个原因,我们可以将异常检测看作是离群值检测的特殊情况,其中单个数据点还包含了上下文和能够代表模式的任何其他信息。
与任何其他机器学习技术一样,我们既有监督学习方法,也有无监督学习方法。此外,我们还提出了半监督模式:
-
监督:以监督方式进行的异常检测也可以称为异常分类,例如垃圾邮件检测。在异常分类中,我们将每个观测标记为异常(垃圾邮件)或非异常(正常邮件),然后使用二元分类器将每个点分配到相应的类别。可以使用任何标准的机器学习算法,比如支持向量机、随机森林、逻辑回归,当然还有神经网络,尽管它不是本章的重点。
这种方法的主要问题之一是数据的倾斜度。根据定义,异常只占人口的一小部分。在训练阶段没有足够的反例将导致糟糕的结果。此外,一些异常可能以前从未见过,很难建立一个足够概括正确分类它们的模型。
-
无监督:纯粹的无监督方法意味着没有关于什么构成异常或不异常的基本事实(没有黄金标准)的历史信息。我们知道数据中可能存在异常,但没有关于它们的历史信息。
在这些场景中,检测也可以视为聚类问题,目标不仅是将相似的观测结果进行分组,还要识别所有其余的孤立点。因此,它带来了所有关于聚类问题的问题和考虑。数据建模和距离度量应该被谨慎选择,以便能够将每个点排列为靠近或远离现有的“正常行为”群集之一。
典型的算法是 k-means 或基于密度的聚类。聚类的主要困难在于对噪声的高度敏感和著名的维度灾难。
-
半监督:也被称为新颖性检测,半监督学习可能对你来说是一个新名词。它既可以被视为无监督学习(数据未标记),也可以被视为单类别监督学习(所有都在同一个标签下)。半监督的假设是训练数据集完全属于一个标签:“期望的行为”。我们不是学习用于预测“期望”还是“异常”的规则,而是学习用于预测观察到的点是否来自生成训练数据的相同源的规则。这是一个相当强的假设,也是使异常检测成为实践中最难解决的问题之一的原因。
流行的技术包括 SVM 单类别分类器和统计分布模型,例如多元高斯分布。
更多关于用于异常检测的多元高斯分布的信息可以在这个教程中找到:
dnene.bitbucket.org/docs/mlclass-notes/lecture16.html。下图显示了在二维空间中可视化的主分布中的异常值的经典识别:
具有单个异常值的正态分布的二维表示(
dnene.bitbucket.org/docs/mlclass-notes/lecture16.html)
使用深度自编码器进行异常检测。
使用深度学习的提出方法是半监督的,并且在以下三个步骤中广泛解释:
-
确定代表正态分布的一组数据。在这种情况下,“正常”一词代表一组我们有信心主要代表非异常实体的点,并且不应与高斯正态分布混淆。
识别通常是历史性的,我们知道没有官方确认的异常。这就是为什么这种方法不是纯无监督的原因。它依赖于这样一个假设:大多数观察结果是没有异常的。我们可以使用外部信息(即使是可用的标签)来实现所选子集的更高质量。
-
从这个训练数据集中学习“正常”是什么意思。训练模型将在其数学定义中提供一种度量标准;也就是说,将每个点映射到代表与另一个代表正态分布的点之间距离的实数。
基于异常分数的阈值进行检测。通过选择合适的阈值,我们可以在精度(更少的虚警)和召回(更少的漏报)之间实现所需的折衷。
这种方法的优点之一是对噪声的鲁棒性。我们可以接受训练中正常数据中的一小部分异常值,因为该模型将试图概括群体的主要分布而不是单个观测值。这种特性在泛化方面给我们带来了巨大的优势,相对于监督方法而言,后者仅限于过去所能观察到的内容。
此外,这种方法也可以扩展到带标签的数据,使其适用于各种类别的异常检测问题。由于建模过程中不考虑标签信息,我们可以将其从特征空间中丢弃,并将所有内容视为同一标签下的。在验证阶段,标签仍然可以用作基本真相。然后,我们可以将异常分数视为二元分类分数,并使用 ROC 曲线及相关指标作为基准。
对于我们的用例,我们将利用自编码器架构来学习训练数据的分布。正如我们在 第四章 无监督特征学习 中所看到的,网络被设计为具有任意但对称的隐藏层,输入层和输出层中的神经元数量相同。整个拓扑结构必须对称,即左侧的编码拓扑与右侧的解码部分相同,并且它们都共享相同数量的隐藏单元和激活函数:

H2O 训练手册中的自编码器简单表示(https://github.com/h2oai/h2o-training-book/blob/master/hands-on_training/images/autoencoder.png)
通常使用的损失函数是输入与输出层中相应神经元之间的 MSE(均方误差)。通过这种方式,网络被迫通过原始数据的非线性和压缩表示来逼近一个恒等函数。
深度自编码器也经常用作监督学习模型的预训练步骤和降维。事实上,自编码器的中心层可以用于表示降维的点,正如我们将在最后一个示例中看到的那样。
然后,我们可以开始使用完全重构的表示进行分析,这是编码和解码级联的结果。恒等自编码器会完全重构原始点的相同值。这并不是非常有用的。实际上,自编码器基于中间表示进行重构,这些表示使训练误差最小化。因此,我们从训练集中学习这些压缩函数,使得正常点很可能被正确重构,但异常值的 重构误差(原始点与重构点之间的均方误差)会更高。
然后我们可以使用重构误差作为异常分数。
或者,我们可以使用一个技巧,将网络的中间层设置得足够小,以便我们可以将每个点转换为低维压缩表示。如果将其设置为二或三,甚至可以可视化这些点。因此,我们可以使用自动编码器来降低维度,然后使用标准机器学习技术进行检测。
H2O
在我们深入研究示例之前,让我们花一些时间来证明我们选择使用 H2O 作为异常检测的深度学习框架的决定是合理的。
H2O 不仅仅是一个要安装的库或软件包。它是一个开源、功能丰富的分析平台,提供了机器学习算法和高性能并行计算抽象。
H2O 核心技术是围绕着为内存处理分布式数据集进行优化的 Java 虚拟机构建的。
可以通过基于 Web 的 UI 或在许多语言中以编程方式使用,例如 Python、R、Java、Scala 和 JSON 中的 REST API。
数据可以从许多常见数据源加载,例如 HDFS、S3、大多数流行的 RDBMS 和少数其他 NoSQL 数据库。
加载后,数据以H2OFrame的形式表示,使得习惯于使用 R、Spark 和 Python pandas 数据框架的人感到熟悉。
后端可以在不同引擎之间切换。它可以在您的机器上本地运行,也可以部署在 Spark 或 Hadoop MapReduce 之上的集群中。
H2O 将自动处理内存占用,并优化大多数数据操作和模型学习的执行计划。
它提供了针对经过训练模型的数据点进行快速评分的功能;据宣传,它的运行时间为纳秒级。
除了传统的数据分析和机器学习算法外,它还提供了一些非常强大的深度学习模型的实现。
构建模型的一般 API 是通过H2OEstimator。可以使用专门的H2ODeepLearningEstimator类来构建前馈多层人工神经网络。
我们选择 H2O 用于异常检测的一个主要原因是它提供了一个内置类,非常适用于我们的用例,即H2OAutoEncoderEstimator。
正如您将在以下示例中看到的那样,构建一个自动编码器网络只需要指定几个参数,然后它将自动调整其余部分。
估算器的输出是一个模型,根据要解决的问题,可以是分类模型、回归、聚类,或在我们的情况下是自动编码器。
H2O 的深度学习并不是穷尽的,但它相当简单直接。它具有自动自适应权重初始化、自适应学习率、各种正则化技术、性能调整、网格搜索和交叉折叠验证等功能。我们将在第十章 构建生产就绪的入侵检测系统 中探讨这些高级功能。
我们也希望很快在框架中看到 RNN 和更高级的深度学习架构的实现。
H2O 的关键点是可伸缩性、可靠性和易用性。它非常适合关心生产方面的企业环境。其简单性和内置功能也使其非常适合研究任务和希望学习和尝试深度学习的好奇用户。
开始使用 H2O
本地模式下的 H2O 可以简单地使用 pip 安装为依赖项。请按照 www.h2o.ai/download/h2o/python 上的说明操作。
第一次初始化时将自动启动本地实例。
打开 Jupyter 笔记本并创建一个 h2o 实例:
import h2o
h2o.init()
要检查初始化是否成功,应该打印出类似于 "Checking whether there is an H2O instance running at http://localhost:54321. connected." 的内容。
你现在已经准备好导入数据并开始构建深度学习网络了。
示例
以下示例是如何应用自动编码器来识别异常的概念证明。本章不涉及特定调优和高级设计考虑。我们将默认一些文献中的结果,而不深入研究太多已经在前几章中涵盖的理论基础。
我们建议读者仔细阅读第四章 无监督特征学习 和有关自动编码器的相关部分。
我们将在示例中使用 Jupyter 笔记本。
或者,我们也可以使用 H2O Flow (http://www.h2o.ai/product/flow/),这是一个类似 Jupyter 的 H2O 笔记本样式的用户界面,但我们不想在整本书中使读者感到困惑。
我们还假设读者对 H2O 框架、pandas 和相关绘图库 (matplotlib 和 seaborn) 的工作原理有基本了解。
在代码中,我们经常将一个 H2OFrame 实例转换为 pandas.DataFrame,以便我们可以使用标准绘图库。这是可行的,因为我们的 H2OFrame 包含小数据;但在数据量大时不推荐使用。
MNIST 数字异常识别
这是一个用于基准测试异常检测模型的相当标准的示例。
我们在第三章中已经看到过这个数据集,深度学习基础。不过,在这种情况下,我们不是在预测每个图像代表的数字,而是判断图像代表的是一个清晰的手写数字还是一个丑陋的手写数字。目标是识别写得不好的数字图像。
实际上,在我们的示例中,我们将丢弃包含标签(数字)的响应列。我们对每个图像代表的数字不感兴趣,而是更关心这个数字的清晰程度。
我们将遵循 H2O 教程中提供的相同配置,位于github.com/h2oai/h2o-training-book/blob/master/hands-on_training/anomaly_detection.md。
我们将以标准的pandas和matplotlib导入开始:
%matplotlib inline
import pandas as pd
from matplotlib import cm
import matplotlib.pyplot as plt
import numpy as np
from pylab import rcParams
rcParams['figure.figsize'] = 20, 12
from six.moves import range
接下来,我们将从 H2O 存储库导入数据(这是原始数据集的改编版本,以便更轻松地解析和加载到 H2O 中):
train_with_label = h2o.import_file("http://h2o-public-test-data.s3.amazonaws.com/bigdata/laptop/mnist/train.csv.gz")
test_with_label = h2o.import_file("http://h2o-public-test-data.s3.amazonaws.com/bigdata/laptop/mnist/test.csv.gz")
加载的训练和测试数据集表示每行一个数字图像,并包含 784 列,表示 28 x 28 图像网格中每个像素的 0 到 255 的灰度值,最后一列用作标签(数字)。
我们将只使用前 784 个作为预测因子,而将标签保留在验证中:
predictors = list(range(0,784))
train = train_with_label[predictors]
test = test_with_label[predictors]
H2O 教程建议使用一个只有 20 个神经元的隐藏层的浅层模型,以双曲正切作为激活函数,并进行 100 个 epochs(对数据进行 100 次扫描)。
目标不是学习如何调整网络,而是理解异常检测方法背后的直觉和概念。我们需要理解的是编码器容量取决于隐藏神经元的数量。过大的容量会导致一个恒等函数模型,这不会学习任何有趣的结构。在我们的案例中,我们设置了一个较低的容量,从 784 个像素到 20 个节点。这样,我们将迫使模型学习如何通过只使用表示数据相关结构的少数特征最好地逼近恒等函数:
from h2o.estimators.deeplearning import H2OAutoEncoderEstimator
model = H2OAutoEncoderEstimator(activation="Tanh", hidden=[20], ignore_const_cols=False, epochs=1)
model.train(x=predictors,training_frame=train)
在我们训练自编码器模型之后,我们可以预测测试集中使用我们的新降维表示重构的数字,并根据重构错误对它们进行排序:
test_rec_error = model.anomaly(test)
让我们快速描述一下重构错误:
test_rec_error.describe()
我们会看到重构错误在 0.01 到 1.62 之间,平均值大约为 0.02,不是对称分布。
让我们绘制出所有测试点的重构错误的散点图:
test_rec_error_df = test_rec_error.as_data_frame()
test_rec_error_df['id'] = test_rec_error_df.index
test_rec_error_df.plot(kind='scatter', x='id', y='Reconstruction.MSE')

我们可以看到测试集仅包含一个明显的异常点,而其余的点落在[0.0,0.07]范围内。
让我们将包括标签在内的测试特征集与重构错误连接起来,并抓取异常点,并尝试使用自编码器模型重构它:
test_with_error = test_with_label.cbind(test_rec_error)
outlier = test_with_error[test_with_error['Reconstruction.MSE'] > 1.0][0, :]
outlier_recon = model.predict(outlier[predictors]).cbind(outlier['Reconstruction.MSE'])
我们需要定义一个辅助函数来绘制单个数字图像:
def plot_digit(digit, title):df = digit.as_data_frame()pixels = df[predictors].values.reshape((28, 28))error = df['Reconstruction.MSE'][0]fig = plt.figure()plt.title(title)plt.imshow(pixels, cmap='gray')error_caption = 'MSE: {}'.format(round(error,2)) fig.text(.1,.1,error_caption)plt.show()
并且绘制原始异常值和其重构版本:
plot_digit(outlier, 'outlier')
plot_digit(outlier_recon, 'outlier_recon')

重构版本非常嘈杂,尽管异常值似乎清晰地表示数字三。我们会发现它有一个使它与其他三个数字不同的特定细节。
让我们更仔细地观察剩余点的错误分布:
test_rec_error.as_data_frame().hist(bins=1000, range=[0.0, 0.07])

根据分布,我们可以将“中心钟”在 0.02 处分为“好”数字(在左边)和“坏”数字(在右边)。最右边的尾部(大于 0.05)可以被视为“丑陋”的数字或最异常的数字。
现在我们将从“好”子集中挑选一些数字三的数字,并与我们的异常值进行比较:
digits_of_3 = test_with_error[(test_with_error['C785'] == 3) & (test_with_error['Reconstruction.MSE'] < 0.02)]
为了可视化多个数字,我们需要将绘图工具扩展为一个绘制图像网格的函数:
def plot_multi_digits(digits, nx, ny, title):df = digits[0:(nx * ny),:].as_data_frame()images = [digit.reshape((28,28)) for digit in df[predictors].values]errors = df['Reconstruction.MSE'].valuesfig = plt.figure()plt.title(title)plt.xticks(np.array([]))plt.yticks(np.array([]))for x in range(nx):for y in range(ny):index = nx*y+xax = fig.add_subplot(ny, nx, index + 1)ax.imshow(images[index], cmap='gray')plt.xticks(np.array([]))plt.yticks(np.array([]))error_caption = '{} - MSE: {}'.format(index, round(errors[index],2)) ax.text(.1,.1,error_caption)plt.show()
现在,我们可以绘制 36 个随机数字的原始值和重构值,排列在一个6(nx)乘以6(ny)的网格中:
plot_multi_digits(digits_of_3, 6, 6, "good digits of 3")
plot_multi_digits(model.predict(digits_of_3[predictors]).cbind(digits_of_3['Reconstruction.MSE']), 6, 6, "good reconstructed digits of 3")

原始的数字三的好数字

数字三的好数字的重构版本
乍一看,我们的异常值看起来与分类良好的图像并没有太大的不同。许多重构出来的图像看起来与它们的原始表示很相似。
如果我们仔细观察这些数字,我们会发现它们中没有一个数字具有几乎触及角落的底部左侧形状。
让我们选择索引为 1 的数字,得分为 0.02,并复制异常值图像的底部左侧部分(最后的 16 x 10 像素)。我们将重新计算修改后图像的异常分数:
good_digit_of_3 = digits_of_3[1, :]
bottom_left_area = [(y * 28 + x) for y in range(11,28) for x in range (0, 11)]
good_digit_of_3[bottom_left_area] = outlier[bottom_left_area]
good_digit_of_3['Reconstruction.MSE'] = model.anomaly(good_digit_of_3)
plot_digit(good_digit_of_3, 'good digit of 3 with copied bottom left from outlier')

神奇的是,均方误差上升到了 0.86。高异常值分数(~1.62)的剩余贡献可能是由异常的书写风格解释的。
这个解释意味着模型对噪音过于敏感。它会因为训练数据不包含足够的样本,而将一个数字图像标记为异常,仅仅是因为它具有合法的特性。这就是异常值检测器的“异常值”,一个错误的正例示例。
一般情况下,可以使用去噪自动编码器来解决这个问题。为了发现更健壮的表示,我们可以训练模型从它的嘈杂版本中重构原始输入。我们可以在第四章,无监督特征学习 中找到更多理论解释。
在我们的用例中,我们可以使用二项式抽样掩盖每个数字,在这个过程中,我们以概率 p 随机将像素设为 0。损失函数将是从嘈杂版本和原始版本的重构图像的误差。在撰写本文时,H2O 没有提供这个功能,也没有损失函数的定制。因此,为了这个例子而实现它将会太过复杂。
我们的数据集包含数字的标签,但不幸的是,它没有关于它们质量的任何评估。我们将不得不进行手动检查,以确保我们的模型运行良好。
我们将抓取底部的 100 个(好的)和顶部的 100 个(丑的)点,并将它们可视化成一个 10 x 10 的网格:
sorted_test_with_error_df = test_with_error.as_data_frame().sort_values(by='Reconstruction.MSE')
test_good = sorted_test_with_error_df[:100]
plot_multi_digits(test_good, 10, 10, "good digits")

最佳数字的重构误差
test_ugly = sorted_test_with_error_df.tail(100)
plot_multi_digits(test_ugly, 10, 10, "ugly digits")

最糟糕的丑数字的重构误差
从图中很容易看出,“好的”代表数字 1,这是最容易写的数字,因为它的简单结构是一条直线。因此,数字 1 的数字不太容易写错。
底部的组别显然很丑陋。圆形的形状使得在类似数字之间更难区分,并且它非常依赖于特定人的手写风格。因此,它们很可能代表“异常”。它们很可能偏离大多数人口的书写风格。
请注意,不同的运行可能会因为引入了用于可扩展性的随机性而导致不同的结果,这是由于 Hogwild!算法在以下章节中解释的竞争条件引起的。为了使结果可重复,您应该指定一个 seed 并设置 reproducibility=True。
心电图脉冲检测
在第二个例子中,我们将从 H2O 专门为异常检测用例准备的心电图时间序列数据中获取一份快照。
准备好的数据可从 H2O 公共存储库获取。原始数据集由www.physionet.org/提供。其他参考资料可在www.cs.ucr.edu/~eamonn/discords/找到。
准备好的数据集包含 20 个正常心跳的心电图时间序列加上三个异常心跳。
每一行有 210 列,表示有序序列中的值样本。
首先,我们加载心电图数据并生成训练集和测试集:
ecg_data = h2o.import_file("http://h2o-public-test-data.s3.amazonaws.com/smalldata/anomaly/ecg_discord_test.csv")
train_ecg = ecg_data[:20:, :]
test_ecg = ecg_data[:23, :]
让我们定义一个函数,堆叠并绘制时间序列:
def plot_stacked_time_series(df, title):stacked = df.stack()stacked = stacked.reset_index()total = [data[0].values for name, data in stacked.groupby('level_0')]pd.DataFrame({idx:pos for idx, pos in enumerate(total)}, index=data['level_1']).plot(title=title)plt.legend(bbox_to_anchor=(1.05, 1))
然后绘制数据集:
plot_stacked_time_series(ecg_data.as_data_frame(), "ECG data set")

我们可以清楚地看到前 20 个时间序列是正常的,而最后三个(标记为 21、22 和 23)与其他时间序列非常不同。
因此,我们只想对前 20 个样本训练模型。这一次,我们将使用由 50 个、20 个和 20 个、50 个边缘和两个神经元组成的五个隐藏层的更深层架构。请记住,自编码器的拓扑结构总是对称的,并且通常随着层大小的减小。其思想是学会如何将原始数据编码到一个较低维度的空间中,最小化信息的丢失,然后能够从这种压缩表示中重建原始值。
这一次,我们将为可再现性固定种子的值:
from h2o.estimators.deeplearning import H2OAutoEncoderEstimator
seed = 1
model = H2OAutoEncoderEstimator(activation="Tanh",hidden=[50,20, 2, 20, 50],epochs=100,seed=seed,reproducible=True)
model.train(x=train_ecg.names,training_frame=train_ecg
)
我们可以如下绘制重构信号:
plot_stacked_time_series(model.predict(ecg
_data).as_data_frame(), "Reconstructed test set")
重构信号看起来都非常相似。异常点(20、21 和 23)现在无法区分,这意味着它们将具有更高的重构误差。
让我们计算并绘制重构误差:
recon_error = model.anomaly(test_ecg)
plt.figure()
df = recon_error.as_data_frame(True)
df["sample_index"] = df.index
df.plot(kind="scatter", x="sample_index", y="Reconstruction.MSE", title = "reconstruction error")

很容易将最后的三个点识别为异常点。
现在让我们尝试从不同的角度看问题。通过将中心层大小设置为二,我们可以使用编码器输出来压缩和可视化我们的点在二维图中。我们将使用训练模型的deepfeatures API 来绘制一个新的数据框,其中包含指定隐藏层索引的二维表示(从 0 开始,中间的索引为 2):
from matplotlib import cm
def plot_bidimensional(model, test, recon_error, layer, title):bidimensional_data = model.deepfeatures(test, layer).cbind(recon_error).as_data_frame()cmap = cm.get_cmap('Spectral')fig, ax = plt.subplots()bidimensional_data.plot(kind='scatter', x= 'DF.L{}.C1'.format(layer+1), y= 'DF.L{}.C2'.format(layer+1), s = 500,c = 'Reconstruction.MSE',title = title,ax = ax,colormap=cmap)layer_column = 'DF.L{}.C'.format(layer + 1)columns = [layer_column + '1', layer_column + '2']for k, v in bidimensional_data[columns].iterrows():ax.annotate(k, v, size=20, verticalalignment='bottom', horizontalalignment='left')fig.canvas.draw()
然后我们使用先前训练的种子为 1 的模型来可视化所有点:
plot_bidimensional(model, test_ecg, recon_error, 2, "2D representation of data points seed {}".format(seed))
如果我们通过将种子设置为 2、3、4、5 和 6 重新训练模型重复相同的程序,我们可以得到如下结果:

如你所见,每个种子给出了完全不同的二维表示。更有趣的是异常点(标记为 20、21 和 22)始终具有相同的重构误差(由它们的颜色给出)。对于模型来说,这些都是有效的二维压缩表示,其中包含相同数量的信息,并且可以解码为原始时间序列。
然后我们可以使用自编码器来降低维度,然后使用无监督方法(例如基于密度的聚类)来将相似点分组。通过对每个种子重复聚类,我们可以应用一致性聚类来确定哪些点最大程度上相互一致(总是被聚类在一起的点)。这种方法不一定告诉你异常在哪里,但它将帮助你了解数据并发现可以进一步调查的小维度聚类。越小且与其他聚类相隔越远,异常得分越高。
总结
异常检测是许多应用中常见的问题。
在本章的开始,我们描述了一些可能的用例,并根据上下文和应用需求突出了主要类型和区别。
我们简要介绍了使用浅层机器学习算法解决异常检测的一些流行技术。主要差异在于特征生成的方式。在浅层机器学习中,这通常是一个手动任务,也称为特征工程。使用深度学习的优势在于它可以以无监督的方式自动学习智能数据表示。良好的数据表示可以极大帮助检测模型发现异常。
我们概述了 H2O 并总结了其用于深度学习的功能,特别是自编码器。
我们实施了一些概念验证示例,以学习如何应用自编码器来解决异常检测问题。
对于数字识别,我们根据模型重构误差给出的异常分数对每个图像进行了排序。
类似的方法还可以进一步扩展到应用程序,如签名验证、手稿的作者手写识别或通过图像照片进行故障检测。
数字识别示例是一种单点异常检测。它使用了仅有一个隐藏层的浅层架构。
对于心电图(ECG)示例,我们使用了更深的架构,并展示了一种基于压缩特征表示而不是完全重构的附加检测技术。我们使用网络的编码器部分将原始数据的非线性关系压缩成更小的维度空间。然后可以将新的表示用作预处理步骤,以应用常规的异常检测算法,如高斯多元分布。通过减少到二维空间,甚至可以可视化数据点并识别主椭圆分布边界上的异常。
尽管如此,自编码器并不是使用深度学习进行异常检测的唯一方法。您也可以采用监督方法,从数据中剔除部分信息,并尝试根据剩余信息进行估计。预测值将代表您的正常预期行为,与该值偏离的部分将代表异常。例如,在时间序列的情况下,您可以使用循环神经网络(RNN)或其在长短期记忆(LSTM)中的演变作为回归模型,以预测时间序列的下一个数值,然后使用预测值和观察值之间的误差作为异常得分。
我们更倾向于专注于这种半监督方法,因为它可以应用于许多应用程序,并且还因为它在 H2O 中得到了很好的实现。
另一个重要的细节是,大部分代码片段是用于数据分析、操作和可视化的。通过使用 H2O,我们可以仅用几行代码就实现深度神经网络。与其他框架相比,这相当令人印象深刻。此外,H2O 的估计器和模型提供了各种可自定义的参数和不同的配置。另一方面,我们发现 H2O 在扩展其用途到目前不支持的范围方面相当有限。总的来说,这是一项非常有前景的技术,还有很大的改进空间。
请注意,本章涵盖的技术仅作为深度学习如何应用于异常检测的概念验证。在处理生产数据时,有许多技术和实际方面的注意事项和陷阱需要考虑。我们将在第十章, 构建一个生产就绪的入侵检测系统中涵盖其中的一些。
第十章:构建生产就绪的入侵检测系统
在前一章中,我们详细解释了异常检测是什么以及如何使用自动编码器来实现它。我们提出了一种半监督方法来进行新颖性检测。我们介绍了 H2O,并展示了一些在该框架之上实现的例子(MNIST 数字识别和 ECG 脉冲信号),这些例子在本地模式下运行。这些示例使用了一个已经清理和准备好用作概念验证的小型数据集。
现实世界的数据和企业环境工作方式大不相同。在本章中,我们将利用 H2O 和一般的常见做法来构建一个可扩展的分布式系统,准备好在生产环境中部署。
我们将以入侵检测系统为例,旨在检测网络环境中的入侵和攻击。
我们将提出一些实际和技术问题,这些问题在构建用于入侵检测的数据产品时可能会遇到。
特别是,你将学到:
-
数据产品是什么
-
如何更好地初始化深度网络的权重
-
如何使用 HOGWILD! 并行化多线程随机梯度下降算法
-
如何利用 Apache Spark 和 Sparkling Water 在 Map/Reduce 上分布计算
-
调整可扩展性和实现参数的一些经验法则
-
自适应学习的全面技术列表
-
如何在有和无地面真实情况下进行验证
-
如何在精度和减少误报之间选择正确的权衡
-
考虑技术和业务方面的详尽评估框架的一个例子
-
模型超参数和调整技术的摘要
-
如何将训练好的模型导出为 POJO 并部署在异常检测 API 中
什么是数据产品?
数据科学的最终目标是通过采用数据密集型解决方案来解决问题。重点不仅在于回答问题,而且在于满足业务需求。
仅构建数据驱动的解决方案是不够的。如今,任何应用程序或网站都由数据驱动。构建一个用于列出待售物品的 Web 平台确实会使用数据,但不一定是一个数据产品。
Mike Loukides 给出了一个很好的定义:
数据应用程序从数据本身获取其价值,并因此生成更多数据;它不仅仅是一个带有数据的应用程序;它是一个数据产品。数据科学使得能够创建数据产品。
来源于《什么是数据科学》(
www.oreilly.com/ideas/what-is-data-science)
基本要求是系统能够从数据中提取价值——而不仅仅是消耗它——并生成知识(以数据或见解的形式)作为输出。数据产品是能够从原始数据中提取信息、建立知识并有效地消耗它以解决特定问题的自动化。
在异常检测章节中的两个示例定义了数据产品的概念。我们打开了一个笔记本,加载了一份数据快照,开始分析和尝试深度学习,并最终产生了一些证明我们可以应用自编码器来检测异常的图表。尽管整个分析是可重复的,在最好的情况下,我们可能已经建立了一个概念验证或玩具模型。这对解决现实世界的问题合适吗?这对你的业务来说是一个最小可行产品(MVP)吗?可能不是。
机器学习、统计学和数据分析技术并不是新事物。数学统计学的起源可以追溯到 17 世纪;机器学习是人工智能(AI)的一个子集,这是由艾伦·图灵在 1950 年通过他的Turing Test证明的。你可能会认为数据革命始于数据收集的增加和技术的进步。我认为这正是使数据革命能够顺利进行的原因。真正的转变可能发生在公司开始意识到他们可以通过信任他们的数据来创建新产品、提供更好的服务,并显著改进他们的决策。然而,创新不在于手动地在数据中寻找答案;而是在于整合从数据驱动系统中生成的信息流,这些信息流可以提取并提供能够推动人类行动的见解。
数据产品是科学和技术交汇的结果,旨在生成人工智能,能够在我们的代表进行规模化和不偏颇的决策。
因为数据产品通过消耗更多的数据而变得更好,而且它本身也会生成数据,所以生成效应理论上可以建立一个无限的信息流。因此,数据产品必须也是自适应的,并能在收集到新观测数据时逐步融合新知识。统计模型只是最终数据产品的一个组成部分。例如,在异常检测后的入侵检测系统会反馈一堆可用于后续模型训练的标记数据。
然而,数据分析在每个组织中也非常重要。在组织中经常会找到数据科学家和分析师混合团队。手动监督、检查和可视化中间结果对于构建成功的解决方案是必不可少的要求。我们的目标是消除有限产品的人工干预。换句话说,开发阶段涉及大量的探索性分析和手动检查点,但最终的交付通常是端到端的管道(或一堆独立的微服务),它以数据作为输入并产生数据作为输出。整个工作流最好是自动化、经过测试且可扩展的。理想情况下,我们希望在企业系统中集成实时预测,以便对每次检测做出反应。
例如,工厂中的一个大屏幕显示实时测量数据,来自活动机器,可以在出现问题时发出警报。这些数据产品不会替你修复机器,但会成为人类干预的支持工具。
人类互动通常应该是:
-
领域专业知识通过从经验中设置先验来
-
开发与测试
-
产品的最终消费
在我们的入侵检测系统中,我们将利用数据为安全分析团队推荐行动,以便他们能够优先考虑并做出更好的决策。
训练
训练网络意味着已经设计好了网络的拓扑结构。为此,我们建议参考第四章中的相应自编码器部分,对输入数据的类型和预期用例进行设计指南。
一旦我们定义了神经网络的拓扑结构,我们就处于起点了。模型现在需要在训练阶段进行拟合。我们将介绍一些适合于具有大型数据集的生产环境的训练算法的学习加速和扩展技术。
权重初始化
神经网络的最终收敛性可以受到初始权重的强烈影响。根据我们选择的激活函数,我们希望在最初的迭代中具有陡峭的斜率,以便梯度下降算法可以快速跳入最佳区域。
对于第一层(直接连接到输入层)的隐藏单元j,维度为d的训练样本x在第一次迭代的值之和为:

这里,w[0,i]是第i维的初始权重。
由于我们选择的权重是独立同分布的(i.i.d.),并且也独立于输入,单元j的均值为:

如果输入值x[i]被归一化为µ[x]=0和标准差s[x]=1,则均值为E(h[j]),方差为:

隐藏单元j的输出将通过其激活函数转换为:

这里的b是偏置项,可以简单地初始化为 0 或非常接近 0 的值,例如在 ReLU 激活函数的情况下为 0.01。
在 sigmoid 函数的情况下,对于大值(正负),我们得到非常平坦的曲线。为了获得较大的梯度,我们希望处于*[-4,+4]*范围内。
如果我们从均匀分布 中抽取初始权重,则单元j的方差变为:
中抽取初始权重,则单元j的方差变为:

h[j]落在[-4,+4]之外的概率非常小。我们有效地减少了过早饱和的概率,无论d的大小如何。
将初始权重分配为输入层节点数d的函数的技术称为均匀自适应初始化。H2O 默认应用均匀自适应选项,通常比固定均匀或正态分布更好。
如果我们只有一个隐藏层,只需初始化第一层的权重即可。在深度自动编码器的情况下,我们可以预先训练一堆单层自动编码器。也就是说,我们创建一堆浅自动编码器,其中第一个重建输入层,第二个重建第一个隐藏层的潜在状态,依此类推。
让我们使用标签L[i]来标识第i层,其中L[0]是输入层,最后一个是最终输出,其他所有层都是隐藏层。
例如,一个 5 层网络 可以拆分为 2 个网络
可以拆分为 2 个网络 和
和 。
。
第一个自动编码器,在训练后,将初始化L[1]的权重,并将输入数据转换为L[1]的潜在状态。这些状态用于训练第二个自动编码器,后者将用于初始化L[2]的权重。
解码层共享编码对应的初始权重和偏置。因此,我们只需要预训练网络的左半部分。
很可能,一个 7 层网络 可以拆分为
可以拆分为 、
、 和
和 。
。
一般来说,如果深度自动编码器有 N 层,我们可以将其视为一堆 堆叠的单层自动编码器:
堆叠的单层自动编码器:

预训练后,我们可以一起训练整个网络,使用指定的权重。
使用 HOGWILD!的并行 SGD
正如我们在前几章中所看到的,深度神经网络是通过反向传播给定损失函数产生的错误来进行训练的。反向传播提供了模型参数(每一层的权重 W 和偏差 B)的梯度。一旦我们计算出梯度,我们可以使用它来沿着最小化错误的方向移动。其中最流行的技术之一是随机梯度下降(SGD)。
SGD 可以总结如下。
-
初始化 W, B。
-
在收敛前:
-
获取训练样本i
-
 对于任何
对于任何 的W
的W -
 对于任何
对于任何 的B
的B
-
这里W是权重矩阵,B是偏置向量, 是通过反向传播计算的梯度,a是学习率。
是通过反向传播计算的梯度,a是学习率。
尽管 SGD 是许多机器学习模型最流行的训练算法,但它并不是高效的可并行化的。文献中提出了许多并行化版本,但大多数都受到处理器之间同步和内存锁限制的困扰,没有利用参数更新的稀疏性,这是神经网络的常见特性。
在大多数神经网络问题中,更新步骤通常是稀疏的。对于每个训练输入,只有少数与错误反应的神经元相关的权重被更新。一般来说,神经网络被构建成每个神经元只有在输入中存在特定特征时才激活。事实上,每次输入都激活的神经元并不是很有用。
HOGWILD! 是一种替代算法,允许每个线程覆盖其他线程的工作,并提供更好的性能。使用 HOGWILD!,多个核心可以异步处理训练数据的不同子集,并独立地对梯度更新做出贡献
如果我们把数据的维度 d 分成小的子集 E,然后 是由E的坐标索引的向量x的部分,我们可以把整个成本函数 L 分解为:
是由E的坐标索引的向量x的部分,我们可以把整个成本函数 L 分解为:

我们利用的关键属性是成本函数在某种意义上是稀疏的,即 ,而d可能很大,但是L[e]只在输入向量(
,而d可能很大,但是L[e]只在输入向量( )的较小部分上计算。
)的较小部分上计算。
如果我们有p个处理器,共享相同的内存,且都能访问向量x,则组件更新是原子的,因为具有加法性质:

这意味着我们可以更新单个单元的状态而无需单独的锁定结构。更新多个组件的情况则不同,在这种情况下,每个处理器都会异步重复以下循环:
在E中均匀随机采样e。
读取当前状态  并评估
并评估  。
。
对于  执行
执行  。
。
这里  是梯度
是梯度  乘以
乘以  。b[v]是一个位掩码向量,其中 1 对应于e的选定索引,*?*是步长,每个时期末会缩小一个因子ß。
。b[v]是一个位掩码向量,其中 1 对应于e的选定索引,*?*是步长,每个时期末会缩小一个因子ß。
因为梯度计算不是瞬时的,任何处理器可能随时修改x,我们可能会使用在许多时钟周期之前读取的旧值计算梯度来更新x。HOGWILD 的新颖之处在于提供了一种异步的、增量的梯度算法在其中收敛的条件。
特别是,已经证明梯度计算和使用之间的延迟始终小于或等于最大值 t t t。 t t t的上界值取决于处理器的数量,并且当我们接近算法的标准串行版本时, t t t收敛于 0。如果处理器的数量小于d^(1/4),那么我们获得的梯度步数几乎与串行版本相同,这意味着我们在处理器数量方面实现了线性加速。此外,输入数据越稀疏,处理器之间的内存争用可能性就越小。
在最坏的情况下,即使梯度计算具有计算密集性,该算法也始终可以提供一些速度改进。
你可以在原始论文中找到更多细节:people.eecs.berkeley.edu/~brecht/papers/hogwildTR.pdf。
总之,有许多优化学习速度、稳定性和陷入局部最优的概率的技术。非自适应学习率与动量结合可能会产生最好的结果,但这将需要调整更多的参数。Adadelta 是复杂性和性能之间的权衡,因为它只需要两个参数(ρ和ϵ),并且能够适应不同的场景。
自适应学习
在前面的段落中,我们已经看到了权重初始化的重要性和 SGD 算法的概述,其基本版本使用固定值的学习率 a。它们都是保证快速和准确收敛的重要条件。
可以采用一些先进的技术来动态优化学习算法。特别是,我们可以划分为两种类型的技术:一种旨在在任何方便的地方加快学习,另一种在接近局部最小值时减慢学习。
如果θ[t]表示我们在迭代t(权重和偏差参数)更新的数量,则一般 SGD 算法的更新如下:


学习率退火
我们需要选择α。学习率较低将需要很多迭代才能收敛,并且有搁置在局部最小值的风险。具有较高学习率会导致不稳定性。如果算法包含太多动能,那么最小化θ的步骤会导致其在周围跳来跳去。
学习率退火在训练期间消耗数据点时,会将α[t]缓慢降低。一种技术是在每k个样本更新一次 :
:

因此,衰减率将对应于需要将学习率减半所需的训练样本数的倒数。
动量
动量考虑了前几次迭代的结果来影响当前迭代的学习。引入并定义一个新的速度向量v,如下所示:

这里µ是动量衰减系数。我们不再使用梯度来改变位置,而是使用梯度来改变速度。动量项负责加快学习,在梯度继续指向同一方向的维度上,减慢那些梯度符号交替的维度,也就是那些对应于局部最优解区域的区域。
这个额外的动量项将有助于更快地收敛。不过过多的动量可能会导致发散。假设我们运行带动量的 SGD 足够的 epochs,最终速度最终将是:

如果µ小于 1,则这是一个几何级数;那么极限将收敛到与以下成比例的某物:

在这个公式中,当µ接近 1 时,系统会移动得太快。
此外,在学习初期,可能已经存在大梯度(权重初始化的影响)。因此,我们希望以一个小的动量开始(例如 0.5); 一旦大梯度消失,我们可以增加动量,直到它达到最终稳定值(例如 0.9),并保持恒定。
Nesterov 的加速
标准动量计算当前位置的梯度,并放大累积梯度方向的步骤。就像把球推下山并盲目地跟随山坡斜率一样。由于我们可以近似地预测球会落在哪里,所以我们希望在计算梯度时考虑这个信息。
让我们记住时间t处参数θ的值是:

如果我们省略二阶导数,?t 的梯度可以近似为:

更新步骤将使用时间t处的梯度而不是t – 1处的梯度计算:

Nesterov 变化首先会朝着先前累积梯度的方向迈出一大步,然后再根据跳跃后计算的梯度进行校正。这种校正防止了它过快地行进并提高了稳定性。
在球滚下山的类比中,Nesterov 校正根据山坡调整速度,并且仅在可能的情况下加速。
牛顿方法
而单阶方法只使用梯度和函数评估来最小化L,二阶方法也可以使用曲率。在牛顿方法中,我们计算损失函数L(θ)的二阶偏导数的 Hessian 矩阵HL(θ) 。逆 Hessian 将定义 a 的值,最终步骤方程为:

这里使用对角线的绝对值来确保负梯度方向最小化L。参数?用于平滑具有小曲率的区域。
通过使用二阶导数,我们可以在更有效的方向上执行更新。特别是,在平缓(平坦)曲率上我们会有更激进的更新,而在陡峭的曲率上会有更小的步长。
该方法的最佳属性是它没有超参数,除了平滑参数被固定为一个小值;因此它是一个维度较少的调整。主要问题在于计算和内存成本。H的大小是神经网络大小的平方。
已经开发了许多拟牛顿方法来近似逆 Hessian。例如,**L-BFGS(Limited Memory Broyden-Fletcher-Goldfarb-Shanno)**只存储几个向量,这些向量隐含地表示近似和所有先前向量的最后更新的历史。由于 Hessian 是从以前的梯度评估中近似构建的,因此在优化过程中不改变目标函数非常重要。此外,朴素实现需要在单个步骤中计算完整数据集,并且不太适合小批量训练。
Adagrad
Adagrad是 SGD 的另一种优化,根据先前所有计算梯度的 L2 范数每个维度进行学习率的调整。
α的值取决于时间t和第i个参数θ[t,i]:

这里G[t]是一个d x d大小的对角矩阵,元素i, i是θ[k,i]的梯度平方和直到迭代t – 1:

每个维度的学习率与梯度成反比。也就是说,较大的梯度将具有较小的学习率,反之亦然。
参数ϵ是一个平滑项,有助于避免除以零。它通常在 1e-4 和 1e-10 之间波动。
向量化更新步骤由按元素矩阵-向量乘法给出:

全局学习率a在分子上可以设置为默认值(例如 0.01),因为算法会在几次迭代后自动适应它。
现在我们已经获得了速率退火的相同衰减效果,但具有良好的性质,即每个维度随着时间的推移均匀化,就像二阶优化方法一样。
Adadelta
Adagrad 的一个问题是非常敏感于初始状态。如果初始梯度很大,并且我们希望它们像权重初始化中描述的那样很大,那么相应的学习率将从训练开始就非常小。因此,我们必须通过设置a的高值来抵消这种效应。
Adagrad 的另一个问题是分母一直在积累梯度,并在每次迭代中增长。这使得学习率最终变得无限小,以至于算法不能再从剩余的训练数据中学到任何新东西。
Adadelta 旨在通过将累积的过去梯度数量固定为某个W值,而不是t-1来解决后一个问题。它不是存储w个先前的值,而是在时间t上以递减的方式执行正在运行的平均值。我们可以用过去梯度的递减平均值替换对角矩阵G[t]:

这里的ρ是衰减常数,通常在 0.9 和 0.999 之间波动。
我们真正需要的是 的平方根,它近似了时间t下
的平方根,它近似了时间t下 的均方根(RMS):
的均方根(RMS):

更新步骤将是:

我们已经定义了Δ,即每次迭代时要添加到参数向量中的更新步骤。为了使这些方程正确,我们必须确保单位匹配。如果我们想象参数有一些假设的单位,Δ应具有相同的单位。到目前为止考虑的所有一阶方法都将Δ的单位与参数的梯度相关联,并假设成本函数L是无量纲的:

相比之下,牛顿法等二阶方法使用 Hessian 信息,或其近似值,来获取正确的更新步骤单位?:

对于 方程,我们需要用某个与t的 RMS 成比例的量替换项a。
方程,我们需要用某个与t的 RMS 成比例的量替换项a。
由于我们目前不知道?(t),所以我们只能计算相同大小的窗口w上t – 1 的均方根值:

其中使用相同的常数 ?,其目的是在 ?(0) = 0 时启动第一次迭代,并确保即使由于累积梯度在分母上饱和效应导致之前的更新很小,也能保持进展。
如果曲率足够平滑,我们可以近似  ,这将改变 Adadelta 的方程为:
,这将改变 Adadelta 的方程为:

最终的 Adadelta 方程覆盖了讨论的许多方法的特性:
-
它是对对角 Hessian 的近似,但只使用 ?L 和 ? 的 RMS 度量,并且每次迭代只进行一次梯度计算。
-
它始终遵循负梯度,就像普通的 SGD 一样。
-
分子滞后于分母 1 次。这使得学习对突然出现的大梯度更加稳健,在分子能够反应之前,它会增加分母并降低学习率。
-
分子起到了加速项的作用,就像动量法一样。
-
分母的作用类似于 Adagrad 中的每个维度衰减,但是通过固定的窗口保证了在任何步骤中,每个维度总是取得进展。
通过 Map/Reduce 进行分布式学习
将训练并行化在多个并发线程中是一个很大的改进,但它受到单台机器中可用核心和内存的数量的约束。换句话说,我们只能通过购买更多资源丰富和更昂贵的机器来实现垂直扩展。
结合并行和分布式计算可以实现所需的水平可扩展性,只要我们有增加额外节点的能力,理论上是无限的。
我们选择 H2O 作为异常检测框架的两个原因是它提供了一个易于使用的内置自动编码器实现,以及它在功能(我们想要实现的内容)和实现(我们如何实现它)之间提供了一个抽象层。这个抽象层提供了透明和可扩展的实现,允许以 map/reduce 的方式进行计算和数据处理的分布。
如果我们的数据在每个节点上均匀分区在较小的分片中,我们可以将高级分布式算法描述如下:
-
初始化:提供具有权重和偏置的初始模型。
-
洗牌:数据可以完全在每个节点上可用,也可以进行引导采样。我们将在段落末尾解决这个数据复制问题。
-
映射:每个节点将通过使用 HOGWILD!中的异步线程基于本地数据进行模型训练。
-
减少:每个训练模型的权重和偏置被平均到最终模型中。这是一个蒙德运算和可交换操作;平均是可结合和可交换的。
-
验证(可选):当前的平均模型可以针对验证集进行评分,以进行监控、模型选择和/或提前停止准则。
-
迭代:在满足收敛标准之前多次重复整个工作流程。

H2O 深度学习架构
复杂度时间将会是每次迭代 o(n/p + log§),其中 n 是每个节点中数据点的数量,p 是处理器的数量(节点)。线性项是映射计算,对数项是减少计算。
在前述公式中,我们没有考虑内存占用和数据洗牌的昂贵性。我们可以忽略减少步骤中模型平均的复杂性,因为我们假设模型参数相对于数据大小足够小。特别是,模型的大小是网络的神经元数量加上隐藏层的数量(偏置项)对应的参数数量。假设你有一百万个神经元,模型的总大小将小于 8MB。
最终的可扩展性将取决于:
-
计算并行性
-
内存缓冲
-
网络流量和 I/O
我们的目标是在模型精度和训练速度之间找到合适的权衡。
我们将使用术语迭代来表示仅在指定数量的train_samples_per_iteration上训练的单个 Map/Reduce 步骤。参数epochs将定义完成训练所需的数据通行证数量。
train_samples_per_iteration参数可以对应整个数据集,也可以更小(无替换的随机采样),甚至更大(有替换的随机采样)。
train_samples_per_iteration的值将影响内存占用和模型平均时间,也就是训练速度。
另一个重要的参数是布尔标志replicate_training_data。如果启用,整个数据的副本将在每个节点上可用。这个选项将允许每个模型训练得更快。
另一个关联参数是shuffle_trainingd_data,它决定数据是否可以在节点之间进行洗牌。
如果 N 是可用节点的数量,n 是训练数据集的大小,我们可以通过train_samples_per_iteration的特殊值和replicate_training_data的激活来识别一些特定的操作模式:
train_samples_per_iteration | replicate_training_data | 描述 |
|---|---|---|
| 0 | False | 只进行一个 epoch,在本地数据平均构建 N 个模型。 |
| -1 | True | 每个节点每次迭代处理整个数据集。这导致 N 个节点中的每个并行训练 N 个 epoch。 |
| -1 | False | 所有节点只处理本地存储的数据。一个 epoch 对应一个迭代。你可以有很多 epochs。 |
| -2 | True | 根据计算时间和网络开销的自动调整迭代次数。完整数据集被复制,进行无替换采样。 |
| -2 | False | 基于计算时间和网络开销自动调整每次迭代的样本数。只有本地数据可用;可能需要有放回地进行采样。 |
| > 0 | true | 从完整数据集中抽样的每次迭代的固定样本数量。 |
| > 0 | false | 从只有本地可用数据中抽样的每次迭代的固定样本数量。 |
如果n=1M且N=4,每个节点平均将存储 25K 个本地数据。如果我们设置samples_per_iteration=200K,单个 Map/Reduce 迭代将处理 20 万条记录。也就是说,每个节点将处理 5 万行。为了完成一个 epoch,我们需要 5 个 Map/Reduce 迭代对应 20 个本地训练步骤。
在前面的例子中,每个节点都将从本地可用数据中获取这 50K 个样本,根据本地数据量与请求的数据量的大小,可以有或没有对数据进行采样。采用有放回抽样可能会对模型的准确性产生负面影响,因为我们将在数据的重复和有限的子集上进行训练。如果我们启用复制,我们在每个节点上始终具有最多的本地数据,假设可以放入内存。
当我们想要精确处理本地数据量而不对数据进行采样(train_samples_per_iteration = -1)时,也是一个特殊情况。在这种情况下,在每次迭代中,我们将反复迭代相同的数据集,这对于多次迭代来说是多余的。
另一个特殊情况是当samples_per_iteration接近或大于启用复制的 N * n。在这种情况下,每个节点在每次迭代中将几乎使用整个数据集或更多进行训练。同样,在每次迭代中几乎使用相同的数据。
对于这两种特殊情况,shuffle_training_data会自动开启。也就是说,在每次训练之前本地数据将被随机混洗。
总之,根据数据大小的不同,我们可能会在每个节点上复制或不复制数据。H2O 提供了一种智能的方式,通过平衡 CPU 成本和网络开销自动调整和适应每次迭代的大小。除非你对系统进行微调有特殊要求,你可能会想使用自动调整选项。
深度学习的分布式算法将在准确性和训练速度上使你的最终模型受益。即使你可能没有一个非常大的数据集,这种分布式方法也是你考虑用于生产系统的东西。
Sparkling Water
尽管 H2O 可以在自己的独立集群上运行,但企业环境可能已经有一个分布式数据处理集群。即使物理上在相同的机器上,管理两个单独的集群也可能会很昂贵和冲突。
Apache Spark如今是处理大型数据集和构建可扩展数据产品的事实计算框架。H2O 包括 Sparkling Water,这是一个抽象层,让你可以将数据和算法模型与本机框架的所有功能和功能结合起来,同时还具有 Spark 的能力。
Sparkling Water 是用于进行机器学习的 ML 和 MLlib 框架的替代品,也是在 Spark 之上进行深度学习的少数替代品之一。
Spark 是用 Scala 设计和实施的。为了理解 H2O 和 Spark 的互操作性,我们需要参考本地 Scala API。
在 Sparkling Water 架构中,H2O 上下文与 Spark 上下文共存于驱动节点。此外,现在 Spark 2 有 SparkSession 作为主要入口点。很可能,H2O 和 Spark 执行器共存于工作节点。因此,它们共享相同的Java 虚拟机(JVM)和内存。资源分配和设置可以通过 YARN 来完成,YARN 是用于资源管理和作业调度的 Hadoop 组件。
你可以构建端到端的管道,结合了 Spark 和 MLlib 的优势以及 H2O 的特点。
例如,你可能会一起使用 Spark 和 H2O 进行数据整理并交替应用不同的转换函数。然后在 H2O 中进行深度学习建模。最终,你可以将训练好的模型返回,以在更大的应用程序中进行集成。
Spark 提供了三种 API 用于存储、建模和操纵数据。类型化的RDD(弹性分布式数据)、DataFrame 和最近统一的 DataSet API。DataFrame是sql.Row类型的 RDD;因此在这种集成中,它们被认为是类似的。
Sparkling Water 目前提供了在H2OFrame和 RDD 以及 DataFrame 之间的双向转换。将H2OFrame转换为 RDD 时,会创建一个包装器,将列名映射到在Product trait 中指定的类类型的相应元素。也就是说,你通常需要声明一个 Scala case 类,作为你从H2OFrame转换数据的容器。这种方法的局限性在于 case 类只能存储最多 21 个平面字段。对于更大的表,可以使用嵌套结构或字典。
将H2OFrame转换为 Spark DataFrame 不需要任何类型的参数。模式会动态地从H2OFrame的列名和类型中派生出来。
相反地,将现有的 RDD 或 DataFrame 转换成H2OFrame需要数据被复制和重新加载。由于H2OFrame被注册在键/值存储中,我们可以选择性地指定框架名称。在 RDD 的情况下,不需要指定明确的类型,因为 Scala 编译器可以推断出来。
列的基本类型必须与以下表格相匹配:
| Scala/Java 类型 | SQL 类型 | H2O 类型 |
|---|---|---|
| 无 | 二进制类型 | 数值 |
| Byte | ByteType | Numeric |
| Short | ShortType | Numeric |
| Integer | IntegerType | Numeric |
| Long | LongType | Numeric |
| Float | FloatType | Numeric |
| Double | DoubleType | Numeric |
| String | StringType | String |
| Boolean | BooleanType | Numeric |
| java.sql.TimeStamp | TimestampType | Time |
RDD 和 H2OFrame 在执行器 JVM 中共享相同的内存空间;在转换和复制后取消持久化它们是方便的。
现在我们已经了解了与 Spark 的本地 Scala 集成的工作原理,我们可以考虑 Python 包装器。
在驱动程序中,Python SparkContext 将使用 Py4J 启动驱动程序 JVM 和相应的 Java SparkContext。后者将创建 H2OContext,然后在 Spark 集群中启动 H2O 云。在此设置阶段之后,可以使用 H2O 和 PySpark 的 Python API 与数据和算法进行交互。
虽然 PySpark 和 PySparkling 是在 Python 中开发 Spark 和 H2O 的良好选择,但请记住 Python API 是 JVM 执行器的包装器。在分布式环境中维护和调试复杂项目可能比坚持使用本地 API 更加繁琐。尽管如此,在大多数情况下,Python API 都能正常工作,您不必在 Python 和本地语言之间切换。
测试
在讨论数据科学中测试的含义之前,让我们总结一些概念。
首先,总的来说,在科学中什么是模型?我们可以引用以下定义:
在科学中,模型是用于描述和解释无法直接体验的现象的想法、对象、甚至过程或系统的表示。
科学建模, 科学学习中心, http://sciencelearn.org.nz/Contexts/The-Noisy-Reef/Science-Ideas-and-Concepts/Scientific-modelling
还有这个:
科学模型是对现实世界现象的概念、数学或物理表示。当对象或过程至少部分理解但难以直接观察时,通常会构建模型。例如,用棍子和球表示分子,数学模型表示行星运动或概念原理如理想气体定律。由于实际自然界中的无限变化,除了最简单和最模糊的模型外,其他模型都是对真实世界现象的不完美表示。
在科学中,什么是模型?参考: https://www.reference.com/science/model-science-727cde390380e207
我们需要一个模型来简化系统的复杂性,以一种假设的形式。我们证明了深度神经网络可以描述复杂的非线性关系。尽管我们只是用比浅层模型更复杂的东西来逼近一个真实系统,但最终这只是另一个近似。我怀疑任何真实系统实际上都像神经网络一样工作。神经网络受到我们的大脑处理信息的方式的启发,但它们只是对它的巨大简化。
模型是根据一些参数(参数模型)来定义的。一方面,我们有一个将输入空间映射到输出的函数模型的定义。另一方面,我们需要一堆参数,函数需要这些参数来应用映射。例如,权重矩阵和偏差。
模型拟合和训练是指估计模型参数以使其最佳描述基础数据的过程。模型拟合通过定义依赖于模型参数和数据的损失函数的学习算法进行,然后尝试通过估计模型参数的最佳值集合来最小化这个函数。其中最常见的算法之一是梯度下降,以及它的所有变体。请参见之前的训练部分。对于自动编码器,你将最小化重构误差以及正则化惩罚(如果有的话)。
验证有时被与测试和评估混淆。验证和测试通常使用相同的技术和/或方法,但它们有两个不同的目的。
模型验证对应于一种假设验证。我们认为我们的数据可以被模型很好地描述。假设是,如果该模型是正确的,在经过训练(参数估计)后,它将以与训练集相同的方式描述未见过的数据。我们假设模型在我们将要使用的场景的限制下足够泛化。模型验证旨在找到一个量化模型如何拟合验证数据的度量(通常称为指标)。对于有标签数据,我们可以从验证数据上的异常分数计算的受试者工作特征(ROC)或精确率-召回率(PR)曲线中推导出一些指标。对于无标签数据,例如可以使用异常质量(EM)或质量-体积(MV)曲线。
尽管模型验证可以作为评估性能的一种方式,但它被广泛用于模型选择和调整。
模型选择是在一组候选模型中选择得分最高的模型的过程。候选模型可以是相同模型的不同配置,许多不同模型,选择不同特征、不同归一化和/或转换技术等。
在深度神经网络中,特征选择可能被省略,因为我们委托网络本身来扮演找出和生成相关特征的角色。此外,特征也通过学习过程中的正则化而被丢弃。
假设空间(模型参数)取决于拓扑选择、激活函数、大小和深度、预处理(例如图像白化或数据清洗)和后处理(例如,使用自动编码器减少维度,然后运行聚类算法)。我们可以将整个流程(给定配置上的组件集)看作模型,即使每个部分的拟合可能是独立进行的。
类似地,学习算法将引入一些参数(例如,学习率或衰减率)。特别是,因为我们希望最大化模型的泛化能力,通常在学习函数中引入正则化技术,这将引入额外的参数(例如,稀疏系数,噪声比或正则化权重)。
此外,算法的特定实施还具有一些参数(例如,周期,迭代次数)
我们可以使用相同的验证技术来量化模型和学习算法的性能。我们可以想象存在一个包括模型参数和超参数的单个大向量。我们可以调整所有内容以最小化验证度量标准。
在经过验证的模型选择和调整结束时,我们得到了一个系统,该系统:
-
取可用数据的一部分
-
分为训练和验证,确保不引入偏见或不平衡
-
创建由不同模型或不同配置、学习参数和实现参数构成的搜索空间
-
利用给定的损失函数(包括正则化)根据指定参数在训练数据上使用训练数据和学习算法对每个模型进行拟合
-
通过在验证数据上应用拟合模型来计算验证度量标准
-
选择使验证度量标准最小化的搜索空间中的一个点
选定的点将明确定义我们的最终理论。该理论表明我们的观察结果是从所选点对应的流程生成的模型生成的。
评估是验证最终理论的可接受性并从技术和业务角度量化其质量的过程。
科学文献显示了在历史进程中一个理论是如何取代另一个的。在不引入认知偏见的情况下选择正确的理论需要理性、准确的判断和逻辑解释。
确认理论,即指导科学推理而非演绎推理的研究,可以帮助我们定义一些原则。
在我们的情况下,我们想量化我们的理论的质量,并验证它是否足够好,并且与一个简单得多的理论(基线)相比具有显而易见的优势。基线可以是我们系统的一个天真的实现。在异常检测器的情况下,它可以简单地是一个基于规则的阈值模型,其中对于每个特征值超过静态阈值集的观察结果都标记为异常。这样一个基线可能是我们可以在一段时间内实现和维护的最简单的理论。它可能不会满足所有的接受标准,但它将帮助我们证明为什么我们需要另一个理论,即更高级的模型。
Colyvan,在他的书 数学的不可或缺性 中,总结了接受一个好的理论作为另一个理论替代品的四个主要标准:
-
简洁性/简约性:如果实证结果可以比较的话,简单比复杂更好。只有在需要克服某些限制时才需要复杂性。否则,无论是数学形式还是本体论承诺,都应该更喜欢简单。
-
统一性/解释力:能够一致解释现有和未来观察结果的能力。此外,统一性意味着尽量减少解释所需的理论设备数量。一个好的理论提供了一个直观的方法来解释为什么期望某个给定的预测。
-
大胆性/富有成效性:一个大胆的理论是一个想法,如果它是真实的,就能够预测和/或解释我们正在建模的系统的更多内容。大胆性有助于我们拒绝那些对我们已知的知识贡献很少的理论。可以制定一些新颖而创新的内容,然后尝试用已知证据来反驳它。如果我们无法证明一个理论是正确的,我们可以证明证据并不证明相反。另一个方面是启发式潜力。一个好的理论可以促使更多的理论。在两个理论之间,我们希望更偏向于更富有成效的那一个:具有更多被重新使用或扩展的潜力的那一个。
-
形式优雅:一个理论必须具有美学吸引力,并且应该足够强大,以便对一个失败的理论进行临时修改。优雅是以一种清晰、经济、简洁的方式解释某事的质量。优雅也能够更好地进行审查和维护。
在神经网络的情况下,这些标准被转化为以下内容:
-
我们更喜欢具有少量层和小容量的浅层模型。正如我们在网络设计部分讨论的那样,我们从简单的东西开始,如果需要的话逐渐增加复杂性。最终,复杂性将收敛,并且任何进一步的增加都不会带来任何好处。
-
我们将区分解释力和统一力:
-
解释力 与模型验证类似,但使用不同的数据集进行评估。我们之前提到我们将数据分成三组:训练、验证和测试。我们将使用训练和验证来制定理论(模型和超参数),然后模型会重新训练在两者的联合上,成为新的训练集;最终,已经验证过的最终模型将与测试集进行评估。在这个阶段,考虑在训练集和测试集上的验证指标非常重要。我们期望模型在训练集上表现更好,但两者之间有太大差距意味着模型无法很好地解释未见观察。
-
统一力 可以通过模型的稀疏性来表示。解释意味着将输入映射到输出。统一意味着减少应用映射所需的元素数量。通过添加正则化惩罚,我们使特征更稀疏,这意味着我们可以使用更少的回归器(理论设备)来解释观察和其预测。
-
-
果实性和果敢性 也可以分为两个方面:
-
果敢性 由我们的测试驱动方法来代表。除了第 2 点,我们试图明确模型的功能和原因,并在测试驱动方法中,我们把系统视为黑盒,并检查在不同条件下的回应。对于异常检测,我们可以系统地创建一些不同程度异常性的失败场景,并测量系统在何种程度上能够检测和反应。或者对于时间反应探测器,我们可以测量检测数据漂移需要多长时间。如果测试通过,那么我们就可以确定它无论如何都能正常工作。这可能是机器学习中最常见的方法之一。我们尝试一切我们认为可能奏效的方法;当我们的关键努力未能成功时,我们会谨慎评估并暂时接受(即,测试通过)。
-
果实性 来自于给定模型和系统的可重复性。它是否与特定用例过于紧密耦合?自编码器独立于底层数据表示的内容,它们使用非常少的领域知识。因此,如果理论是特定自编码器可用于解释系统在其工作条件下的情况,那么我们可以扩展它并在任何类型的系统中重复使用。如果我们引入一个预处理步骤(如图像白化),那么我们就假设输入数据是图像的像素,因此即使这个理论非常适合我们的用例,它对更大范围的可用性贡献度较小。然而,如果领域特定的预处理显著改善最终结果,那么我们将把它视为理论的重要部分。但如果贡献可以忽略不计,建议拒绝以换取更可重复的东西。
-
-
深度神经网络中优雅的一个方面可以被隐式地表示为从数据中学习特征而不是手动构建特征的能力。如果是这样,我们可以通过学习相关特征来衡量同一模型在不同场景下的自适应能力。例如,我们可以测试,在给定任何我们认为正常的数据集的情况下,我们是否可以构建一个始终学习正态分布的自动编码器。我们可以向同一数据集中添加或删除特征,或根据某些外部标准进行分组,从而生成具有不同分布的数据集。然后,我们可以检查学习到的表示,并测量模型的重构能力。与描述模型的具体输入特征和权重的函数相比,我们将其描述为具有学习能力的神经元实体。可以说,这是一个很好的优雅示例。
从商业角度来看,我们真的需要仔细考虑接受标准是什么。
我们至少要回答以下问题:
-
我们试图解决什么问题?
-
公司将如何从中受益?
-
在实际和技术层面上,模型将以何种方式集成到现有系统中?
-
最终的交付物如何才能具有可消化性和可执行性?
我们将尝试以入侵检测系统为例,并尝试回答这些问题。
我们想要实时监控网络流量,对每个单独的网络连接进行标记,标记为正常或可疑。这将使业务能够更好地防范入侵者。被标记的连接将被停止,并进入手动检查队列。安全专家团队将查看这些连接,并确定是否为误报,如果确认是攻击,则将该连接标记为其中一个可用的标签。因此,模型必须提供按异常分数排序的连接实时列表。列表中的元素数量不能超过安全团队的能力。此外,我们需要在允许攻击的成本、在发生攻击时的损害成本以及检查所需的成本之间取得平衡。为了以概率化方式限制最坏情况,最低要求是精确度和召回率。
所有这些评估策略都主要是定性而非定量定义的。很难比较和报告那些无法用数字衡量的内容。
数据科学从业者 Bryan Hudson 说:
如果你无法定义它,那就无法衡量它。如果无法测量,就不应该报告。首先定义,然后测量,再报告。
首先定义,然后测量,再报告。但要小心。我们可以考虑定义一个新的评估指标,考虑到迄今讨论的每个可能的方面和场景。
虽然许多数据科学家可能会尝试使用单一的实用函数来量化模型的评估,就像您在验证过程中所做的那样,但对于真正的生产系统,这是不被建议的。正如专业数据科学宣言中所表达的那样:
产品需要一系列措施来评估其质量。一个单一数字无法捕捉现实的复杂性。
专业数据科学宣言,www.datasciencemanifesto.org
即使在我们定义了关键绩效指标 (KPIs)之后,与基准相比,它们的实际含义是相对的。我们必须考虑为什么我们需要对比更简单或现有的解决方案。
评估策略需要定义测试用例和 KPI,以便我们可以涵盖最科学的方面和业务需求。其中一些是聚合数字,其他可以用图表表示。我们的目标是在单个评估仪表板中总结所有这些内容并有效地呈现它们。
在接下来的几节中,我们将看到一些使用标记和未标记数据进行模型验证的技术。
接下来,我们将看看如何使用一些并行搜索空间技术来调整参数空间。
最后,我们将给出使用 A/B 测试技术进行网络入侵使用情况的最终评估的示例。
模型验证
模型验证的目标是评估所训练模型的假设估计/预测的数值结果是否是对独立数据集的可接受描述。主要原因是由于训练集上的任何测量都会存在偏见和乐观主义,因为模型已经看到了这些观察结果。如果我们没有不同的验证数据集,我们可以从训练数据中留出一部分并将其用作基准。另一个常见的技术是交叉折叠验证,及其分层版本,其中整个历史数据集被分成多个折叠。为简单起见,我们将讨论留一法; 同样的标准也适用于交叉折叠验证。
训练集和验证集的划分不能完全随机。验证集应代表我们将用模型进行评分的未来假设场景。重要的是不要用与训练集高度相关的信息(泄露)污染验证集。
可以考虑一系列标准。最简单的是时间。如果您的数据是按时间顺序排列的,那么您将希望选择验证集总是在训练集之后。
如果您的部署计划是每天重新训练一次,并对接下来 24 小时的所有观察结果进行评分,那么您的验证集应恰好为 24 小时。24 小时后的所有观察结果将永远不会使用最后训练的模型进行评分,而是使用包括额外过去 24 小时观察结果的模型进行评分。
当然,仅使用 24 小时观察来进行验证太过严格了。我们需要进行几次验证,在每个分割点,我们将在该点之前训练模型,并在随后的验证窗口中验证数据。
分割点的选择取决于可用资源的数量。理想情况下,我们希望能够映射模型训练的确切频率,也就是说,过去一年左右每天一个分割点。
在分割训练和验证集时需要考虑一些操作事项:
-
无论数据是否具有时间戳,时间顺序应该根据当时可用的时间来设定。换句话说,假设数据生成和将其转换为训练特征空间之间有 6 小时的延迟;你应该考虑后者的时间,以便过滤掉分割点之前或之后的数据。
-
训练过程需要多长时间?假设我们的模型需要 1 小时进行重新训练;我们将在之前模型过期的前一小时安排重新训练。在其训练间隔期间得分将由以前的模型覆盖。这意味着我们无法对在最后一次收集训练数据的后续一小时内发生的任何观察进行预测。这在训练集和验证集之间引入了一个间隙。
-
模型在 day-0 恶意软件(冷启动问题)上表现如何?在验证过程中,我们希望以最坏的情况来评估模型,而不是过于乐观。如果我们可以找到一个分区属性,例如设备 ID 或网络卡 MAC 地址,那么我们可以将用户分成代表不同验证 fold 的桶,并进行交叉 fold 验证,依次选择一个用户 fold 来验证使用其他用户 fold 训练的模型。通过这样做,我们总是验证我们以前从未见过历史的用户的预测结果。这有助于真正衡量对于那些训练集已经包含同一设备在过去连接中的异常信号的情况的泛化能力。在这种情况下,模型很容易发现异常,但他们不一定与实际用例相匹配。
-
应用分区的属性(主键)的选择并不简单。我们希望尽可能减少 fold 之间的相关性。如果我们简单地根据设备 ID 进行分区,我们将如何处理同一用户或同一台机器具有多个设备,都使用不同的标识符注册的情况?选择分区键是一个实体解析问题。解决这个问题的正确方法是首先对属于同一实体的数据进行聚类,然后分区使得属于同一实体的数据绝不会分隔在不同的 fold 中。实体的定义取决于特定的用例背景。
-
在执行交叉折叠验证时,我们仍然需要确保时间约束。也就是说,对于每个验证折叠,我们需要在与其他训练折叠的交集中找到一个时间分割点。在实体 ID 和时间戳上过滤训练集;然后根据验证窗口和间隔来过滤验证折叠中的数据。
-
交叉折叠验证引入了一个类别不平衡的问题。按定义;异常是罕见的;因此我们的数据集是高度倾斜的。如果我们随机抽样实体,那么我们可能会得到一些没有异常的折叠和一些有太多异常的折叠。因此,我们需要应用分层交叉折叠验证,我们希望在每个折叠中均匀保留相同的异常分布。这在未标记数据的情况下是一个棘手的问题。但是我们仍然可以对整个特征空间运行一些统计,并以最小化折叠之间的分布差异的方式进行分区。
我们刚刚列举了在定义分割策略时需要考虑的一些常见陷阱。现在我们需要计算一些度量标准。验证度量标准的选择应与真实操作用例显著相关。
我们将在接下来的几节中看到为标记和未标记数据定义的几个可能的度量。
标记数据
标记数据的异常检测可以被视为标准的二元分类器。
让 成为我们的异常评分函数,其中分数越高,成为异常的概率就越高。对于自编码器来说,它可以简单地是重构误差上计算的 MSE,并重新缩放为[0,1]范围内。我们主要关心的是相对排序而不是绝对值。
成为我们的异常评分函数,其中分数越高,成为异常的概率就越高。对于自编码器来说,它可以简单地是重构误差上计算的 MSE,并重新缩放为[0,1]范围内。我们主要关心的是相对排序而不是绝对值。
我们现在可以使用 ROC 或 PR 曲线进行验证。
为此,我们需要设置一个与评分函数s对应的阈值a,并将具有评分s(x) = a的所有点x视为异常。
对于每个a值,我们可以计算混淆矩阵如下:
| 观察数量 n | 预测的异常 s(x) = a | 预测的非异常 (s < a) |
|---|---|---|
| 真异常 | 真正例(TP) | 假负例(FN) |
| 真负例 | 假正例(FP) | 真负例(TN) |
从与 a 值对应的每个混淆矩阵中,我们可以推导出真正例率(TPR)和假正例率(FPR)的度量标准:


我们可以在二维空间中绘制每个a值,生成包含 的 ROC 曲线。
的 ROC 曲线。
我们解释图的方式如下:每个切断点告诉我们在 y 轴上我们在验证数据中发现的异常的比例(召回率)。x 轴是误报比率,标记为异常的观察值在所有正常观察值中的比例。
如果我们将阈值设定为接近 0,意味着我们将一切标记为异常,但所有正常的观察将产生虚警。如果我们将其设定为接近 1,我们将永远不会触发任何异常。
假设对于给定的 a 值,相应的 TPR = 0.9 和 FPR = 0.5;这意味着我们检测到了 90%的异常,但异常队列中也包含了一半的正常观察。
最佳阈值点将位于坐标(0,1)处,对应于 0 假阳性和 0 假阴性。这种情况从来不会发生,因此我们需要在召回率和虚警率之间找到一个折衷。
ROC 曲线的一个问题是它不能很好地展现高度偏斜的数据集的情况。如果异常只占数据的 1%,那么* x 轴很可能会很小,我们可能会放松阈值以增加召回率,而对 x *轴没有太大的影响。
精确度-召回率(PR)图交换轴,并用精确度替换 FPR 定义为:

精确度是一个更有意义的指标,它代表了检测到的异常中的异常部分。
现在的想法是最大化两个轴。在* y 轴上,我们可以观察到将要被检查的部分的预期结果, x *轴告诉我们有多少异常将会遗漏,它们都取决于异常概率。
有一个二维图可以帮助我们理解检测器在不同场景下的行为,但为了应用模型选择,我们需要最小化一个单一的效用函数。
有一系列措施可以用来综合这一点。最常见的是曲线下面积(AUC),它是检测器在任何阈值下的平均性能指标。对于 ROC 曲线,AUC 可以解释为均匀抽取的随机异常观察排在均匀抽取的随机正常观察之前的概率。这对于异常检测并不是非常有用。
精确度和召回率的绝对值在同一尺度上被定义,可以使用调和平均值(也称为F-score)进行汇总:

在这里,ß是一个系数,它权衡了召回率比精确度更重要的程度。
为了将评分缩放在 0 和 1 之间,添加了术语 。
。
对称的情况下,我们得到了 F1 分数:

安全分析员也可以根据精确度和召回率的最小要求设定偏好。在这种情况下,我们可以将偏好中心得分定义为:

PC 分数使我们能够选择一系列可接受的阈值,并根据 F1 分数优化中间点。第一个情况中的单位术语是添加的,因此它将始终优于第二个情况。
无标签的数据
不幸的是,大多数情况下数据都没有标签,而且需要太多的人力去对每个观察结果进行分类。
我们提出了两种不需要标签的 ROC 和 PR 曲线的替代品:质量体积(MV)和 超额质量(EM)曲线。
这次让  成为我们的逆异常评分函数,其中分数越小,异常的概率越高。在自动编码器的情况下,我们可以使用重构误差的倒数:
成为我们的逆异常评分函数,其中分数越小,异常的概率越高。在自动编码器的情况下,我们可以使用重构误差的倒数:

这里 ϵ 是一个小项,用于在接近零的重构误差情况下稳定。
评分函数将对每个观察结果进行排序。
让  成为一组 i.i.d. 观测值 X[1],…,X[n] 的正态分布的概率密度函数,F 是其累积密度函数。
成为一组 i.i.d. 观测值 X[1],…,X[n] 的正态分布的概率密度函数,F 是其累积密度函数。
函数 f 对于任何不属于正态分布的观察结果都会返回一个非常接近 0 的分数。我们想找到评分函数 s 与 f 的接近程度的度量。理想的评分函数将与 f 完全一致。我们将称这样的性能准则为 C(s)。
给定一组与勒贝格测度可积的评分函数 S。
s 的 MV-曲线是映射的绘图:

这里  。
。
集合 X 的勒贝格测度通过将集合分成桶(开区间序列)并求和每个桶的 n-体积得到。n-体积是每个维度的长度的乘积,定义为最大值和最小值之间的差异。如果 X[i] 是一堆 d 维点的子集,则它们在每个轴上的投影将给出长度,长度的乘积将给出 d 维体积。
a 处的 MV 测度对应于 X 的由阈值 t 定义的下确界子集的 n-体积,使得 s(X) 在 t 处的 c.d.f. 高于或等于 a。

来自“质量体积曲线与异常排名”的体积质量曲线,S. Clemencon,UMR LTCI No. 5141,Telecom ParisTech/CNRS
最佳的 MV 曲线将是在 f 上计算的曲线。我们希望找到最小化在感兴趣的区间 IMV 上点与 MVf 之间的逐点差异的得分函数 s,该区间表示大密度级集合(例如,[0.9, 1])。
已经证明  。由于 MV s 总是在 MV f 下方,因此
。由于 MV s 总是在 MV f 下方,因此  将对应于
将对应于  。我们的 MV 的性能准则为
。我们的 MV 的性能准则为  。CMV 的值越小,评分函数的性能越好。
。CMV 的值越小,评分函数的性能越好。
MV 曲线的一个问题是,如果分布的支持是无限的(可能值的集合没有界限),则曲线下的面积(AUC)在 a = 1 时会发散。
一个解决方法是选择区间  。
。
更好的变体是过剩质量(EM)曲线,定义为映射的绘制:

性能指标将是  和
和  ,其中
,其中  。EM[s] 现在总是有限的。
。EM[s] 现在总是有限的。

从《异常排名和过剩质量曲线》中的过剩质量曲线,N. Goix,A. Sabourin,S. Clemencon,UMR LTCI No. 5141,Telecom ParisTech/CNRS。
EM 的一个问题是,大级别集的区间与总支持体积的倒数数量级相同。对于具有大尺寸的数据集来说,这是一个问题。此外,对于 EM 和 MV,正常数据的分布 f 是未知的,必须进行估计。为了实用性,可以通过蒙特卡洛逼近来估计勒贝格体积,这仅适用于小尺寸。
为了适应大维数据,我们可以迭代地用替换子集的方式在随机固定数量的特征 d’ 中进行训练和验证数据的子采样,以计算 EM 或 MV 性能指标分数。仅在我们为每个特征子集绘制样本后才进行替换。
最终的性能指标是通过对不同特征绘制的这些部分指标进行平均得到的。缺点是我们不能验证超过 d’ 个特征的组合。另一方面,这种特征抽样使我们能够估计大维度下的 EM 或 MV,并且使我们能够比较从不同维度的数据输入空间产生的模型,假设我们想要在消耗不同视图的模型之间进行选择。
验证摘要
我们已经看到了如何在有标签和无标签数据的情况下绘制曲线图并计算聚合度量。
我们已经展示了如何选择得分函数的阈值子范围,以使聚合度量在异常检测中更具意义。对于 PR 曲线,我们可以设置精确度和召回率的最小要求;对于 EM 或 MV,即使它们没有直接对应的含义,我们也可以任意选择相应于大级别集的区间。
在我们的网络入侵示例中,我们对异常点进行评分并将其存储到队列中供进一步人工检查。在这种情况下,我们还需要考虑安全团队的吞吐量。假设他们每天只能检查 50 个连接;我们的性能指标应仅计算队列中的前 50 个元素。即使模型能够在前 1,000 个元素上达到 100% 的召回率,这些 1,000 个元素在实际情况下也不可检查。
这种情况有点简化了问题,因为我们将自动选择给出预期数量的预测异常的阈值,而与真正阳性或假阳性无关。这是模型可以做的最好的,鉴于最有可能是异常的前 N 个观察值。
在交叉折叠验证中,基于阈值的验证指标存在另一个问题,那就是聚合技术。聚合有两种主要方式:微观和宏观。
宏观聚合是最常见的一种;我们在每个验证折叠中计算阈值和指标,然后对它们求平均。微观聚合包括存储每个验证折叠的结果,将它们串联在一起,并在最后计算一个单一的阈值和指标。
宏观聚合技术还提供了稳定性的度量,以及如果我们通过使用不同样本进行扰动时系统性能的变化程度。另一方面,宏观聚合会给模型估计引入更多偏差,特别是在罕见类别(如异常检测)中。因此,一般偏向于微观聚合。
超参数调整
根据前面章节的深度神经网络设计,我们将得到一堆需要调整的参数。其中一些具有默认值或推荐值,并且不需要昂贵的微调。其他参数则严重依赖于底层数据、特定应用领域和一系列其他组件。因此,找到最佳值的唯一方法是执行模型选择,根据在验证数据折叠上计算的所需指标进行验证。
现在我们将列出一个表格,其中包含我们可能想要考虑调整的参数。请注意,每个库或框架可能有额外的参数和自定义设置方式。此表格源自于 H2O 中可用的调整选项。它总结了在生产中构建深度自动编码器网络时的常见参数,但不是全部:
| 参数 | 描述 | 推荐值 |
|---|---|---|
activation | 可微激活函数。 | 取决于数据的特性。流行函数包括:Sigmoid、Tanh、Rectifier 和 Maxout。每个函数都可以映射到相应的丢弃版本。请参考网络设计部分。 |
| hidden | 尺寸和层数。 | 当网络是自编码器时,层数始终是奇数,并且在编码和解码之间对称。尺寸取决于网络设计和正则化技术。没有正则化时,编码层应连续小于前一层。有了正则化,我们可以拥有比输入尺寸更高的容量。 |
| epochs | 对训练集进行的迭代次数。 | 一般来说,介于 10 和几百之间。根据算法的不同,可能需要额外的迭代来收敛。如果使用了早停法,就不需要担心迭代次数太多。对于使用网格搜索进行模型选择,最好将其保持足够小(小于 100)。 |
train_samples_per_iteration | Map/Reduce 迭代中的训练样例数。 | 此参数仅适用于分布式学习的情况。这在很大程度上取决于实现方式。H2O 提供了自动调优选项。请参考Distributed learning via Map/Reduce部分。 |
adaptive_rate | 启用自适应学习率。 | 每个库可能有不同的策略。H2O 的默认实现是ADADELTA。对于ADADELTA,还必须指定额外的参数 rho(介于 0.9 和 0.999 之间)和 epsilon(介于 1e-10 和 1e-4 之间)。请参考自适应学习部分。 |
rate,rate_decay | 学习率的值和衰减系数(如果不是自适应学习)。 | 较高的学习率可能导致不稳定的模型,较低的值会减缓收敛速度。一个合理的值是 0.005。衰减系数表示学习率在各个层级上衰减的速率。 |
momentum_start,momentum_ramp,momentum_stable | 动量技术的参数(如果不是自适应学习)。 | 当动量开始和稳定值之间存在间隔时,动量斜坡是以训练样例数量为单位衡量的。默认值通常较大,例如 1e6。 |
Input_dropout_ratio,hidden_dropout_ratio | 每个层级中要在训练过程中省略的输入节点的比例。 | 输入(所有特征)的默认值为 0,隐藏层的值约为 0.5。 |
l1,l2 | L1 和 L2 正则化参数。 | 较大的 L1 值会导致许多权重变为 0,较大的 L2 值会减小但保留大部分权重。 |
max_w2 | 一个节点上所有权重的平方和的最大值。 | 对于无界激活函数(如 ReLU 或 Maxout)很有用的一个参数。 |
initial_weight_distribution | 初始权重的分布。 | 典型的值有均匀分布(Uniform)、正态分布(Normal)或自适应均匀分布(UniformAdaptive)。通常更倾向于后者。 |
loss | 后向传播过程中要使用的损失函数。 | 这取决于问题和数据的性质。常见的函数有交叉熵(CrossEntropy)、平方差(Quadratic)、绝对值(Absolute)、Huber。请参考网络设计部分。 |
rho_sparsity,beta_sparsity | 稀疏自动编码器的参数。 | Rho 是平均激活频率,beta 是与稀疏惩罚相关的权重。 |
这些参数可以使用搜索空间优化技术来进行调优。H2O 支持的两个基本和流行的技术是网格搜索和随机搜索。
网格搜索是一种穷举的方法。每个维度指定了一系列可能的值,笛卡尔积生成了搜索空间。每个点将以并行方式进行评估,并选择得分最低的点。评分函数由验证指标定义。
一方面,我们的计算成本与维度的幂等于(维度的诅咒)。另一方面,它是尴尬地并行的。也就是说,每个点都是完全可以并行化的,它的运行与其他点是独立的。
另外,在密集搜索空间中随机选择点可能更有效,并且可以在需要更少的计算的情况下产生类似的结果。在一个特定数据集中,浪费的网格搜索尝试的数量与被证明对于某一个数据集是无关紧要的搜索维度的数量是指数级的。不是每个参数在调整过程中都具有相同的重要性。随机搜索不受这些低重要性维度的影响。
在随机搜索中,每个参数必须提供一个分布,取决于参数的值是连续的还是离散的。试验点是从这些分布中独立抽样的点。
随机搜索的主要优势包括:
-
您可以固定预算(最大探索点数或最大允许时间)。
-
您可以设置收敛标准。
-
添加不影响验证性能的参数不影响效率。
-
在调整过程中,您可以动态地添加额外的参数,而无需调整网格并增加尝试次数。
-
如果某次试验运行失败,由于任何原因,可以放弃或重新启动,而不会危及整个调整算法。
随机搜索的常见应用与早期停止有关。特别是在高维空间中有许多不同模型的情况下,收敛到全局最优解之前的尝试次数可能会很多。当学习曲线(训练)或验证曲线(调整)趋于平缓时,早期停止将停止搜索。
因为我们也可以限制计算预算,所以我们可以设置诸如:当 RMSE 比最佳 5 个模型的移动平均改善少于 0.0001 时停止,但最多不超过 1 小时 的标准。
基于度量的早期停止结合最大运行时一般给出最佳的权衡。
通常也会有多阶段的调整,例如,您可以运行随机搜索来识别可能存在最佳配置的子空间,然后仅在所选子空间中进行进一步的调整阶段。
更高级的技术还利用了顺序,自适应的搜索/优化算法,其中一个试验的结果影响下一个试验的选择和/或超参数是联合优化的。目前正在进行研究,试图预先确定超参数的变量重要性。此外,领域知识和手动微调对于那些自动技术难以收敛的系统可能是有价值的。
端到端评估
从商业角度来看,真正重要的是最终的端到端性能。你的利益相关者都不会对你的训练误差、参数调整、模型选择等感兴趣。重要的是基于最终模型计算的关键绩效指标。评估可以被看作是最终的裁决。
此外,正如我们预期的那样,评估产品不能仅仅依靠单一指标。通常,构建一个内部仪表板是一个好的有效的做法,它可以以汇总数字或易于解释的可视化图表的形式实时报告或测量我们产品的一系列绩效指标。通过一瞥,我们希望理解整个图片并将其转化为我们在业务中产生的价值。
评估阶段通常包括与模型验证相同的方法。我们在前面的章节中看到了一些在有标签和无标签数据情况下验证的技术。这些可以作为起点。
除了那些,我们还应该包括一些具体的测试场景。例如:
-
已知与未知检测性能:这意味着衡量检测器对已知和未知攻击的性能。我们可以使用标签创建不同的训练集,其中一些根本没有攻击,而另一些则有小部分攻击;请记住,在训练集中有太多异常将违反异常的定义。我们可以根据训练集中异常百分比的函数来测量前 N 个元素的精度。这将为我们提供检测器相对于过去异常和假设的新异常的一般性的指示。取决于我们试图构建的内容,我们可能更感兴趣于新异常还是已知异常。
-
相关性能:只有得分达到阈值或者在优先级队列中被选择是重要的,但排名也很重要。我们希望最相关的异常总是排在队列的前面。在这里,我们可以定义不同标签的优先级,并计算排名系数(例如,Spearman 系数),或者使用一些用于推荐系统的评估技术。后者的一个例子是信息检索中使用的 k 个均值平均精度(MAP@k),用于评分查询引擎返回文档的相关性。
-
模型稳定性:我们在验证过程中选择最佳模型。如果我们以不同的方式抽样训练数据,或者使用略有不同的验证数据集(包含不同类型的异常),我们希望最佳模型始终保持相同,或者至少是在顶部选出的模型之一。我们可以创建直方图,显示给定模型被选择的频率。如果没有明显的获胜者或一组频繁候选模型,那么模型选择就有些不稳定。每天,我们可能会选择一个不同的模型,该模型可以很好地对新攻击做出反应,但代价是稳定性不好。
-
攻击结果:如果模型检测到一次得分非常高的攻击,并且分析师们确认了这次攻击,那么模型是否能够检测出系统是否已被入侵或恢复正常?一种测试方法是在发出警报后测量异常得分的分布。将新的分布与旧的分布进行比较,并测量其中的差距。一个好的异常检测器应该能够告诉你系统的状态。评估仪表板可以将最近检测到的异常可视化显示出来。
-
故障案例模拟:安全分析师可以定义一些场景并生成一些合成数据。其中一个业务目标可以是“能够保护免受未来这些类型的攻击”。可以从这个人工数据集中提取专用的性能指标。例如,对同一主机和端口的网络连接进行递增的斜坡可能是拒绝服务 (DOS) 攻击的迹象。
-
检测时间:检测器通常独立地对每个数据点进行评分。对于上下文和基于时间的异常,同一实体可能会生成许多数据点。例如,如果我们打开一个新的网络连接,我们可以在连接仍然打开时对其进行评分,并且每隔几秒生成一个特征收集在不同时间间隔内的新数据点。通常,您会将多个连续的连接整合到一个数据点中进行评分。我们希望能够测量反应所需的时间。如果第一个连接不被视为异常,也许在连续尝试了 10 次之后,检测器将会有反应。我们可以将已知的异常拆分成连续增长的数据点,然后报告在经过多少个数据点后发现了上下文异常。
-
损害成本:如果我们能够以某种方式量化攻击造成的损害或由于检测而产生的节省,我们应该将其纳入最终评估中。我们可以以过去的一个月或一年作为基准,并估计节省的金额;希望这个平衡是正向的,如果我们自那时起部署了当前解决方案,或者如果当前解决方案是在最近这段时间部署的,这样可以获得真正的节省。
我们希望能够在单个仪表板中总结所有这些信息,以便我们可以发表如下的声明:我们的异常检测器能够以 76%(± 5%)的精度和平均反应时间为 10 秒来检测先前发现的异常,以及以 68%(± 15%)的精度和 14 秒的反应时间来检测新异常。我们每天观察到平均 10 个异常。考虑到每天可以进行 1,000 次检查的能力,我们可以在队列的前 120 个元素中填充 80%的最相关检测,对应于仅将 6 个异常纳入其中。这些中仅有 2 个是危及系统的。然后我们可以将检查分为两个级别;第一级将立即响应前 120 个元素,第二级将处理剩下的。按照当前模拟的故障场景,我们在其中受到了 90%的保护。自去年以来的总节省额相当于 120 万美元。
A/B 测试
到目前为止,我们只考虑过基于过去历史数据(事后分析)和/或基于合成数据集模拟的评估。第二种方法是基于假设未来会发生特定故障场景的。仅基于历史数据进行评估假定了系统将始终在这些条件下运行,并且当前的数据分布也描述了未来数据流。此外,任何关键绩效指标都应相对于基线进行评估。产品负责人希望为该项目的投资提供理由。如果相同的问题可以以更便宜的方式解决呢?
出于这个原因,评估任何机器学习系统的唯一方法是 A/B 测试。A/B 测试是一种统计假设检验,有两种变体(控制组和变体组)的受控实验。A/B 测试的目标是确定两组之间的性能差异。在网站用户体验设计或广告/营销活动中广泛使用这种技术。在异常检测的情况下,我们可以将基线(最简单的基于规则的检测器)作为控制版本,当前选择的模型作为变体候选者。
下一步是找到一个有意义的评估,量化投资回报。
“我们必须找到一种让重要的事物可度量,而不是让可度量的事物变得重要的方法。”
罗伯特·麦克纳马拉,前美国国防部部长
投资回报将由提升定义为:

两个 KPI 之间的差异量化了治疗效果。
为了公平比较,我们必须确保这两组共享相同的人口分布。我们希望消除数据样本选择所带来的任何偏见。在异常检测器的情况下,我们原则上可以将相同的数据流应用到这两个模型。虽然这样做并不推荐。通过应用一个模型,您可以影响给定过程的行为。一个典型的例子是一个入侵者首先被模型检测到,因此系统会通过中断他的开放连接来做出反应。一个聪明的入侵者会意识到他已被发现,不会再尝试连接。在这种情况下,由于第一个模型的影响,第二个模型可能永远不会观察到某个预期模式。
通过将两个模型分离到数据的两个不相交子集中,我们确保这两个模型不能相互影响。此外,如果我们的用例要求分析师进一步调查异常,那么它们不能被复制。
在这里,我们必须根据与数据验证中相同的标准进行分割:没有数据泄露和实体子采样。能够确认这两组实际上是相同分布的最终测试是 A/A 测试。
顾名思义,A/A 测试就是在两组上重新使用控制版。我们期望性能应该非常相似,相当于接近 0 的增益。这也是性能方差的指标。如果 A/A 增益不为零,则我们必须重新设计受控实验,使其更加稳定。
A/B 测试非常适合衡量两个模型之间性能的差异,但模型不是唯一影响最终性能的因素。如果我们考虑损耗成本模型,即业务核心,模型必须准确地生成一个优先级列表,以便调查异常,同时分析师必须擅长识别、确认和采取行动。
因此,我们有两个因素:模型准确性和安全团队的有效性。
我们可以将受控实验分成 A/B/C/D 测试,创建四个独立的组,如下所示:
| 基础模型 | 先进模型 | |
|---|---|---|
| 来自安全团队的无操作 | A 组 | B 组 |
| 来自安全团队的干预 | C 组 | D 组 |
我们可以计算一系列增益度量,量化模型准确性和安全团队的有效性。特别是:
-
uplift(A,B): 先进模型单独的有效性 -
uplift(D,C): 发生安全干预时先进模型的有效性 -
uplift(D,A): 先进模型和安全干预一起的有效性 -
uplift(C,A): 低准确性队列上的安全干预的有效性 -
uplift(D,B): 安全干预对高准确性队列的有效性
这只是一个有意义的实验和评估的示例,您想进行这些评估以便以数字形式量化业务真正关心的内容。
此外,还有一堆用于 A/B 测试的高级技术。只是举一个例子,多臂老丨虎丨机算法允许您动态调整不同测试组的大小,以适应它们的性能并最小化由于性能低的组造成的损失。
测试摘要
总之,对于使用神经网络和标记数据的异常检测系统,我们可以定义以下内容:
-
模型作为网络拓扑的定义(隐藏层的数量和大小),激活函数,预处理和后处理转换。
-
模型参数作为隐藏单元的权重和隐藏层的偏置。
-
拟合模型作为具有参数估计值的模型,能够将样本从输入层映射到输出层。
-
学习算法(也称为训练算法)作为 SGD 或其变体(HOGWILD!,自适应学习)+损失函数+正则化。
-
训练集、验证集和测试集是可用数据的三个不相交且可能独立的子集,其中我们保留相同的分布。
-
模型验证作为在训练集上拟合的模型计算的 ROC 曲线上的最大 F-度量分数。
-
模型选择作为一组可能配置中的最佳验证模型(1 隐藏层 Vs. 3 隐藏层,50 个神经元 Vs. 1000 个神经元,Tanh Vs. Sigmoid,Z-scaling Vs. Min/Max 归一化等等…)。
-
超参数调整作为模型选择的延伸,使用算法和实现参数,如学习参数(epochs,批量大小,学习速率,衰减因子,动量…),分布式实现参数(每次迭代的样本),正则化参数(L1 和 L2 中的 lambda,噪声因子,稀疏性约束…),初始化参数(权重分布)等等。
-
模型评估,或测试,作为在测试集上计算的最终业务指标和验收标准,使用在训练集和验证集上拟合的模型合并在一起。一些示例是仅针对前 N 个测试样本的精确度和召回率,检测时间等等。
-
A/B 测试作为模型与基线之间的评估性能提升,基线是根据现场数据人群的两个不同但同质的子集计算的(对照组和变化组)。
我们希望我们已经澄清了在测试生产就绪的深度学习入侵检测系统时需要考虑的基本和最重要的步骤。这些技术、指标或调整参数可能对您的用例不同,但我们希望深思熟虑的方法论可以作为任何数据产品的指南。
一个关于构建既科学正确又对业务有价值的数据科学系统的指导方针和最佳实践的重要资源是专业数据科学宣言:www.datasciencemanifesto.org。推荐阅读并围绕列出的原则进行思考。
部署
在这个阶段,我们应该已经完成了几乎所有构建异常检测器或通用深度学习数据产品所需的分析和开发工作。
我们只剩下最后但同样重要的一步:部署。
部署通常非常特定于用例和企业基础架构。在本节中,我们将介绍一些在通用数据科学生产系统中使用的常见方法。
POJO 模型导出
在测试部分,我们总结了机器学习管道中的所有不同实体。特别是,我们已经看到了模型、适配模型和学习算法的定义和区别。在我们训练、验证和选择了最终模型之后,我们得到了一个准备好使用的最终适配版本。在测试阶段(除了 A/B 测试),我们只对通常已经可用于训练模型的历史数据进行了评分。
在企业架构中,常见的是有一个数据科学集群,您在其中构建一个模型,以及用于部署和使用适配模型的生产环境。
一种常见的导出适配模型的方法是纯旧的 Java 对象(POJO)。POJO 的主要优点是它可以很容易地集成到 Java 应用程序中,并安排在特定数据集上运行或部署以实时进行评分。
H2O 允许您通过编程方式或从 Flow Web UI 中提取适配模型,这在本书中没有涵盖。
如果 model 是您的适配模型,您可以通过运行以下命令将其保存为指定路径中的 POJO jar:
model.download_pojo(path)
POJO jar 包含了一个独立的 Java 类 hex.genmodel.easy.EasyPredictModelWrapper,不依赖于训练数据或整个 H2O 框架,而只依赖于 h2o-genmodel.jar 文件,该文件定义了 POJO 接口。它可以从任何在 JVM 中运行的东西中读取和使用。
POJO 对象将包含与在 H2O 中使用的模型 id(model.id)对应的模型类名称,以及用于异常检测的模型类别将是 hex.ModelCategory.AutoEncoder。
不幸的是,在撰写本章时,关于实现 AutoEncoder 的 Easy API 仍然存在一个未解决的问题:0xdata.atlassian.net/browse/PUBDEV-2232。
来自 h2ostream 邮件列表的 Roberto Rösler 通过实现自己的 AutoEncoderModelPrediction 类解决了这个问题,如下所示:
public class AutoEncoderModelPrediction extends AbstractPrediction {public double[] predictions;public double[] feature;public double[] reconstrunctionError;public double averageReconstructionError;
}
并修改了 EasyPredictModelWrapper 中的 predictAutoEncoder 方法,如下所示:
public AutoEncoderModelPrediction predictAutoEncoder(RowData data) throws PredictException { double[] preds = preamble(ModelCategory.AutoEncoder, data);// save predictionsAutoEncoderModelPrediction p = new AutoEncoderModelPrediction();p.predictions = preds;// save raw datadouble[] rawData = new double[m.nfeatures()];setToNaN(rawData);fillRawData(data, rawData);p.feature = rawData;//calculate and reconstruction errordouble[] reconstrunctionError = new double [rawData.length];for (int i = 0; i < reconstrunctionError.length; i++) {reconstrunctionError[i] = Math.pow(rawData[i] - preds[i],2); } p.reconstrunctionError = reconstrunctionError;//calculate mean squared errordouble sum = 0; for (int i = 0; i < reconstrunctionError.length; i++) {sum = sum + reconstrunctionError[i];} p.averageReconstructionError = sum/reconstrunctionError.length;return p;}
自定义修改的 API 将公开一种检索每个预测行的重构错误的方法。
为使 POJO 模型工作,我们必须指定与训练期间使用的相同的数据格式。数据应加载到hex.genmodel.easy.RowData对象中,这只是java.util.Hashmap<String, Object>的实例。
创建RowData对象时,必须确保以下事项:
-
使用相同的列名和
H2OFrame的类型。对于分类列,必须使用 String。对于数值列,可以使用 Double 或 String。不支持不同的列类型。 -
对于分类特征,除非您将
convertUnknownCategoricalLevelsToNa显式设置为模型包装器中的 true,否则值必须属于训练时使用的相同集合。 -
可以指定其他列,但将被忽略。
-
任何缺少的列都将被视为 NA。
-
数据也应该应用相同的预处理转换。
这最后一个要求可能是最棘手的。如果我们的机器学习流水线由一堆转换器组成,那么这些转换器必须在部署中完全复制。因此,POJO类是不够的,还应该与 H2O 神经网络以及流水线中的所有其他步骤一起使用。
下面是一个 Java 主函数的示例,它读取一些数据,并针对导出的POJO类进行评分:
import java.io.*;
import hex.genmodel.easy.RowData;
import hex.genmodel.easy.EasyPredictModelWrapper;
import hex.genmodel.easy.prediction.*;public class main {public static String modelClassName = "autoencoder_pojo_test";public static void main(String[] args) throws Exception {hex.genmodel.GenModel rawModel;rawModel = (hex.genmodel.GenModel) Class.forName(modelClassName).newInstance();EasyPredictModelWrapper model = new EasyPredictModelWrapper(rawModel);RowData row = new RowData();row.put("Feature1", "value1");row.put("Feature2", "value2");row.put("Feature3", "value3");AutoEncoderModelPrediction p = model.predictAutoEncoder(row);System.out.println("Reconstruction error is: " + p.averageReconstructionError);}
}
我们已经看到了如何将 POJO 模型实例化为 Java 类并将其用于评分模拟数据点的示例。我们可以重新调整此代码,以便将其集成到现有的基于 JVM 的企业系统中。如果您正在集成它到 Spark 中,您只需将我们在示例主类中实现的逻辑包装在一个函数中,并从 Spark 数据集的 map 方法中调用它。您所需要的只是将模型 POJO jar 加载到您想要进行预测的 JVM 中。或者,如果您的企业栈是基于 JVM 的,还有一些实用的入口点,例如hex.genmodel.PredictCsv。它允许您指定一个 csv 输入文件和一个用于存储输出的路径。由于 Easy API 尚不支持AutoEncoder,您将不得不根据我们之前看到的自定义补丁修改PredictCsv主类。另一种架构可能是使用 Python 构建模型并在生产部署中使用基于 JVM 的应用程序。
异常分数 API
将模型导出为 POJO 类是以程序方式将其包含在现有 JVM 系统中的一种方法,就像导入外部库一样。
在一些其他情况下,使用自包含的 API 进行集成会更好,比如在微服务架构或非 JVM-based 系统中。
H2O 可以将训练好的模型封装为一个 REST API,通过附加在 HTTP 请求中的 JSON 对象指定要评分的行数据来调用。 REST API 后端的实现可以执行您在 Python H2O API 中执行的所有操作,包括预处理和后处理步骤。
REST API 可从以下位置访问:
-
任何使用简单插件的浏览器,例如 Chrome 中的 Postman
-
curl,用于客户端 URL 传输的最流行工具之一
-
任何您选择的语言;REST API 完全与语言无关
尽管存在 POJO 类,但 H2O 提供的 REST API 依赖于运行中的 H2O 集群实例。您可以在http://hostname:54321后面加上 API 版本(最新为 3)和资源路径,例如,http://hostname:54321/3/Frames将返回所有 Frames 的列表。
RESTAPI 支持五个动词或方法:GET、POST、PUT、PATCH和DELETE。
GET用于读取没有副作用的资源,POST用于创建新资源,PUT用于更新和完全替换现有资源,PATCH用于修改现有资源的一部分,DELETE用于删除资源。H2O RESTAPI 不支持PATCH方法,并添加了一个称为HEAD的新方法。它类似于GET请求,但仅返回HTTP状态,可用于检查资源是否存在而无需加载它。
H2O 中的端点可以是 Frames、Models 或 Clouds,这些是与 H2O 集群中节点状态相关的信息片段。
每个端点将指定其自己的有效载荷和模式,并且文档可以在docs.h2o.ai/h2o/latest-stable/h2o-docs/rest-api-reference.html上找到。
H2O 在 Python 模块中提供了一个连接处理程序,用于所有 REST 请求:
with H2OConnection.open(url='http://hostname:54321') as hc:hc.info().pprint()
hc对象有一个名为request的方法,可以用来发送REST请求:
hc.request(endpoint='GET /3/Frames')
对于POST请求的数据载荷可以使用data参数(x-www 格式)或json参数(json 格式),并指定一个键值对字典。通过指定filename参数映射到本地文件路径来上传文件。
在这个阶段,无论我们使用 Python 模块还是任何 REST 客户端,我们必须按照以下步骤上传一些数据并获取模型得分:
-
使用
POST /3/ImportFiles导入要评分的数据,使用ImporFilesV3模式,包括从哪里加载数据的远程路径(通过 http、s3 或其他协议)。相应的目标帧名称将是文件路径:POST /3/ImportFiles HTTP/1.1 Content-Type: application/json { "path" : "http://s3.amazonaws.com/my-data.csv" } -
猜测解析参数;它将返回从数据中推断出的一堆参数,用于最终解析(您可以跳过并手动指定这些参数):
POST /3/ParseSetup HTTP/1.1 Content-Type: application/json { "source_frames" : "http://s3.amazonaws.com/my-data.csv" } -
根据解析参数解析:
POST /3/Parse HTTP/1.1 Content-Type: application/json { "destination_frame" : "my-data.hex" , source_frames : [ "http://s3.amazonaws.com/my-data.csv" ] , parse_type : "CSV" , "number_of_columns" : "3" , "columns_types" : [ "Numeric", "Numeric", "Numeric" ] , "delete_on_done" : "true" } -
从响应中获取作业名称,并轮询导入完成状态:
GET /3/Jobs/$job_name HTTP/1.1 -
当返回状态为 DONE 时,您可以运行模型评分如下:
POST /3/Predictions/models/$model_name/frames/$frame_name HTTP/1.1 Content-Type: application/json { "predictions_frame" : "$prediction_name" , "reconstruction_error" : "true" , "reconstruction_error_per_feature" : "false" , "deep_features_hidden_layer" : 2 } -
解析结果后,您可以删除输入和预测框架:
DELETE /3/Frames/$frame_nameDELETE /3/Frames/$prediction_name
让我们分析 Predictions API 的输入和输出。 reconstruction_error、reconstruction_error_per_feature 和 deep_features_hidden_layer 是 AutoEncoder 模型的特定参数,并确定输出中将包含什么。输出是一个 model_metrics 数组,对于 AutoEncoder 将包含:
-
MSE:预测的均方误差
-
RMSE:预测的均方根误差
-
得分时间:自这次评分运行开始以来的毫秒数
-
预测:包含所有预测行的框架
部署的总结
我们已经看到两种导出和部署训练模型的选项:将其导出为 POJO 并将其合并到基于 JVM 的应用程序中,或者使用 REST API 调用已加载到运行中 H2O 实例中的模型。
一般来说,使用 POJO 是一个更好的选择,因为它不依赖于运行中的 H2O 集群。因此,您可以使用 H2O 构建模型,然后在任何其他系统上部署它。
如果您想要实现更大的灵活性,并且能够在任何客户端随时生成预测,只要 H2O 集群正在运行,那么 REST API 就会很有用。然而,这个过程需要比 POJO 部署更多的步骤。
另一个推荐的架构是使用导出的 POJO 并将其包装在使用 Jersey 进行 Java 或者 Play 或 akka-http 进行 Scala 的 JVM REST API 中。构建自己的 API 意味着您可以以编程方式定义接受输入数据的方式以及单个请求中要返回的内容,而不是 H2O 中的多个步骤。此外,您的 REST API 可以是无状态的。也就是说,您不需要将数据导入帧并在之后删除它们。
最终,如果您希望基于 POJO 的 REST API 能够轻松地移植和部署到任何地方,建议您使用 Docker 将其包装在虚拟容器中。Docker 是一个开源框架,允许您将软件包装在一个完整的文件系统中,其中包含运行所需的所有内容:代码、运行时、系统工具、库以及您需要安装的所有内容。这样,您就有了一个单一的轻量级容器,在任何环境中始终可以运行相同的服务。
Docker 化的 API 可以轻松地部署到您的任何生产服务器上。
部署摘要
在本章中,我们经历了一段漫长的优化、调整、测试策略和工程实践之旅,将我们的神经网络转化为入侵检测数据产品。
特别是,我们将数据产品定义为从原始数据中提取价值并将可操作的知识作为输出返回的系统。
我们看到了一些训练深度神经网络以获得更快、可扩展和更健壮性的优化方法。我们通过权重初始化解决了早期饱和问题。利用并行多线程版本的 SGD 和 Map/Reduce 中的分布式实现来提高可扩展性。我们看到了 H2O 框架如何通过 Sparkling Water 将 Apache Spark 作为计算后端来实现。
我们强调了测试的重要性,以及模型验证和完整端到端评估之间的区别。模型验证用于拒绝或接受给定模型,或选择性能最佳的模型。同样,模型验证指标可用于超参数调整。另一方面,端到端评估更全面地量化了完整解决方案如何解决实际业务问题。
最终,我们进行了最后一步——通过将测试过的模型直接部署到生产环境中,要么将其导出为 POJO 对象,要么通过REST API 将其转换为服务。
我们总结了在构建强大的机器学习系统和更深层次的架构方面所学到的一些经验教训。我们期望读者将这些作为进一步发展和根据每个使用案例定制解决方案的基础。